객체와 엔티티 매핑하기
•
@Entity
@Entity 애노테이션이 붙은 클래스는 JPA가 관리하며 엔티티라고 부른다. JPA를 사용해 DB의 테이블과 매핑하기 위해서는 클래스에 반드시 @Entity 애노테이션을 붙여주어야 한다.
@Entity 애노테이션을 사용하면 public 혹은 protected의 기본 생성자(파라미터 없는 생성자)가 반드시 있어야 하고, 내부 필드에 final이 붙은 필드가 없어야 한다. enum이나 interface, inner 클래스, final 클래스에는 사용할 수 없다.
기본적으로 클래스의 클래스 명을 그대로 사용하는데,
@Entity(name = "USER")
public class Member {
...
}
Java
복사
이와 같이 name 속성을 통해 별도로 지정하는 것도 가능하다. 이름이 동일한 클래스가 여러 개 있는 것이 아니라면, 가급적 클래스 명 그대로 사용하는 것을 권장한다.
•
@Table
@Table 애노테이션은 엔티티 클래스와 매핑할 테이블을 지정할 때 사용된다.
속성 | 기능 | 기본값 |
name | 매핑할 테이블 이름 | 엔티티 이름 사용 |
catalog | 데이터베이스 catalog 매핑 | |
schema | 데이터베이스 schema 매핑 | |
unqiueConstraints(DDL) | DDL 생성 시에 유니크 제약 조건 생성 |
데이터베이스 스키마 자동 생성하기
애플리케이션 실행 시 DDL을 자동으로 생성하는데, 데이터베이스 방언을 활용해 데이터베이스에 맞는 적절한 DDL 생성한다.
옵션 | 설명 |
create | 기존 테이블 삭제 후 다시 생성 |
create-drop | 기존 테이블 삭제 후 다시 생성 + 종료 시점에 테이블 DROP |
update | 변경된 내용만 반영 |
validate | 엔티티와 테이블이 정상적으로 매핑되었는지만 확인 |
none | DDL 사용하지 않음 |
이렇게 생성된 DDL은 개발 장비에서만 사용해야한다. 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용해야한다. alter를 통해 테이블을 수정하는 작업은 데이터의 양에 따라 시간이 굉장히 오래 걸릴 수도 있는데, 그 작업을 수행하는 동안 해당 테이블에는 락이 걸린다. 때문에 운영 서버에서 애플리케이션 실행 중에 자동으로 DDL을 생성하여 수행하는 것은 굉장히 위험한 작업이다. 운영 서버나 테스트 서버에 테이블 수정이 필요하다면, 직접 DDL 스크립트를 꼼꼼히 작성해서 수행하는 것이 권장된다.
개발 초기 : create 혹은 update
테스트 서버 : update 혹은 validate
스테이징, 운영 서버 : validate 혹은 none
•
DDL 생성 기능
◦
제약 조건 추가
@Column(nullable = false, length = 10)
◦
유니크 제약 조건 추가
@Table(uniqueConstraints = {@UniqueConstraint( name = “NAME_AGE_UNIQUE”, columnNames = {”NAME”, “AGE”} )})
이러한 DDL 생성 기능은 DDL 자동 생성 시에만 사용되고 JPA 실행 로직에는 영향을 주지 않는다.
필드 및 컬럼 매핑하기
•
@Column
컬럼 매핑
속성 | 설명 | 기본값 |
name | 필드와 매핑할 테이블의 컬럼 이름 | 객체의 필드 이름 |
insertable, updatable | 등록, 변경 가능 여부 | TRUE |
nullable(DDL) | null 값의 허용 여부를 설정한다. false 설정 시 DDL에 not null 제약 조건 추가 | TRUE |
unique(DDL) | @Table의 unqiueConstraints로도 설정할 수 있지만, 필드별로 간단하게 유니크 제약 조건을 걸 때 사용
컬럼 매핑을 통해 생성하면 제약 조건 이름이 임의의 값으로 설정되어 알기 어려워져 생각보다 잘 사용되지 않는다. | FALSE |
columnDefinition(DDL) | 필드의 자바 타입과 방언 정보를 사용해 데이터 베이스 컬럼 정보를 직접 설정
ex) varchar(100) default ‘EMPTY’ | |
length(DDL) | 문자 길이 제약 조건, String 타입에만 사용 | 255 |
percision, scale(DDL) | BIgDecimal 타입에서 사용(double, float에 적용 안됨)
precision : 소수점을 포함한 전체 자리수
scale : 소수점 이하 자리수 | precision=19
scale=2 |
•
@Enumerated
enum 타입 매핑
속성 | 설명 | 기본값 |
value | EnumType.ORDINAL : enum 순서를 데이터베이스에 저장
EnumType.STRING : enum 이름을 데이터베이스에 저장
ORDINAL은 거의 사용 하지 않는다.(enum을 알기도 어렵고 변경 시 항상 enum의 마지막에 추가해야 기존 값과 섞이는 오류가 발생하지 않기 때문) | EnumType.ORDINAL |
•
@Temporl
날짜(java.util.Date, java.util.Calendar) 타입 매핑
LocalDate와 LocalDateTime은 최신 하이버네이트에서 지원하여 생략 가능
속성 | 설명 | 기본값 |
value | TemporalType.DATE : 날짜, 데이터베이스의 date타입와 매핑
TemporalType.TIME : 시간, 데이터베이스의 time 타입과 매핑
TemporalType.TIMESTAMP : 날짜와 시간, 데이터베이스의 timestamp 타입과 매핑 |
•
@Lob
@Lob 애노테이션은 Large Object 약자로, 255 글자 이상의 문자열이나 용량이 큰 데이터 바이트 등을 데이터 베이스에 저장할 때 사용된다.
필드 타입이 String, char[], java.sql.CLOB 등의 타입이라면 CLOB 타입으로 매핑하고, 그 외의 byte[], java.sql.BLOB 등의 타입이라면 BLOB으로 매핑한다.
•
@Transient
특정 필드를 컬럼에 매핑하지 않겠다는 애노테이션으로, 해당 애노테이션이 붙은 필드는 데이터베이스에 저장하지 않고 조회할 수 없다.
주로 메모리상에서만 임시로 특정 값을 저장하고 싶을 때 사용된다.
기본 키(PK) 전략
기본 키는 @Id와 @GeneratedValue 애노테이션을 통해 매핑한다.
@Id 애노테이션만 사용하여 직접 할당하는 것이 아니라면 @GeneratedValue 애노테이션과 함께 사용하여, 여러 PK 전략들 중 하나를 선택해야한다.
기본 키는 null이 아니여야하고, 유일해야하고, 변해서는 안된다. 일반적으로 우리가 추가해서 사용하는 필드(컬럼)는 이런 조건을 만족하기 어려워, 대리키(대체키)를 사용하자. 권장되는 방법은 Long 타입이나 UUID의 대체키와 키 생성전략을 사용하는 것이다.
•
IDENTITY 전략
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
Java
복사
기본 키 생성을 데이터베이스에 위임하는 방법으로, 주로 MySQL, PostgrSQL, SQL Server, DB2에서 사용된다.(MySQL - AUTO_INCREMENT)
MySQL의 AUTO_INCREMENT는 데이터베이스에 INSERT SQL이 실행된 이후에나 ID 값을 알 수 있는데, JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL을 실행한다. 이러한 상황을 피하기 위해 IDENTITY 전략 사용 시 JPA는 em.persist() 시점에 즉시 INSERT SQL이 실행되고 DB에서 ID 값을 가져온다.
•
SEQUENCE 전략
@Entity
@SequenceGenerator(name = "MEMBER_SEQ_GENERATOR",
sequenceName = "MEMBER_SEQ",
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}
Java
복사
Oracle, PostgreSQL, DB2, H2 등의 데이터베이스에서 유일한 값을 순서대로 생성하는 데이터베이스 오브젝트(시퀀스)를 통해 값을 생성하여 ID로 사용하는 방식이다.
sequence 전략은 em.persist() 시점에 DB에 시퀀스 요청을 보내서 ID 값을 받아온다. 그렇다면 Sequence 전략은 새 엔티티를 저장할 때 매번 시퀀스 요청을 보내니까 여러 엔티티를 생성하는 경우 네트워크 비용이 더 들게 된다.
이에 대한 해결책이 아래의 allocationSize 속성이다. DB에서는 시퀀스가 50개를 미리 할당해두고, 50개의 ID에 대한 값들을 메모리로 가져와 엔티티를 생성 시 메모리에 저장해둔 ID를 꺼내서 할당하는 것이다. 이론상 allocationSize가 클수록 좋지만, 애플리케이션이 내려가게되면 ID 값들 사이에 구멍이 생기는 문제 때문에 50 정도를 기본값으로 두고 있다.
@SequenceGenerator 속성
속성 | 설명 | 기본값 |
name | 식별자 생성기 이름 | 필수 |
sequenceName | 데이터베이스에 등록되어 있는 시퀀스 이름 | hibernate_sequence |
initalValue | 시퀀스 DDL을 생성할 때 시작 값을 지정(DDL 생성 시에만 사용) | 1 |
allocationSize | 시퀀스 한 번 호출시마다 증가되는 수(성능 최적화에 사용)
데이터베이스 시퀀스 값이 1씩 증가하도록 설정되어 있다면 반드시 1로 설정해야한다. | 50 |
catalog | 데이터베이스 catalog, schema 이름 |
•
TABLE 전략
create table MY_SEQUENCE (
sequence_name varchar(255) not null,
next_val bigint,
primary key ( sequence_name )
)
SQL
복사
@Entity
@TableGenerator(name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCE",
pkColumnValue = "MEMBER_SEQ", allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.TABLE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;
}
Java
복사
키 생성 전용 테이블을 하나 만들어두고, 데이터베이스 시퀀스를 흉내내어 기본 키를 결정하는 전략이다. 모든 데이터베이스에 적용이 가능하지만, 성능 문제가 있다.
@TableGenerator 속성
속성 | 설명 | 기본값 |
name | 식별자 생성기 이름 | 필수 |
table | 키 생성 테이블명 | hibernate_sequences |
pkColumnName | 시퀀스 컬럼명 | sequence_name |
valueColumnName | 시퀀스 값 컬럼명 | next_val |
pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
initalValue | 초기 값, 마지막으로 생성된 값이 기준이다. | 0 |
allocationSize | 시퀀스 한 번 호출에 증가하는 수(성능 최적화 시 사용) | 50 |
catalog, schema | 데이터베이스 catalog, schema 이름 | |
uniqueConstraints(DDL) | 유니크 제약 조건 지정 |
•
AUTO 전략
기본 키를 데이터베이스 방언에 따라 자동으로 지정되는 전략이다. 별다른 설정이 없다면 기본 키 default 전략은 AUTO 전략으로 사용된다.
JPA 데이터 타입
JPA 데이터 타입에는 @Entity 애노테이션으로 정의되는 클래스인 엔티티 타입과, 단순히 값으로 사용되는 자바 원시 타입과 참조타입들인 기본값 타입이 있다.
@Entity
public class Member {
...
}
Java
복사
엔티티 타입은 데이터베이스의 테이블과 매핑되는 엔티티 객체이다. 데이터가 변해도 식별자를 통해 지속적으로 추적하는 것이 가능하다. 또한 엔티티 타입을 공유하는 것이 가능하고, 자기 자신의 생명 주기를 자신이 관리한다.
값 타입은 int, Integer, String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체를 말한다.
