
REST API 개발 시 주의사항
엔티티의 외부 노출 금지
@GetMapping("/api/v1/members")
public List<Order> ordersV1() {
List<Order> all = orderRepository.findAllByString(new OrderSearch());
return all;
}
Java
복사
위와 같이 엔티티 자체를 반환하거나 엔티티를 입력으로 받는 경우 여러 문제를 발생시킬 수 있어, 가급적 엔티티를 외부에 직접 노출하는 것은 좋지 않다. 엔티티를 외부에 노출함으로써 발생하는 문제들은 다음과 같다.
•
요청을 받을 때 엔티티를 통해 받게 되면, 값 검증(Validation)이 필요한 경우에 엔티티 필드에 @NotEmpty나 @NotBlank와 같은 검증 애노테이션이 붙게 된다. 또한 다른 요청에서는 해당 값에 검증이 필요없는 경우에도, 일부 요청에서 검증이 필요하기 때문에 검증을 수행하는 경우가 있을 수 있다.
•
엔티티의 필드명이 바뀌거나 새로운 필드가 추가되거나 일부 필드가 삭제되는 등의 변경이 발생한다면, 해당 엔티티를 반환값으로 사용하는 요청의 API 스펙 자체가 바뀌게 되어 재조정해야한다.
•
연관 관계를 가지는 엔티티를 반환하게되면, 자바의 Serializer에서는 연관된 엔티티까지 가져와서 직렬화를 하게 된다. 만약 이 때 지연 로딩으로 설정되어 있다면 에러가 발생하게 되고, 이를 해결하기 위해서는 Hibernate5Module과 같은 별도의 모듈을 설치하여 사용해야한다.
•
연관 관계의 지연로딩을 어떻게 잘 해결했다고 하더라도, 양방향 연관 관계로 묶여있다면 A 직렬화 → 연관 관계로 B 직렬화 → 연관 관계로 A 직렬화 → … 와 같이 무한 루프에 빠지게 되어 스택 오버플로우가 발생한다. 이런 상황을 막기 위해서는 추가적으로 @JsonIgnore와 같은 직렬화를 막는 애노테이션을 추가해야한다. 이로 인해 엔티티 간의 상호 의존관계가 발생한다.
•
위에서 언급만 문제점들에서 @NotEmpty나 @NotBlank, @JsonIgnore 등 여러 프레젠테이션 계층을 위한 로직이 엔티티 내부에 들어가게 된다.
이런 문제점들로 인해 엔티티는 최대한 외부에 노출하지 않는 편이 좋고, REST API 개발 환경에서는 다음과 같이 DTO를 통해 반환하는 것이 좋다.
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
return result;
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
...
}
}
Java
복사
반환은 가급적 객체로
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
return result;
}
Java
복사
엔티티를 그대로 반환하는 것을 해결했지만, 반환값을 List와 같은 컬렉션으로 반환하는 것도 문제가 있다.
해당 요청의 반환값은 Serializer에 의해 아래와 같이 변환된다.
[
{
"orderId" : 1,
"name" : "주문",
"orderDate" : "2024-02-09T13:15:23.02394",
"orderStatus" : "CANCELED",
"Address" : {
"city" : "서울",
"street" : "asdf",
"zipcode" : "1111"
}
},
{
...
}
]
Java
복사
하지만 이와 같은 형태로 API 스펙을 확정지으면, 추후 데이터를 확장하는데 큰 어려움을 겪게된다. 위의 예시에서는 유저가 요청한 전체 주문 수나 유저의 정보 등을 추가해서 보내야 한다면, API를 새로 작성해야하게 되는 것이다. 이처럼 데이터를 반환할 때는 List나 Map처럼 컬렉션으로 반환하면 데이터를 더 이상 확장 할 수 없어, 유연성이 떨어지게 된다.
@GetMapping("/api/v2/simple-orders")
public SimpleOrderListDto ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
SimpleOrderListDto simpleOrderListDto = new SimpleOrderListDto(result);
return simpleOrderListDto;
}
@Data
@AllArgsConstuctor
static class SimpleOrderListDto {
private List<SimpleOrderDto> result;
}
Java
복사
이러한 이유로 API 응답으로 컬렉션 데이터를 반환할 때는, 이처럼 항상 객체로 감싼 형태로 반환하는 것이 좋다. 이렇게 작성하면 데이터 확장이 용이하여, 추후 추가적인 데이터를 보내야하는 상황에서 간단하게 필드만 추가하여 API를 수정할 수 있다.
