
@Async 애노테이션
Spring에서 비동기 처리는 @Async 애노테이션을 통해 구현할 수 있다. 그렇다면 그 내부 동작 원리에 대해서 제대로 이해해보자.
@Async 애노테이션은 스프링 AOP으로 구현되어, 프록시 패턴 기반으로 동작한다. 스프링에서 해당 객체를 스프링 빈에 등록하는 과정에서 프록시 객체를 생성 및 등록하여, 프록시 객체 → 실제 객체 순으로 실행되어 프록시 객체를 통해 특정 동작을 구현하는 방식이다.
AsyncAnnotationAdvisor 내부 코드를 살펴보면,
public class AsyncAnnotationAdvisor extends AbstractPointcutAdvisor implements BeanFactoryAware {
...
protected Advice buildAdvice(@Nullable Supplier<Executor> executor, @Nullable Supplier<AsyncUncaughtExceptionHandler> exceptionHandler) {
AnnotationAsyncExecutionInterceptor interceptor = new AnnotationAsyncExecutionInterceptor((Executor)null);
interceptor.configure(executor, exceptionHandler);
return interceptor;
}
}
Java
복사
이와 같이 어드바이스를 생성하는 시점에 executor와 ExceptionHandler를 주입해 AnnotationAsyncExecutionInterceptor를 생성 후 반환한다.
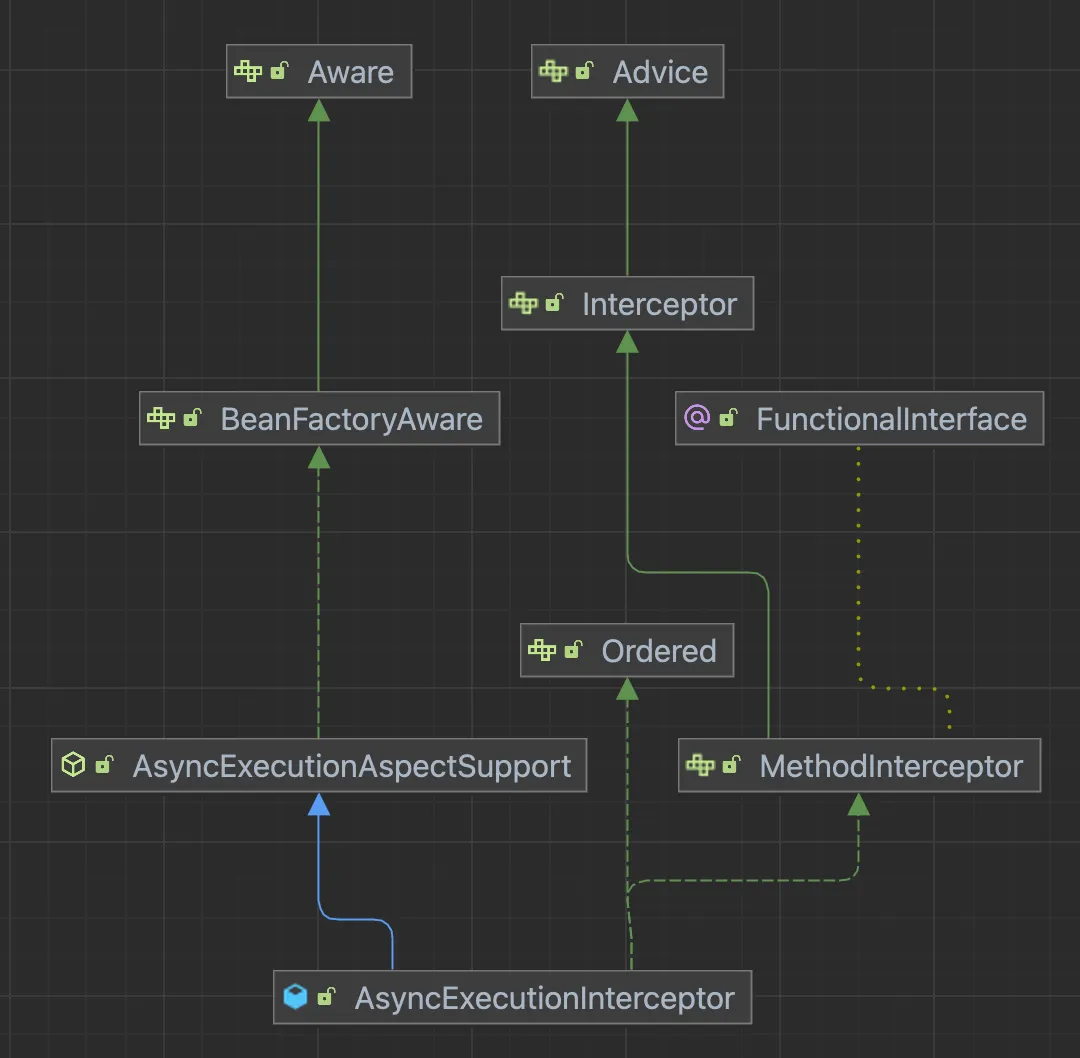
AnnotationAsyncExecutionInterceptor는 Advice를 상속받은 객체로, AsyncExecutionAspectSupport 추상 객체를 구현하는 객체이다.
public abstract class AsyncExecutionAspectSupport implements BeanFactoryAware
@Nullable
public Object invoke(final MethodInvocation invocation) throws Throwable {
Class<?> targetClass = invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null;
Method specificMethod = ClassUtils.getMostSpecificMethod(invocation.getMethod(), targetClass);
Method userDeclaredMethod = BridgeMethodResolver.findBridgedMethod(specificMethod);
AsyncTaskExecutor executor = this.determineAsyncExecutor(userDeclaredMethod);
if (executor == null) {
throw new IllegalStateException("No executor specified and no default executor set on AsyncExecutionInterceptor either");