String name;
int age;
Java
복사
값 타입은 식별자가 없고 값만 있기 때문에, 변경 시 추적하는 것이 불가능하다.
그럼 기본값 타입의 여러 종류의 데이터 타입을 알아보자.
•
기본값 타입
Integer a = 10;
Integer b = a;
a = 20;
System.out.println(b); // b = 10
Java
복사
자바 원시 타입(int, double)이나 래퍼 클래스(Integer, Long), String 등을 말한다. 모든 기본값 타입은 생명주기를 해당 필드가 속한 엔티티에 의존하고, 값 타입은 공유가 되지 않고 항상 복사해서 사용된다.
•
임베디드 타입
@Embeddable
public class Period {
private LocalDateTime startDate;
private LocalDateTime endDate;
}
@Entity
public class Member {
...
@Embedded
private Period workPeriod;
}
Java
복사
임베디드 타입은 위처럼 @Embeddable 애노테이션과 @Embedded 애노테이션을 통해 새로운 값 타입을 직접 정의해서 사용할 수 있는 타입을 말한다. 주로 기본 값 타입을 모아서 만들기 때문에, 복합 값 타입이라고도 불린다. 임베디드 타입은 기본 생성자가 반드시 있어야하고, 임베디드 타입 역시 타입을 소유한 엔티티에 생명주기를 의존한다.
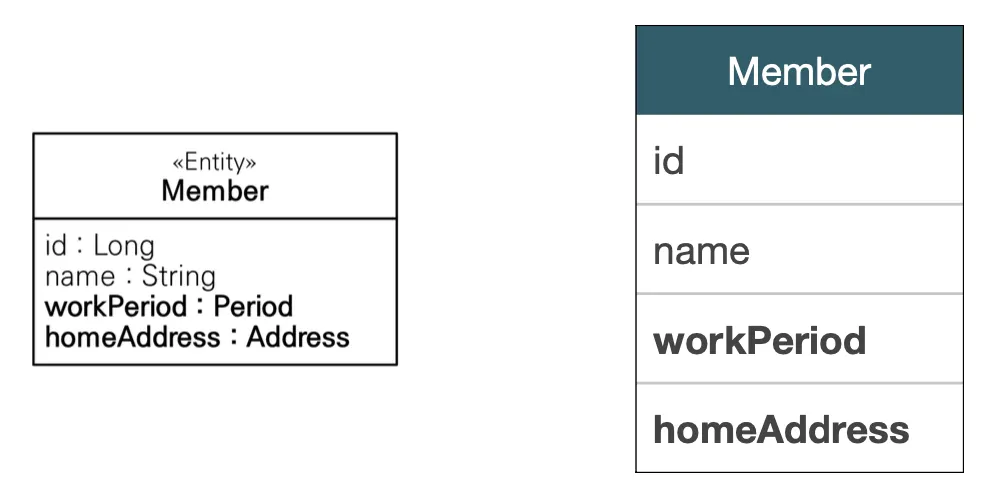
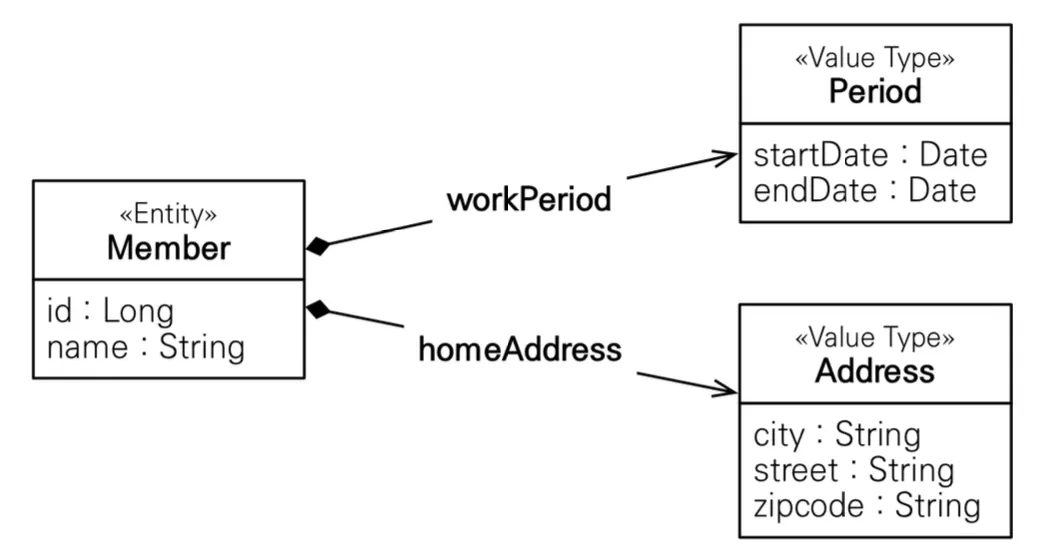
이러한 임베디드 타입을 사용하면 코드 재사용성이나 응집도를 높일 수 있다. 또한 임베디드 값 타입 내에 해당 값 타입에만 의미 있는 메소드를 만들 수도 있다.
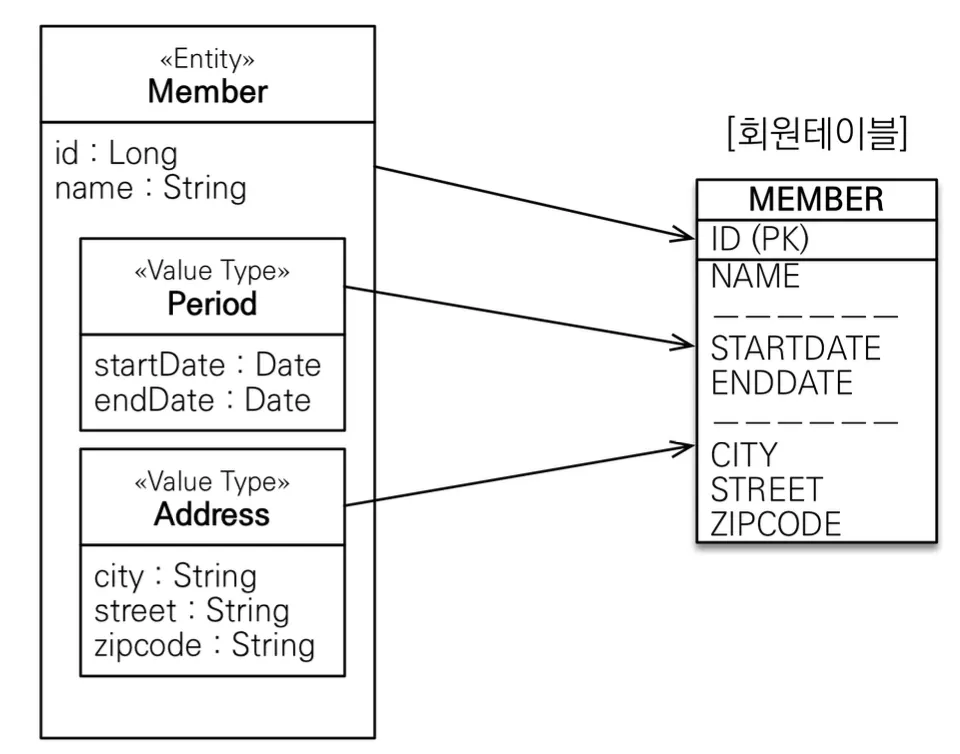
임베디드 타입은 사용하기 전과 후에 매핑하는 테이블이 동일하고, 임베디드 타입을 사용하면 객체와 테이블을 아주 세밀하게(find-grained) 매핑하는 것이 가능하다. 잘 설계한 ORM 애플리케이션은 이와 같은 특성들을 잘 활용해 매핑한 테이블 수보다 클래스 수가 더 많은 것이 특징이다.
임베디드 타입을 쓰다보면 하나의 엔티티에서 여러 값 타입의 이름 중 서로 같은 이름을 가지게 되는 경우가 있다. 이런 경우 @AttributeOverrides와 @AttributeOverride 애노테이션을 통해 컬럼명을 재정의할 수 있다. 또한 임베디드 타입의 값이 null이라면 매핑한 컬럼 전부에 null이 들어간다.
•
값 타입 컬렉션
@Entity
public class Member {
...
@ElementCollection
@CollectionTable(name = "FAVORITE_FOOD", joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
@Column(name = "FOOD_NAME")
private Set<String> favoriteFoods = new HashSet<>();
@ElementCollection
@CollectionTable(name = "ADDRESS_HISTORY", joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
@Column(name = "HOME_ADDRESS")
private List<Address> addressHistory = new ArrayList<>();
}
Java
복사
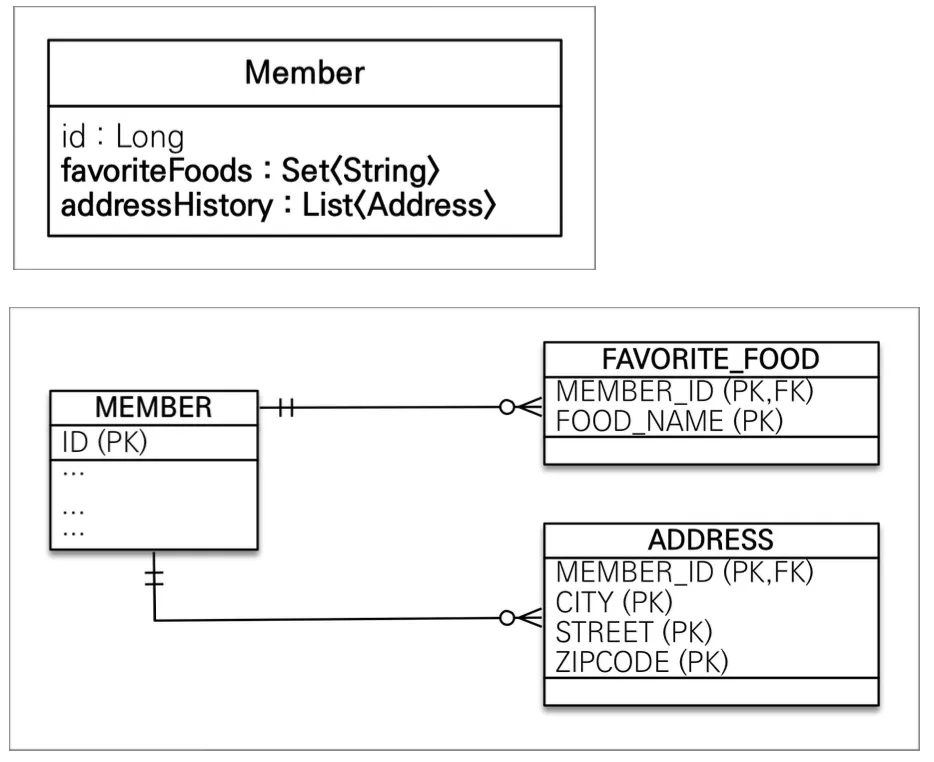
값 타입 컬렉션은 값 타입을 하나 이상 저장할 때 사용하며, @ElementCollection, @CollectionTable을 사용하여 구현할 수 있다. 데이터베이스에서는 컬렉션을 같은 테이블에 저장할 방법이 없기 때문에, 별도의 테이블에 저장하게 된다.
