로그 추적기
애플리케이션 구조
상품을 주문하는 프로세스를 가정하고, Controller → Service → Repository로 이어지는 흐름을 작성해보자.
@Repository
@RequiredArgsConstructor
public class OrderRepositoryV0 {
public void save(String itemId) {
if (itemId.equals("ex")) {
throw new IllegalStateException("예외 발생!");
}
sleep(1000);
}
private void sleep(int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Java
복사
@Service
@RequiredArgsConstructor
public class OrderServiceV0 {
private final OrderRepositoryV0 orderRepository;
public void orderItem(String itemId) {
orderRepository.save(itemId);
}
}
Java
복사
@RestController
@RequiredArgsConstructor
public class OrderControllerV0 {
private final OrderServiceV0 orderService;
@GetMapping("/v0/request")
public String request(String itemId) {
orderService.orderItem(itemId);
return "ok";
}
}
Java
복사
이와 같은 계층 구조로 로직을 작성하고, 이제 웹 애플리케이션에 로그 추적기를 추가해보자.
로그 추적기 추가
로그 추적기의 요구사항은 다음과 같다.
•
모든 public 메서드의 호출과 응답을 로그로 출력
•
로그가 비즈니스 로직의 동작에 영향을 주지 않아야 함
•
메서드 호출에 걸린 시간 출력
•
정상 흐름과 예외 흐름 구분 및 예외 발생 시 예외 정보 출력
•
메서드 호출의 depth 표현
정상 요청
[796bccd9] OrderController.request()
[796bccd9] |-->OrderService.orderItem()
[796bccd9] | |-->OrderRepository.save()
[796bccd9] | |<--OrderRepository.save() time=1004ms
[796bccd9] |<--OrderService.orderItem() time=1014ms
[796bccd9] OrderController.request() time=1016ms
예외 발생
[b7119f27] OrderController.request()
[b7119f27] |-->OrderService.orderItem()
[b7119f27] | |-->OrderRepository.save() [b7119f27] | |<X-OrderRepository.save() time=0ms ex=java.lang.IllegalStateException: 예외 발생! [b7119f27] |<X-OrderService.orderItem() time=10ms ex=java.lang.IllegalStateException: 예외 발생! [b7119f27] OrderController.request() time=11ms ex=java.lang.IllegalStateException: 예외 발생!
Plain Text
복사
이와 같은 동작을 하도록 로그 추적기를 추가해보자.
@Getter
@AllArgsConstructor(access = AccessLevel.PROTECTED)
public class TraceId {
private String id;
private int level;
public TraceId() [
this.id = UUID.randomUUID().toString().substring(0, 8);
this.level = 0;
}
public TraceId createNextId() {
return new TraceId(id, level + 1);
}
public TraceId createPreviousId() {
return new TraceId(id, level - 1);
}
}
Java
복사
@Getter
@AllArgsConstructor
public class TraceStatus {
private TraceId traceId;
private Long startTimeMs;
private String message;
}
Java
복사
이렇게 만든 TraceId와 TraceStatus를 통해 로그 추적기를 추가한다.
@Slf4j
@Component
public class HelloTraceV1 {
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
public TraceStatus begin(String message) {
TraceId traceId = new TraceId();
Long startTimeMs = System.currentTimeMillis();
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
public void end(TraceStatus status) {
complete(status, null);
}
public void exception(TraceStatus status, Exception e) {
complete(status, e);
}
private void complete(TraceStatus status, Exception e) {
Long stopTimeMs = System.currentTimeMillis();
long resultTimeMs = stopTimeMs - status.getStartTimeMs();
TraceId traceId = status.getTraceId();
if (e == null) {
log.info("[{}] {}{} time={}ms", traceId.getId(),
addSpace(COMPLETE_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs);
} else {
log.info("[{}] {}{} time={}ms ex={}", traceId.getId(),
addSpace(EX_PREFIX, traceId.getLevel()), status.getMessage(), resultTimeMs, e.toString());
}
}
private static String addSpace(String prefix, int level) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < level; i++) {
sb.append( (i == level - 1) ? "|" + prefix : "| ");
}
return sb.toString();
}
}
Java
복사
로그 추적기의 요구사항을 구현하여 로직을 작성한다.
@RestController
@RequiredArgsConstructor
public class OrderControllerV1 {
private final OrderServiceV1 orderService;
private final HelloTraceV1 trace;
@GetMapping("/v1/request")
public String request(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderController.request()");
orderService.orderItem(itemId);
trace.end(status);
return "ok";
} catch (Exception e) {
trace.exception(status, e);
throw e; //예외를 꼭 다시 던져주어야 한다.
}
}
}
Java
복사
작성한 로그 추적기를 위와 같이 비즈니스 로직에 끼워 넣어 로그를 출력하도록 만들었다. 서비스와 레포지토리도 마찬가지로 추가해주자.
정상 요청
[11111111] OrderController.request()
[22222222] OrderService.orderItem()
[33333333] OrderRepository.save()
[33333333] OrderRepository.save() time=1000ms
[22222222] OrderService.orderItem() time=1001ms
[11111111] OrderController.request() time=1001ms
예외 발생
[5e110a14] OrderController.request()
[6bc1dcd2] OrderService.orderItem()
[48ddffd6] OrderRepository.save()
[48ddffd6] OrderRepository.save() time=0ms ex=java.lang.IllegalStateException: 예 외 발생!
[6bc1dcd2] OrderService.orderItem() time=6ms ex=java.lang.IllegalStateException: 예외 발생!
Plain Text
복사
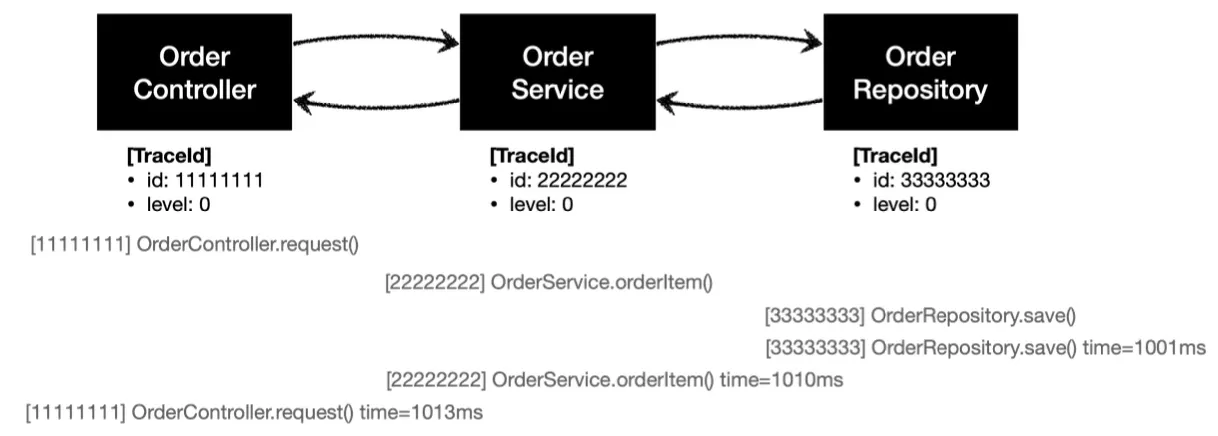
로그를 직접 확인해보면, 이와 같이 각 요청의 UUID가 계층이 변할 때마다 바뀌고 depth가 표현 되지 않는 문제가 있다.
이를 해결하기 위해서는 TraceStatus를 파라미터로 넘겨서 동기화하여 개발해야한다.
//V2에서 추가
public TraceStatus beginSync(TraceId beforeTraceId, String message) {
TraceId nextId = beforeTraceId.createNextId();
Long startTimeMs = System.currentTimeMillis();
log.info("[" + nextId.getId() + "] " + addSpace(START_PREFIX, nextId.getLevel()) + message);
return new TraceStatus(nextId, startTimeMs, message);
}
Java
복사
이와 같이 traceId와 level을 전달받아 다음 TraceId를 생성하는 로직을 로그 추적이에 추가해주고,
public void orderItem(TraceId traceId, String itemId) {
TraceStatus status = null;
try {
status = trace.beginSync(traceId, "OrderService.orderItem()");
orderRepository.save(status.getTraceId(), itemId);
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
Java
복사
이와 같이 비즈니스 로직에서의 로그 추적기 부분을 새로 추가한 로직으로 변경한다.
정상 요청
[c80f5dbb] OrderController.request()
[c80f5dbb] |-->OrderService.orderItem()
[c80f5dbb] | |-->OrderRepository.save()
[c80f5dbb] | |<--OrderRepository.save() time=1005ms
[c80f5dbb] |<--OrderService.orderItem() time=1014ms
[c80f5dbb] OrderController.request() time=1017ms
예외 발생
[ca867d59] OrderController.request()
[ca867d59] |-->OrderService.orderItem()
[ca867d59] | |-->OrderRepository.save()
[ca867d59] | |<X-OrderRepository.save() time=0ms
ex=java.lang.IllegalStateException: 예외 발생!
[ca867d59] |<X-OrderService.orderItem() time=7ms
ex=java.lang.IllegalStateException: 예외 발생!
[ca867d59] OrderController.request() time=7ms
ex=java.lang.IllegalStateException: 예외 발생!
Plain Text
복사
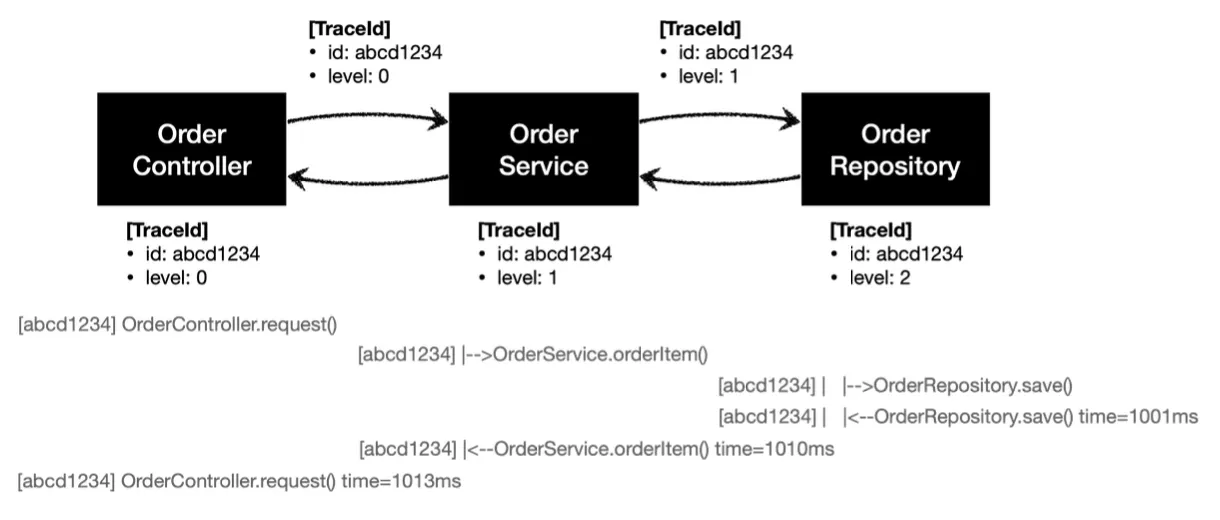
이와 같이 요구사항이 잘 반영된 로그를 확인할 수 있다.
ThreadLocal
필드 동기화
위에서 만든 로그 추적기는 traceId와 level을 동기화 하기 위해 파라미터로 전달하였다. 하지만 이러면 로그를 출력하는 모든 메서드에서 해당 파라미터를 전달하고 받아야 하는 문제가 있다.
이를 싱글톤을 통해 해결해보자.
public interface LogTrace {
TraceStatus begin(String message);
void end(TraceStatus status);
void exception(TraceStatus status, Exception e);
}
Java
복사
먼저 이와 같은 LogTrace 인터페이스를 추가하여 추후 구현체를 통해 바꿀 수 있게 만들자.
@Slf4j
public class FieldLogTrace implements LogTrace {
...
private TraceId traceIdHolder; //traceId 동기화, 동시성 이슈 발생
@Override
public TraceStatus begin(String message) {
syncTraceId();
TraceId traceId = traceIdHolder;
Long startTimeMs = System.currentTimeMillis();
log.info("[{}] {}{}", traceId.getId(), addSpace(START_PREFIX, traceId.getLevel()), message);
return new TraceStatus(traceId, startTimeMs, message);
}
...
private void complete(TraceStatus status, Exception e) {
...
releaseTraceId();
}
private void syncTraceId() {
if (traceIdHolder == null) {
traceIdHolder = new TraceId();
} else {
traceIdHolder = traceIdHolder.createNextId();
}
}
private void releaseTraceId() {
if (traceIdHolder.isFirstLevel()) {
traceIdHolder = null; //destroy
} else {
traceIdHolder = traceIdHolder.createPreviousId();
}
}
}
Java
복사
이와 같은 로그 추적기 구현체를 작성한다. 여기서 달라진 점은 내부 필드로 traceHolder가 추가되어 traceId를 관리한다는 것이고, 그로 인해 내부적으로 traceId 동기화 부분이 추가되었다.
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
return new FieldLogTrace();
}
}
Java
복사
그리고 위와 같이 싱글톤으로 스프링 빈에 등록하자.
private final LogTrace trace;
public void orderItem(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderService.orderItem()");
orderRepository.save(itemId);
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
Java
복사
이를 통해 파라미터 형태로 전달되던 코드를 삭제할 수 있다.
정상 요청
[f8477cfc] OrderController.request()
[f8477cfc] |-->OrderService.orderItem()
[f8477cfc] | |-->OrderRepository.save()
[f8477cfc] | |<--OrderRepository.save() time=1004ms
[f8477cfc] |<--OrderService.orderItem() time=1006ms
[f8477cfc] OrderController.request() time=1007ms
예외 발생
[c426fcfc] OrderController.request()
[c426fcfc] |-->OrderService.orderItem()
[c426fcfc] | |-->OrderRepository.save()
[c426fcfc] | |<X-OrderRepository.save() time=0ms
ex=java.lang.IllegalStateException: 예외 발생!
[c426fcfc] |<X-OrderService.orderItem() time=7ms
ex=java.lang.IllegalStateException: 예외 발생!
[c426fcfc] OrderController.request() time=7ms
ex=java.lang.IllegalStateException: 예외 발생!
Plain Text
복사
실행시켜보면 정상적으로 잘 동작하는 것을 볼 수 있다.
동시성 문제
위 로그 추적기는 문제 없이 잘 동작하는 것처럼 보이지만, 사실 동시성 문제를 내포하고 있다. 비즈니스 로직이 1초가 걸린다 가정할 때, 1초 내에 빠르게 2번 이상의 요청을 보내보자.
[f8477cfc] OrderController.request()
[f8477cfc] |-->OrderService.orderItem()
[f8477cfc] | |-->OrderRepository.save()
[f8477cfc] | |<--OrderRepository.save() time=1004ms
[f8477cfc] |<--OrderService.orderItem() time=1006ms
[f8477cfc] OrderController.request() time=1007ms
[f8477cfc] OrderController.request()
[f8477cfc] |-->OrderService.orderItem()
[f8477cfc] | |-->OrderRepository.save()
[f8477cfc] | |<--OrderRepository.save() time=1004ms
[f8477cfc] |<--OrderService.orderItem() time=1006ms
[f8477cfc] OrderController.request() time=1007ms
Plain Text
복사
우리가 기대하던 요청 로그는 이와 같을 것이다.
[nio-8080-exec-3] [aaaaaaaa] OrderController.request()
[nio-8080-exec-3] [aaaaaaaa] |-->OrderService.orderItem()
[nio-8080-exec-3] [aaaaaaaa] | |-->OrderRepository.save()
[nio-8080-exec-4] [aaaaaaaa] | | |-->OrderController.request()
[nio-8080-exec-4] [aaaaaaaa] | | | |-->OrderService.orderItem()
[nio-8080-exec-4] [aaaaaaaa] | | | | |-->OrderRepository.save()
[nio-8080-exec-3] [aaaaaaaa] | |<--OrderController.request() time=1005ms
[nio-8080-exec-3] [aaaaaaaa] |<--OrderService.orderItem() time=1005ms
[nio-8080-exec-3] [aaaaaaaa] OrderController.request() time=1005ms
[nio-8080-exec-4] [aaaaaaaa] | | | | |<--OrderRepository.save() time=1005ms time=1005ms
[nio-8080-exec-4] [aaaaaaaa] | | | |<--OrderService.orderItem() time=1005ms
[nio-8080-exec-4] [aaaaaaaa] | | |<--OrderController.request() time=1005ms
Plain Text
복사
하지만 실제 로그는 위와 같이 발생한다. 이는 싱글톤으로 등록된 스프링 빈이라서, 내부 필드인 traceIdHolder를 여러 스레드에서 조작하기 때문에 발생한다.
이러한 동시성 문제는 각각 다른 스택 영역에 할당이 되는 지역 변수에서는 발생하지 않고, 주로 싱글톤 인스턴스의 필드나 static 같은 공용 필드에 접근할 때 발생한다. 또한 모든 스레드에서 값을 읽기만 한다면 발생하지 않고, 어디선가 값을 변경할 때 발생한다.
ThreadLocal
위 문제를 ThreadLocal을 통해 해결할 수 있다.
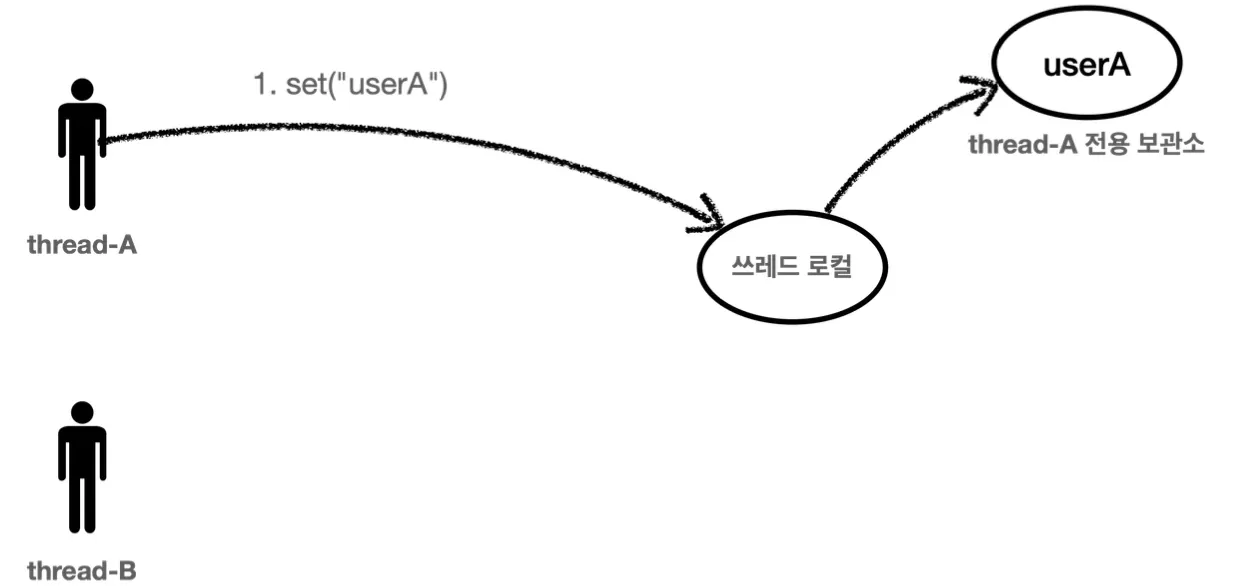
ThreadLocal은 해당 스레드만 접근할 수 있는 특별한 저장소로, 다른 스레드가 요청한다면 다른 저장소를 할당하기 때문에 스레드 별로 별개의 변수를 사용할 수 있다.
이러한 ThreadLoacl을 통해 위 로그 추적기의 문제를 해결해보자.
@Slf4j
public class ThreadLocalLogTrace implements LogTrace {
...
private ThreadLocal<TraceId> traceHolder = new ThreadLocal<>();
...
private void syncTraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId == null) {
traceIdHolder.set(new TraceId());
} else {
traceIdHolder.set(traceId.createNextId());
}
}
private void release TraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId.getLevel() == 0) {
traceIdHolder.remove(); // destroy
} else {
traceIdHolder.set(traceId.createPreviousId());
}
}
...