} else {
Callable<Object> task = () -> {
try {
Object result = invocation.proceed();
if (result instanceof Future) {
return ((Future)result).get();
}
} catch (ExecutionException var4) {
ExecutionException ex = var4;
this.handleError(ex.getCause(), userDeclaredMethod, invocation.getArguments());
} catch (Throwable var5) {
Throwable exx = var5;
this.handleError(exx, userDeclaredMethod, invocation.getArguments());
}
return null;
};
return this.doSubmit(task, executor, invocation.getMethod().getReturnType());
}
}
@Nullable
protected Object doSubmit(Callable<Object> task, AsyncTaskExecutor executor, Class<?> returnType) {
if (CompletableFuture.class.isAssignableFrom(returnType)) {
return CompletableFuture.supplyAsync(() -> {
try {
return task.call();
} catch (Throwable var2) {
Throwable ex = var2;
throw new CompletionException(ex);
}
}, executor);
} else if (ListenableFuture.class.isAssignableFrom(returnType)) {
return ((AsyncListenableTaskExecutor)executor).submitListenable(task);
} else if (Future.class.isAssignableFrom(returnType)) {
return executor.submit(task);
} else {
executor.submit(task);
return null;
}
}
}
Java
복사
AsyncExecutionAspectSupport에는 위와 같이 프록시 객체에서 실행될 로직이 들어있다.
invoke를 호출 시에 생성 시 주입받은 Executor를 통해 스레드를 실행시키거나 스레드풀에 작업으로 등록한다. doSummit 메서드를 살펴보면,
1.
반환 값이 없는 경우(null)
2.
반환 값이 있는 경우(Future)
3.
반환 값이 있고 예외 처리가 필요한 경우(CompletableFuture)
위 상황에 따라 서로 다른 함수형 인터페이스를 통해 스레드를 실행시키는 것을 확인할 수 있다.
내부적으로 이와 같이 구성되어있기 때문에, 호출자의 로직을 처리하는 스레드와 별도의 스레드에서 비동기로 작업이 진행된다.