// 저장
Member member = new Member();
...
member.getFavoriteFoods().add("치킨");
member.getFavoriteFoods().add("피자");
member.getAddressHistory().add(new Address("old1", "street", "zipcode");
member.getAddressHistory().add(new Address("old2", "street", "zipcode");
em.persist(member);
// 조회
Member findMember = em.find(Member.class, member.getId());
Set<String> favoriteFoods = findMember.getFavoriteFoods(); // 지연로딩
List<Address> addressHistory = findMember.getAddressHistory(); // 지연로딩
Java
복사
위에서 보면 컬렉션에 대해 별도의 persist를 호출하지 않았다. 값 타입 컬렉션 역시 엔티티에 속한 값 타입이기 때문에, 생명주기를 엔티티에 의존하기 때문에 멤버를 수정하면 자동으로 반영된다.
// 수정
findMember.getFavoriteFoods().remove("치킨");
findMember.getFavoriteFoods().add("중식");
findMebmer.getAddressHistory().remove(new Address("old1", "street", "zipcode");
findMebmer.getAddressHistory().add(new Address("new", "street", "zipcode");
Java
복사
delete
from
ADDRESS
where
MEMBER_ID=?
insert
into
ADDRESS
(MEMBER_ID, city, street, zipcode)
values
(?, ?, ?, ?)
SQL
복사
값 타입은 식별자 개념이 없어 변경하면 추적이 어렵기 때문에, 모든 컬럼을 묶어서 기본 키를 구성한다. 때문에 이와 같이 값 타입 컬렉션은 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제 후 컬렉션에 있는 현재 값을 모두 다시 저장한다. 또한 모든 컬럼에 null을 받아서도 안되며 중복된 데이터를 저장하는 것도 안된다.
이러한 문제들 때문에 상황에 따라 값 타입 컬렉션 대신 일대다 연관관계를 고려해보는 것이 권장된다.
@Entity
public class AddressEntity {
@Id @GeneratedValue
privateLong id;
private Address address;
...
}
@Entity
public class Member {
...
@OneToMany(cascade = ALL, orphanRemoval = true)
@JoinColumn(name = "MEMBER_ID")
private List<AddressEntity> addressHistory = new ArrayList<>();
}
Java
복사
일대다 관계로 매핑하고, 영속성 전이(Cascade) + 고아 객체 제거(Orphanremoval) 속성을 통해 값 타입 컬렉션처럼 사용하는 것이다. 값 타입 컬렉션은 체크박스를 통해서 내가 좋아하는 여러 항목들 모두 받기 등 추적할 필요가 전혀 없는 상황에서만 사용하자.
값 타입과 불변객체, 값 타입의 비교
값 타입은 복잡한 객체를 조금이라도 단순화하기 위해 만든 개념이기 때문에, 값 타입을 최대한 단순하고 안전하게 사용해야한다.
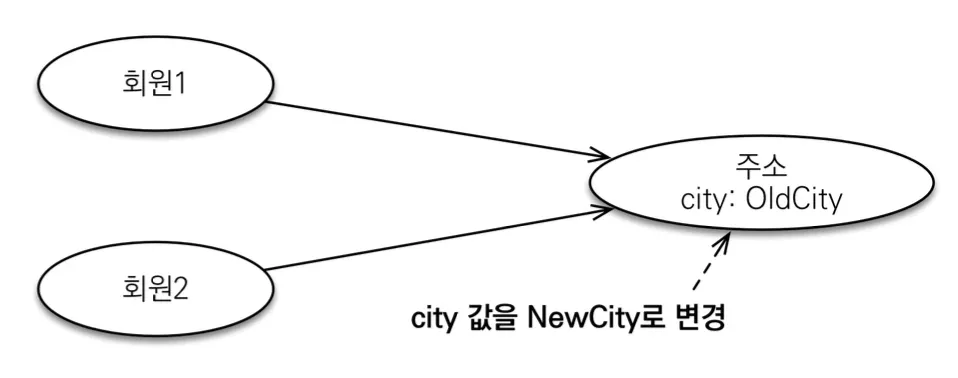
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면, 위처럼 원치 않게 값이 바뀌어버리는 부작용(side effect)이 발생한다.
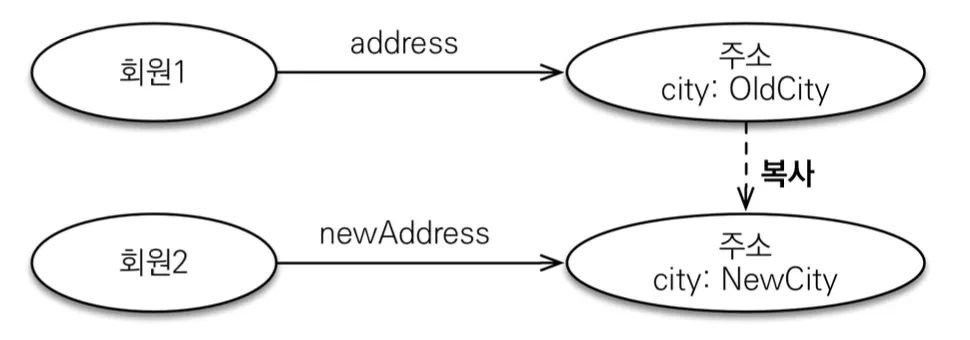
때문에 값 타입의 실제 인스턴스를 공유하는 것은 위험하고, 인스턴스의 실제 값을 복사하여 전달해야한다. 항상 값을 복사해서 이와 같이 공유 참조로 인해 발생하는 부작용을 피할 수 있다.

하지만 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입 아닌 객체 타입이다. 자바의 기본 타입에 값을 대입하면 복사해서 넣지만, 객체 타입은 참조 값을 직접 대입하는 것을 막을 방법이 없다. 때문에 임베디드 타입에서는 공유 참조를 피할 수 없다.
이러한 객체 타입의 공유 참조와 같은 부작용을 피하려면, 객체 타입을 생성 시점 이후 값을 절대 수정할 수 없는 불변 객체(immutable object)로 설계해야 한다. 오직 생성자로만 값을 설정하고, 수정자(setter)를 제공하지 않아 값을 바꿀 수 없도록 만드는 것이다. 우리가 사용하는 Integer나 String과 같은 클래스도 자바에서 제공하는 불변 객체이다.
값 타입을 비교할 때는 인스턴스가 다르더라도 그 내부의 값이 같다면 동일한 것으로 보아야한다.

•
동일성(identity) 비교 : 인스턴스의 참조 값을 비교하는 것으로, == 연산을 사용하여 비교한다.
•
동등성(equivalence) 비교 : 인스턴스의 값을 비교하는 것으로, equals()를 사용하여 비교한다.
값 타입은 a.equals(b)처럼 동등성 비교를 통해 내부의 값을 비교해야하고, 이를 위해 값 타입의 equals() 메서드를 적절하게 재정의(override)하여 내부의 모든 필드를 비교하도록 구현해두어야 한다.
값 타입들은 이러한 불변 객체 제약 조건과 비교 조건 등 고려해야할 것이 많기 때문에, 정말 값 타입이라고 판단될 때만 사용하고 엔티티와 값 타입을 혼동해서 엔티티를 값 타입으로 만들면 안된다. 식별자가 필요하며 지속해서 값을 추적해야하고, 변경할 필요가 있다면 값 타입이 아닌 엔티티로 만들어야한다.
연관관계 매핑
JPA를 통해 테이블을 엔티티로 객체처럼 사용할 수 있게 되었다. 하지만 테이블은 외래 키를 통해 연관된 테이블을 찾을 수 있는데, 객체는 참조를 통해 연관된 객체를 찾는다. 객체를 테이블에 맞추어 연관된 객체의 id를 저장해두는 것처럼 데이터 중심으로 모델링하면, 엔티티 객체를 객체 지향적으로 사용하기 어려워진다. 이를 해결해주는 것이 연관관계 매핑이다.
•
단방향 연관관계
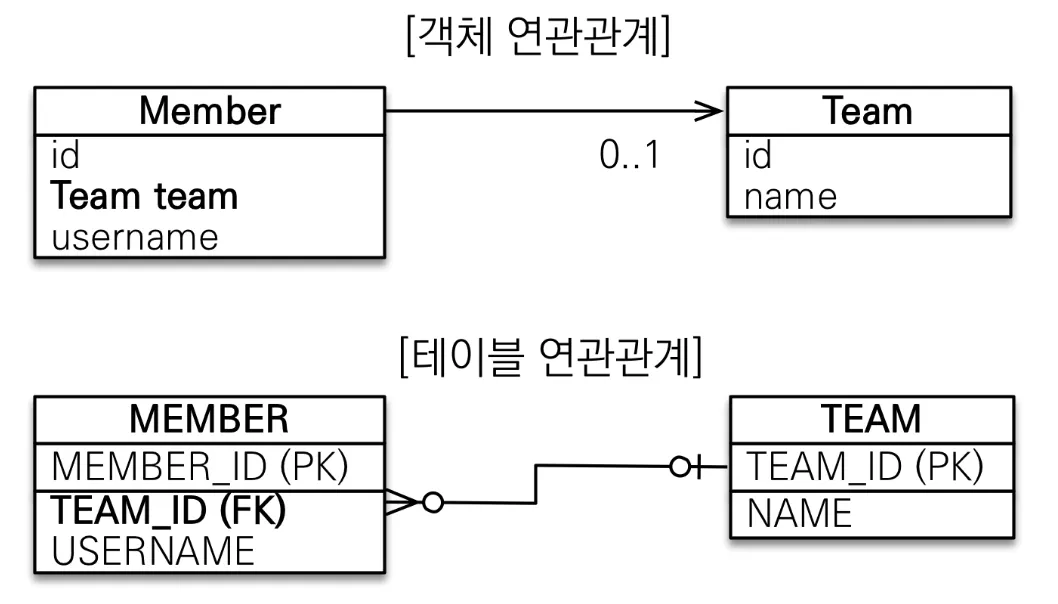
@Entity
public class Member {
@Id @GenerateValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(user = "USERNAME")
private String name;
@Column(name = "TEAM_ID")
private Lond teamId;
}
Java
복사
// 테이블 중심의 모델링
// 팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
// 회원 저장
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId()); // 객체 지향스럽지않은 모델링
em.persist(member);
// 테이블 중심의 그래프 탐색
Long teamId = member.getTeamId();
Team findTeam = em.find(Team.class, teamId);
Java
복사
이처럼 테이블 중심으로 모델링하게 되는 경우, 객체지향스럽지 않게 저장해야하고 조회도 객체지향스럽지 못하게 조회를 해야한다.