~ToOne 성능 최적화
Fetch Join으로 N+1 문제 해결
연관 관계 로딩 전략을 EAGER로 설정한다면 의도치 않은 쿼리가 발생하고 성능 최적화가 불가능하여 가급적 LAZY 코딩을 사용해야한다.
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<SimpleOrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
return result;
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
...
}
}
Java
복사
하지만 LAZY 로딩을 설정해두면, 위와 같은 조회 쿼리는 Order 조회 → 순회하면 DTO 생성 시 각각 Member 조회, Delivery 조회로 1 + N + N 만큼의 쿼리가 발생하게 된다.
이러한 문제는 상황에 따라 조금 다를 수 있지만, 대부분 Fetch Join을 통해 해결할 수 있다.
// JPA 방식
public List<Order> findAllWithMemberDelivery() {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d", Order.class)
.getResultList();
}
// Spring Data JPA 방식
@Query("select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d")
public List<Order> findAllWithMemberDelivery();
Java
복사
이와 같이 JPQL을 통해서 Fetch Join으로 여러 엔티티를 쿼리 한 번에 영속성 컨텍스트로 들고오도록 작성하면 된다.
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllWithMemberDelivery();
List<SimpleOrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
return result;
}
Java
복사
이미 Fetch Join을 통해 이미 필요한 엔티티들을 전부 영속화 해두었기 때문에, 위 상황에서도 N + 1 문제가 발생하지 않아 성능적으로 개선된다.
JPA에서 DTO로 직접 조회
추가적인 조회 성능 최적화 방법으로 JPA에서 DTO로 직접 조회하는 방법이 있다.
@Repository
@RequiredArgsConstructor
public class OrderSimpleQueryRepository {
private final EntityManager em;
public List<OrderSimpleQueryDto> findOrderDtos() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.OrderSimpleQueryDto(" +
"o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o" +
" join o.member m" +
" join o.delivery d", OrderSimpleQueryDto.class)
.getResultList();
}
}
@Data
public class OrderSimpleQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate; //주문시간 private OrderStatus orderStatus;
private Address address;
public OrderSimpleQueryDto(Long orderId, String name, LocalDateTimeorderDate,
OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}
Java
복사
이 방식은 SQL을 직접 작성할 때처럼 원하는 값만 select에 넣어 선택하여 조회하는 방식이다. JPQL의 new 명령어를 사용해서 DTO로 즉시 변환하여 반환한다.
이러한 DTO 직접 조회 방식은 트레이드 오프가 있다.
•
필요한 데이터만 가져오기 때문에 성능상 이점이 있다.
•
해당 DTO에 딱 맞춰서 데이터를 조회하기 때문에, 다른 코드에서 사용할 수 없다(재사용성이 없다).
•
위 예시를 보면 알 수 있듯이 코드가 지저분해지고, API 스펙 자체를 레포지토리가 의존하게 된다.
SQL의 주된 성능 차이는 주로 Join 연산에서 발생하는데, 위 방식의 성능상의 이점은 네트워크에 더 적은 데이터를 보낸다는 점이다. 하지만 최근에는 네트워크가 많이 좋아져서 실질적인 성능상 이득은 미비하다.
이러한 이유로 select로 가져오는 데이터가 20~30개 되지만 그 중 2~3개 정도의 데이터만 사용하는 상황이거나 굉장히 자주 호출되는 API로 인해 극한의 최적화가 필요한 경우가 아니라면 웬만해서는 잘 사용되지 않는다.
주로 통계 데이터나 특수한 조회 목적으로 사용되고, 위의 예시처럼 별도의 DTO 조회 전용의 Repository를 만들어서 유지보수성을 최대한 끌어올려 사용한다.
추가적으로 이 방식보다 더 최적화가 필요하다면 JPA가 제공하는 네이티브 쿼리나, Spring JDBCTemplate을 사용해 직접 SQL을 호출하여 사용한다.
OneToMany 성능 최적화
일대다 관계와 Fetch Join
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAllByString(new OrderSearch());
List<OrderDto> result = orders.stream()
.map(SimpleOrderDto::new).toList();
return result;
}
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems;
public OrderDto(Order order) {
...