}
Java
복사
ThreadLocal을 적용하여, 위와 같이 set과 get을 통해 변수를 조회하고 저장한다.
[nio-8080-exec-3] [52808e46] OrderController.request()
[nio-8080-exec-3] [52808e46] |-->OrderService.orderItem()
[nio-8080-exec-3] [52808e46] | |-->OrderRepository.save()
[nio-8080-exec-4] [4568423c] OrderController.request()
[nio-8080-exec-4] [4568423c] |-->OrderService.orderItem()
[nio-8080-exec-4] [4568423c] | |-->OrderRepository.save()
[nio-8080-exec-3] [52808e46] | |<--OrderRepository.save() time=1001ms
[nio-8080-exec-3] [52808e46] |<--OrderService.orderItem() time=1001ms
[nio-8080-exec-3] [52808e46] OrderController.request() time=1003ms
[nio-8080-exec-4] [4568423c] | |<--OrderRepository.save() time=1000ms
[nio-8080-exec-4] [4568423c] |<--OrderService.orderItem() time=1001ms
[nio-8080-exec-4] [4568423c] OrderController.request() time=1001ms
Plain Text
복사
로그를 살펴보면, 동시에 요청이 들어왔지만 각 스레드별로 단계에 맞게 실행되는 것을 확인할 수 있다.
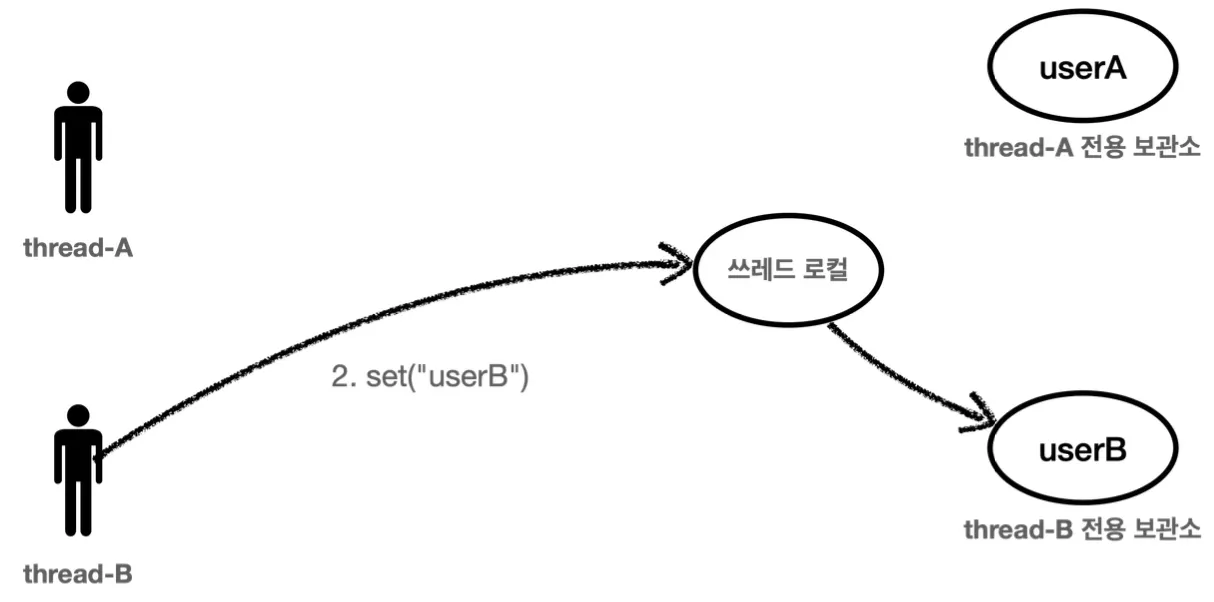
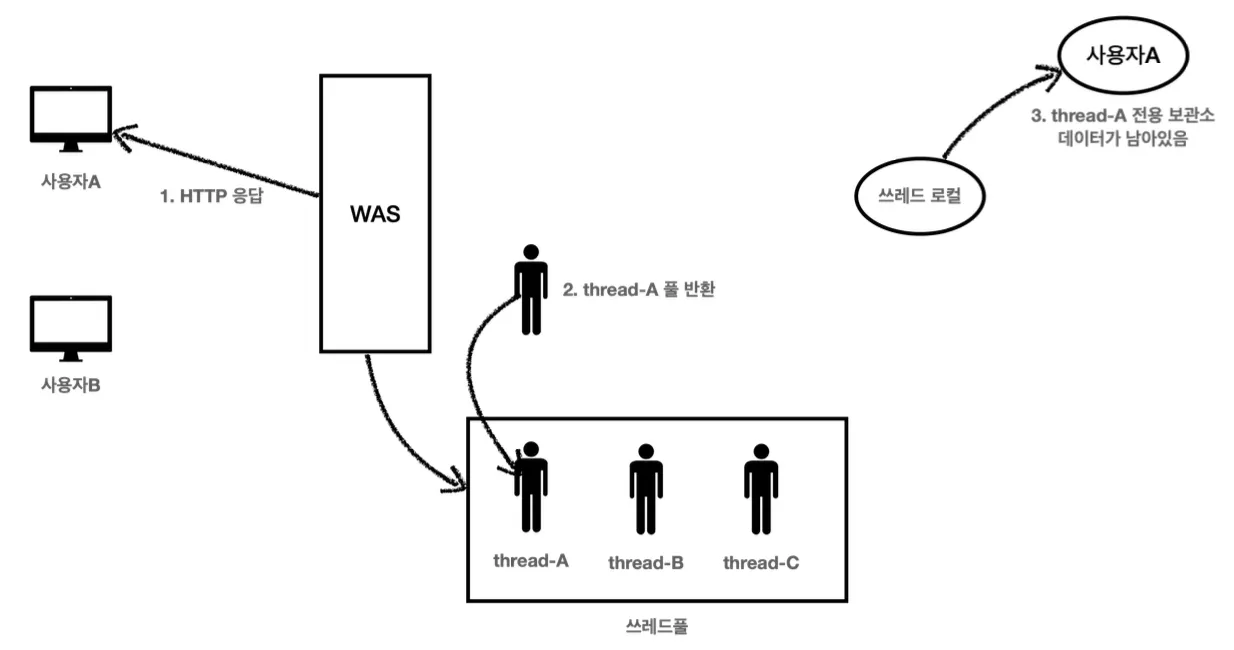
ThreadLocal을 사용할 때 중요한 점은 다 사용하고 나면 반드시 remove를 호출해서 제거해야한다는 것이다. 이를 제거하지 않고 방치하게되면, WAS(톰캣)와 같이 스레드 풀을 사용하는 경우에 심각한 문제가 발생할 수 있다.
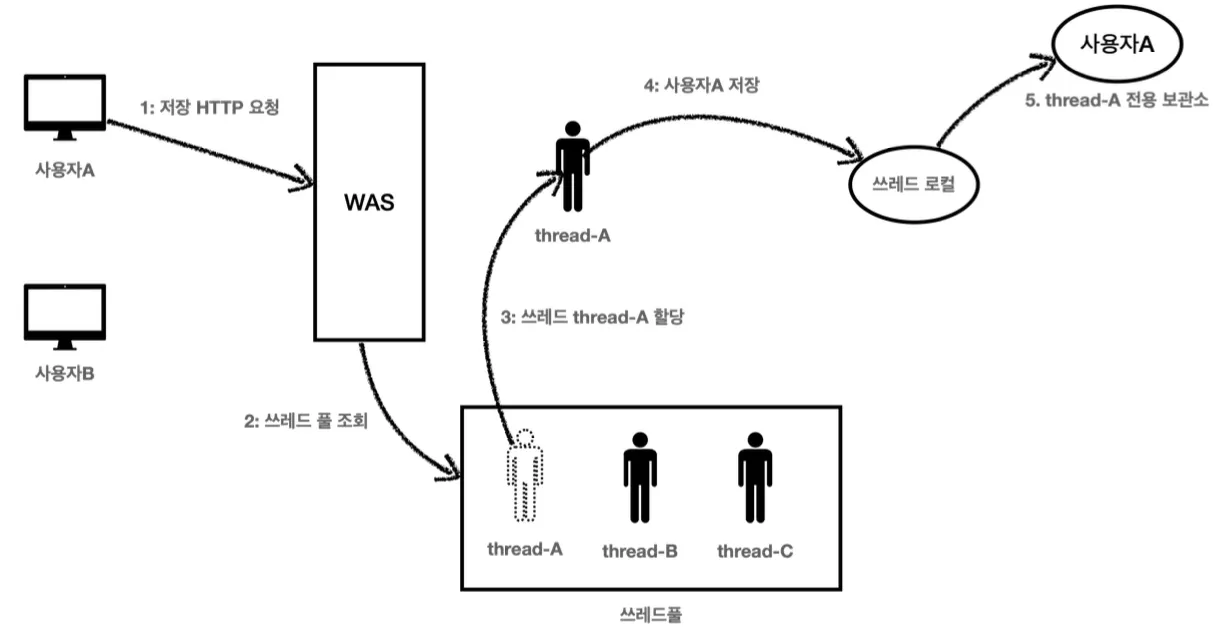
이와 같이 사용자 A가 스레드를 받아 ThreadLocal을 사용하고 난 후 ThreadLocal을 제거하지 않고 스레드를 스레드 풀에 반납했을 때,
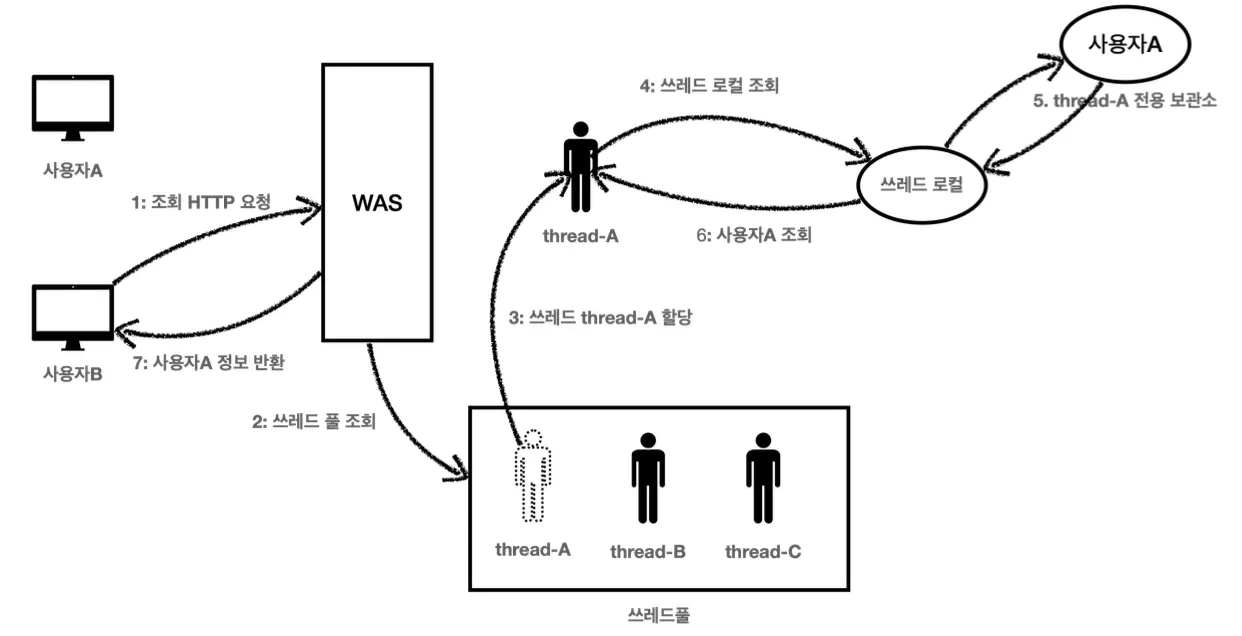
사용자 B가 아까 사용했던 스레드를 다시 할당받게 된다면 ThreadLocal 사용 시 사용자 A에 대한 정보를 반환하게 된다. 이러한 문제를 방지하기 위해 ThreadLocal을 다 사용하고 나면, 반드시 remove를 호출해 내부의 값을 제거해야 한다.
디자인 패턴 적용
템플릿 메서드 패턴
@GetMapping("/v0/request")
public String request(String itemId) {
orderService.orderItem(itemId);
return "ok";
}
Java
복사
@GetMapping("/v3/request")
public String request(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderController.request()");
orderService.orderItem(itemId); //핵심 기능
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
return "ok";
}
Java
복사
로그 추적기 적용 전과 후를 비교해보면, 적용 후에는 비즈니스 로직인 핵심 기능보다 로그 출력을 위한 부가 기능이 더 많고 복잡하다.
TraceStatus status = null;
try {
status = trace.begin("message");
/* 핵심 기능(비즈니스 로직) 호출 */
trace.end(status);
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
Java
복사
로그 추적기가 적용된 로직들을 살펴보면, 위와 같이 동일한 코드(패턴)가 반복되는 것을 알 수 있다.
좋은 설계는 변하는 것과 변하지 않는 것을 분리하고, 중복되는 코드를 한 곳으로 묶어 단일 책임 원칙을 지키는 것이다. 이를 템플릿 메서드 패턴(Template Method Pattern)을 적용하여 해결할 수 있다.
템플릿 메서드 패턴은 알고리즘의 골격을 정의하고 일부 단계를 하위 클래스로 연기하여, 알고리즘의 구조를 변경하지 않고도 일부 단계를 재정의 할 수 있는 패턴이다.
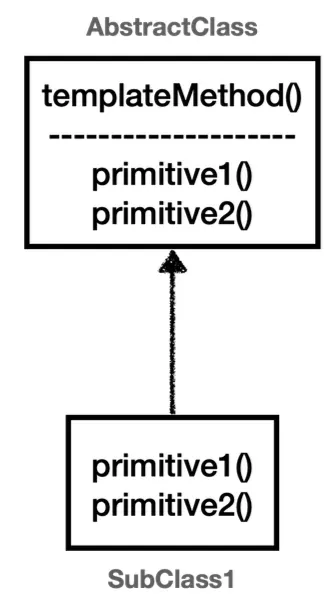
다시 말해, 부모 클래스에서 템플릿(알고리즘의 골격)을 정의하고, 이를 상속 받는 자식 클래스에서 변경되는 일부 로직을 정의하여 사용하는 것이다. 이를 통해 자식 클래스만 변경하여, 전체 구조(템플릿)를 변경하지 않으면서 특정 부분만 재정의 할 수 있다.
로그 추적기에 템플릿 메서드 패턴을 적용해보자.
@RequiredArgsConstructor
public abstract class AbstractTemplate<T> {
private final LogTrace trace;
public T execute(String message) {
TraceStatus status = null;
try {
status = trace.begin(message);
// 로직 호출
T result = call();
trace.end(status);
return result;
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
protected abstract T call();
}
Java
복사
먼저 제네릭을 통해 AbstractTemplate 추상 클래스를 정의한다. 템플릿 역할을 하는 execute 메서드에 기존의 try-catch를 통한 로그 추적기 템플릿을 구현한다. 변하는 부분을 처리하기 위한 메서드인 call 메서드를 추상 메서드로 정의하여, 상속 받는 자식 클래스에서 반드시 재정의하여 구현하도록 만든다.
@AllArgsConstructor
public class ControllerLogTrace extends AbstractTemplate {
@Override
protected String call() {
orderService.orderItem(itemId);
return "ok";
}
}
@GetMapping("/v4/request")
public String request(String itemId) {
AbstractTemplate<String> template = new ControllerLogTrace();
return template.execute("OrderController.request()");
}
Java
복사
그 후 이와 같이 AbstractTemplate를 상속받는 클래스를 구현하여, 구현 클래스를 통해 로그 추적기 내부에 핵심 로직을 넣으면 된다.
하지만 이와 같은 방식은 별개의 클래스를 매번 새로 생성해야한다는 문제와, 핵심 로직을 서비스 계층이 아닌 별도의 클래스에서 들고 있다는 문제가 있다.
@GetMapping("/v4/request")
public String request(String itemId) {
AbstractTemplate<String> template = new AbstractTemplate<>(trace) {
@Override
protected String call() {
orderService.orderItem(itemId);
return "ok";
}
};
return template.execute("OrderController.request()");
}
Java
복사
때문에 이와 같이 익명 클래스를 통해 사용할 수 있다.
이와 같이 템플릿 메서드 패턴을 적용하면, 로그를 남기는 부분을 하나로 모아서 모듈화하고 비즈니스 로직과 로그 관련 부분을 분리할 수 있게 된다.
좋은 설계는 변경이 발생할 때 드러난다. 추후 로그를 남기는 로직을 수정해야 한다고 하면, 기존에는 해당 로직을 쓰는 모든 부분을 직접 수정해야하지만 템플릿 메서드 패턴이 적용된 코드에서는 템플릿 부분 하나만 고치면 된다. 이를 통해 단일 책임 원칙(SRP)을 지키게 된 것이다.
하지만 이런 템플릿 메서드 패턴도 문제점이 있다. 일단 상속을 사용하기 때문에, 상속에서 오는 단점들을 그래도 내포하고 있다. 자식이 부모 클래스와 강결합 하게되어, 자식이 부모를 의존하게 된다는 점이다. 예를 들어 부모 클래스에 추상 메서드가 하나 더 추가된다면, 해당 부모를 상속받는 모든 자식들에서 해당 메서드를 재정의 해야한다. 위 코드에서는 자식 클래스 입장에서는 부모 클래스의 기능을 전혀 사용하지 않는데도, 부모 클래스를 extends를 통해 확장했기 때문에 부모의 클래스를 알고 있어야 한다.
전략 패턴
위의 템플릿 메서드 패턴의 단점과 추가적으로 익명 내부 클래스의 코드도 그리 깔끔하지 않다는 문제를 해결할 수 있는 방법이 바로 전략 패턴(Strategy Pattern)이다.
템플릿 메서드 패턴에서는 부모 클래스에 변하지 않는 템플릿 부분을 두고, 변하는 부분을 상속 받는 자식 클래스에서 구현하여 문제를 해결했었다.
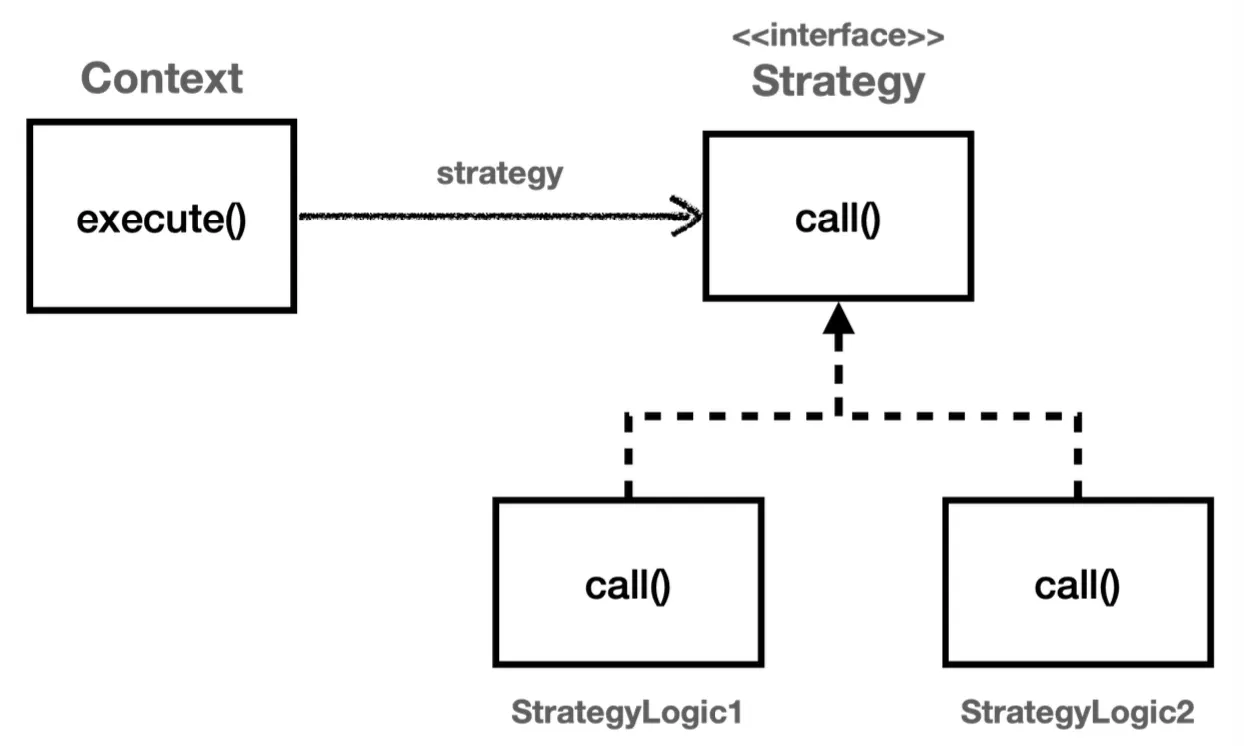
전략 패턴에서는 변하지 않는 부분을 Context에 두고, 변하는 부분을 Strategy라는 인터페이스에 구현을 받아 문제를 해결한다. 상속이 아니라 함수형 인터페이스를 통한 위임으로 문제를 해결하는 것이다.