사용 시 주의사항
@Async 애노테이션 역시 스프링의 AOP 기술을 사용하기 때문에, 그와 동일한 사용 조건을 가진다.
1.
self-invocation(내부호출) 시에는 적용되지 않는다.
2.
public 메서드에만 적용 가능하다.
사실 위 1번과 2번은 동일한 말인데, 결국 해당 객체 대신 스프링 빈에 프록시 객체를 등록해두어 프록시 객체에서 별도의 로직을 처리하는 기술이기 때문이다. 내부 호출을 하게되면, 프록시 객체를 통해 요청이 전달되는게 아닌 해당 메서드가 직접 호출되기 때문에 동작하지 않는다.
이와 같은 이유로 외부에서도 호출할 수 있는 public 메서드에만 적용가능한 것이다.
AsyncTaskExecutor
public interface AsyncTaskExecutor extends TaskExecutor {
/** @deprecated */
@Deprecated
long TIMEOUT_IMMEDIATE = 0L;
/** @deprecated */
@Deprecated
long TIMEOUT_INDEFINITE = Long.MAX_VALUE;
/** @deprecated */
@Deprecated
void execute(Runnable task, long startTimeout);
Future<?> submit(Runnable task);
<T> Future<T> submit(Callable<T> task);
}
Java
복사
AsyncTaskExecutor는 이와 같은 인터페이스로 여러 실행자들을 구현하는 표준이 된다.
스프링에서는 해당 인터페이스의 구현체로 SimpleAsyncTaskExecutor를 디폴트로 제공하는데, 공식 레퍼런스에는 일반적인 방식의 스레드 풀이 아니기 때문에 스레드를 재사용하는 실행자(스레드풀 방식)를 지정하여 사용하는 것이 권장된다.
실행자를 등록하는 방법으로는
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(5);
executor.setQueueCapacity(5);
executor.setKeepAliveSeconds(30);
executor.setThreadNamePrefix("My Thread - ");
executor.initialize();
return executor;
}
}
Java
복사
이와 같이 AsyncConfigurer를 재정의하거나,
@Configuration
public class ThreadPoolConfig {
@Bean
public Executor asyncThreadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setThreadNamePrefix("Thread - ");
return executor;
}
}
Java
복사
혹은 이와 같이 Executor를 정의하는 빈을 등록해주면된다. 그 과정에서 위처럼 스레드풀의 최대 사이즈나 생성되는 스레드의 이름 prefix 등을 지정할 수 있다.
이렇게 등록된 Executor 빈이 유니크(1개)하다면 스프링이 해당 Executor로 실행하지만, 2개 이상인 경우에는 SimpleAsyncTaskExecutor를 사용하기 때문에 별도로 지정해주어야한다.
@Bean
public Executor asyncThreadPool1() {
...
}
@Bean
public Executor asyncThreadPool2() {
...
}
@Async("asyncThreadPool1")
public void test() {
...
}
Java
복사
등록된 특정 실행자를 지정하여 실행하고 싶다면, 이와 같이 애노테이션에 스프링 빈의 이름(지정하지 않으면 메서드명을 따라간다)을 지정하면 된다.
반대로 등록된 빈이 없다면 어떻게 될까?