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.toList();
}
}
@Data
static class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
Java
복사
위 코드는 이전의 예시에서 일대다 관계까지 가져오도록 수정한 코드이다. 이와 같이 일대다 관계의 데이터까지 가져오는 경우, LAZY 로딩을 설정해두면 1 + N + N + N * M 쿼리가 발생하게 된다. 이전에 비해 훨씬 많은 수의 쿼리가 발생하니 성능 최적화가 반드시 이루어져야 한다.
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i", Order.class)
.getResultList();
}
Java
복사
마찬가지로 Fetch Join을 통해 데이터를 미리 조회해두면 해결이 되긴하지만, 이러한 일대다 관계의 Fetch Join의 경우 몇 가지 문제점들이 있다.
데이터 중복 발생
데이터베이스에서 일대다 연관 관계를 가지는 두 테이블을 Join하여 조회하면 다(N) 쪽 데이터 수에 맞춰서 레코드 개수가 출력된다. 이는 JPA에서도 마찬가지로 일대다 연관관계를 Fetch Join으로 불러오게되면, 다(N) 쪽의 데이터 개수에 맞춰서 전체 데이터 수가 증가하게 된다.
조회한 데이터가 이렇게 중복된 값을 가지고 있기 때문에 영속성 컨텍스트 내에 일(1) 쪽 엔티티가 여러 개 올라오게 되는데, 이를 위해서 DISTINCT 문을 추가해주어야 한다. JPA의 DISTINCT 문은 SQL에 DISTINCT를 추가하는 기능 외에도, 영속성 컨텍스트 내의 중복된 엔티티들을 제거해주는 기능도하여 이후 데이터를 순회할 때 중복되는 데이터가 없어진다.
페이징과 다중 컬렉션 조인 불가능
위에서 언급했듯이 일대다 컬렉션을 Fetch Join으로 불러오는 경우 조회되는 데이터 수가 증가하게 되므로, 페이징을 적용하기에는 데이터의 개수를 JPA가 예측할 수 없다. 때문에 JPA에서는 경고를 띄우며 모든 데이터를 메모리로 들고온 뒤 페이징을 수행하게 된다. 만약 데이터가 엄청 많다면 OutOfMemory 에러가 발생하여 큰 장애를 초래할 수 있기 때문에, 페이징과 Fetch Join을 함께 사용해서는 안된다.
최근의 Spring Data JPA에서는 별도의 CountQuery를 작성하여, 데이터 개수가 맞지 않더라도 직접 작성한 CountQuery의 데이터 개수로 전체 데이터 수를 결정하게 된다.
추가적으로 이러한 컬렉션 조인은 단 한 번만 수행할 수 있고, 두 개 이상의 컬렉션 조인은 불가능하다. 그 이유 또한 마찬가지로 컬렉션 조인 시 데이터 수가 증가하는데, 이를 두 번 이상 반복하여 조회하는 경우 데이터가 카르테시안 곱만큼 증가하게되어 기하급수적으로 많아진다. 때문에 JPA에서는 컬렉션 조인을 두 번 이상은 불가능하도록 막아두었다.
IN 절을 통한 최적화
Fetch Join 시 페이징이 불가능한 점과 컬렉션 조인은 두 번 이상 사용할 수 없지만, 페이징을 수행해야하거나 두 번 이상의 일대다 연관 관계가 필요한 상황이 있을 수 있다. 이러한 상황에서는 최적화 하는 방법은 다음과 같다.
1.
~ToOne 관계는 모두 Fetch Join으로 한 번에 조회(페이징이 필요하다면 수행)
2.
일대다 연관관계는 LAZY로딩을 통해 첫 조회 시 같이 가져오지 않도록 설정
3.
IN 절 조회를 통회 여러 조회 쿼리를 한 번으로 합쳐서 조회
•
spring.jpa.properties.hibernate.default_batch_fetch_size로 글로벌 설정
# application.yml
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
YAML
복사
•
@BatchSize 애노테이션으로 엔티티별 설정
// ~ToOne
@Entity
@BatchSize(200)
public class Item {
...
}
// OneToMany
@Entity
public class Order {
...