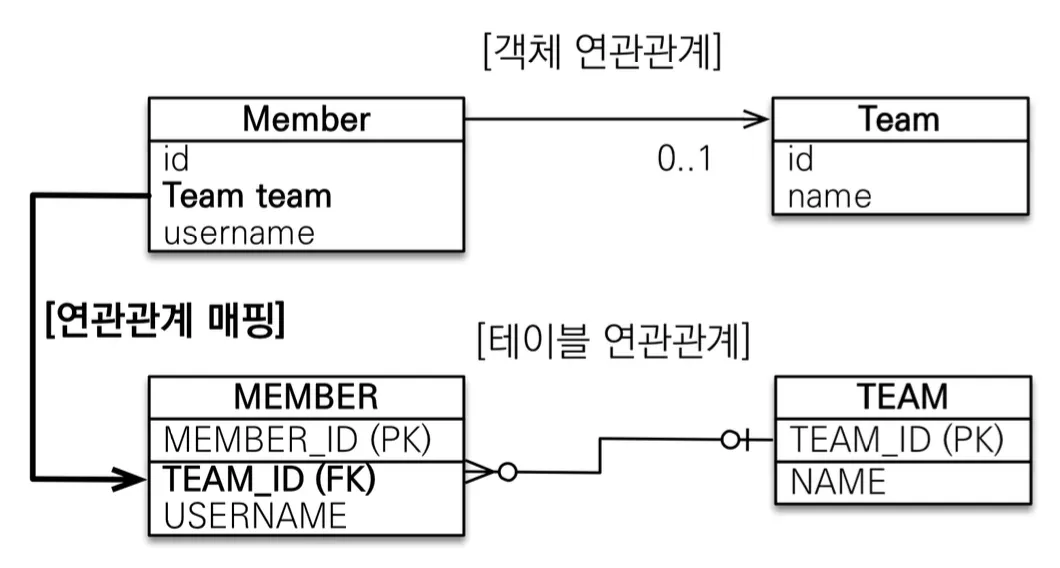
@Entity
public class Member {
@Id @GenerateValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(user = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
Java
복사
// 연관관계 저장을 통한 객체 지향 모델링
// 팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
// 회원 저장
Member member = new Member();
member.setName("member1");
member.setTeam(team); // 단방향 연관관계 설정으로 참조 저장 가능
em.persist(member);
// 참조를 통한 객체 그래프 탐색
Team findTeam = member.getTeam();
Java
복사
•
양방향 연관관계
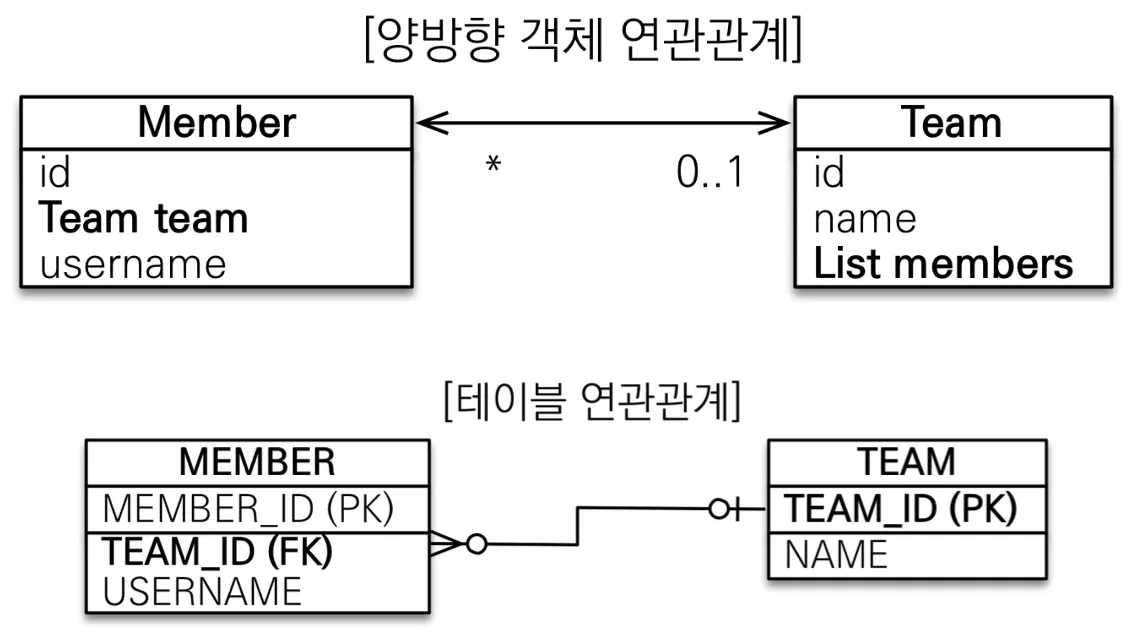
실제 객체는 위와 같이 서로 참조 관계를 넣어두면, 양쪽에서 참조로 객체 탐색하는 것이 가능하다. 하지만 참조 객체를 넣어두지 않는다면 객체를 탐색하는 것은 불가능하다. 반면 테이블에서는 FK를 통해 반대쪽이 필요한 경우, 방향과 관계없이 그냥 Join을 통해 불러오면 된다. 사실상 외래 키를 통한 Join으로 방향과 관계없이 불러 올 수 있는 것이다.
이와 같은 차이 때문에 객체에서는 서로 상대 객체를 필드로 넣어두고, 양방향 연관관계를 맺어 사용한다.
@Entity
public class Member {
@Id @GenerateValue
@Column(name = "TEAM_ID")
private Long id;
@Column(user = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID)
private Team team;
}
@Entity
public class Team {
@Id @GenerateValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
}
Java
복사
위에서 언급했듯이, 객체는 회원 → 팀의 단반향 연관관계와 팀 → 회원의 단방향 연관관계로 두 개의 객체 연관관계를 맺는다. 이러한 단방향 연관관계 2개를 통해 양방향 연관관계처럼 사용하는 것이다. 반면 테이블에서는 FK 한개로 회원  팀의 양방향 연관관계 1개만 맺고, FK를 통해 양쪽으로 Join하여 데이터를 가져올 수 있다.
팀의 양방향 연관관계 1개만 맺고, FK를 통해 양쪽으로 Join하여 데이터를 가져올 수 있다.
팀의 양방향 연관관계 1개만 맺고, FK를 통해 양쪽으로 Join하여 데이터를 가져올 수 있다.
이러한 차이 때문에 객체에서 이를 표현하는 과정에서 문제가 있었다.
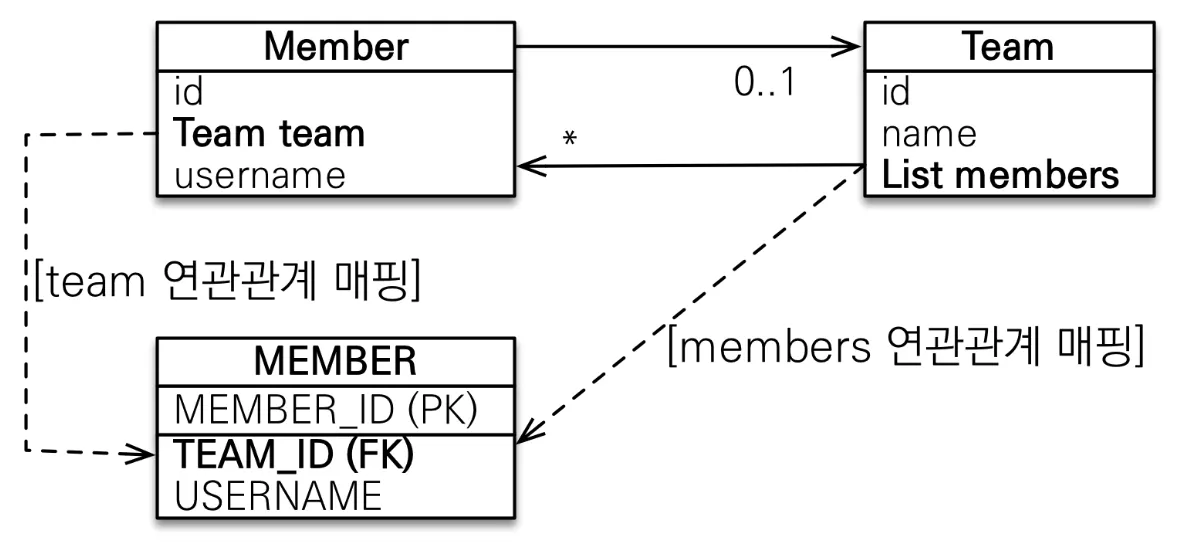
이러한 관계에서 Member 객체의 team을 수정 했을 때 Member 테이블의 FK를 수정해야 하는것과 Team 객체의 members를 수정했을 때 Member 테이블의 FK를 수정해야하는 것 중 어떤 것을 기준으로 삼아야할 지 명확하지 않았다. 하지만 이는 DB 입장에서는 FK 하나만 수정하면 되는 간단한 문제이다.
이를 해결하기 위해 연관관계의 주인이라는 개념이 생기게 되었다. 객체의 두 관계 중에 한 쪽을 연관관계의 주인으로 지정하고, 연관관계의 주인만 외래 키를 관리하도록 하고 주인이 아닌 쪽은 읽기만 가능하도록 한 것이다.
연관관계의 주인이 아닌 쪽에서 mappedBy를 사용하고, 이를 통해 연관관계를 맺은 상대 객체가 연관관계의 주인임을 나타낸다. mappedBy가 붙은 쪽에서는 연관관계의 주인이 아니기 때문에, 연관관계를 Join하여 조회하는 것만 가능하고 해당 참조 필드에 값을 넣어도 SQL이 발생하지만 DB에서는 아무 일도 발생하지 않는다.
// 역방향(주인이 아닌 방향) 데이터 설정 -> SQL은 발생하지만 DB에 저장 안됨
team.getMembers().add(member);
// 연관관계의 주인에서 데이터 설정 -> DB에 저장 됨
member.setTeam(team);
Java
복사
mappedBy는 어느 쪽에서든 사용 가능하지만, 가급적 외래 키를 가지는 쪽을 주인으로 정하는 것이 권장된다. 그 이유로는 외래 키가 아닌 쪽을 주인으로 지정하면, 수정하지 않은 테이블의 수정 쿼리가 발생할 수 있기 때문이다. 위의 관계에서는 Team의 Members를 수정했는데, Member 테이블의 수정 쿼리가 발생하는 꼴이다. 이는 개발자에게 혼돈을 유발하기도 하고, 추가적으로 성능 이슈도 있다. DB에서는 항상 Many 쪽에 FK를 가지기 때문에, 항상 Many 측을 연관관계의 주인으로 설정하는 것이 좋다.
•
양방향 연관관계에서 주의할 점
위 예시 코드에서 team.getMembers().add(member) 코드는 DB에는 아무 반영도 되지 않는다고 말했지만, 두 가지 이유에 있어서 이를 코드적으로 명시해주는 것이 좋다.
1.
영속성 컨텍스트의 1차 캐시 때문이다. 위의 add(member) 없이 team.getMembers()를 하게되면, flush, clear를 수행하면 상관이 없지만 그게 아니라면 member가 추가되지 않은 영속성 컨텍스트의 엔티티를 꺼내오기 때문에 값이 없다.
2.
객체 지향적으로 생각했을 때, 양쪽 모두 참조 필드가 있기 때문에 양 쪽에 모두 값을 추가해주는 것이 객체 지향적으로 올바른 동작이다. 이는 테스트 코드를 작성할 때에도 영향을 미칠 수 있다.
@Entity
public class Member {
...
// 연관관계 편의 메서드
public void changeTeam(team) {
this.team = team;
team.getMembers().add(this);
}
}
Java
복사
이러한 이유로 위와 같이 양방향을 모두 설정해주는 연관관계 편의 메서드를 생성하여 사용하자. 편의 메서드는 연관관계 주인과 관계없이 편한 쪽에 만들어서 사용해도 되지만, 둘 다 만들 경우 상호 참조로 인한 무한 루프에 빠지지 않도록 조심하자.
또한 양방향 매핑에서 toString(), lombok, JSON 생성 라이브러리 등에서 member.toString() → team.toString() → member.toString() → … 처럼 무한 루프에 빠질 수 있으니 주의하자.