@ConditionalOnClass({ThreadPoolTaskExecutor.class})
@AutoConfiguration
@EnableConfigurationProperties({TaskExecutionProperties.class})
public class TaskExecutionAutoConfiguration {
public static final String APPLICATION_TASK_EXECUTOR_BEAN_NAME = "applicationTaskExecutor";
public TaskExecutionAutoConfiguration() {
}
@Bean
@ConditionalOnMissingBean
public TaskExecutorBuilder taskExecutorBuilder(TaskExecutionProperties properties, ObjectProvider<TaskExecutorCustomizer> taskExecutorCustomizers, ObjectProvider<TaskDecorator> taskDecorator) {
TaskExecutionProperties.Pool pool = properties.getPool();
TaskExecutorBuilder builder = new TaskExecutorBuilder();
builder = builder.queueCapacity(pool.getQueueCapacity());
builder = builder.corePoolSize(pool.getCoreSize());
builder = builder.maxPoolSize(pool.getMaxSize());
builder = builder.allowCoreThreadTimeOut(pool.isAllowCoreThreadTimeout());
builder = builder.keepAlive(pool.getKeepAlive());
TaskExecutionProperties.Shutdown shutdown = properties.getShutdown();
builder = builder.awaitTermination(shutdown.isAwaitTermination());
builder = builder.awaitTerminationPeriod(shutdown.getAwaitTerminationPeriod());
builder = builder.threadNamePrefix(properties.getThreadNamePrefix());
Stream var10001 = taskExecutorCustomizers.orderedStream();
var10001.getClass();
builder = builder.customizers(var10001::iterator);
builder = builder.taskDecorator((TaskDecorator)taskDecorator.getIfUnique());
return builder;
}
@Lazy
@Bean(
name = {"applicationTaskExecutor", "taskExecutor"}
)
@ConditionalOnMissingBean({Executor.class})
public ThreadPoolTaskExecutor applicationTaskExecutor(TaskExecutorBuilder builder) {
return builder.build();
}
}
Java
복사
위의 @ConditionalOnMissingBean({Executor.class}) 애노테이션을 보면 알 수 있듯, 등록된 빈이 없는 경우에는 TaskExecutionAutoConfiguration 설정에서 빌더를 통해 생성된 ThreadPoolTaskExecutor 실행자로 동작하게 된다.
public class TaskExecutorBuilder {
...
public ThreadPoolTaskExecutor build() {
return this.configure(new ThreadPoolTaskExecutor());
}
}
Java
복사
ThreadPoolTaskExecutor 동작
ThreadPoolTaskExecutor는 내부적으로 ThreadPoolExecutor를 통해 스레드에 작업을 실행시킨다.
public class ThreadPoolExecutor extends AbstractExecutorService {
...
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
}
Java
복사
그 실행 동작은 위와 같은데,
1.
coreSize 확인하여 작업 중인 스레드가 corePoolSize보다 작은지 확인
2.
그보다 작다면 새로운 스레드 생성 및 작업 실행
3.
없다면 workQueue(BlockingQueue)에 작업을 넣어 대기
4.
BlockingQueue도 가득 찼다면 새로운 스레드를 생성 및 작업 실행(최대 MaxPoolSize)
5.
최대 스레드 개수라면 TaskRejectException 발생
6.
작업 중인 스레드가 완료되면 BlockingQueue에 처리할 작업 확인 및 실행
AsyncUncaughtExceptionHandler
맨 처음의 코드를 살펴보면 AsyncAnnotationAdvisor에서 Advice를 생성할 때, AsyncUncaughtExceptionHandler도 파라미터로 받아 interceptor에 같이 등록하는 것을 확인할 수 있다.
@FunctionalInterface
public interface AsyncUncaughtExceptionHandler {
void handleUncaughtException(Throwable ex, Method method, Object... params);
}
Java
복사
이 AsyncUncaughtExceptionHandler는 위와 같은 함수형 인터페이스이다.
@Slf4j
public class MyAsyncExceptionHandler implements AsyncUncaughtExceptionHandler {
@Override
public void handleUncaughtException(Throwable ex, Method method, Object... params) {
...
}
}
Java
복사
이와 같이 AsyncUncaughtExceptionHandler를 직접 구현하여
@Configuration
public class AsyncConfig {
@Bean
public AsyncUncaughtExceptionHandler asyncExceptionHandler() {
return new MyAsyncExecptionHandler();
}
}
Java
복사
빈으로 등록하거나
@EnableAsync
@Configuration
public class AsyncConfig implements AsyncConfigurer {
@Override
public AsyncUncaughtExceptionHandler getAsyncUncaughtExceptionHandler() {
return new MyAsyncExceptionHandler();
}
}
Java
복사
Configuration 내에 추가해주면, Async 애노테이션으로 인해 실행되는 스레드에서 발생하는 예외 중 원하는 예외를 직접 처리할 수 있다.