@BatchSize(100)
private List<OrderItem> orderItems = new ArrayList<>();
}
Java
복사
위와 같이 @BatchSize 애노테이션이나 프로퍼티에 default_batch_fetch_size를 설정해두면, 동일한 엔티티에 대해 반복적인 쿼리 발생 시, 아래처럼 JPA에서 여러 쿼리들을 IN 절을 통해 합쳐서 한 번에 조회해온다.
select
orderitems0_.order_id as order_id5_5_1_,
orderitems0_.order_item_id as order_it1_5_1_,
orderitems0_.order_item_id as order_it1_5_0_,
orderitems0_.count as count2_5_0,
orderitems0_.item_id as item_id4_5_0_,
orderitems0_.order_id as order_id5_5_0_,
orderitems0_.order_price as order_pr3_5_0_
from
order_item orderitems0_
where
orderitems0_.order_id in (
?, ?, ?, ?
)
SQL
복사
default_batch_fetch_size나 @BatchSize의 경우 적당한 크기를 골라야한다. 데이터베이스에 따라 IN 절 파라미터 개수를 최대 1000개로 제한하는 경우도 있기 때문에, 일반적으로 100 ~ 1000 사이의 값이 권장된다. 값이 크던 작던 메모리 사용량은 동일하고, 값이 작은 경우는 느리지만 순간적인 부하가 적고 값이 크면 빠르지만 순간적인 부하가 치솟을 수 있다. 결국 DB나 애플리케이션이 순간적인 부하를 얼마나 견딜 수 있는지에 따라 결정하면 된다.
Hibernate 6.2 이후
Hibernate 6.2 이후의 버전은 IN 절 대신 array_contains 문법을 사용한다.
... where array_contains(?, item.item_id)
SQL
복사
IN 절을 사용하면 파싱과 분석을 위해 복잡한 일을 수행하는데, 성능을 최적화하기 위해 이미 수행된 SQL 구문 자체를 내부에 캐싱하고 있다. IN 절은 데이터가 동적으로 변하면 SQL 구문 자체가 변하지만(IN 절의 파라미터 개수 변경), array_contains는 ? 내부의 바인딩 값만 변하고 SQL 문은 그대로이기 때문에 캐싱된 SQL 구문을 그대로 사용하여 더 빠르다.
// 서로 다른 SQL 파싱 구문
select ... where item.item_id in (1, 2)
select ... where item.item_id in (1, 2, 3)
// 동일한 SQL 파싱 구문
select ... where array_contains([1, 2], item.item_id)
select ... where array_contains([1, 2, 3], item.item_id)
SQL
복사
참고로 array_contains는 BatchSize에 맞춰 남은 자리에 null을 추가하는데, 이는 특정 DB에서 배열의 데이터 숫자가 같아야 최적화되기 때문으로 추정된다.
JPA에서 DTO 직접 조회
일대다 연관관계 또한 DTO를 통해 직접 조회하는 것이 가능하다.
@Data
@EqualsAndHashCode(of = "orderId")
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate,
OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}
@Data
public class OrderItemQueryDto {
@JsonIgnore
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}
Java
복사
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o" +
" join o.member m" +
" join o.delivery d", OrderQueryDto.class)
.getResultList();
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id = : orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getReultList();
}
Java
복사
public List<OrderQueryDto> findOrderQueryDtos() {
List<OrderQueryDto> result = findOrders();
result.forEach(o -> {
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId());
o.setOrderItems(orderItems);
});
return result;
}
Java
복사
JPA도 결국 데이터베이스에서 가져온 데이터의 레코드를 1줄씩 읽어서 처리하기 때문에, 한 번에 컬렉션 처리하는 것은 불가능하다. 때문에 위처럼 루트 쿼리 1회 조회 후 순회하면서 컬렉션 데이터를 조회하여 값을 채우도록 작성하면 DTO를 통해 조회할 수 있다.
마찬가지로 여기서도 N+1 문제가 발생하기 때문에 이 역시 IN 절을 통해 해결할 수 있다.
List<OrderQueryDto> result = findOrders();
List<Long> orderIds = result.stream()
.map(o -> o.getOrderId())
.collect(Collectors.toList());
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count)" +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(OrderItemQueryDto::getOrderId));
Java
복사
이와 같이 첫 조회로 가져온 데이터에서 식별자들만 따로 뽑아내어, IN 절에 넣어 한 번에 조회해온다. 이후 가져온 데이터를 가공하기 쉽게 Map으로 분류하고, 루트 쿼리 결과를 순회하면서 DTO를 반환할 값에 채워넣는 방식이다.
여기서 더 나아가 쿼리 1번으로 조회하는 방법도 존재한다.