사실 단방향만으로 이미 연관관계 매핑은 완료가 된 것과 같고, 양방향 매핑은 반대 방향으로 조회 기능이 추가된 것일 뿐이다. 그러니 가급적 단방향 매핑으로 설계를 끝내고, 이후 JPQL을 통한 역방향 탐색이 많을 때아 양방향 매핑이 필요해질 때만 추가하자. 그렇게 하더라도 테이블에는 영향이 전혀 없다.
•
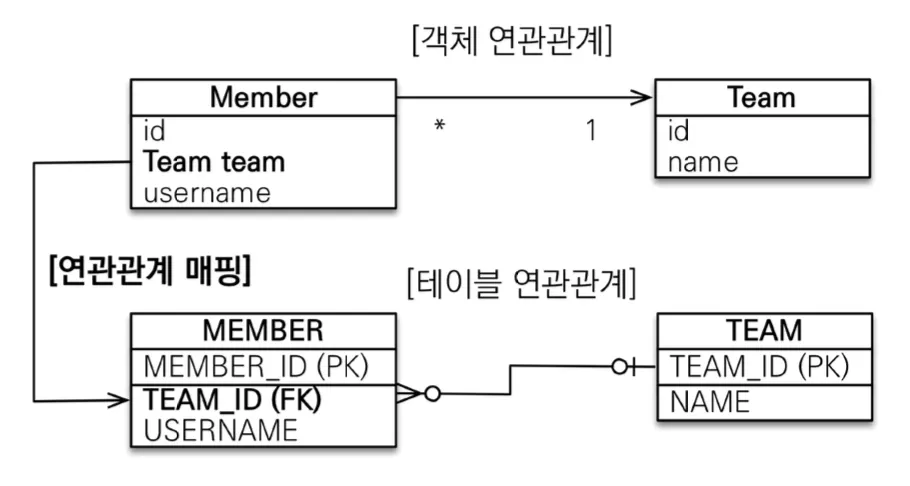
단방향 다대일(N:1) 연관관계
다(N) 쪽에서 외래 키를 가지고 있고 일(1) 쪽과 연관관계 매핑을 맺은 관계이다. 모든 관계 중 가장 많이 사용된다.
•
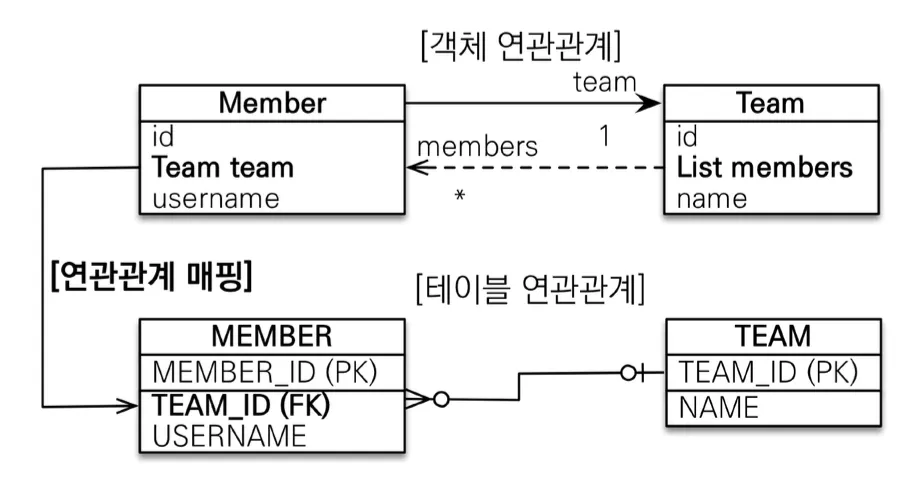
양방향 다대일(N:1) 연관관계
외래 키를 가진 쪽이 연관관계 주인이고, 일(1) 쪽에서도 참조 가능하도록 mappedBy로 지정한 관계이다.
•
단방향 일대다(1:N) 연관관계
일(1) 쪽에 외래 키를 넣고 다(N) 쪽과 연관관계 매핑을 맺은 관계이다.
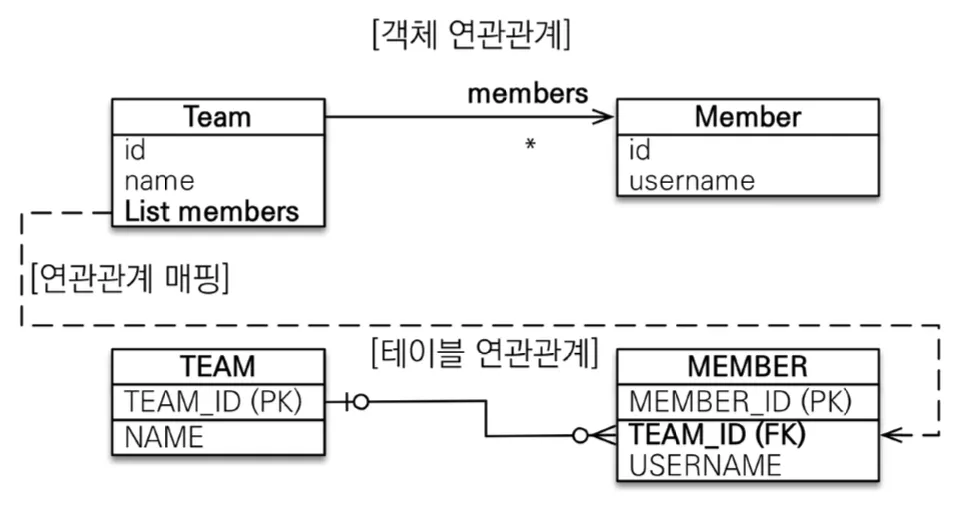
테이블에서는 항상 다(N) 쪽이 외래 키를 가지고 있기 때문에, 객체와 테이블 차이 때문에 반대편 테이블의 외래 키를 관리하게 되는 특이한 구조이다. @JoinColumn을 반드시 사용해야 하고, 사용하지 않으면 JPA 중간 테이블을 하나 새로 만들어버린다.
엔티티가 관리하는 외래 키가 다른 테이블에 있기 때문에 team을 수정해도 추가로 member의 Update SQL 발생한다. 이러한 이유로 권장되지 않으니, 가급적 일대다 단방향보다 다대일 양방향을 쓰도록 하자.
•
양방향 일대다(1:N) 연관관계
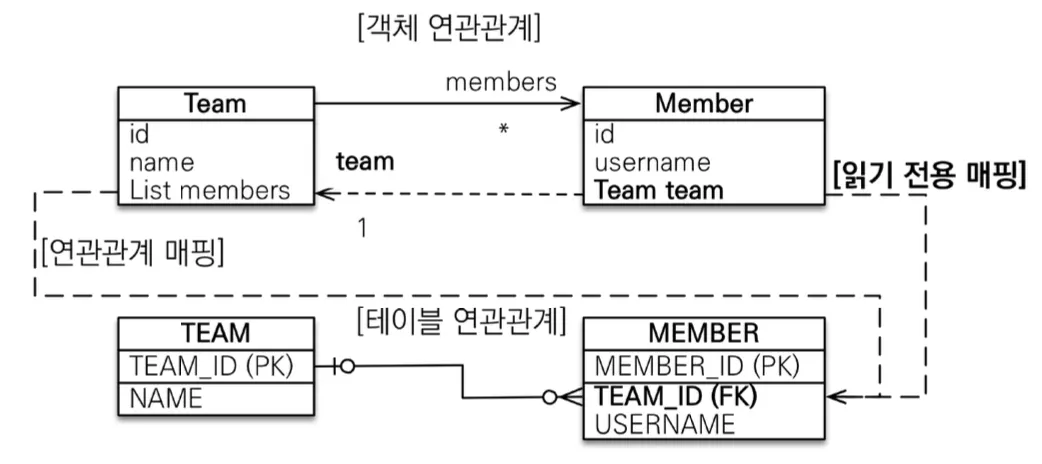
@JoinColumn(insertable=false, updatable=false)로 읽기 전용 필드로 만들어 임의로 양방향처럼 사용하는 방법으로, 공식적으로 JPA는 이런 매핑 방식을 지원하지 않는다. 그러니 다대일 양방향을 사용하자.
•
일대일(1:1) 연관관계
일대일 관계는 반대도 일대일 관계이기 때문에, 주 테이블이나 대상 테이블 중에 선택하여 외래 키를 두고 사용하는게 가능하다. 일대일 관계에서는 반드시 외래 키에 유니크 제약 조건을 걸어야한다.
1.
주 테이블에 외래 키 두기
주 객체가 대상 객체의 참조를 가지는 것처럼 주 테이블에 외래 키를 두고 대상 테이블을 찾는 방식이다. JPA 매핑이 편리하고 조회를 쉽게 할 수 있기 때문에, 성능상의 이점도 있고 주로 객체지향 개발자가 선호한다.
주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인이 가능하지만, 값이 없으면 외래 키에 null이 들어가야 한다는 문제가 있다.
단방향
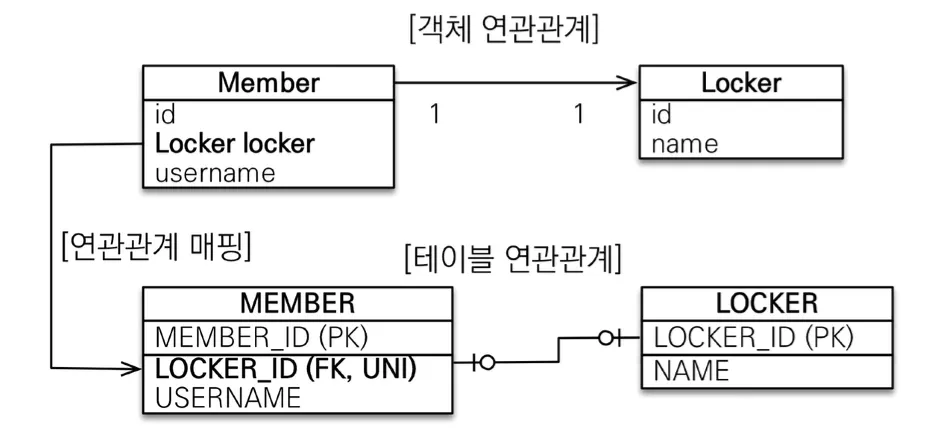
다대일(@ManyToOne) 단방향 매핑과 유사한 형태이다.
양방향
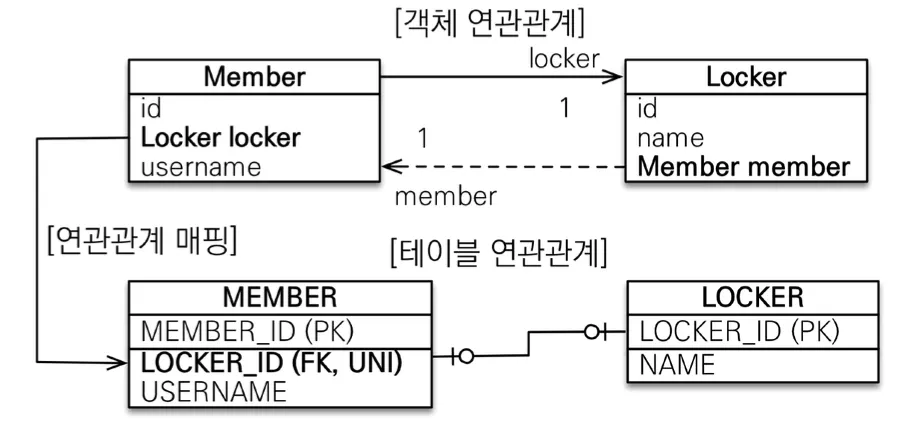
다대일 양방향 매핑처럼 외래 키가 있는 곳이 연관관계의 주인이고 반대편에 mappedBy를 적용해주면 된다.