트랜잭션 중 비동기 호출
그럼 비동기 실행 환경에서 트랜잭션은 어떻게 될까? 먼저 트랜잭션 범위 내에서 비동기 메서드를 호출할 경우, 비동기로 실행되는 로직에는 트랜잭션이 적용되지 않는다.
그 이유를 살펴보자.
public class JpaTransactionManager extends AbstractPlatformTransactionManager implements ResourceTransactionManager, BeanFactoryAware, InitializingBean {
...
protected Object doGetTransaction() {
JpaTransactionObject txObject = new JpaTransactionObject();
txObject.setSavepointAllowed(this.isNestedTransactionAllowed());
EntityManagerHolder emHolder = (EntityManagerHolder)TransactionSynchronizationManager.getResource(this.obtainEntityManagerFactory());
if (emHolder != null) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Found thread-bound EntityManager [" + emHolder.getEntityManager() + "] for JPA transaction");
}
txObject.setEntityManagerHolder(emHolder, false);
}
if (this.getDataSource() != null) {
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(this.getDataSource());
txObject.setConnectionHolder(conHolder);
}
return txObject;
}
}
Java
복사
먼저 JPA의 트랜잭션을 관리하는 JpaTransactionManager를 살펴보면, doGetTransaction 메서드 내에서 TransactionSynchronizationManager를 통해 JDBC 연결 리소스를 홀딩한다.
TransactionSynchronizationManager는 스레드 별로 리소스 및 트랜잭션 동기화를 관리하는 객체이다. 그내부를 살펴보면,
public abstract class TransactionSynchronizationManager {
private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations = new NamedThreadLocal("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName = new NamedThreadLocal("Current transaction name");
private static final ThreadLocal<Boolean> currentTransactionReadOnly = new NamedThreadLocal("Current transaction read-only status");
private static final ThreadLocal<Integer> currentTransactionIsolationLevel = new NamedThreadLocal("Current transaction isolation level");
private static final ThreadLocal<Boolean> actualTransactionActive = new NamedThreadLocal("Actual transaction active");
...
}
Java
복사
이와 같이 모든 필드를 ThreadLocal을 통해 관리한다.
ThreadLocal은 Java에서 지원하는 스레드 안전한 변수를 선언하는 기술로, 멀티 스레드 환경에서 각각의 스레드에 별도의 저장공간을 할당하여 동일한 변수를 각 스레드마다 별도의 상태를 가지도록 도와준다.
public class ThreadLocal<T> {
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
Java
복사
그 원리는 Thread를 key로 사용하는 Map을 저장하여, 각 Thread마다 서로 다른 값을 저장하도록 지원한다. 정리하자면, 말 그대로 해당 스레드만 접근할 수 있는 특별한 저장소를 의미한다.
위처럼 TransactionSynchronizationManager가 트랜잭션 관련 리소스를 ThreadLocal로 관리하기 때문에, 비동기로 별도의 스레드에서 실행되는 로직에는 해당 트랜잭션 정보에 대해서 접근할 수 없다.
이와 같은 이유로 비동기로 실행되는 메서드에서 예외를 던지더라도 트랜잭션에는 전혀 영향을 미치지 않는다. 또한, 트랜잭션 내에서 이미 호출된 비동기 메서드는 트랜잭션이 실패하여 롤백 되더라도 영향 받지 않고 별도의 스레드에서 독립적으로 수행된다.
비동기 메서드에 트랜잭션 적용하기
위에서 언급했듯이 비동기 메서드는 트랜잭션 정보를 확인할 수 없다.
@Async
@Transactional
public void asyncOperation() {
...