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private Address address;
private OrderStatus orderStatus;
private String itemName;
private int orderPrice;
private int count;
...
}
Java
복사
이와 같이 첫 조회의 DTO에 컬렉션의 모든 필드들을 펼쳐서(flat) 넣어두고,
public List<OrderFlatDto> findAllByDto_flat() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count)" +
" from Order o" +
" join o.member m" +
" join o.delivery d" +
" join o.orderItems oi" +
" join oi.item i", OrderFlatDto.class)
.getResultList();
}
Java
복사
모든 값을 조인하여 조회한다.
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(), o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(), o.getItemName(), o.getOrderPrice(), o.getCount()), toList())))
.entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(), e.getKey().getName(), e.getKey().getOrderDate(),
e.getKey().getOrderStatus(), e.getKey().getAddress(), e.getValue()))
.toList();
Java
복사
이후 이와 같이 메모리 상으로 중복을 전부 제거하면서 루트 DTO와 컬렉션 DTO로 각각 변환하는 로직을 수행하면된다.
쿼리는 딱 1번만 발생한다는 장점이 있지만, 딱 보면 알 수 있듯이 애플리케이션에서 추가 작업을 많이 수행하고 해당 로직이 복잡하여 가독성이 그리 좋지 않다. 추가적으로 페이징도 불가능하며, 쿼리는 한 번이지만 여러 번의 Join으로 인해 오히려 쿼리 2번 발생하는 방식보다 성능이 더 안좋을 수 있다.
OSIV 성능 최적화
OSIV(Open Seesion In View)는 데이터베이스 커넥션을 언제까지 유지할 지에 대한 전략이다. Hibernate에서는 Open Session In View라 부르고, JPA에서는 Open EntityManger In View라 부른다.
OSIV ON
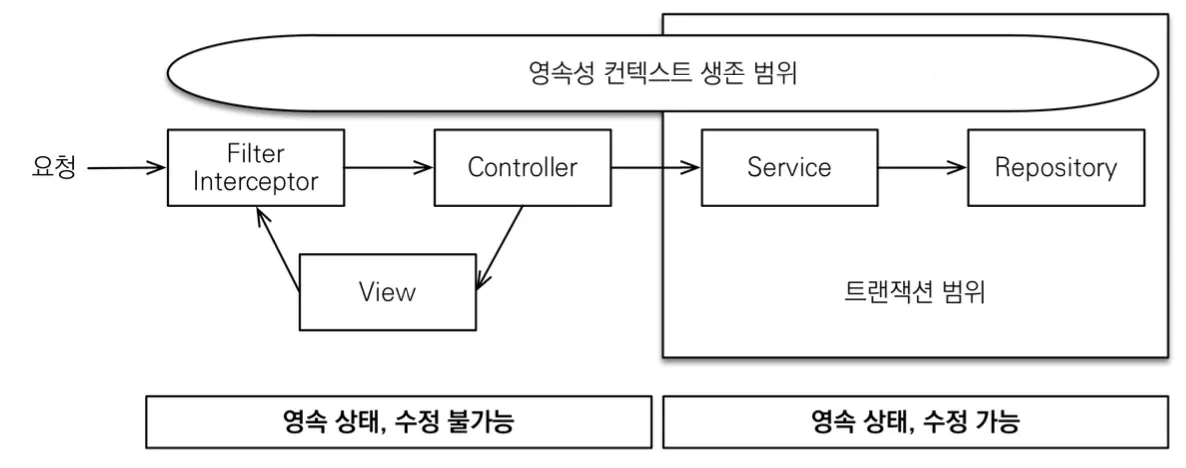
이 OSIV 전략은 데이터베이스 커넥션을 랜더링이 끝나는 순간까지 유지하여, 영속성 컨텍스트 생존 범위를 요청에 대한 응답이 완전히 끝날 때까지 늘리는 방식이다. 지연 로딩을 통해 프록시 객체를 실제 객체로 대체하는 방식은 영속성 컨텍스트가 살아있고 데이터베이스와 커넥션을 유지하고 있어야 가능하기 때문에, OSIV 설정을 켜두면 우리는 트랜잭션 범위 바깥에서도 지연 로딩된 프록시 객체를 사용할 수 있는 것이다.