2.
대상 테이블에 외래 키 두기
대상 테이블에 외래 키를 두고 주 테이블에 해당하는 엔티티에서 매핑을 지정하는 방식이다. 유니크 제약 조건만 해제하면 일대다 관계로 바꾸는 것이 편리하기 때문에, 전통적인 데이터베이스 개발자들이 선호한다. 단방향은 구현 불가능하기 때문에, 항상 양방향으로 구현해야한다.
주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조를 유지하면서 변경할 수 있지만, 프록시 기능의 한계로 인해 지연 로딩으로 설정해도 항상 즉시 로딩된다.
단방향
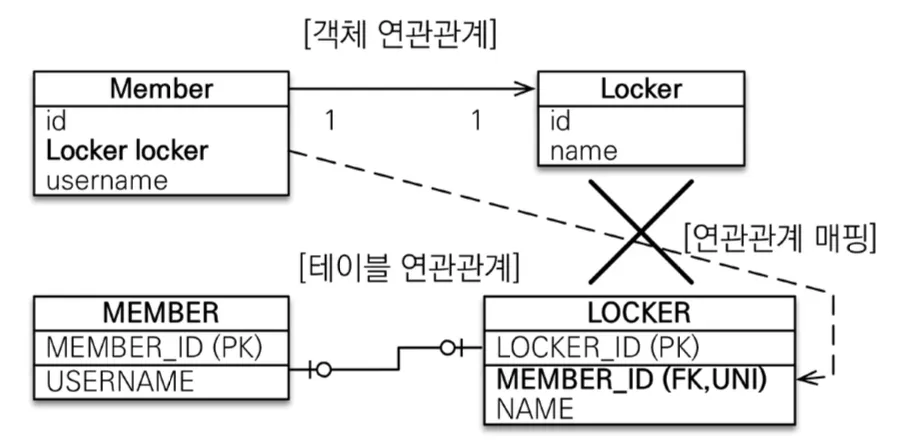
일대다(@OneToMany) 단방향 매핑처럼 JPA에서 공식적으로 지원하지 않는다. 일대다 단방향처럼 꼼수가 통하지도 않기 때문에, 구현하는게 불가능하다.
양방향
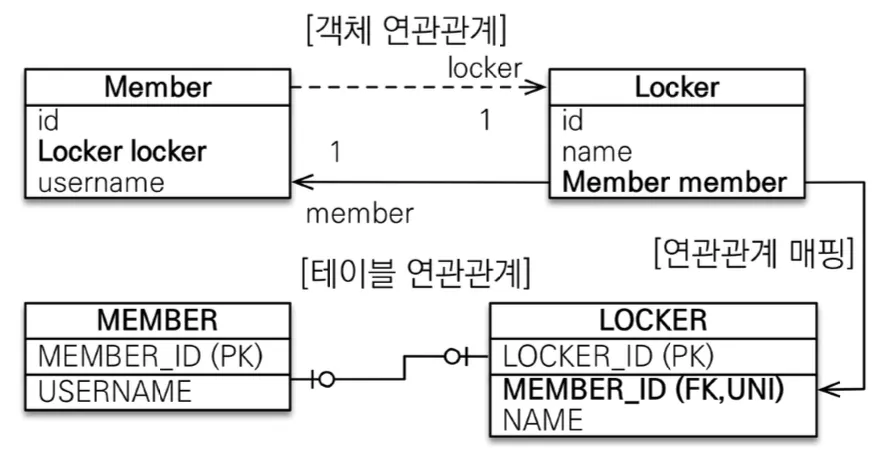
사실상 위의 주 테이블 일대일 양방향 매핑을 뒤집은 모양으로, 마찬가지로 외래 키가 있는 곳이 연관관계의 주인이다.
•
다대다(N:M) 연관관계
객체는 컬렉션을 통해 객체 2개로 다대다 관계 가능

정규화된 관계형 데이터베이스는 테이블 2개로 다대다 관계를 표현하는게 불가능하여, 연결 테이블을 추가해 일대다, 다대일 관계로 풀어내야 함
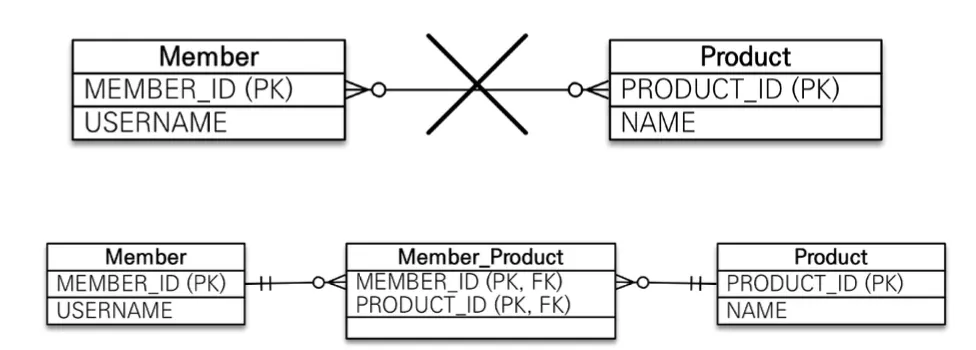
@ManyToMany와 @JoinTable을 통해 연결 테이블을 지정하여 다대다 매핑 단방향, 양방향 모두 가능하다. 하지만 이는 실무에서는 거의 사용되지 않는데, 주문 시간이나 주문 수량 등 연결 테이블에 추가적인 데이터가 필요한 경우가 많아 연결 테이블 자체를 새로운 엔티티로 만들어 사용한다.
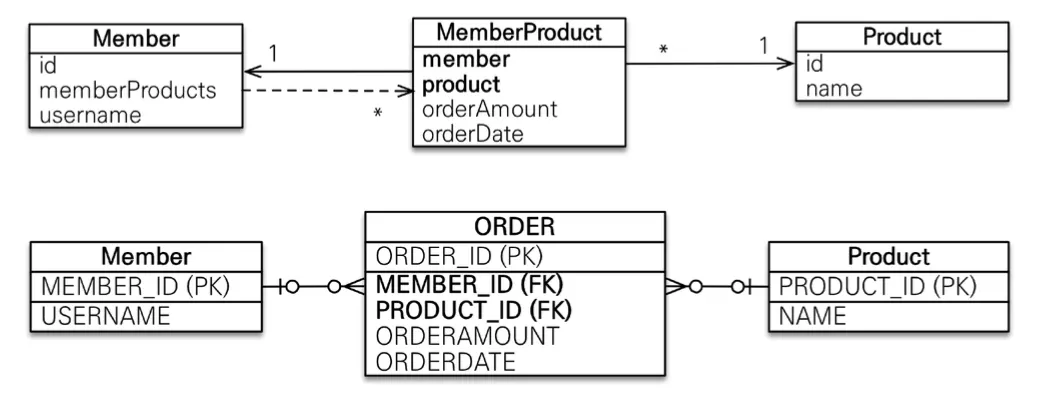
@ManyToMany 대신 @OneToMany + @ManyToOne로 만들어서 사용하자.
•
@JoinColumn
외래 키를 매핑할 때 사용되는 애노테이션
속성 | 설명 | 기본값 |
name | 매핑할 외래 키 이름 | 필드명 + _ + 참조하는 테이블의 기본 키 컬럼명 |
referencedColumnName | 외래 키가 참조하는 대상 테이블의 컬럼명 | 참조하는 테이블의 기본 키 컬럼명 |
foreignKey(DDL) | 외래 키 제약 조건을 직접 지정할 수 있다.
이 속성은 테이블을 생성할 때만 사용한다. | |
unique
nullable
insertable
columnDefinition
table | @Column의 속성과 동일 |
•
@ManyToOne
다대일 관계 매핑
속성 | 설명 | 기본값 |
optional | false로 설정하면 연관된 엔티티가 항상 있어야 한다. | TRUE |
fetch | 글로벌 페치 전략을 설정한다. | FetchType.EAGER |
cascade | 영속성 전이 기능을 사용한다. | |
targetEntity | 연관된 엔티티의 타입 정보를 설정한다.
컬렉션의 제네릭으로 타입 정보를 알 수 있기 때문에 이 기능은 더이상 사용되지 않는다. |
•
@OneToMany
일대다 관계 매핑
속성 | 설명 | 기본값 |
mappedBy | 연관관계의 주인 필드를 선택한다. | |
fetch | 글로벌 페치 전략을 설정한다. | FetchType.LAZY |
cascade | 영속성 전이 기능을 사용한다. | |
targetEntity | 연관된 엔티티의 타입 정보를 설정한다.
컬렉션의 제네릭으로 타입 정보를 알 수 있기 때문에 이 기능은 더이상 사용되지 않는다. |
상속 관계 매핑
일부 데이터베이스를 제외하고는 관계형 데이터베이스에는 상속 관계가 없지만, 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사한 구조를 가진다.
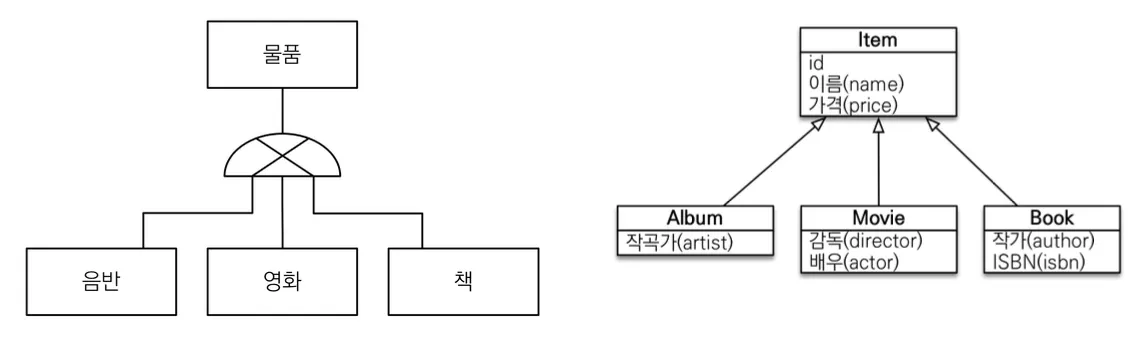
이를 통해 엔티티 객체의 상속 관계를 데이터베이스의 슈퍼타입 서브타입 관계로 모델링 후 매핑하여 사용한다.
슈퍼타입 서브타입 논리 모델을 실제 물리 모델을 통해 구현하는 방법은 3가지가 있다.