}
Java
복사
때문에 이처럼 Async와 Transactional을 같이 묶는다면, 해당 비동기 처리 로직이 별도의 트랜잭션에서 처리가 될 뿐이고 해당 비동기 메서드를 호출한 트랜잭션과는 무관하게 동작한다.
다만 여기서 추가적으로 확인해야할 포인트는 위와 같이 둘 다 AOP를 사용하는 @Async 애노테이션과 @Transactional 애노테이션이 함께 적용된다면, 어떻게 동작할 지를 알아볼 필요가 있다.
위에서 우리가 살펴본 동작 과정을 생각해보면, 트랜잭션 적용 이후 비동기 메서드를 실행한다면 ThreadLocal로 관리되는 트랜잭션 정보를 읽지 못하기 때문에 제대로 동작하지 않을 것이다. 때문에 이처럼 두 개 이상의 트랜잭션이 적용된 경우에는 그 실행 순서가 중요하다.
@Async 애노테이션 적용 시 호출되는 어드바이스인 AsyncExecutionInterceptor를 보면,
public class AsyncExecutionInterceptor extends AsyncExecutionAspectSupport implements MethodInterceptor, Ordered {
...
public int getOrder() {
return Integer.MIN_VALUE;
}
}
Java
복사
실행순서를 결정하는 Order 값으로 Integer.MIN_VALUE를 반환한다.
@Transactional 애노테이션의 어드바이스에 적용되는 TransactionSynchronization 인터페이스 내부를 보면,
public interface TransactionSynchronization extends Ordered, Flushable {
...
default int getOrder() {
return Integer.MAX_VALUE;
}
}
Java
복사
이와 같이 order로 Integer.MAX_VALUE 값을 반환한다.
이처럼 여러 AOP 애노테이션이 적용될 때 트랜잭션은 가장 먼저, 비동기는 가장 나중에 처리될 것을 예상할 수 있다.
추가적으로 위의 예시처럼 AOP가 적용된 여러 애노테이션이 사용된다면, 각 애노테이션마다 프록시를 생성하는 것이 아니라 단 1개의 프록시를 생성하고 그 내부에 위처럼 여러 어드바이스를 두어 그 순서에 따라 실행시킨다.
그 이유로는
1.
각 AOP 애노테이션마다 프록시 객체로 생성 시 그만큼 메모리 사용량과 메서드 호출 시 발생하는 오버헤드가 커진다.
2.
또한 프록시 객체 내부에서 실행 순서를 관리하는 것에 비해 여러 개의 프록시 객체를 두면 그 실행 순서를 관리하기가 복잡해진다.
3.
그리고 단일 프록시에서 모든 어드바이스를 관리하게 되면, 예외 처리나 후처리 로직을 일관되게 적용할 수 있고 트랜잭션 롤백이나 리소스 정리 작업을 더 안전하게 처리할 수 있다.
이러한 이유로 스프링은 여러 AOP 애노테션을 하나의 프록시 내에서 여러 개의 어드바이스로 관리한다.
TransactionalEventListener
TransactionalEventListener란?
하지만 비동기 메서드를 호출하는 로직과 트랜잭션을 연결하여 처리할 필요가 있는 상황이 발생할 수 있다. 이를 해결하는 방법으로는 TransactionalEventListener를 통해 이벤트 발행 - 이벤트 리스너 형태로 처리하면 트랜잭션을 이어서 관리하는 것이 가능하다.
@Service
@RequiredArgsConstructor
public class testService {
private final ApplicationEventPublisher publisher;
@Transactional
public void event() {
publisher.publishEvent(new testEvent());
}
}
Java
복사
이와 같이 이벤트를 발행하고,
@Component
public class TestEventHandler {
@Async
@TransactionalEventListener
public void eventOperation() {
...
}
}
Java
복사
@TransactionalEventListener 애노테이션이 달린 이벤트 리스너를 통해 해당 이벤트를 처리하면 된다.