로그 추적기가 아닌 간단한 예제를 통해 전략 패턴의 사용법을 알아보자.
public interface Strategy {
void call();
}
Java
복사
public class StrategyLogic implements Strategy {
@Override
public void call() {
// 위임 로직(핵심 기능) 구현
}
}
Java
복사
public class ContextV1 {
private final Strategy strategy;
public ContextV1(Strategy strategy) {
this.strategy = strategy;
}
public void execute() {
// 템플릿 로직 구현
...
strategy.call();
...
}
}
Java
복사
이와 같이 변하지 않는 로직은 Context 내부의 execute 메서드에 구현해두고, 변하는 로직은 Strategy라는 인터페이스의 call 메서드에 담도록한다.
Strategy strategyLogic = new StrategyLogic();
ContextV1 context = new ContextV1(strategyLogic);
context1.execute();
Java
복사
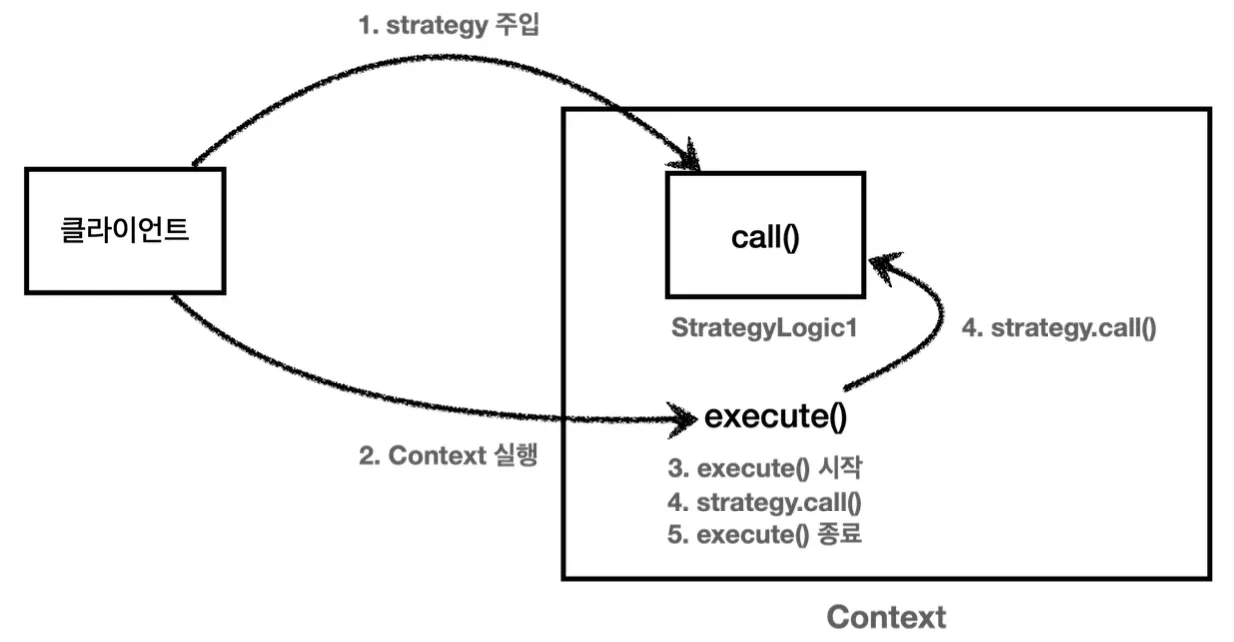
위임 로직을 포함하고 있는 strategyLogic의 구현체를 선택하여 Context에 넘겨 템플릿을 실행할 수 있게 만든다.
ContextV1 context = new ContextV1(new StrategyLogic() {
@Override
public void call() {
// 위임 로직
}
});
context1.execute();
Java
복사
위와 같이 익명 클래스를 통해 직접 생성자 내부에서 호출하는 방식도 가능하다.
이러한 방식의 문제는, 위임 로직이 달라지게 된다면 setter를 통해 Strategy를 변경하거나 Context를 새로 생성해야 한다는 것이다.
public class ContextV2 {
public void execute(Strategy strategy) {
// 템플릿 로직 구현
...
strategy.call();
...
}
}
Java
복사
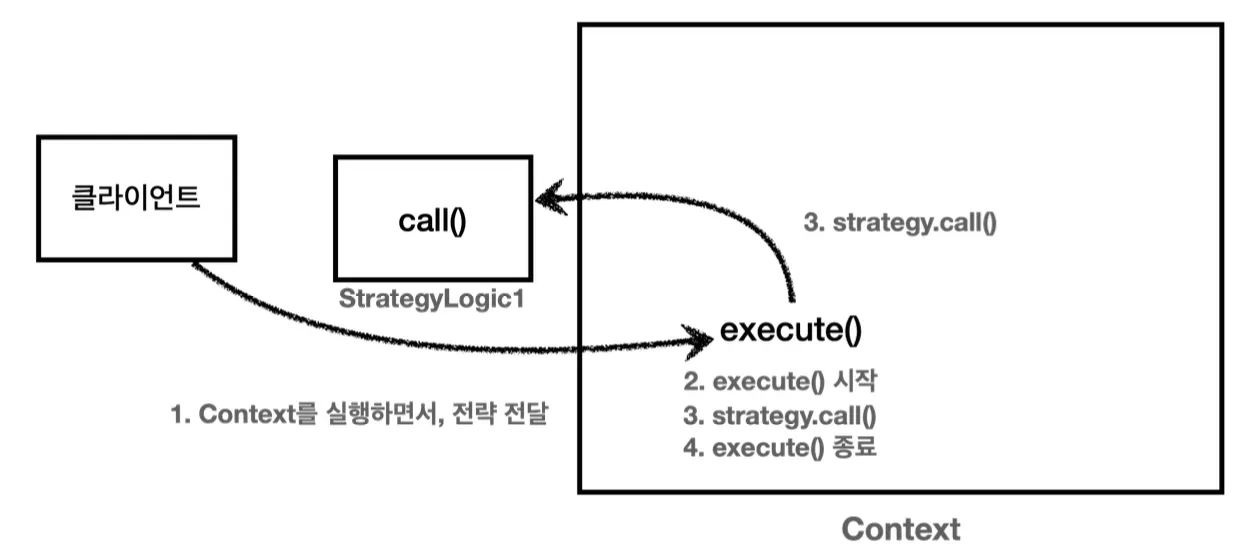
때문에 Strategy를 내부 필드로 두고 주입받아서 사용하는 것이 아니라, 이와 같이 파라미터로 전달해 사용하는 방법이 있다.
ContextV2 context = new ContextV2();
// 별개의 클래스 생성 방식
context.execute(new StrategyLogic());
// 익명 클래스 방식
context.execute(new Strategy() {
@Override
public void call() {
// 위임 로직
}
});
// 람다 방식
context.execute(() -> {
// 위임 로직
});
Java
복사
이처럼 해당 인터페이스의 구현체를 바꿔끼워 위임 로직을 쉽게 바꿀 수 있으면서도, 템플릿 메서드 패턴의 문제인 상속을 하지 않고 람다를 통해 익명 클래스도 깔끔하게 정리할 수 있다.
템플릿 콜백 패턴
전략 패턴에서 처럼 외부에서 파라미터로 넘겨주어 실행 가능한 코드를 콜백(callback)이라 한다. 코드가 호출(call)되는 시점이 코드를 넘겨주는 지점보다 나중(뒤, back)에 실행된다는 의미이다.
자바에서는 보통 하나의 메서드를 가진 인터페이스를 익명 내부 클래스를 통해 사용해왔고, Java 8부터는 람다를 이용해 실행 가능한 코드를 인수로 넘길 수 있게 되었다.
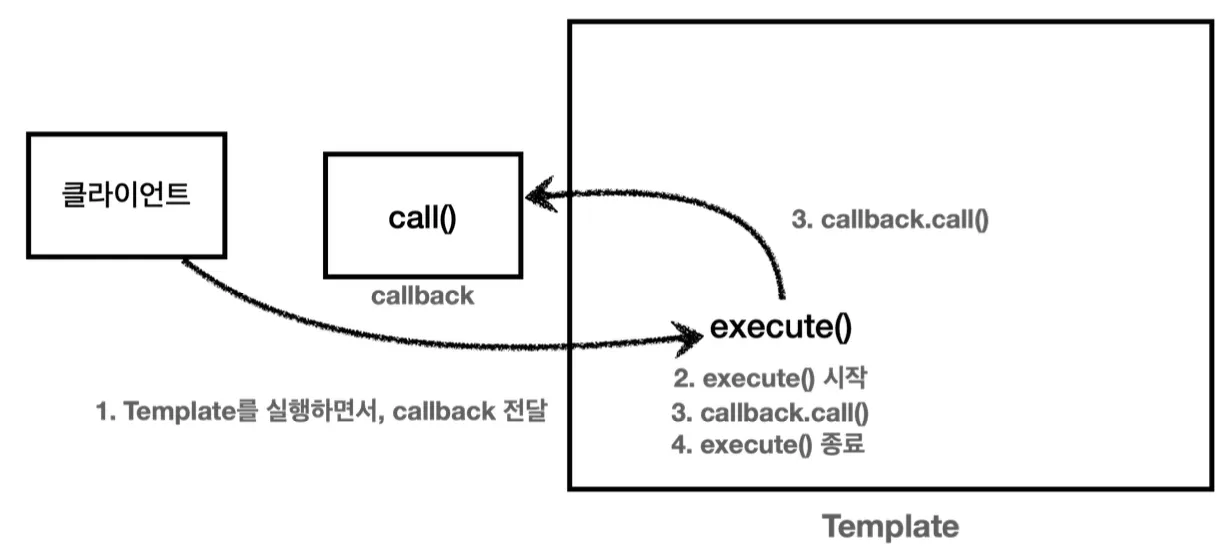
스프링에서는 이와 같이 인수 형태로 코드를 넘기는 전략 패턴을 템플릿 콜백 패턴이라 부른다. Context가 템플릿 역할을 수행하고, Strategy 부분이 콜백으로 넘어가게 된다. 이는 스프링 내부에서만 부르는 패턴으로, 전략 패턴에서 템플릿과 콜백이 강조된 의미라고 생각하면 된다. 스프링의 JdbcTemplate, RestTemplate, TransactionTemplate, RedisTemplate처럼 xxxTemplate 형태는 전부 템플릿 콜백 패턴이 사용되었다고 보면 된다.
그럼 템플릿 콜백 패턴을 통해 로그 추적기 코드를 수정해보자.
public interface TraceCallback<T> {
T call();
}
Java
복사
public class TraceTemplate {
private final LogTrace trace;
public TraceTemplate(LogTrace trace) {
this.trace = trace;
}
public <T> T execute(String message, TraceCallback<T> callback) {
TraceStatus status = null;
try {
status = trace.begin(message);
// 로직 호출
T result = callback.call();
trace.end(status);
return result;
} catch (Exception e) {
trace.exception(status, e);
throw e;
}
}
}
Java
복사
이와 같이 템플릿과 콜백을 작성하고,
@GetMapping("/v5/request")
public String request(String itemId) {
return template.execute("OrderController.request()", () -> {
orderService.orderItem(itemId);
return "ok";
});
}
Java
복사
람다식과 함께 적용하면 이처럼 코드가 간결해진다.
프록시 패턴과 데코레이터 패턴
위에서 로그 추적기를 개선해왔지만 아직도 문제가 남아있다. 로그 추적기를 추가할 모든 메서드에서 template.execute를 통해서 직접 로그 추적기를 호출해주어야 한다는 점이다. 이를 해결하기 위해서는 프록시 개념을 이해해야 한다.
프록시

일반적으로 이와 같이 요청을 하는 측을 클라이언트, 해당 요청을 받아 처리하는 측을 서버라고 부른다.

클라이언트가 서버에 요청을 할 때는 이와 같이 직접 호출하는 방법과,

해당 작업을 대신 처리해주는 대리자를 통해 간접적으로 호출하는 방법이 있다. 이렇게 요청을 대신해서 처리해주는 대리자를 프록시(Proxy)라 부른다.
특정 객체에 프록시를 적용하려면 요청을 처리하는 서버 객체가 프록시로 변경되어도 클라이언트 코드에 변경이 발생하면 안된다.
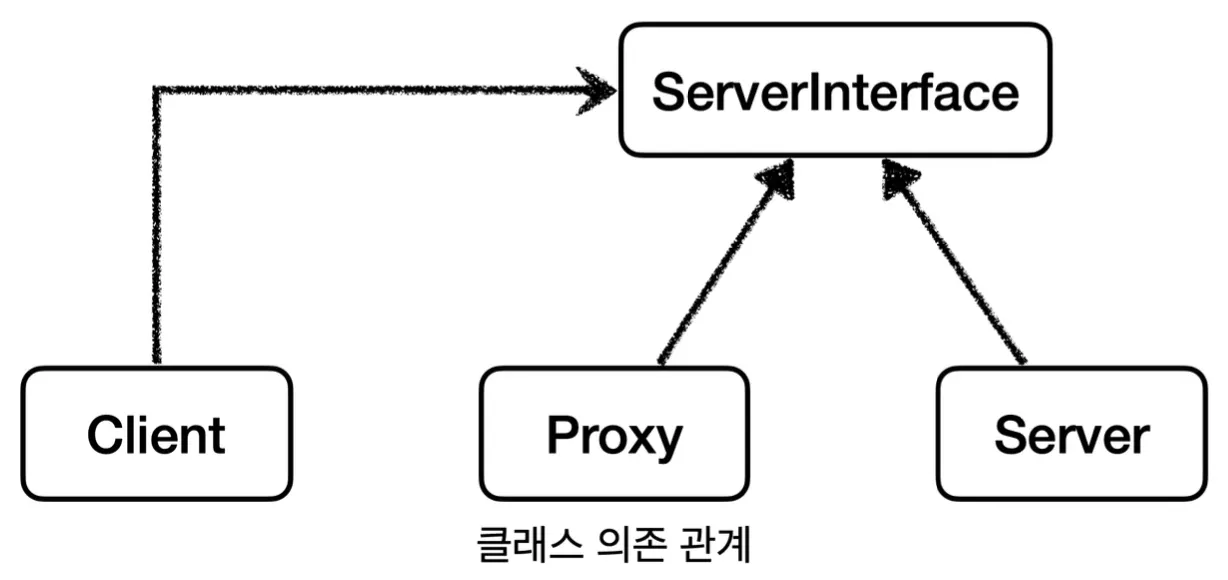
때문에 프록시 객체와 서버 객체는 같은 인터페이스를 구현하고 있어야 한다.

이렇게 클라이언트가 서버에 요청을 보낼 때,

의존성 주입을 통해 서버 대신 프록시로 의존 관계를 변경하더라도 클라이언트에서는 코드 변경이 없고 변경 내용을 몰라야 한다는 점이다. 이를 통해 DI로 유연하게 프록시를 주입할 수 있어야 한다.
이러한 프록시는 여러 역할을 수행할 수 있다.
•
접근 제어
◦
요청을 서버에 전달하기 전에 클라이언트가 해당 요청에 대한 권한이 있는지 확인
◦
이전에 수행된 요청인지 확인하여, 캐싱된 내용이 있다면 서버에 요청을 전달하지 않고 캐싱 결과를 반환하여 빠르게 요청을 처리
◦
JPA의 지연 로딩처럼 실제 데이터가 필요한 시점까지 데이터의 호출을 미루어 성능을 최적화
•
부가 기능 추가
◦
원래 서버의 기능에 더해 부가 기능을 수행
◦
ex) 실행 시간을 측정해 요청을 처리하기까지 걸린 시간을 로그로 남김
두 가지 기능 모두 프록시가 수행할 수 있는 역할이지만, GOF 디자인 패턴에서는 이 두 가지를 구분하여 의도(intent)에 따라 프록시 패턴(접근 제어 목적)과 데코레이터 패턴(부가 기능 추가 목적)으로 구분한다.
프록시 패턴
간단한 예제를 통해 프록시 패턴을 이해해보자.
public interface Subject {
String operation();
}
Java
복사
@Slf4j
public class RealSubject implements Subject {
@Override
public String operation() {
log.info("실제 객체 호출");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Java
복사
이와 같이 Subject 인터페이스와 그를 구현하는 RealSubject를 만들고,
public class ProxyPatternClient {
private Subject subject;
public ProxyPatternClient(Subject subject) {
this.subject = subject;
}
public void execute() {
subject.operation();
}
}
Java
복사
주입 받은 Subject에 요청을 호출하는 클라이언트가 있다.
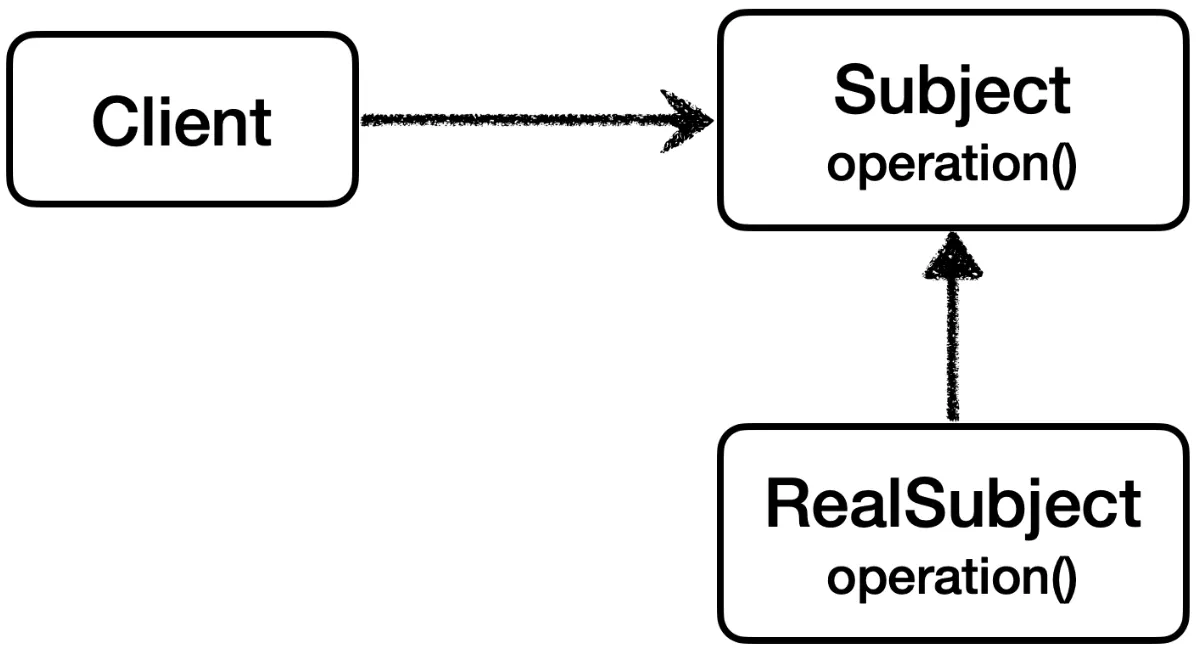
클라이언트에서는 Subject를 보고 있고, RealSubject가 해당 인터페이스를 구현하여 클라이언트의 요청을 처리하는 구조를 가진다.

클라이언트의 요청은 이와 같이 직접 서버를 호출하여 처리하게 된다.