•
JOINED 전략
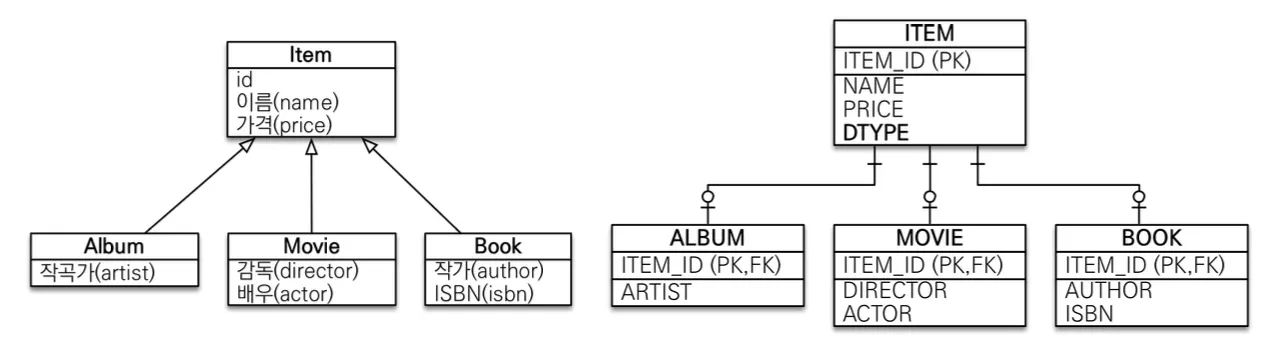
슈퍼타입과 서브타입 논리 모델을 각각 테이블로 변환하고, 슈퍼타입 모델에 서브타입을 구분할 수 있는 구분자(DTPYE)를 추가하는 방식이다.
@Inheritance(strategy = InheritanceType.JOINED)으로 설정할 수 있다.
부모 클래스의 구분자는 기본적으로 생략되어 있으며, @DiscriminatorColumn(name = “DTYPE”)으로 구분자를 지정하여 생성하게 만들 수 있다. 넣지 않게 되면 DB만 보았을 때 해당 Item이 어떤 하위 테이블과 Join 되는지 알 수 없기 때문에, 가급적 넣어주는 것이 권장된다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "DTYPE")
abstract class Item {
@Id @GeneratedValue
Long id;
...
}
Java
복사
반대로 자식 클래스에서 @DiscriminatorValue()를 통해 해당 클래스가 부모 클래스의 DTYPE에 해당하는 type 이름을 지정할 수 있다. 지정하지 않으면 기본값으로 클래스명으로 지정된다.
@Entity
@DiscriminatorValue("B")
class Book extends Item {
@Id @GeneratedValue
Long id;
...
}
Java
복사
장점
◦
테이블 정규화
◦
외래 키 참조 무결성 제약 조건 활용 가능
◦
저장공간 효율성
단점
◦
조회 시 조인을 많이 사용하여 성능 저하
◦
조회 쿼리가 복잡
◦
데이터 저장 시 INSERT SQL을 2번씩 호출
•
SINGLE_TALBE 전략
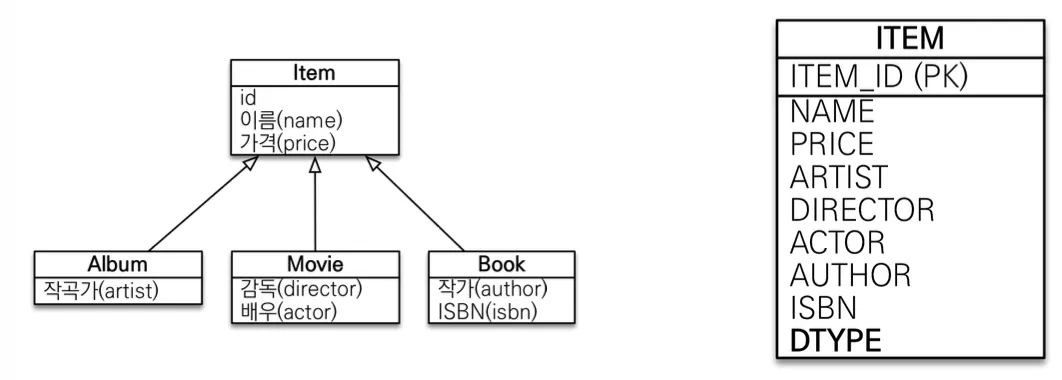
JPA의 기본 전략 방식으로, 모든 논리 모델을 단일 통합 테이블로 합쳐서 변환하는 방식이다.
@Inheritance(strategy = InheritanceType.SINGLE_TALBE)으로 설정할 수 있다.
단일 테이블 전략은 @DiscriminatorColumn을 생략하더라도 기본으로 생성되어 들어가게된다. 이는 단일 테이블 전략에서는 DTYPE과 같은 구분자가 없다면 어떤 클래스와 매핑된 건지 알 방법이 없기 때문이다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
abstract class Item {
@Id @GeneratedValue
Long id;
...
}
Java
복사
@Entity
@DiscriminatorValue("M")
class Movie extends Item {
@Id @GeneratedValue
Long id;
...
}
Java
복사
장점
◦
조인이 없어 일반적으로 조회 성능이 빠름
◦
조회 쿼리가 단순
단점
◦
자식 엔티티가 매핑한 컬럼을 모두 null 허용
◦
단일 테이블에 모든 것을 저장하기 때문에 테이블이 커지고, 때문에 상황에 따라 조회 성능이 느려질 수 있다.
•
TABLE_PER_CLASS 전략

각각의 서브타입 모델을 테이블로 변환하여, 슈퍼타입 모델의 필드들을 해당 테이블들에서 모두 보유하고 있는 방식이다.
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)으로 설정할 수 있다.
이 전략에서는 구분자가 필요없기 때문에, @DiscriminatorColumn을 추가하여도 구분자가 생성되지 않는다.
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
abstract class Item {
@Id @GeneratedValue
Long id;
...
}
Java
복사
이 전략은 저장 시에는 문제가 없지만 부모 클래스 타입으로 검색을 수행하는 순간, 하위 모든 클래스를 UNION으로 전부 검색하여 가져온다. 때문에 이 전략은 데이터베이스 설계자와 ORM 전문가에게 모두 추천되지 않는다.
장점
◦
서브 타입을 명확하게 구분해서 처리할 때 효과적
◦
not null 제약 조건 사용 가능
단점
◦
여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
◦
자식 테이블을 통합해서 쿼리하기 어려움
@MappedSuperClass 애노테이션
@MappedSuperClass 애노테이션은 공통 매핑 정보가 필요할 때 사용되는 애노테이션이다.
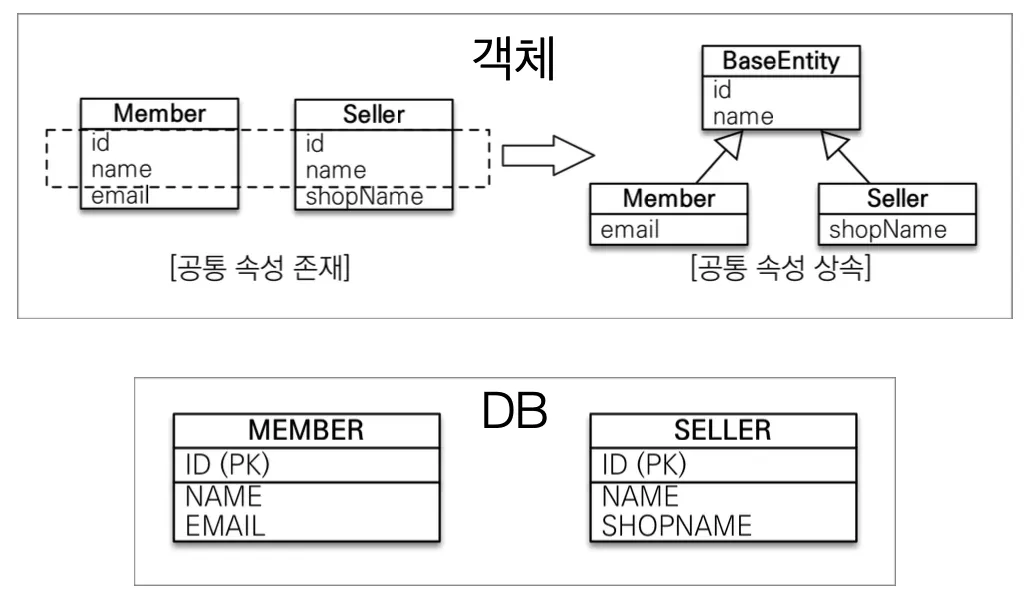
@MappedSuperClass는 주로 id, name, 등록일, 수정일, 등록자, 수정자 등 전체 엔티티에서 공통으로 적용하는 정보들을 한 곳에 모을 때 사용된다.
@MappedSuperClass
public abstract class BaseEntity {
@Id @GeneratedValue
private Long id;
@Column(name = "MEBMER_NAME")
private String name;
...
}
@Entity
public class Member extends BaseEntity {
private String email;
...
}
Java
복사
@MappedSuperClass 애노테이션을 통해 공통 속성을 부모 클래스로 모으면, 부모 클래스는 테이블과 관계가 없고 단순히 여러 엔티티들이 공통으로 사용하는 매핑 정보를 모아주기만 한다. 따라서 부모 클래스는 상속 관계를 매핑할 수 없고, 엔티티나 테이블과 매핑할 수도 없다. 오직 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만을 제공한다. 때문에 부모 클래스(BaseEntity)를 통해 조회를 수행할 수 없다.
이런 이유들로 부모 클래스는 직접 생성해서 사용할 일이 없기 때문에 추상 클래스로 생성하는 것이 권장된다.
프록시
EntityManager에는 데이터를 찾는 두 가지 방법이 있다.
em.find()는 데이터베이스를 통해서 실제 엔티티 객체를 조회해오는 방법이다. 반면, em.getReference()는 가짜(프록시) 엔티티 객체를 반환하며 데이터베이스 조회를 미룬다.
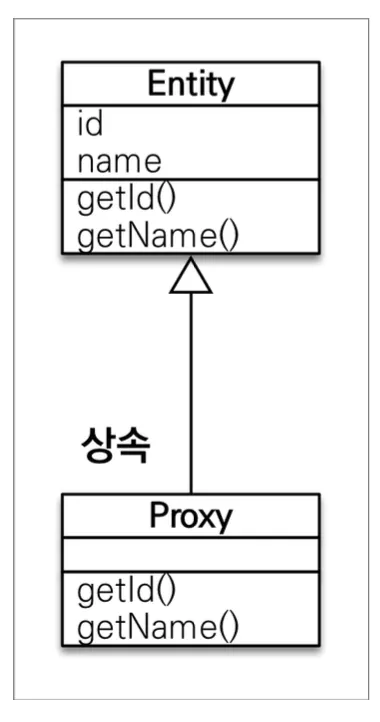
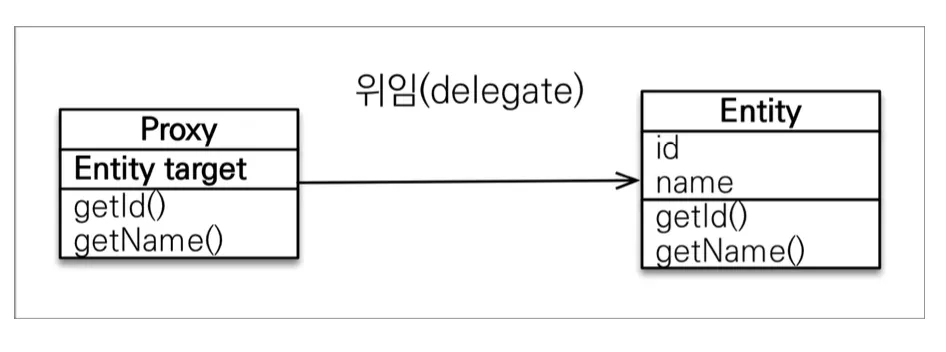
프록시 객체는 실제 클래스를 상속 받아서 실제 클래스와 겉보기에 똑같은 객체를 만든 것이다. 프록시 객체는 실제 객체의 참조(target)를 보관하고, 프록시 객체에서 메서드를 호출하면 실제 객체의 메서드를 호출한다. 이를 통해 이론상 사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용할 수 있다.