TransactionalEventListener는 EventListener와 달리 트랜잭션 동작을 인식하는 EventListener이다. 때문에 트랜잭션이 없다면 TransactionalEventListener는 동작하지 않는다.
TransactionalEventListener Phase
TransactionalEventListener는 아래의 4가지 Phase를 설정하여 동작을 지정할 수 있다.
•
TransactionPhase.BEFORE_COMMIT
◦
기본 설정값(default)으로, 이전 트랜잭션의 commit 직전에 수행된다.
•
TransactionPhase.AFTER_COMMIT
◦
이전 트랜잭션의 commit 직후에 수행된다.
•
TransactionPhase.AFTER_ROLLBACK
◦
이전 트랜잭션이 rollback이 발생한 시점에 수행된다.
•
TransactionPhase.AFTER_COMPLETION
◦
트랜잭션이 완료(commit 혹은 rollback)된 직후에 수행된다.
TransactionalEventListener 동작 원리
그렇다면 위에서는 비동기에 트랜잭션이 걸리지 않았는데, TransactionalEventListener는 트랜잭션을 인식할 수 있는 이유에 대해서 살펴보자.
스프링은 TransactionSynchronization 인터페이스를 통해서 트랜잭션의 각 단계별 콜백을 관리하는데,
public class TransactionalApplicationListenerMethodAdapter extends ApplicationListenerMethodAdapter implements TransactionalApplicationListener<ApplicationEvent> {
...
public void onApplicationEvent(ApplicationEvent event) {
if (TransactionSynchronizationManager.isSynchronizationActive() && TransactionSynchronizationManager.isActualTransactionActive()) {
TransactionSynchronizationManager.registerSynchronization(new TransactionalApplicationListenerSynchronization(event, this, this.callbacks));
} else if (this.fallbackExecution) {
if (this.getTransactionPhase() == TransactionPhase.AFTER_ROLLBACK && this.logger.isWarnEnabled()) {
this.logger.warn("Processing " + event + " as a fallback execution on AFTER_ROLLBACK phase");
}
this.processEvent(event);
} else if (this.logger.isDebugEnabled()) {
this.logger.debug("No transaction is active - skipping " + event);
}
}
}
Java
복사
위와 같이 TransactionalApplicationListenerMethodAdapter에서 트랜잭션 여부와 활성 여부를 판단 후에, TransactionalApplicationListenerSynchronization를 등록하며 트랜잭션 콜백으로 주입하여 처리한다.
class TransactionalApplicationListenerSynchronization<E extends ApplicationEvent> implements TransactionSynchronization {
private final E event;
private final TransactionalApplicationListener<E> listener;
private final List<TransactionalApplicationListener.SynchronizationCallback> callbacks;
public TransactionalApplicationListenerSynchronization(E event, TransactionalApplicationListener<E> listener, List<TransactionalApplicationListener.SynchronizationCallback> callbacks) {
this.event = event;
this.listener = listener;
this.callbacks = callbacks;
}
public int getOrder() {
return this.listener.getOrder();
}
public void beforeCommit(boolean readOnly) {
if (this.listener.getTransactionPhase() == TransactionPhase.BEFORE_COMMIT) {
this.processEventWithCallbacks();
}
}
public void afterCompletion(int status) {
TransactionPhase phase = this.listener.getTransactionPhase();
if (phase == TransactionPhase.AFTER_COMMIT && status == 0) {
this.processEventWithCallbacks();
} else if (phase == TransactionPhase.AFTER_ROLLBACK && status == 1) {
this.processEventWithCallbacks();
} else if (phase == TransactionPhase.AFTER_COMPLETION) {
this.processEventWithCallbacks();
}
}
...
}
Java
복사
실행 중인 트랜잭션에 대한 콜백으로 EventListener를 등록하고, 위와 같이 각 Phase에 따른 동작을 콜백으로 실행시킨다.