@Test
void noProxyTest() {
RealSubject realSubject = new RealSubject();
ProxyPatternClient client = new ProxyPatternClient(realSubject);
client.execute();
client.execute();
client.execute();
}
Java
복사
그 후 이와 같이 요청을 3번 보내게 되면, 내부적으로 sleep(1000)을 수행하기 때문에 총 3초가 걸리게 된다.
여기에 프록시 객체를 통해 캐싱을 적용해보자.
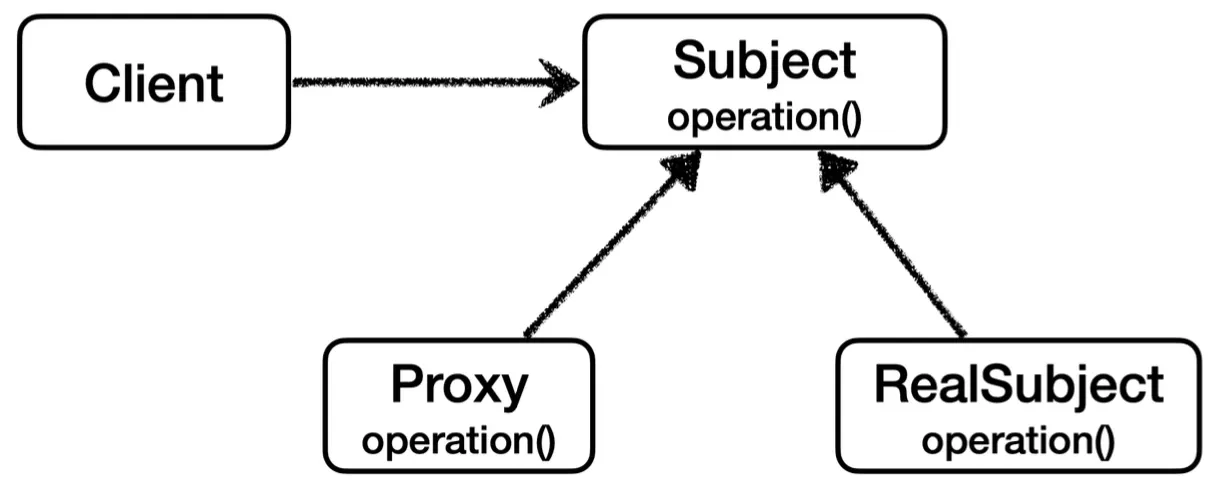
이와 같이 Subject를 구현하는 프록시 객체를 추가할 것이고,

이를 통해 클라이언트에서는 프록시를 통해 realSubject 객체에 간접적으로 요청을 보낼 것이다.
@Slf4j
public class CacheProxy implements Subject {
private Subject target;
private String cacheValue;
public CacheProxy(Subject target) {
this.target = target;
}
@Override
public String operation() {
log.info("프록시 호출");
if (cacheValue == null) {
cacheValue = target.operation();
}
return cacheValue;
}
}
Java
복사
이와 같이 프록시 객체를 작성해주고,
@Test
void cacheProxyTest() {
Subject realSubject = new RealSubject();
Subject cacheProxy = new CacheProxy(realSubject);
ProxyPatternClient client = new ProxyPatternClient(cacheProxy);
client.execute();
client.execute();
client.execute();
}
Java
복사
위와 동일하게 요청을 3번 보내게 되면, 첫 요청에만 내부적으로 sleep(1000)을 수행하고 그 뒤의 요청은 캐시된 값을 통해 즉시 처리하여 1초만 걸리게 된다.
데코레이터 패턴
마찬가지로 간단한 예시를 통해 데코레이터 패턴을 이해해보자.
public interface Component {
String operation();
}
Java
복사
@Slf4j
public class RealComponent implements Component {
@Override
public String operation() {
log.info("RealComponent 실행");
return "data";
}
}
Java
복사
이와 같이 Component 인터페이스와 그를 구현하는 RealComponent를 만들고,
@Slf4j
public class DecoratorPatternClient {
private Component component;
public DecoratorPatternClient(Component component) {
this.component = component;
}
public void execute() {
String result = component.operation();
log.info("result = {}", result);
}
}
Java
복사
주입 받은 Component에 요청을 호출하는 클라이언트가 있다.
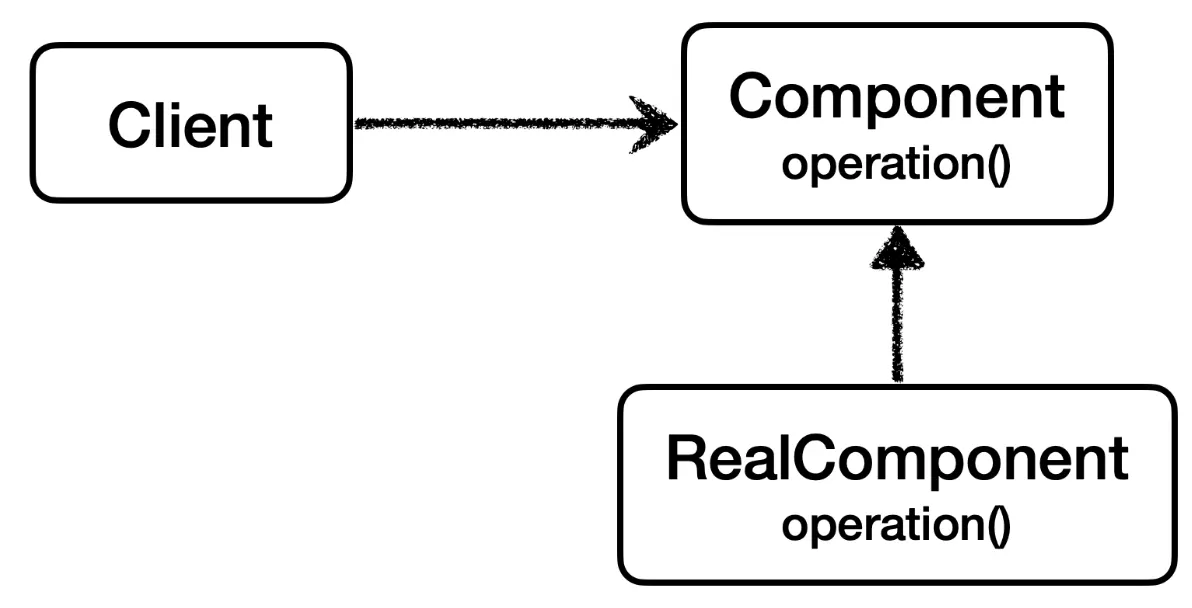
클라이언트에서는 Component를 보고 있고, RealComponent가 해당 인터페이스를 구현하여 클라이언트의 요청을 처리하는 구조를 가진다.

클라이언트의 요청은 이와 같이 직접 서버를 호출하여 처리하게 된다.
@Test
void noDecorator() {
Component realComponent = new RealComponent();
DecoratorPatternClient client =
new DecoratorPatternClient(realComponent);
client.execute();
}
Java
복사
클라이언트에서 위와 같이 요청하면, 동작 결과인 data를 출력한다.
여기에 요청 결과 데이터를 가공하는 프록시를 추가해보자.
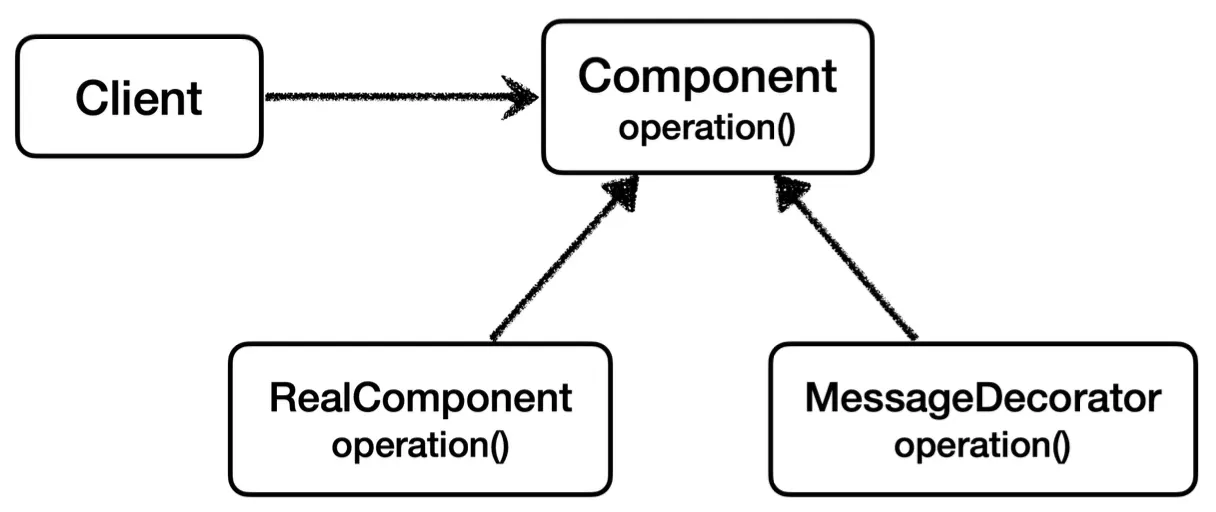
이와 같이 Component를 구현하는 프록시 객체를 추가하고,

이를 통해 클라이언트에서는 프록시를 통해 realComponent 객체에 간접적으로 요청을 보낼 것이다.
@Slf4j
public class MessageDecorator implements Component {
private Component component;
public MessageDecorator(Component component) {
this.component = component;
}
@Override
public String operation() {
log.info("MessageDecorator 실행");
String result = component.operation();
String decoResult = "[" + result + "]";
log.info("MessageDecorator 적용, {} -> {}", result, decoResult);
return decoResult;
}
}
Java
복사
이와 같이 프록시 객체를 작성해주고,
@Test
void decoratorTest1() {
Component realComponent = new RealComponent();
Component messageDecorator = new MessageDecorator(realComponent);
DecoratorPatternClient client =
new DecoratorPatternClient(messageDecorator);
client.execute();
}
Java
복사
위와 같이 메세지 데코레이터 프록시 객체를 클라이언트에 주입하여 동작 시키면, [data]를 출력하는 것을 확인할 수 있다.
여기에 프록시 체인을 통해 하나의 프록시 객체를 더 추가해보자.
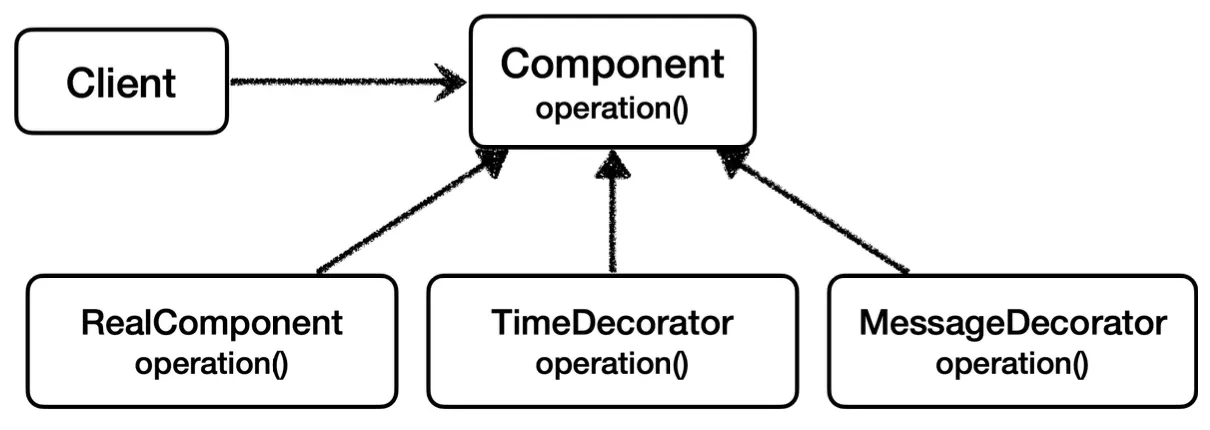
이와 같이 Component를 구현하는 TimeDecorator를 추가하고,

프록시 체인을 통해 순차적으로 프록시 객체들을 호출 후 서버에 요청을 전달하도록 만들 것이다.
@Slf4j
public class TimeDecorator implements Component {
private Component component;
public TimeDecorator(Component component) {
this.component = component;
}
@Override String operation() {
log.info("TimeDecorator 실행");
long startTime = System.currentTimeMillis();
String result = component.operation();
long endTime = System.currentTimeMillis();
log.info("실행 시간 = {}", endTime - startTime);
return result;
}
}
Java
복사
이와 같이 다음 Component를 호출하는 과정을 감싸서 동작 시간을 출력하는 프록시 객체를 작성하고,
@Test
void decoratorTest1() {
Component realComponent = new RealComponent();
Component messageDecorator = new MessageDecorator(realComponent);
Component timeDecorator = new TimeDecorator(messageDecorator);
DecoratorPatternClient client =
new DecoratorPatternClient(timeDecorator);
client.execute();
}
Java
복사
클라이언트에서 요청을 수행하면 [data] 결과와 실행 시간이 출력되는 것을 확인할 수 있다.
이러한 데코레이터 패턴을 살펴보면, Component을 필드로 들고 있는 부분과 생성자 부분과 같이 내부 구조는 동일하고 operation 메서드 내부의 부가 기능 로직만 다른 것을 확인할 수 있다.
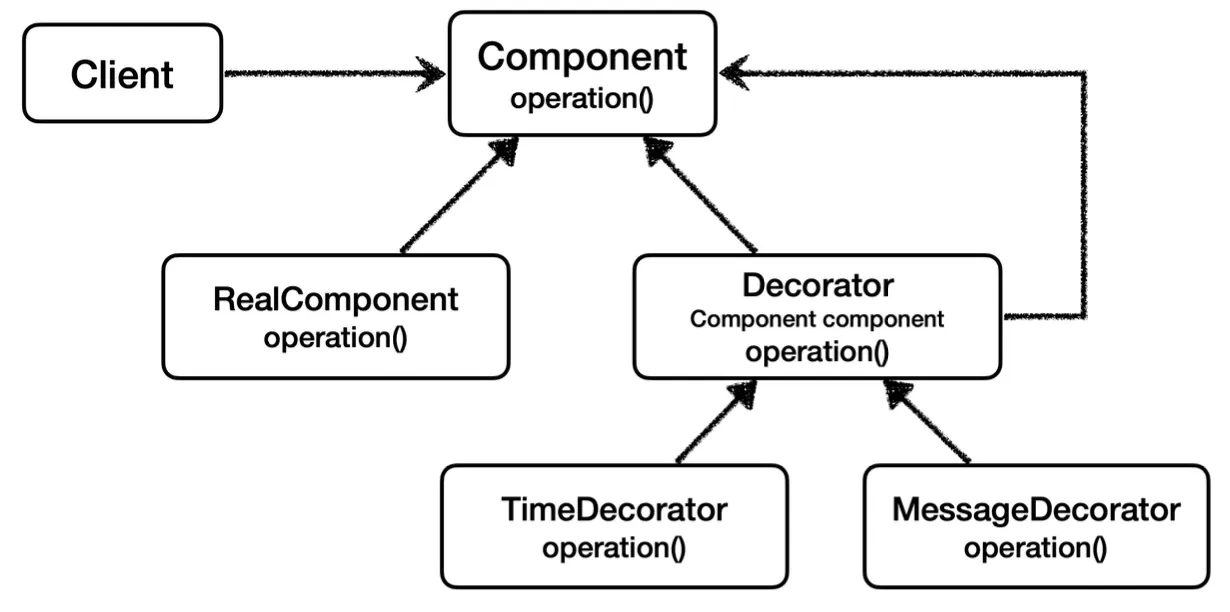
때문에 GOF 데코레이터 패턴에서는 위와 같이 operation 로직만 받아서 처리하는 추가적인 전략 패턴을 적용하기도 한다.
프록시 적용하기
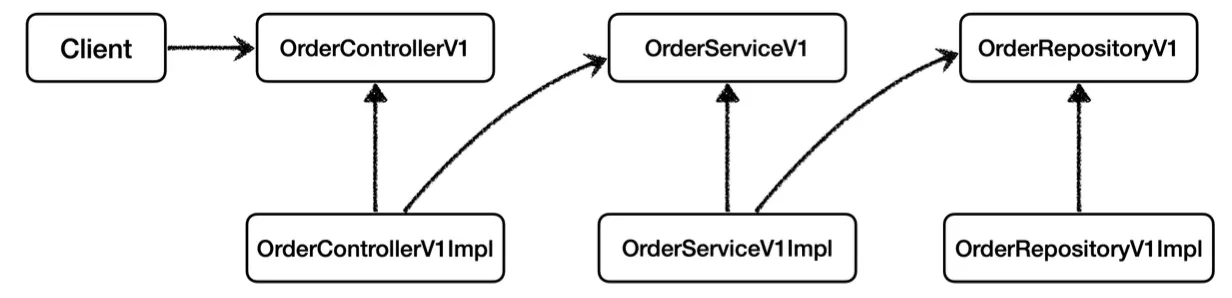
먼저 이와 같이 컨트롤러, 서비스, 레포지토리 계층이 인터페이스에 의존하는 구조에서 프록시를 통해 로그 추적기를 적용해보자.

프록시 적용 전 의존관계는 위와 같다.
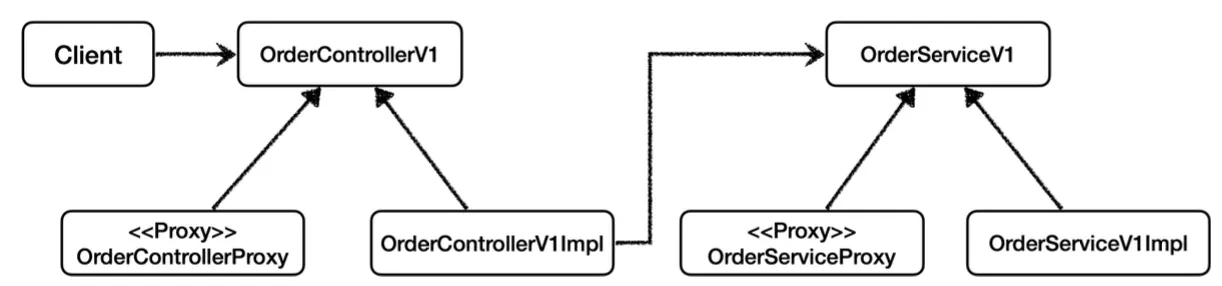
여기에 위와 같이 각 계층마다 로그 추적기 기능을 추가할 프록시 객체들을 추가한다.
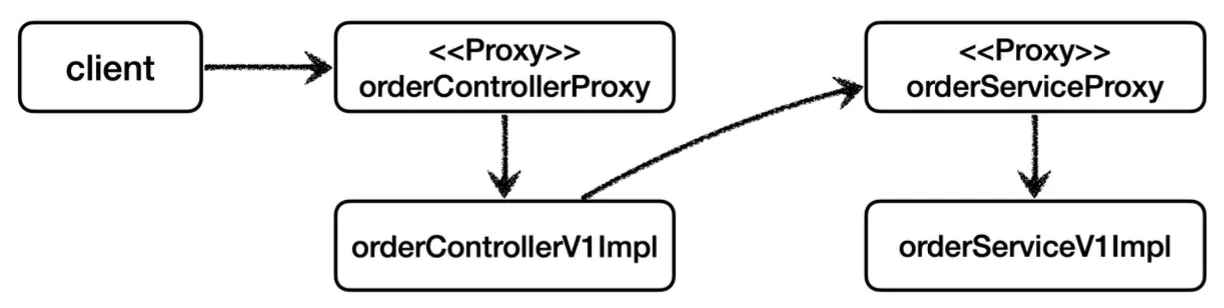
프록시 객체들을 통해 데코레이터 패턴을 적용하여 의존관계를 위처럼 변경할 것이다.
@RequiredArgsConstructor
public class OrderRepositoryInterfaceProxy implements OrderRepositoryV1 {
private final OrderRepositoryV1 target;
private final LogTrace logTrace;
public void save(String itemId) {
TraceStatus status = null;
try {
status = logTrace.begin("OrderRepository.save()"); //target 호출
target.save(itemId);
logTrace.end(status);
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}
Java
복사
위와 같이 컨트롤러와 서비스, 레포지토리에 각각 로그 추적기 로직을 포함하는 프록시 객체를 생성한다.