우리가 OSIV에 대한 별다른 설정 없이 Spring 애플리케이션을 실행하면 open-in-view에 대한 warn이 한 가지 뜨는데, 이는 spring.jpa.open-in-view 설정의 기본값이 true이기 때문에 요청이 많을 때 커넥션 병목으로 장애까지 이어질 수 있음에 대한 경고이다.
OSIV OFF
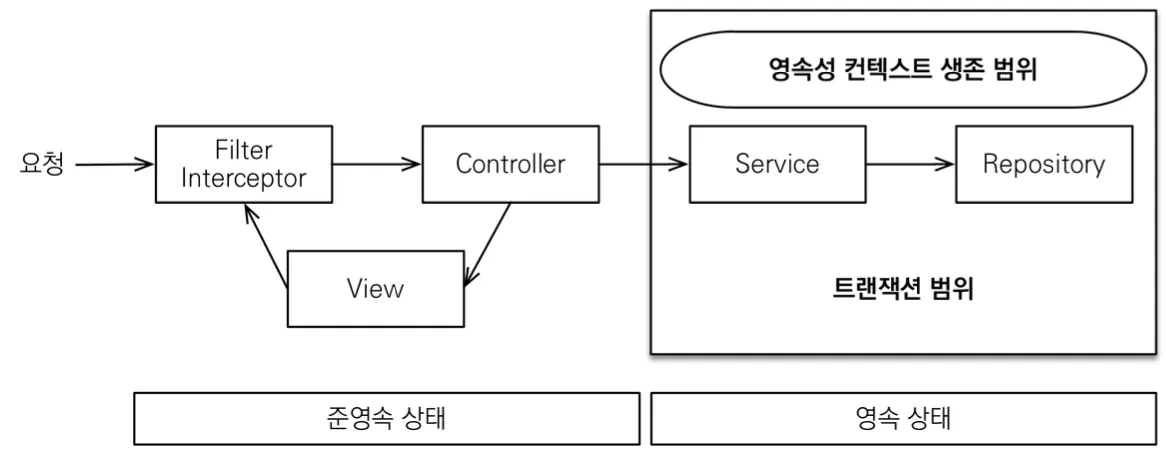
이렇게 OSIV 설정을 false로 꺼두게되면, 트랜잭션이 종료될 때 영속성 컨텍스트를 닫고 데이터베이스 커넥션도 반환하게 된다. 때문에 지연 로딩으로 생성된 프록시 객체들은 트랜잭션 범위 바깥에서 준영속 상태가 되고, 이를 실제 객체로 초기화 하려하면 에러가 발생한다.
OSIV를 끄면 이처럼 커넥션 리소스를 낭비하지 않고 성능 최적화에 도움이 되지만, 지연 로딩된 프록시 객체들은 반드시 트랜잭션 범위 내에서 초기화를 끝내야한다는 단점이 있다.
Command와 Query 분리
OSIV를 끈 상태에서 프록시 객체 초기와 같은 복잡성을 관리하는 좋은 방법으로 Command와 Query를 분리하는 방법이 있다.
일반적으로 비즈니스 로직은 특정 엔티티 몇 개를 등록하거나 수정하는 동작이 전부이므로 성능의상으로 크게 문제가 되지 않는다. 하지만 복잡한 화면을 출력하기 위한 쿼리는 화면에 맞추어 성능을 최적화하는 것이 중요하다. 하지만 복잡한 쿼리를 생성하는 복잡성에 비해, 조회하는 행위 자체는 핵심 비즈니스에 큰 영향을 주지 않는다. 이러한 이유로 크고 복잡한 애플리케이션을 개발한다면, Command와 Query의 관심사를 명확하게 분리하는 것이 유지보수 관점에서 충분히 유의미하다.
일반적으로 Command에 대한 핵심 비즈니스 로직을 가지고 있는 서비스와, 화면이나 API에 맞춰 조회만 수행하는 서비스를 분리한다. 그리고 조회만 수행하는 QueryService에 읽기 전용 트랜잭션을 사용해두고, 조회한 엔티티들(프록시 혹은 실제 엔티티)을 DTO로 변환하는 작업을 전부 QueryService 내에서 수행하는 것이다. 이와 같은 방법으로 OSIV를 끈 상태라도 트랜잭션 내에서 지연 로딩을 사용할 수 있게 된다.
일반적으로 고객들이 많이 사용하는 실시간 API는 OSIV를 끈 채로 사용하고, ADMIN처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV를 켠 채로 사용하는 것이 보편적이다.