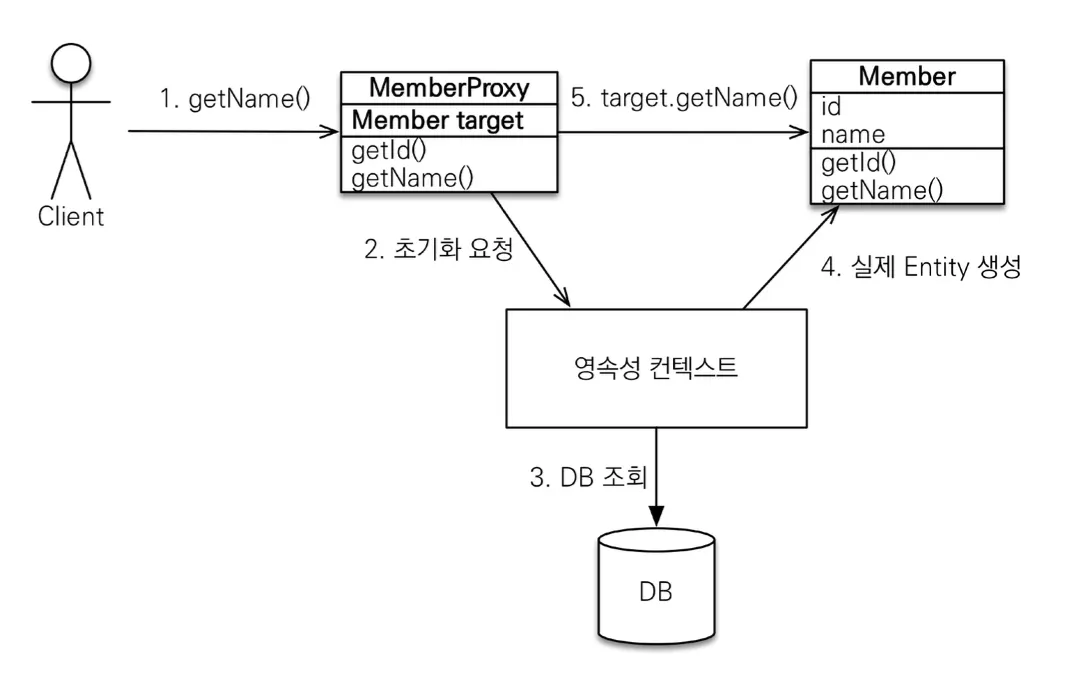
프록시 객체는 처음 사용될 때 한 번만 초기화 되고, 초기화 시 프록시 객체가 실제 엔티티 객체로 바뀌는 것이 아니라 실제 엔티티 객체를 조회해놓고 프록시 객체를 통해서 실제 엔티티 객체에 접근한다. 영속성 컨텍스트에 찾는 엔티티가 있다면 em.getReference()를 호출해도 실제 엔티티를 반환한다.
영속성 컨텍스트에 엔티티가 있다면 프록시를 안만드는 이유
JPA는 트랜잭션에서 REPEATABLE READ 격리 수준을 지원하기 때문에, 동일 트랜잭션 내에서 class1 = class1을 수행하면 항상 true가 반환되어야한다. 이를 위해 이미 조회된 실제 엔티티가 있다면 프록시 객체를 새로 만들지 않고 실제 엔티티를 그대로 반환한다.
그 반대의 경우 프록시 조회 후 em.find를 통해 실제 엔티티를 별도로 받아오고자 해도 위에서 말한 메커니즘을 성립시키기 위해 그냥 프록시 객체를 반환한다.
프록시 객체는 원본 엔티티를 상속 받기 때문에, 타입 체크 시 주의해야 한다. 프록시 객체와 실제 엔티티를 비교하는 경우, == 비교 시 실패할 수도 있기 때문에 instanceOf를 사용해야한다. 또한 영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태일 때, 프록시를 초기화하면 에러가 발생한다(하이버네이트의 경우 LazyInitializationException 예외 발생).
프록시 객체를 확인하는 여러 방법이 있다.
•
프록시 인스턴스의 초기화 여부 확인
◦
PersistenceUnitlUtil.isLoaded(Object entity)
•
프록시 클래스 확인 방법
◦
entity.getClass().getName()
•
프록시 강제 초기화
◦
org.hibernate.initialize(entity)
◦
JPA 표준에는 강제 초기화가 없다 → member.getName()과 같이 내부 메서드 호출로 초기화
즉시 로딩과 지연 로딩
위에서 공부했었던 내용을 보면 @OneToMany, @ManyToOne, @OneToOne의 속성에는 fetch 조건이 있었다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
...
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEMA_ID")
private Team team;
}
Java
복사
이처럼 fetch 속성을 통해 즉시 로딩(Eager Loading)과 지연 로딩(Lazy Loading)을 설정할 수 있다.
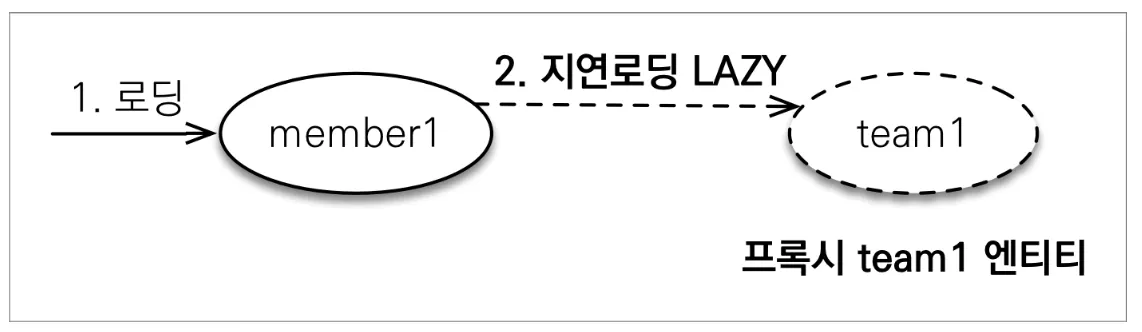
이렇게 지연 로딩을 사용할 수 있는 이유는 조회 시에 프록시 객체를 반환하고 실제 엔티티 객체가 필요하거나 직접 사용되는 경우에, DB를 조회하여 실제 엔티티 객체를 가져와 프록시를 초기화하기 때문이다.
fetch 속성의 기본값은 @ManyToOne, @OneToOne은 FecthType.EAGER이고, @OneToMany, @ManyToMany는 FetchType.LAZY이다.
연관관계를 가지는 구조에서 fetch 옵션으로 가급적 지연 로딩로 바꾸어 사용하길 권장된다. 즉시 로딩을 적용하면 예상치 못한 SQL이 발생할 수 있고, JPQL을 사용하는 경우 즉시 로딩은 N+1 문제가 발생한다. 때문에 항상 지연 로딩을 사용하고, 추가적인 데이터가 필요하다면 JPQL fetch Join이나 엔티티 그래프 기능을 사용하자.
영속성 전이와 고아 객체
•
영속성 전이
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶은 경우, 영속성 전이와 관련된 Cascade 속성을 사용하면 된다.
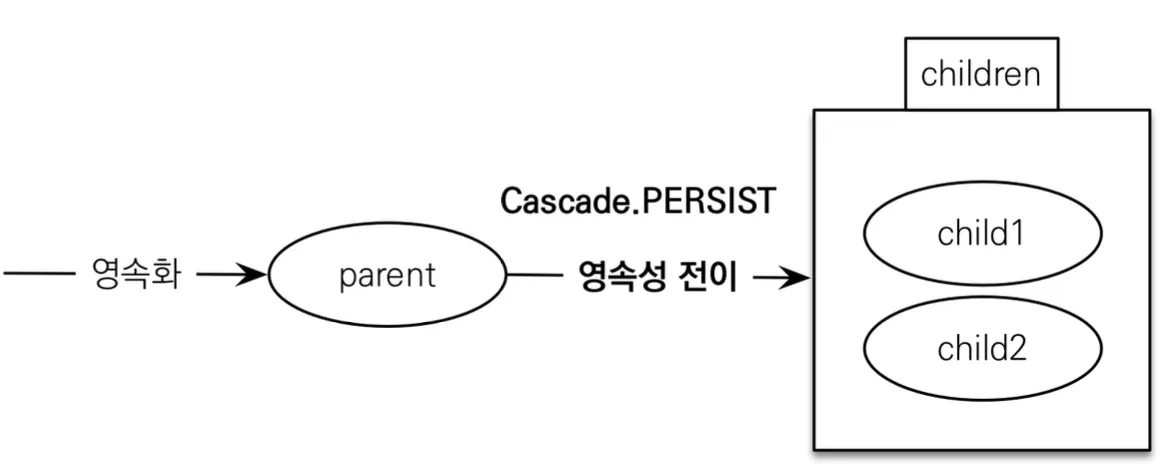
@OneToMany(mappedBy="parent", cascade=CascadeType.PERSIST)
Java
복사
이런 영속성 전이 기능은 연관관계 매핑과는 아무 관련이 없고, 단순히 엔티티를 영속화할 때 연관된 엔티티도 같이 영속화하는 편의 기능을 제공할 뿐이다.
Casecade 종류는 다음과 같다.
•
ALL : 영속성 전이를 영속, 삭제, 병합 등 모두 적용
•
PERSIST : 영속에 대해서만 영속성 전이
•
REMOVE : 삭제에 대해서만 영속성 전이
•
MERGE : 병합에 대해서만 영속성 전이
•
REFRESH : refresh에 대해서만 영속성 전이
•
DETACH : detach에 대해서만 영속성 전이
cascade는 특정 엔티티가 다른 단일 엔티티에 완전히 종속적일 때(하나의 엔티티에서만 참조할 때) 사용하는 것이 좋다. 그렇지 않으면, 한 번의 영속화로 너무 많은 쿼리가 발생하여 성능이 많이 저하될 수 있다. 또한 REMOVE의 경우 아주 조심해서 사용해야하고, 가급적 사용하지 않는 것이 권장된다.
•
고아 객체
고아 객체는 부모 객체와 연관관계가 끊어진 자식 객체를 의미하는데, JPA에서도 이러한 부모 엔티티와 연관관계가 끊어진 고아 엔티티 객체를 자동으로 삭제하는 기능을 제공한다.
@OneToMany(mappedBy="parent", orphanRemoval=true)
Java
복사
이와 같이 설정하면 부모 엔티티를 삭제하고 자식 엔티티를 컬렉션에서 제거했을 때, 고아가 된 자식 엔티티를 삭제하는 SQL이 자동으로 발생하게 된다.
Cascade.ALL 속성과 orphanRemoval=true 속성을 같이 사용하게 되면, 부모 엔티티를 통해 자식 엔티티의 생명 주기를 관리할 수 있게 된다. 이는 도메인 주도 설계(DDD)의 Aggregate Root 개념을 구현할 때 유용하다.
참조가 제거된 엔티티는 또 다른 곳에서 참조하지 않아야 고아 객체로 보고 삭제되기 때문에, 이 역시 cascade와 마찬가지로 참조하는 곳이 한 개일 때만 사용하는 것이 권장된다. 또한 @OneToOne과 @OneToMany에서만 적용할 수 있다.