@Configuration
public class InterfaceProxyConfig {
@Bean
public OrderControllerV1 orderController(LogTrace logTrace) {
OrderControllerV1Impl controllerImpl = new
OrderControllerV1Impl(orderService(logTrace));
return new OrderControllerInterfaceProxy(controllerImpl, logTrace);
}
@Bean
public OrderServiceV1 orderService(LogTrace logTrace) {
OrderServiceV1Impl serviceImpl = new
OrderServiceV1Impl(orderRepository(logTrace));
return new OrderServiceInterfaceProxy(serviceImpl, logTrace);
}
@Bean
public OrderRepositoryV1 orderRepository(LogTrace logTrace) {
OrderRepositoryV1Impl repositoryImpl = new OrderRepositoryV1Impl();
return new OrderRepositoryInterfaceProxy(repositoryImpl, logTrace);
}
}
Java
복사
위와 같이 직접 스프링 빈을 등록하는 과정에서, 각 계층을 등록하는 것이 아니라 각 계층을 주입 받은 프록시 객체들을 등록한다.
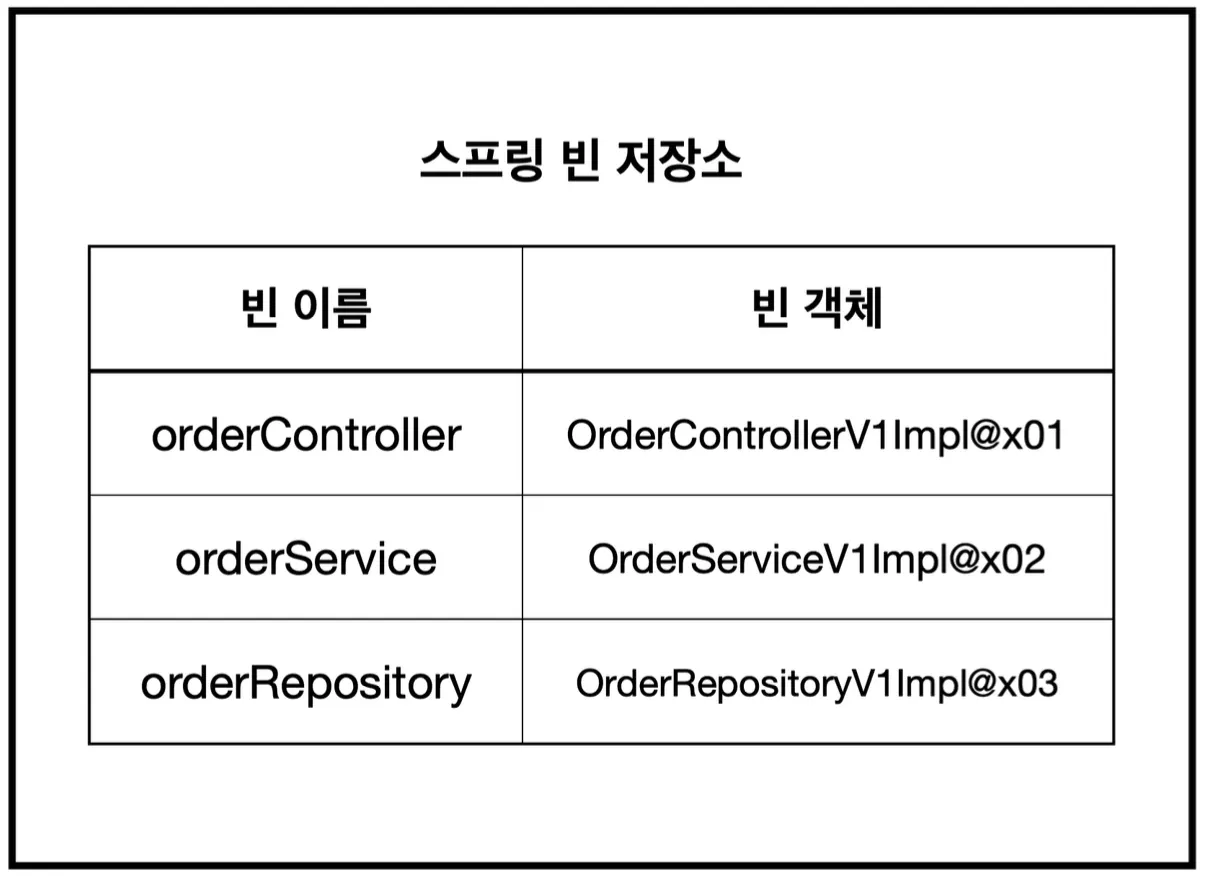
기존의 스프링 빈이 이와 같이 등록되어 있었다면,
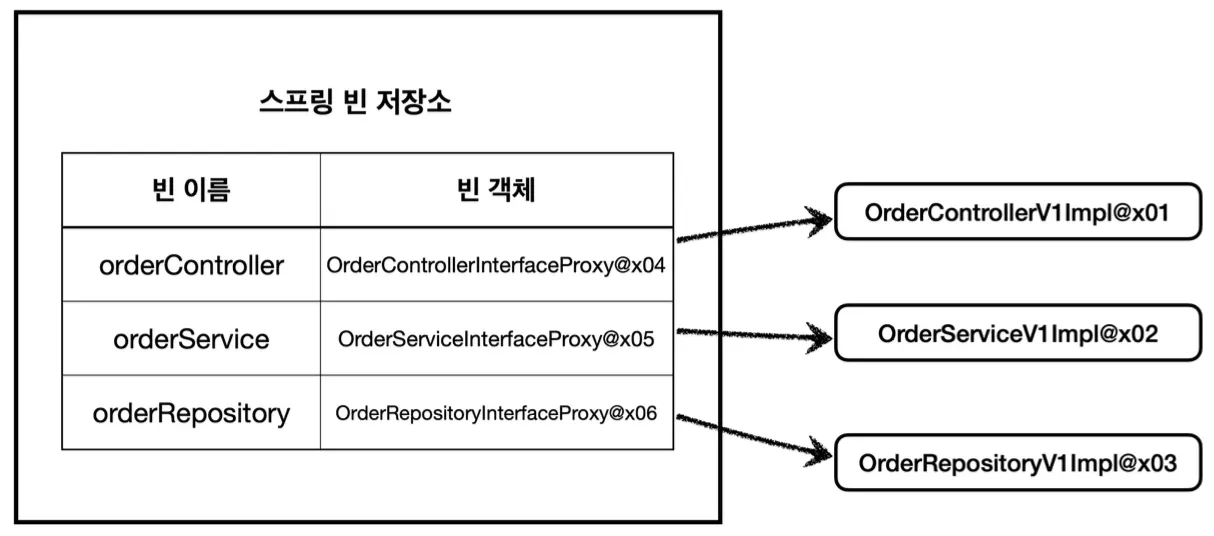
프록시 적용 후에는 이처럼 컨트롤러, 서비스, 레포지토리를 의존하고 있는 프록시 객체가 스프링 빈에 등록된다.
이를 통해 우리는 기존의 컨트롤러, 서비스, 레포지토리의 로직을 전혀 수정없이 로그 추적기를 적용했다.
구체 클래스(콘크리트 클래스)에 프록시 적용하기
그렇다면 인터페이스가 없는 구체 클래스에는 프록시를 어떻게 적용할 수 있는지 알아보자.
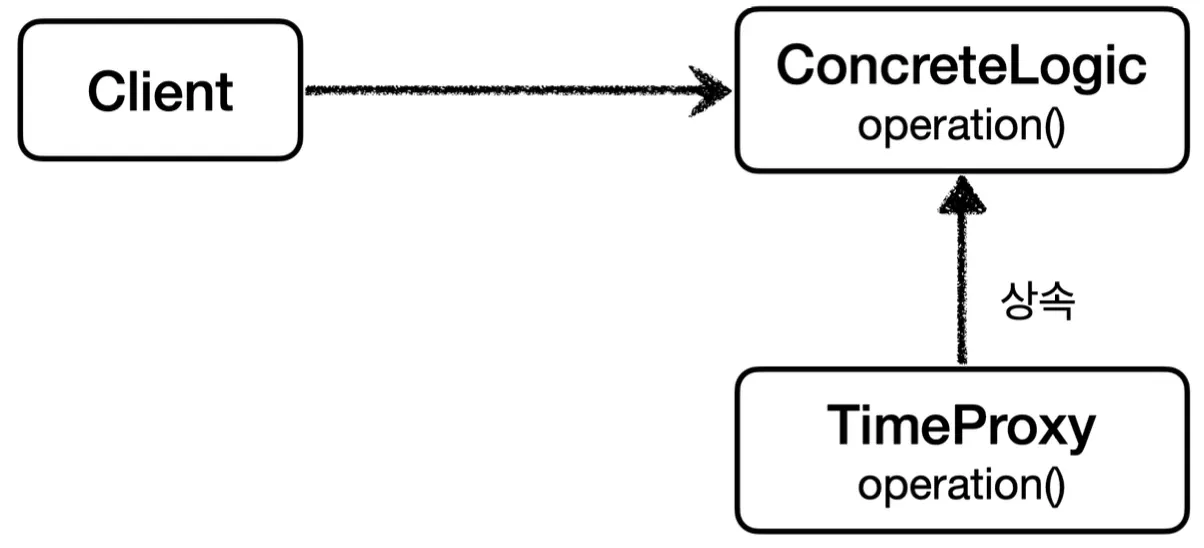
인터페이스가 없는 구체 클래스에는 다형성을 적용하기 어려워 보이지만, 해당 구체 클래스를 상속 받는 클래스를 만들면 다형성을 사용할 수 있다.

이는 자바의 다형성으로 부모 클래스 타입에는 자식 클래스 인스턴스를 선언할 수 있기 때문에, 이를 활용해 위와 같이 프록시를 적용할 수 있다.
public class OrderServiceConcreteProxy extends OrderServiceV2 {
private final OrderServiceV2 target;
private final LogTrace logTrace;
public OrderServiceConcreteProxy(OrderServiceV2 target, LogTrace logTrace) {
super(null);
this.target = target;
this.logTrace = logTrace;
}
@Override
public void orderItem(String itemId) {
TraceStatus status = null;
try {
status = logTrace.begin("OrderService.orderItem()"); //target 호출
target.orderItem(itemId);
logTrace.end(status);
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}
Java
복사
이와 같이 기존의 서비스 계층을 상속받는 서비스 프록시를 만든다. 위 코드를 보면 생성자에서 super(null)을 확인할 수 있는데, 이는 서비스 계층에는 repository를 주입 받는 생성자 밖에 존재하지 않기 때문에 사용하지 않을 repository 대신 null을 넣어 호출해주어야 한다.
@Configuration
public class ConcreteProxyConfig {
@Bean
public OrderControllerV2 orderControllerV2(LogTrace logTrace) {
OrderControllerV2 controllerImpl = new
OrderControllerV2(orderServiceV2(logTrace));
return new OrderControllerConcreteProxy(controllerImpl, logTrace);
}
@Bean
public OrderServiceV2 orderServiceV2(LogTrace logTrace) {
OrderServiceV2 serviceImpl = new
OrderServiceV2(orderRepositoryV2(logTrace));
return new OrderServiceConcreteProxy(serviceImpl, logTrace);
}
@Bean
public OrderRepositoryV2 orderRepositoryV2(LogTrace logTrace) {
OrderRepositoryV2 repositoryImpl = new OrderRepositoryV2();
return new OrderRepositoryConcreteProxy(repositoryImpl, logTrace);
}
}
Java
복사
빈 등록 역시 인터페이스 대신 구체 클래스를 사용한다는 것을 제외하고 기존과 동일하다.
위를 보면 알 수 있듯, 클래스 기반 구체 클래스 프록시는 상속을 사용하기 때문에 몇 가지 제약을 받는다.
•
부모 클래스의 생성자를 호출해야 한다.
•
클래스에 final 키워드가 붙어있으면 상속이 불가능하다.
•
메서드에 final 키워드가 붙으면 해당 메서드를 재정의 할 수 없다.
이와 같은 제약 사항들 때문에, 프록시를 적용한다면 인터페이스 기반의 프록시가 더 자유롭고, 역할과 구현을 명확하게 구분하기 때문에 프로그래밍 관점에서도 더 좋다.
동적 프록시
프록시를 적용한 코드를 살펴보면, 일단 프록시 객체를 너무 많이 생성해야하고 모든 프록시 객체가 LogTrace를 동작하는 것으로 내부 로직이 동일하다. 이를 해결하기 위해 동적 프록시를 적용하여, 하나의 프록시만 만들어서 모든 곳에 적용할 수 있다.
Java의 리플렉션
@Slf4j
static class Hello {
public String callA() {
log.info("callA");
return "A";
}
public String callB() {
log.info("callB");
return "B";
}
}
@Test
void reflection0() {
Hello target = new Hello();
log.info("start");
String result1 = target.callA();
log.info("result={}, result1);
log.info("start");
String result2 = target.callB();
log.info("result={}, result2);
}
Java
복사
위와 같은 로직이 있다고 할 때, callA와 callB를 호출하고 로그를 찍는 동일한 로직 중복을 리플렉션을 통해 해소할 수 있다.(람다식으로도 가능하지만 리플렉션 학습을 위해 제외)
@Test
void reflection() throws Exception {
Class classHello
= Class.forName("hello.proxy.jdkdynamic.ReflectionTest$Hello");
Hello target = new Hello();
Method methodA = classHello.getMethod("callA");
dynamicCall(methodA, target);
Method methodB = classHello.getMethod("callA");
dynamicCall(methodB, target);
}
private void dynamicCall(Method method, Object target) throws Exception {
log.info("start");
Object result = method.invoke(target);
log.info("result={}", result);
}
Java
복사
이와 같이 리플렉션을 활용해 클래스 명으로 클래스 정보 가져오고 메서드 명을 통해 메서드 정보를 가져와, 동적으로 로직을 수정하여 간결하게 코드를 줄일 수 있다.
이처럼 동적으로 처리를 하기 때문에 유연하게 처리할 수 있지만, 리플렉션 기술은 런타임에 동작하기 때문에 컴파일 시점에 오류를 잡을 수 없다는 단점이 있다. 클래스 명이 틀리거나 메서드 명이 틀리는 경우와 같이, 오류가 있더라도 실제 동작 시점에 해당 오류가 발생하게 된다. 이러한 런타임 오류는 애플리케이션이 실행되고, 해당 로직이 직접 호출되기 전까지 발생하지 않는다. 개발자 입장에서 가장 좋은 오류는 컴파일 시점에 발생하여 즉각 수정 가능한 컴파일 오류이다.
추가적으로 리플렉션 기술은 오버헤드가 큰 기술이라 시스템 성능 측면에서 비효율적이다.
이러한 이유로 리플렉션 기술은 일반적으로 사용해서는 안되며, 프레임워크 개발이나 일반적인 공통 처리를 통해 큰 개선을 이루어낼 수 있는 경우에 부분적으로 주의해서 사용해야한다.
JDK 동적 프록시
자바에서는 기본으로 JDK 동적 프록시를 제공한다. 간단한 예제를 통해 동작을 이해해보자.
public interface AInterface {
String call();
}
@Slf4j
public class AImpl implements AInterface {
@Override
public String call() {
log.info("call A");
return "a";
}
}
Java
복사
public interface BInterface {
String call();
}
@Slf4j
public class BImpl implements BInterface {
@Override
public String call() {
log.info("call B");
return "b";
}
}
Java
복사
이와 같은 두 개의 인터페이스와 그 구현체가 있을 때, 여기에 시간 로그를 남기는 프록시를 JDK 동적 프록시로 적용해보자.
public interface InvocationHandler {
public Object invoke(Object proxy, Meethod method, Object[] args) throws Trowable;
}
Java
복사
먼저 JDK 동적 프록시는 InvocationHandler를 지원한다. 이를 구현하여 동적 프록시를 사용할 수 있다.
@Slf4j
public class TimeInvoationHandler implements InvocationHandler {
private final Object target;
public TimeInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Mehtod method, Object[] args) throws Throwable {
log.info("TimeProxy 실행");
long startTime = System.currentTimeMillis();
Object result = method.invoke(target, args);
long endTime = System.currentTimeMillis();
log.info("실행 시간 = {}", endTime - startTime);
return result;
}
}
Java
복사
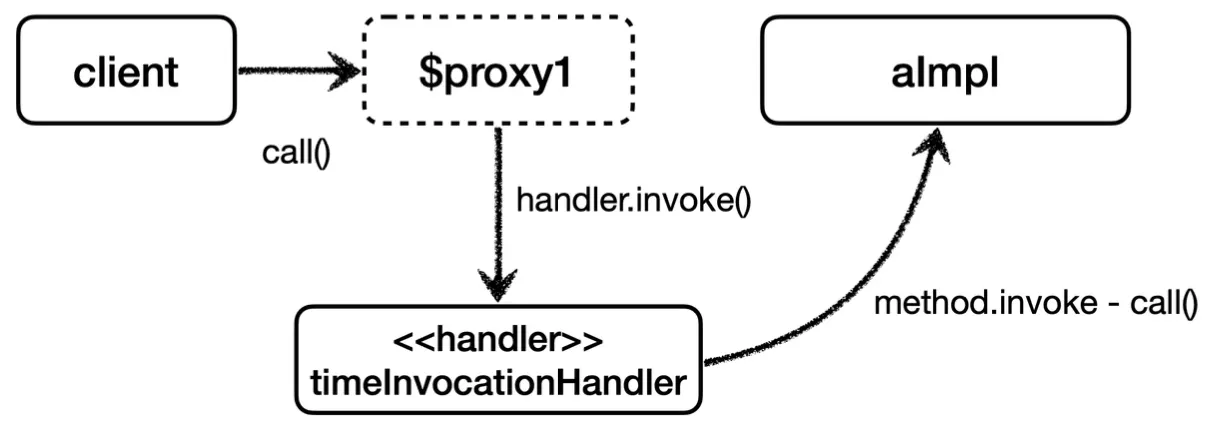
그 구현체를 작성하며, 프록시에 적용할 부가 기능 로직을 invoke 메서드에 추가해준다. 여기서 args는 실제 로직인 method.invoke를 호출할 때 넘겨줄 인수들이다.
JDK 동적 프록시를 사용하는 방법은,
@Test
void dynamicA() {
AInterface target = new AImpl();
TimeInvocationHandler handler = new TimeInvocationHandler(target);
AInterface proxy = (AInterface) Proxy.newProxyInsance(
AInterface.class,
new Class[]{AInterface.class},
handler
);
proxy.call();
}
@Test
void dynamicB() {
BInterface target = new BImpl();
TimeInvocationHandler handler = new TimeInvocationHandler(target);
BInterface proxy = (BInterface) Proxy.newProxyInsance(
BInterface.class,
new Class[]{BInterface.class},
handler
);
proxy.call();
}
Java
복사
이전과 비슷하게 실제 객체를 넣어 프록시 객체를 생성한다. 자바에서 제공하는 JDK 동적 프록시의 Proxy.newProxyInsance를 통해 어떤 타입으로 받을지와 프록시로 사용할 로직이 들어있는 handler를 넘겨 프록시 객체를 동적으로 생성한다.
위 코드를 보면 동적 프록시를 통해 AInterface와 BInterface 각각 프록시 객체 생성 로직을 두는 것이 아니라, 동일한 InvocationHandler에 넘겨주는 클래스 정보만 바꾸어 생성하는 것을 확인할 수 있다.
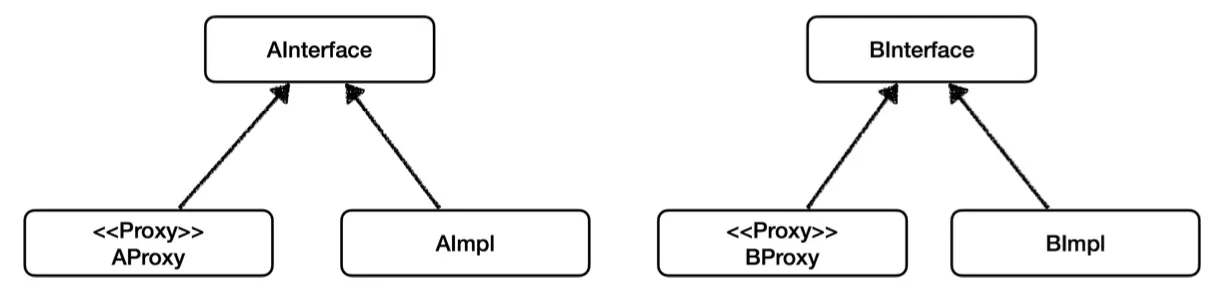
기존의 방식은 이처럼 직접 프록시 객체를 만들어 의존성을 주입하는 과정이였다면,
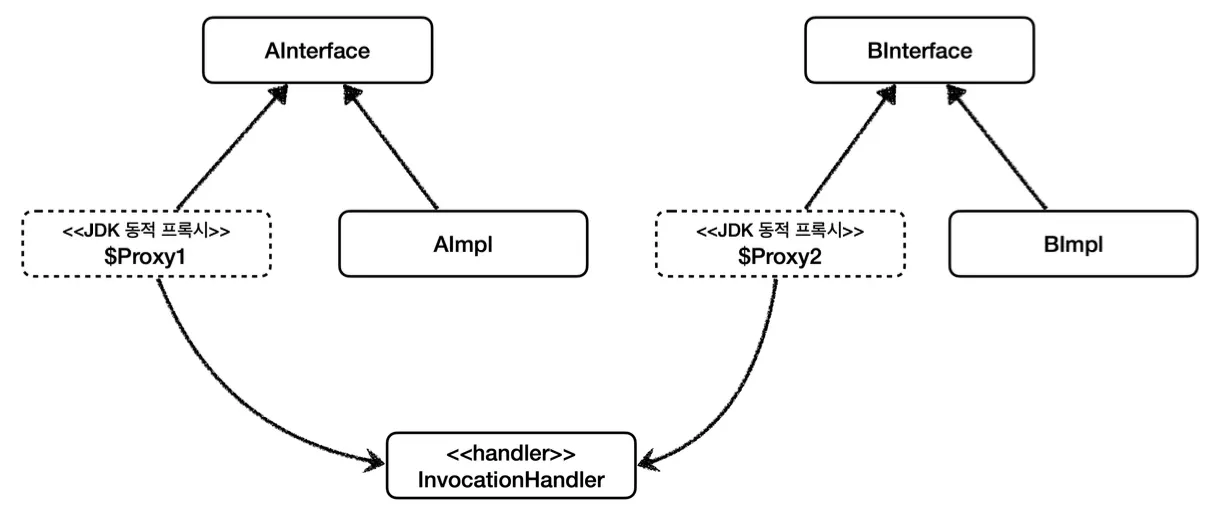
프록시 객체 생성을 직접 하지 않고 JDK 동적 프록시의 InvcationHandler를 통해 만드는 것이다.
JDK 동적 프록시 적용하기
JDK 동적 프록시를 로그 추적기에 적용해보자.
@RequiredArgsConstructor
public class LogTraceBasicHandler implements InvoationHandler {
private final Object target;
private final LogTrace = logTrace;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
TraceStatus status = null;
try {
String message = method.getDeclaringClass().getSimpleName()
+ "." + method.getName() + "()";
status = logTrace.begin(message);
//로직 호출
Object result = method.invoke(target, args);
logTrace.end(status);
return result;
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}
Java
복사
위와 같이 InvocationHandler 인터페이스를 구현하는 LogTraceBasicHandler를 작성한다. invoke 메서드 내부에 로그 추적기의 로직을 넣는다.
@Configuration
public class DynamicProxyBasicConfig {
@Bean
public OrderControllerV1 orderControllerV1(LogTrace logTrace) {
OrderControllerV1 orderController = new
OrderControllerV1Impl(orderServiceV1(logTrace));
OrderControllerV1 proxy = (OrderControllerV1) Proxy.newProxyInstance(
OrderControllerV1.class.getClassLoader(),
new Class[]{OrderControllerV1.class},
new LogTraceBasicHandler(orderController, logTrace));
return proxy;
}
@Bean
public OrderServiceV1 orderServiceV1(LogTrace logTrace) {
OrderServiceV1 orderService = new
OrderServiceV1Impl(orderRepositoryV1(logTrace));
OrderServiceV1 proxy = (OrderServiceV1) Proxy.newProxyInstance(
OrderServiceV1.class.getClassLoader(),
new Class[]{OrderServiceV1.class},
new LogTraceBasicHandler(orderService, logTrace)
);
return proxy;
}
@Bean
public OrderRepositoryV1 orderRepositoryV1(LogTrace logTrace) {
OrderRepositoryV1 orderRepository = new OrderRepositoryV1Impl();
OrderRepositoryV1 proxy = (OrderRepositoryV1) Proxy.newProxyInstance(
OrderRepositoryV1.class.getClassLoader(),
new Class[]{OrderRepositoryV1.class},
new LogTraceBasicHandler(orderRepository, logTrace)
);
return proxy;
}
}
Java
복사
이후 스프링 빈에 등록할 때, 이와 같이 JDK 동적 프록시를 통해 각 계층의 프록시 객체를 생성하여 등록한다.
JDK 동적 프록시를 적용하면
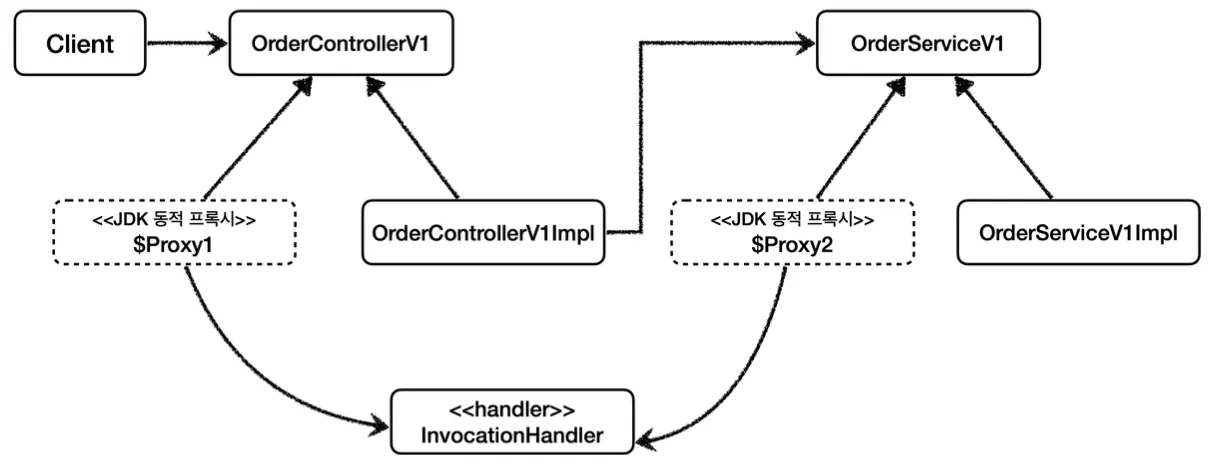
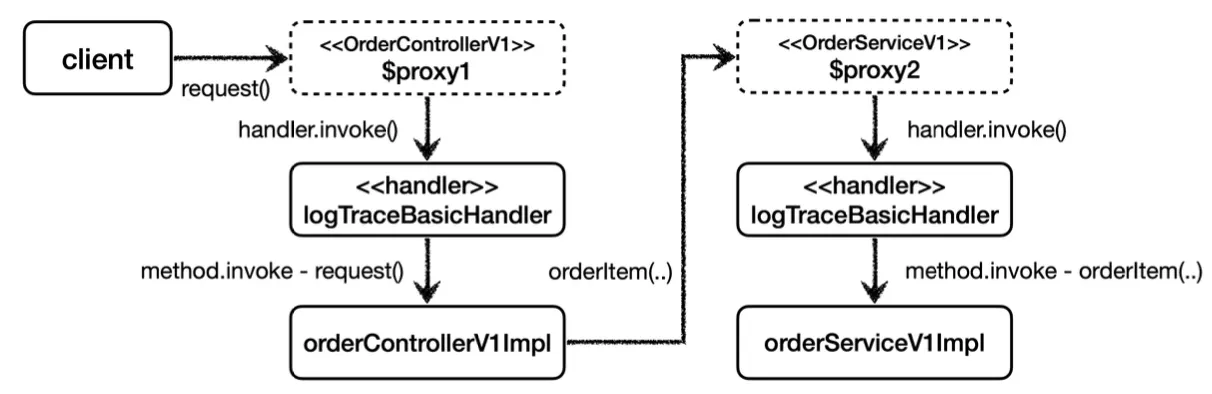
이와 같은 의존 관계를 가지게 된다.
위 코드를 실행시켜보면, 모든 메서드에서 항상 로그가 남게 된다. 이를 패턴을 적용해 특정 메서드만 실행하도록 만들어보자.
@RequiredArgsConstructor
public class LogTraceFilterHandler implements InvocationHandler {
private final Object target;
private final LogTrace logTrace;
private final String[] patterns;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 메서드 명으로 필터링
String methodName = method.getName();
if (PatternMatchUtils.simpleMatch(patterns, methodName)) {
return method.invoke(target, args);
}
...
}
}
Java
복사
이처럼 프록시 생성 시에 패턴을 넘겨받아 해당 패턴에 맞지 않는 경우에는 로그를 적용하지 않도록 만들 수 있다.
@Configuration
public class DynamicProxyFilterConfig {
private static final String[] PATTERNS = {"request*", "order*", "save*"};
@Bean
public OrderControllerV1 orderControllerV1(LogTrace logTrace) {
OrderControllerV1 orderController = new
OrderControllerV1Impl(orderServiceV1(logTrace));
OrderControllerV1 proxy = (OrderControllerV1) Proxy.newProxyInstance(
OrderControllerV1.class.getClassLoader(),
new Class[]{OrderControllerV1.class},
new LogTraceFilterHandler(orderController, logTrace, PATTERNS));
return proxy;
}
...
}
Java
복사
빈 등록 시에 각 계층별로 원하는 패턴을 넣어 로그 추적기를 적용할 메서드를 지정할 수 있다.
CGLIB
하지만 위의 JDK 동적 프록시의 경우 반드시 인터페이스가 존재해야만 사용할 수 있다. 인터페이스가 없는 경우에는 CGLIB라는 바이트코드를 조작하는 라이브러리를 통해 구체 클래스만으로 동적 프로시를 만들 수 있다.
public interface MethodInterceptor extends Callback {
Object intercept(Object obj, Mehtod method, Object[] args, MethodProxy proxy) throws Throwable;
}
Java
복사
CGLIB에는 JDK 동적 프록시와 거의 비슷한 형태의 MethodInterceptor 인터페이스를 제공한다.
@Slf4j
public class TimeMethodInterceptor implements MehtodInterceptor {
private final Object target;
public TimeMethodInterceptor(Object target) {
this.target = target;
}
@Override
public Object intercept(Object obj, Mehtod method, Object[] args, MethodProxy proxy) throws Throwable {
...
Object result = proxy.invoke(target, args);
...
return result;
}
}
Java
복사
JDK 동적 프록시의 Handler처럼 Interceptor를 작성하여 동적으로 프록시를 생성하는 것이 가능하다.
@Test
void cglib() {
ConcreteService target = new ConcreteService();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(ConcreteService.class);
enhancer.setCallback(new TimeMethodInterceptor(target));
ConcreteService proxy = (ConcreteService) enhancer.create();
proxy.call();
}
Java
복사
프록시를 생성하고 호출하는 과정은 이와 같이 Enhancer를 통해 상속 받을 구체 클래스를 지정하고(setSuperclass), 프록시에 적용할 실행 로직을 할당하여(setCallback) 사용할 수 있다.
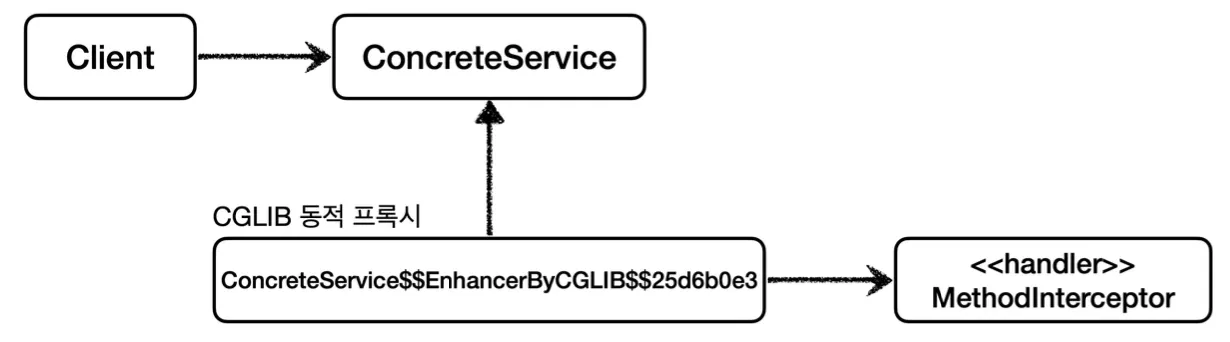
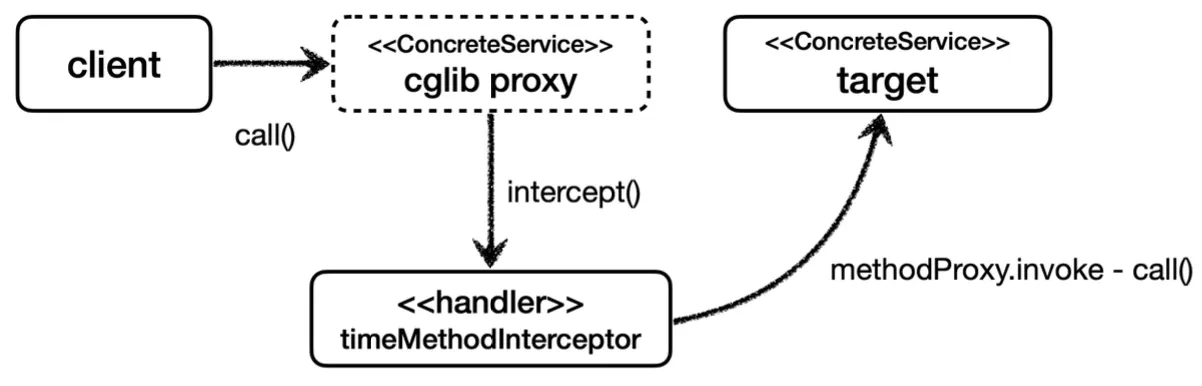
CGLIB를 사용한 동적 프록시 생성의 경우 위와 같은 의존 관계를 가진다.
하지만 이런 CGLIB를 통한 프록시 생성의 경우, 상속을 사용해 프록시를 생성하기 때문에 템플릿 메서드 패턴과 마찬가지로 상속으로 인한 몇 가지 제약사항을 갖는다.
•
프록시 클래스를 동적으로 생성하기 때문에 부모 클래스의 기본 생성자가 필요하다.
•
클래스에 final이 붙으면 CGLIB에서는 예외를 발생시킨다.
•
메서드에 final이 붙으면 CGLIB에서는 해당 프록시 로직이 동작하지 않는다.
스프링의 프록시
프록시 팩토리
인터페이스가 있는 경우에는 JDK 동적 프록시를 사용해야하고, 구체 클래스의 경우 CGLIB를 적용해야한다. 하지만 동일한 프록시 로직을 인터페이스와 구체 클래스 모두에 적용하고 싶은 경우에는, InvocationHandler와 MethodInterceptor를 모두 작성해야한다는 문제가 있다.
스프링에서는 이와 같이 유사한 구체적인 기술들이 있을 때, 그것들을 통합하여 일관성 있게 접근할 수 있고 더욱 편리하게 사용할 수 있도록 추상화하여 제공한다. 이러한 동적 프록시의 경우에는, 스프링에서 프록시 팩토리(ProxyFactory)라는 기술로 추상화하여 제공한다.
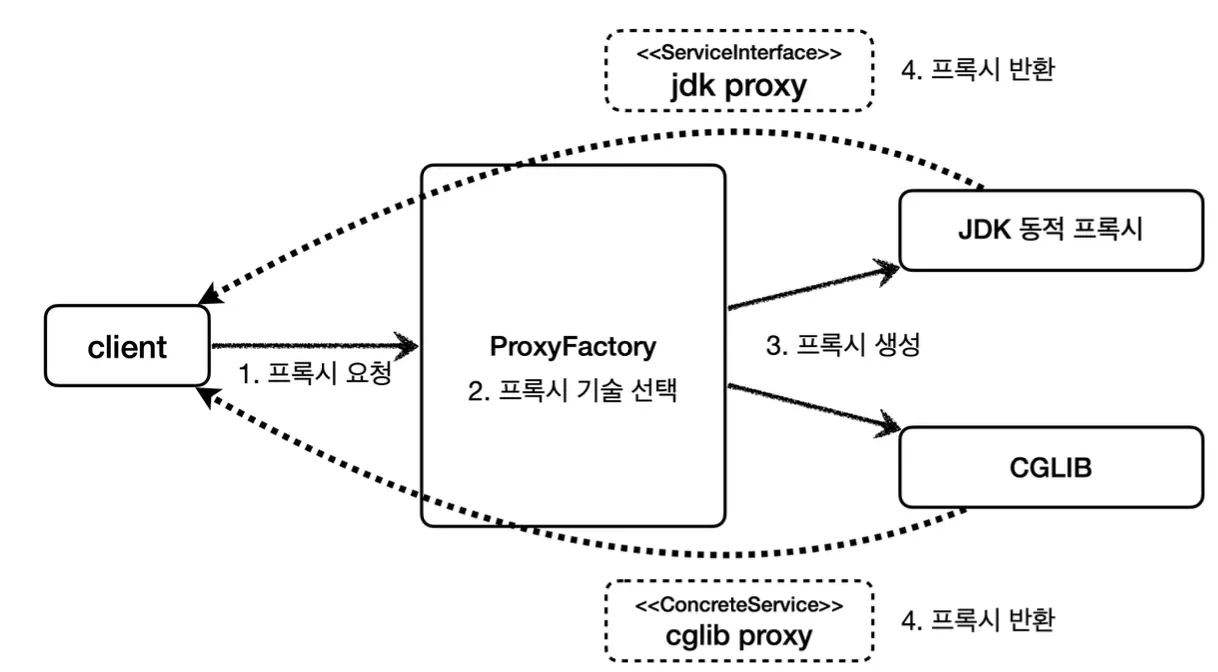
스프링은 프록시 팩토리에서 인터페이스와 구체 클래스 여부에 따라 내부적으로 프록시 기술을 선택하도록 만들었다.
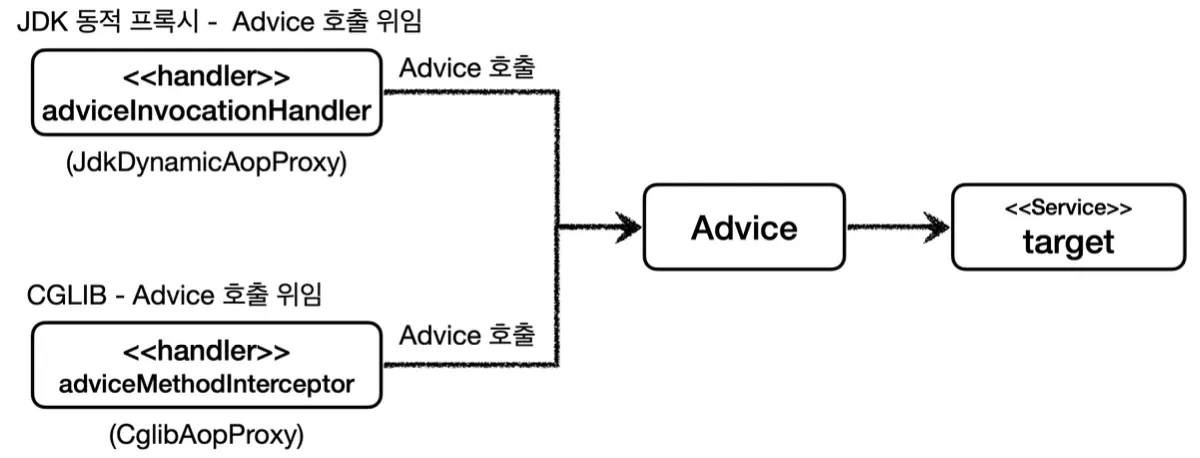
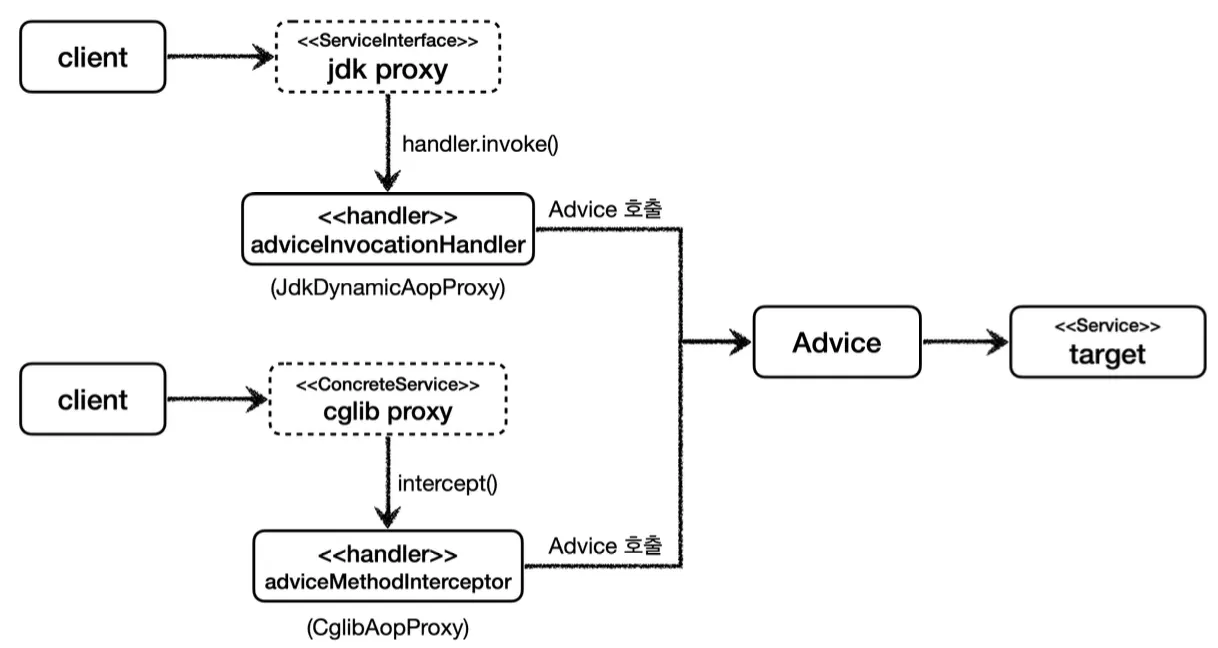
또한 이와 같이 Advice라는 개념을 도입해 기능 로직을 위임하여, 프록시 생성과 기능을 담당하는 로직을 분리했다. 이를 통해 개발자가 InvocationHandler나 MethodInterceptor를 신경쓰지 않고 로직을 Advice에 작성하기만 하면 된다.
간단한 예제를 통해 프록시 팩토리를 사용해보자.
package org.aopalliance.intercept;
public interface MethodInterceptor extends Interceptor {
Object invoke(MethodInvoation invoation) throws Throwable;
}
Java
복사
먼저 핵심 로직을 담당하는 Advice를 처리할 수 있는 MethodInterceptor 인터페이스이다. 여기서 중요한 것은 org.aopalliance.intercept 패키지를 사용한다는 것이다.
기존의 다음 메서드 호출하는 방법과 프록시 객체 인스턴스, 인자(args), 메서드 정보 등이 MethodInvocation 객체 내부로 추상화 되었다.
@Slf4j
public class TimeAdvice implements MehtodInterceptor {
public TimeAdvice() {
}
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
...
Object result = invocation.proceed();
...
return result;
}
}
Java
복사
구체적인 로직 작성 후 이와 같이 invocation.preoceed 메서드를 통해 실제 객체를 호출하면 된다.
@Test
void interfaceProxy() {
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvice(new TimeAdvice());
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.save();
assertThat(AopUtils.isAopProxy(proxy)).isTrue();
assertThat(AopUtils.isJdkDynamicProxy(proxy)).isTrue();
assertThat(AopUtils.isCglibProxy(proxy)).isFalse();
}
Java
복사
프록시 팩토리를 사용하는 방법은 이와 같이 프록시 팩토리를 생성할 때 프록시의 호출 대상을 함께 넘겨주고, 실행할 로직이 담긴 Advice를 addAdvice를 통해 넘겨주면 된다. 프록시 팩토리는 인터페이스와 구체 클래스 여부에 따라 JDK 동적 프록시나 CGLIB를 사용해 동적으로 프록시를 생성해 반환한다.
또한 프록시 팩토리를 적용하면, 위의 테스트 코드와 같이 AopUtils 내부의 프록시인지 확인하는 로직을 사용할 수 있게 된다.
@Test
void concreteProxy() {
ConcreteService target = new ConcreteService();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvice(new TimeAdvice());
ConcreteService proxy = (ConcreteService) proxyFactory.getProxy();
proxy.call();
assertThat(AopUtils.isAopProxy(proxy)).isTrue();
assertThat(AopUtils.isJdkDynamicProxy(proxy)).isFalse();
assertThat(AopUtils.isCglibProxy(proxy)).isTrue();
}
Java
복사
이처럼 동일한 로직을 구체 클래스에 사용하면, 프록시 팩토리에서 CGLIB를 선택하여 사용하게 된다.
추가적으로 인터페이스가 있지만 CGLIB를 통해 프록시를 생성하고 싶은 경우, proxyFactor.setProxyTargetClass(true)를 통해 지정할 수 있다. 하지만 스프링 부트를 사용하는 경우 항상 이 옵션을 true를 기본 설정으로 사용하게 된다.
포인트컷, 어드바이스, 어드바이저
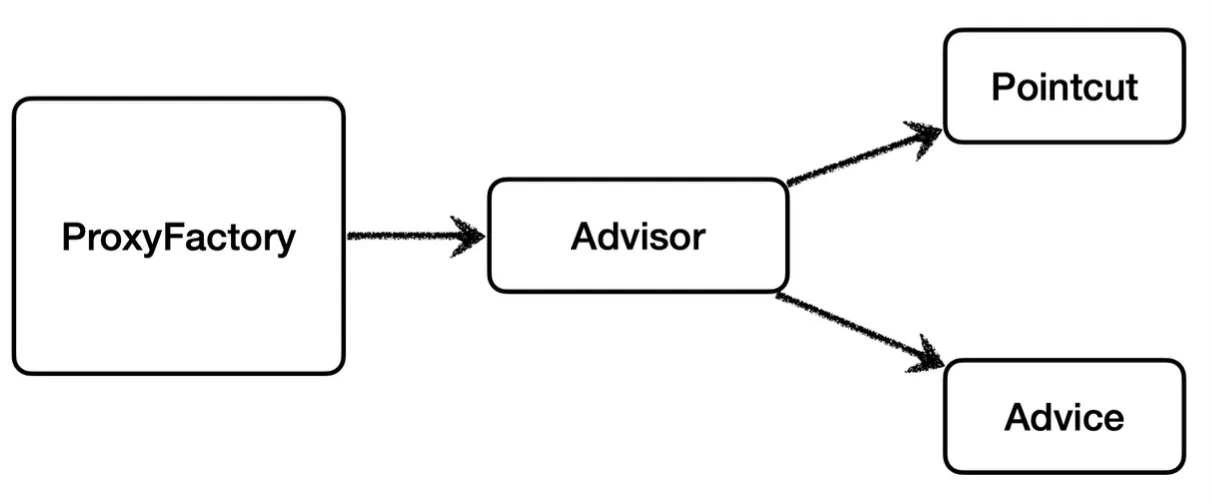
AOP에서 사용되는 포인트컷, 어드바이스, 어드바이저에 대한 용어를 정리하자.
•
포인트컷(Pointcut) : 어디에 부가 기능을 적용할 지 혹은 어디에 부가 기능을 적용하지 않을 지를 판단하는 필터링 로직이다. 어떤 포인트(Point)에 기능을 적용할지 하지 않을지를 잘라서(cut) 구분한다고 생각할 수 있다.
•
어드바이스(Advice) : 해당 프록시가 담당하는 부가 기능의 로직이다.
•
어드바이저(Advisor) : 하나의 포인트컷과 하나의 어드바이스를 어드바이저라 말한다.
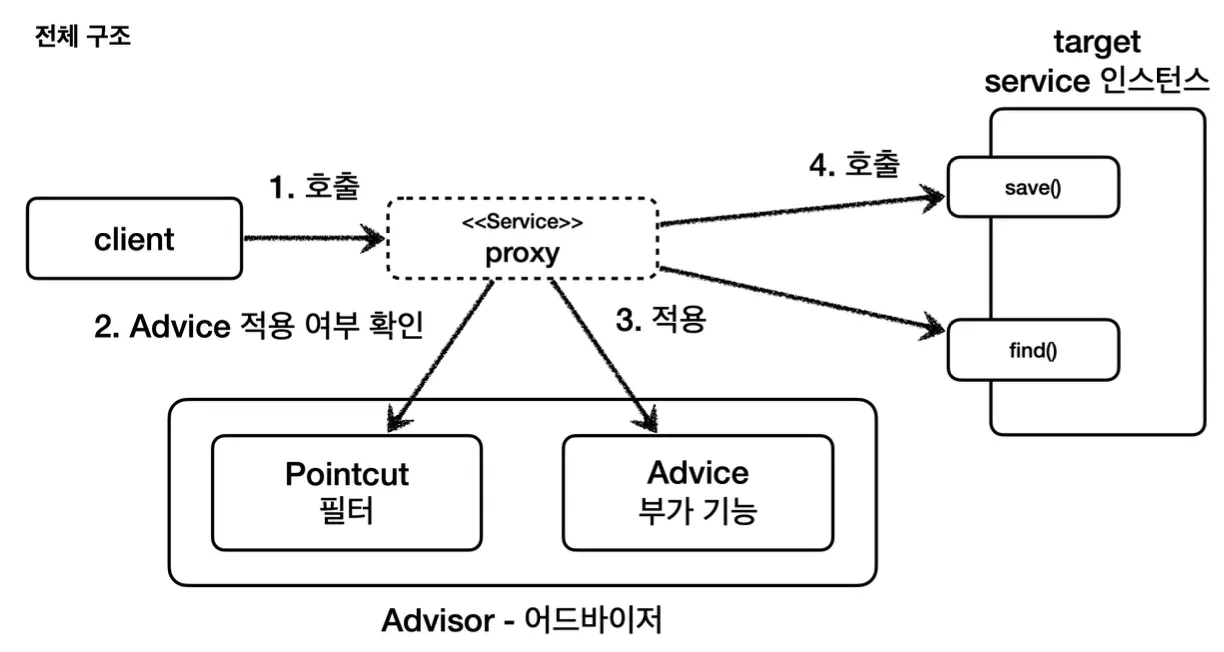
이와 같이 구분하는 이유는 역할과 책임을 명확하게 분리하여, 포인트컷은 필터 역할을 담당하고 어드바이스는 부가 기능 로직만 담당하도록 만든 것이다. 스프링에서는 이 둘을 합쳐 어드바이저(하나의 포인트컷 + 하나의 어드바이스)라고 부른다.
@Test
void interfaceProxy() {
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.addAdvice(new TimeAdvice());
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.save();
}
Java
복사
우리가 위에서 사용했던 addAdvice는
DefaultPointcutAdvisor advisor =
new DefaultPointcutAdvisor(Pointcut.TRUE, new TimeAdvice());
proxyFactory.addAdvisor(advisor);
Java
복사
내부적으로 이와 같이 구현되어 있어, 모든 메서드(포인트컷)에 적용하도록 되어있다.
포인트컷을 직접 만들어 사용하고 싶다면,
@Test
void advisorTest2() {
ServiceImpl target = new ServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(new MyPointcut(), new TimeAdvice());
proxyFactory.addAdvisor(advisor);
ServiceInterface proxy = (ServiceInterface) proxyFactory.getProxy();
proxy.save();
proxy.find();
}
static class MyPointcut implements Pointcut {
@Override
public ClassFilter getClassFilter() {
return ClassFilter.TRUE;
}
@Override
public MethodMatcher getMethodMatcher() {
return new MyMethodMatcher();
}
}
static class MyMethodMatcher implements MethodMatcher {
@Override
public boolean matches(Method method, Class<?> targetClass) {
boolean result = method.getName().equals("save");
return result;
}
@Override
public boolean isRuntime() {
return false;
}
@Override
public boolean matches(Method method, Class<?> targetClass, Object... args) {
throw new UnsupportedOperationException();
}
}
Java
복사
이와 같이 직접 Pointcut과 ClassMatcher, MethodMatcher를 구현하여 작성하여야한다. 위에서는 ClassMatcher는 작성하지 않고 모든 클래스에 적용하도록 true를 반환하였다.
isRuntime 메서드의 결과가 참이면 기존의 matches 메서드가 아니라, Object... args 가변 인수를 포함하여 동적으로 넘어는 매개변수를 판단 로직으로 사용할 수 있는 matches 메서드가 호출된다. 해당 메서드는 매개변수가 동적으로 변한다고 판단하기 때문에 캐싱을 하지 않는다. 이러한 이유로 isRuntime의 결과가 거짓이면 스프링이 내부에서 캐싱을 통해 성능 향상할 수 있지만, 참인 경우에는 캐싱하지 않아 성능을 향상 시킬 수 없다.
MethodMatcher에서는 matches 메서드를 통해 어드바이스를 적용할지 여부를 결정한다.
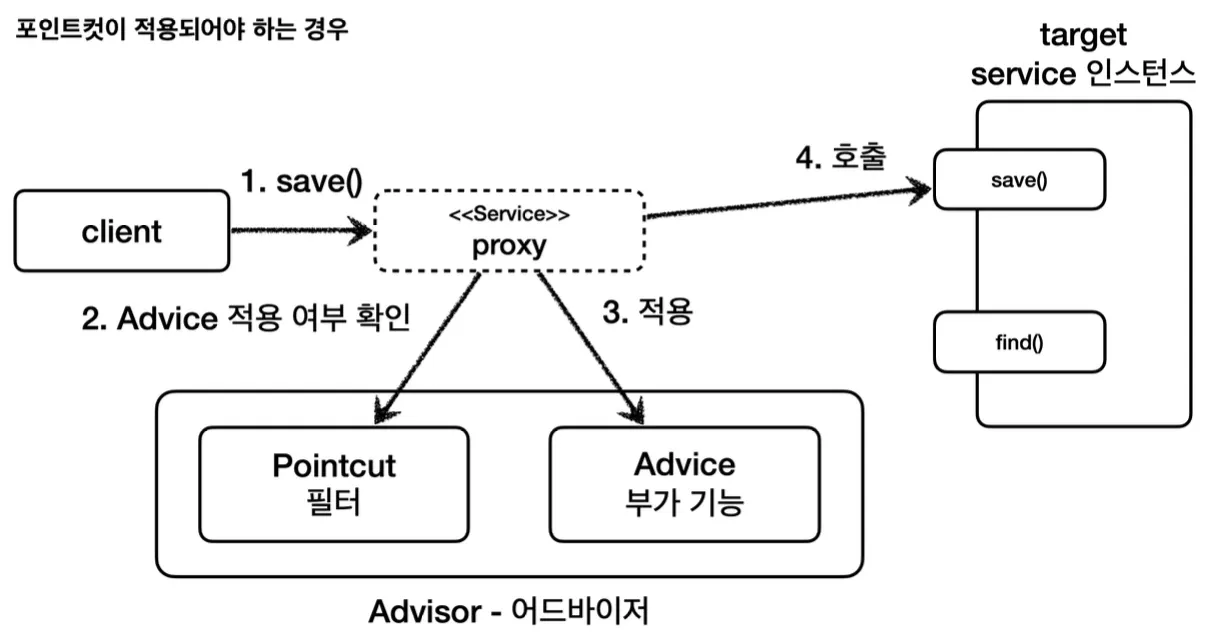
포인트컷이 적용되는 경우에는 이처럼 Advice 로직을 실행 후 target을 호출하고,
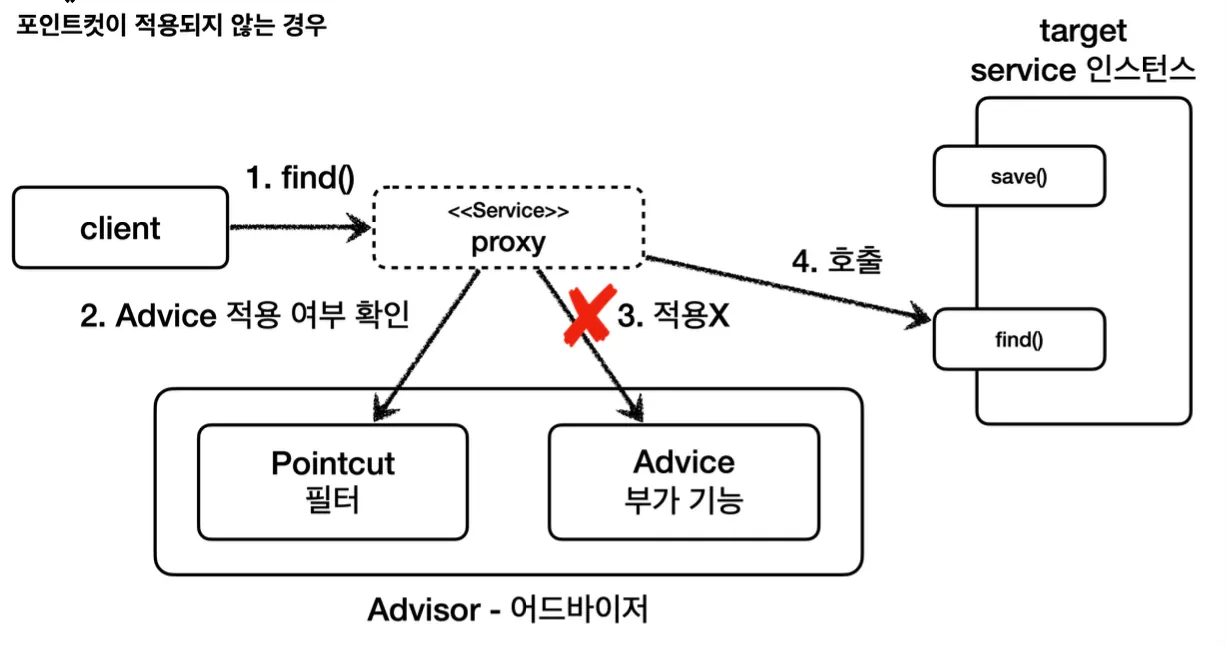
적용되지 않는 경우에는 이와 같이 Advice 로직을 실행하지 않고 바로 target을 호출한다.
하지만 위 코드를 보면 알 수 있듯, 작성해야하는 코드가 많고 읽기에 어렵다는 문제가 있다. 때문에 스프링에서는 여러 포인트컷을 미리 만들어두고 편리하게 사용할 수 있도록 제공한다.
NameMatchMethodPointcut poincut = new NameMatchMethodPointcut();
pointcut.setMappedNames("save");
DefaultPointcutAdvisor advisor = new DefaultPointcutAdvisor(pointcut, new TimeAdvice());
Java
복사
이를 사용하면 이와 같이 간단하고 깔끔하게 포인트컷을 지정할 수 있다.
•
NameMatchPointcut : 메서드 이름을 기반으로 매칭. 내부에서는 PatternMatchUtils를 사용한다.
•
JdkRegexMethodPointcut : JDK 정규 표현식을 기반으로 포인트컷 매칭
•
TruePointcut : 항상 참을 반환
•
AnnotationMatchingPoincut : 애노테이션으로 매칭
•
AspectJExpressionPointcut : asspectJ 표현식으로 매칭
이처럼 스프링에서 제공하는 포인트컷 기능이 많지만, 실무에서는 가장 사용하기 편리하고 기능이 많은 AspectJExpressionPointcut을 주로 사용한다.
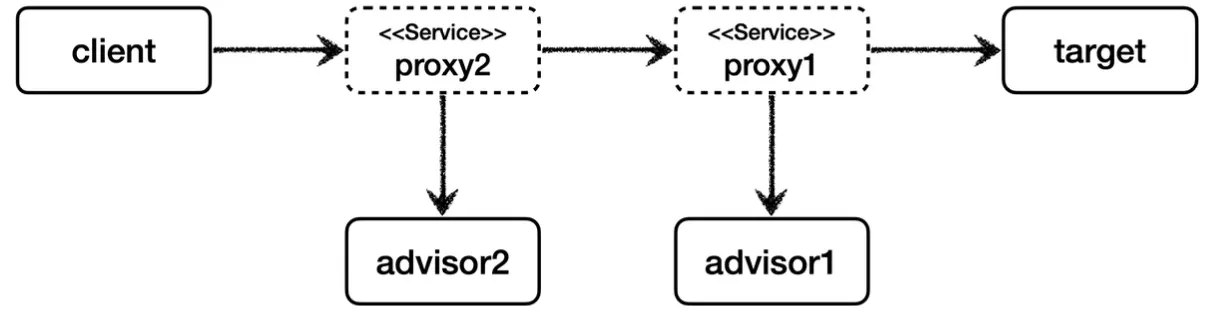
만약 여러 프록시를 적용하고 싶다면,
DefaultPointcutAdvisor advisor2 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice2());
DefaultPointcutAdvisor advisor1 = new DefaultPointcutAdvisor(Pointcut.TRUE, new Advice1());
ServiceInterface target = new ServiceImpl();
ProxyFactory proxyFactory1 = new ProxyFactory(target);
proxyFactory1.addAdvisor(advisor2);
proxyFactory1.addAdvisor(advisor1);
ServiceInterface proxy = (ServiceInterface) proxyFactory1.getProxy();
//실행
proxy.save();
Java
복사
이와 같이 하나의 프록시 팩토리에 addAdvisor를 통해 원하는만큼 등록할 수 있다. 등록하는 순서대로 호출되기 때문에, 위에서는 advisor2 → advisor1 순으로 등록했다.
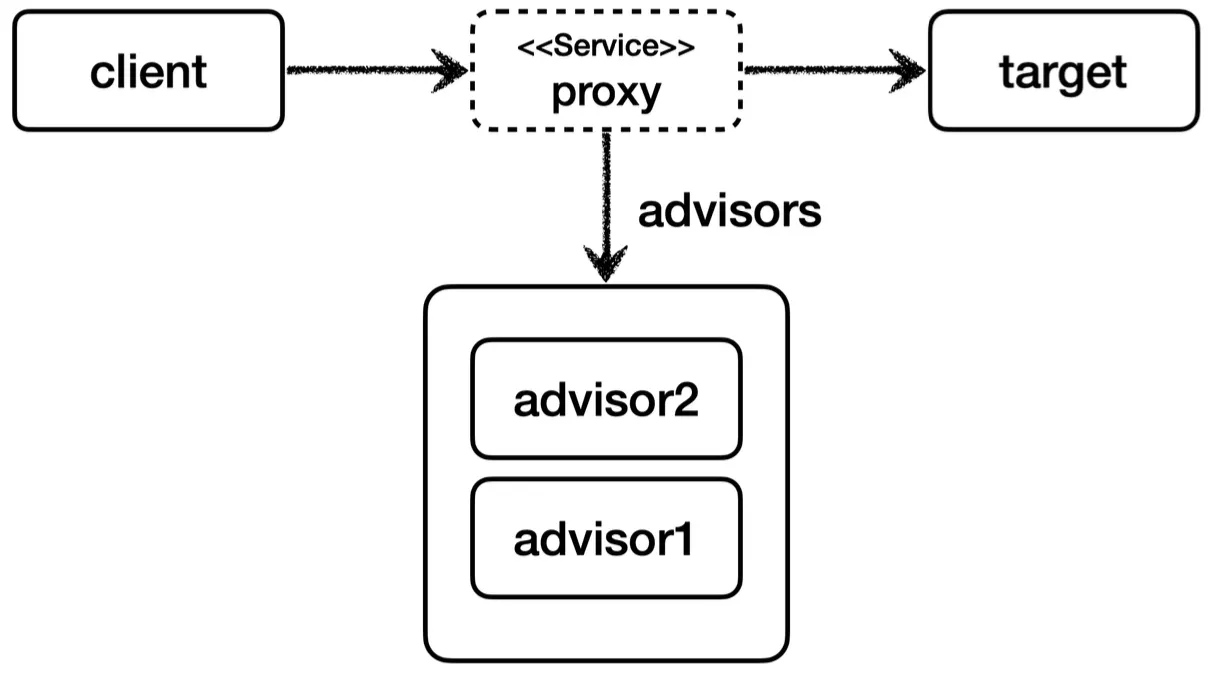
일반적으로 AOP를 적용하면 적용하는 개수만큼 프록시가 생성된다고 착각하기 쉬운데, 프록시는 target마다 하나만 생성하고 하나의 프록시에 여러 어드바이저를 적용하는 것이다.
프록시 팩토리 적용하기
기존의 로그 추적기에 프록시 팩토리 기능을 적용해보자.
@Slf4j
public class LogTraceAdvice implements MethodInterceptor {
private final LogTrace logTrace;
public LogTraceAdvice(LogTrace logTrace) {
this.logTrace = logTrace;
}
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
TraceStatus status = null;
try {
Method method = invocation.getMethod();
String message = method.getDeclaringClass().getSimpleName()
+ "." + method.getName() + "()";
status = logTrace.begin(message);
// 로직 호출
Object result = invacation.proceed();
logTrace.end(status);
return result;
} catch (Exception e) {
logTrace.exceptino(status, e);
throw e;
}
}
}
Java
복사
이와 같이 부가 기능을 Advice에 작성하고,
@Slf4j
@Configuration
public class ProxyFactoryConfigV2 {
@Bean
public OrderControllerV2 orderControllerV2(LogTrace logTrace) {
OrderControllerV2 orderController = new OrderControllerV2(orderServiceV2(logTrace));
ProxyFactory factory = new ProxyFactory(orderController);
factory.addAdvisor(getAdvisor(logTrace));
OrderControllerV2 proxy = (OrderControllerV2) factory.getProxy();
return proxy;
}
@Bean
public OrderServiceV2 orderServiceV2(LogTrace logTrace) {
OrderServiceV2 orderService = new OrderServiceV2(orderRepositoryV2(logTrace));
ProxyFactory factory = new ProxyFactory(orderService);
factory.addAdvisor(getAdvisor(logTrace));
OrderServiceV2 proxy = (OrderServiceV2) factory.getProxy();
return proxy;
}
@Bean
public OrderRepositoryV2 orderRepositoryV2(LogTrace logTrace) {
OrderRepositoryV2 orderRepository = new OrderRepositoryV2();
ProxyFactory factory = new ProxyFactory(orderRepository);
factory.addAdvisor(getAdvisor(logTrace));
OrderRepositoryV2 proxy = (OrderRepositoryV2) factory.getProxy();
return proxy;
}
private Advisor getAdvisor(LogTrace logTrace) {
//pointcut
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
//advice
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
}
Java
복사
이와 같이 인터페이스든 구체 클래스든 상관하지 않고 프록시 팩토리에 어드바이스로 등록하여 부가 기능을 추가할 수 있다.
BeanPostProcessor
빈 후처리기
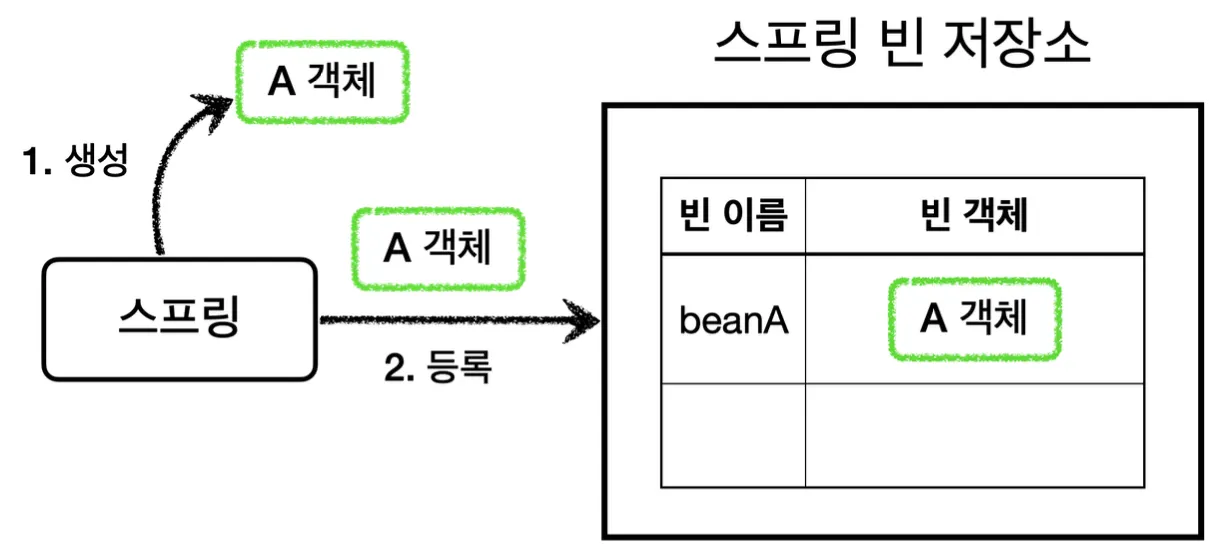
일반적으로 @Bean이나 컴포넌트 스캔으로 스프링 빈으로 등록하게되면, 스프링에서는 대상 객체를 생성하고 스프링 컨테이너 내부의 빈 저장소에 등록한다. 이후에는 스프링 컨테이너를 통해서, 등록된 스프링 빈을 조회하여 사용한다.
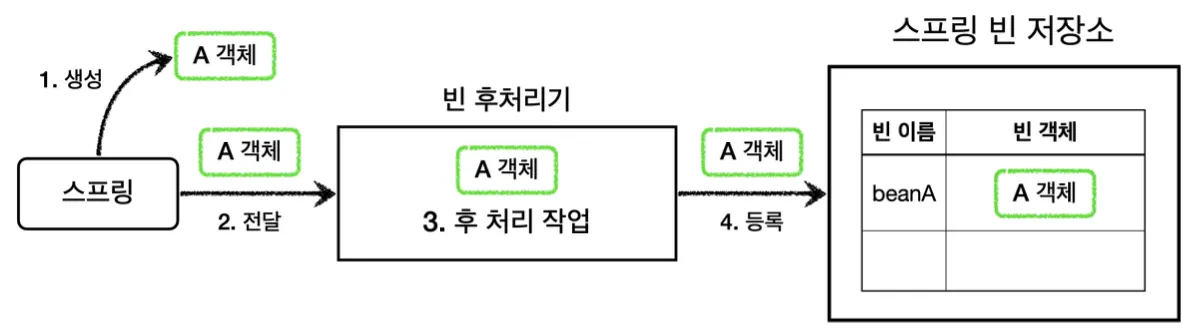
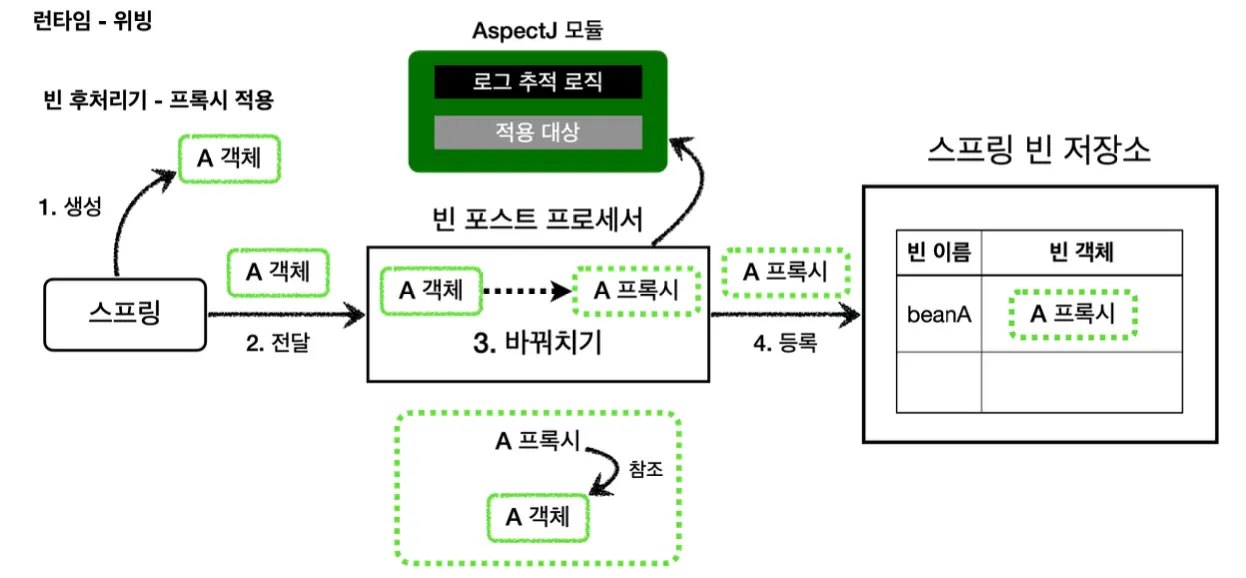
빈 후처리기는 위와 같이 스프링이 빈 저장소에 등록하기 위해 객체를 생성한 이후 스프링 컨테이너의 빈 저장소에 등록하기 전에, 등록될 스프링 빈 객체를 조작하는 용도로 사용된다.
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
Java
복사
빈 후처리기를 사용하기 위해서는 위의 BeanPostProcessor 인터페이스를 구현하여 스프링 빈으로 등록하면 된다.
•
postProcessBeforeInitialization : 객체 생성 이후 @PostConstruct와 같은 초기화가 발생하기 직전에 호출되는 프로세서
•
postProcessAfterInitialization : 객체 생성 이후 @PostConstruct와 같은 초기화가 발생한 다음에 호출되는 프로세서
@PostConstruct은 스프링 빈 이후에 빈을 초기화 하는 역할을 수행하는데, 이 역시 생성된 빈을 조작하는 행위이다.
스프링에서는 CommonAnnotationBeanPostProcessor라는 빈 후처리기를 자동으로 등록하는데, 여기에서 @PostConstruct 애노테이션이 붙은 메서드를 호출하여 처리한다.
빈 후처리기를 사용하면 빈 객체를 조작하는 것을 넘어 다른 객체로 바꿔치기하는 것도 가능하다. 간단한 예제로 빈 후처리기의 동작을 테스트 해보자.
public class BasicTest {
@Test
void basicConfig() {
ApplicationContext applicationContext =
new AnnoationConfigApplicationContext(BasicConfig.class);
// A는 빈으로 등록
A a = applicationContext.getBean("beanA", A.class);
a.helloA();
// B는 빈으로 등록 X
assertThrows(NoSuchBeanDefinitionException.class,
() -> applicationContext.getBean(B.class));
}
@Configuration
static class BasicConfig {
@Bean
public A a() {
return new A();
}
}
@Slf4j
static class A {
public void helloA() {
log.info("hello A");
}
}
@Slf4j
static class B {
public void helloB() {
log.info("hello B");
}
}
}
Java
복사
일반적인 빈 등록의 경우 이와 같이 빈에 등록된 A만 조회할 수 있고 B는 조회할 수 없다.
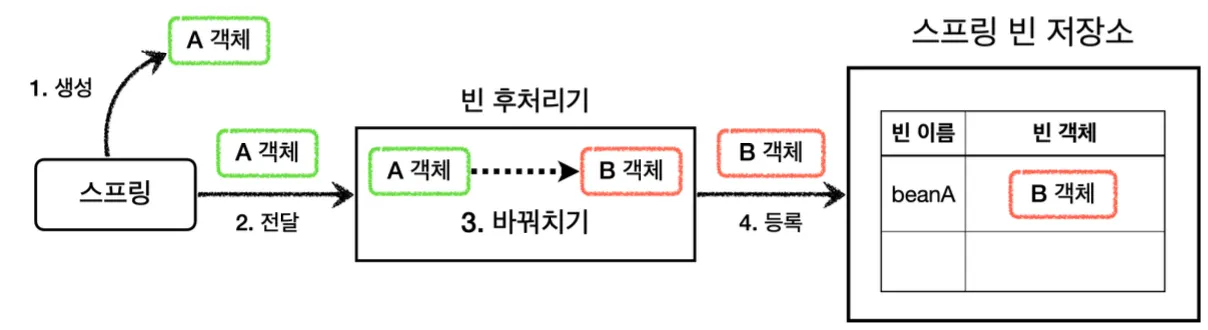
public class BasicTest {
@Test
void postProcessor() {
ApplicationContext applicationContext =
new AnnoationConfigApplicationContext(BasicConfig.class);
//beanA 이름으로 B 객체가 빈으로 등록된다.
B b = applicationContext.getBean("beanA", B.class);
b.helloB();
// A는 빈으로 등록 X
assertThrows(NoSuchBeanDefinitionException.class,
() -> applicationContext.getBean(A.class));
}
@Configuration
static class BeanPostProcessorConfig {
@Bean
public A a() {
return new A();
}
@Bean
public AToBPostProcessor helloPostProcessor() {
return new AToBPostProcessor();
}
}
...
@Slf4j
static class AToBPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException {
if (bean instanceof A) {
return new B();
}
return bean;
}
}
}
Java
복사
이와 같이 빈 후처리기를 통해 빈 등록 전에 A 객체를 B 객체로 바꿔치기 하면, A 객체는 등록되지 않고 B 객체가 빈으로 등록된다.
빈 후처리기 적용하기
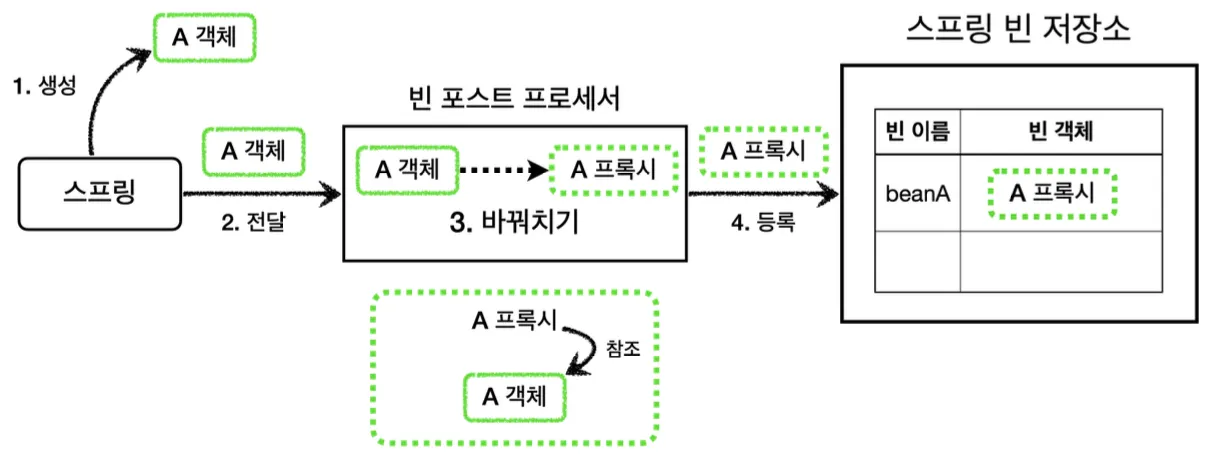
위와 같이 빈 후처리기를 등록하여 프록시를 스프링 빈으로 등록하는 과정을 해보자.
public class PackageLogTraceProxyPostProcessor implements BeanPostProcessor {
private final String basePackage;
private final Advisor advisor;
public PackageLogTraceProxyPostProcessor(String basePackage, Advisor advisor) {
this.basePackage = basePackage;
this.advisor = advisor;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeanException {
//프록시 적용 대상 확인
String packageName = bean.getClass().getPackageName();
// 적용대상이 아니면 원본 그대로 반환
if (!packageName.startsWith(basePackage)) {
return bean;
}
// 프록시 대상이면 프록시 생성하여 반환
ProxyFactory proxyFactory = new ProxyFactory(bean);
proxyFactory.addAdvisor(advisor);
Object proxy = proxyFactory.getProxy();
return proxy;
}
}
Java
복사
이와 같이 빈 후처리기를 통해 특정 패키지에 있는 빈 객체들만 프록시 객체로 바꾸어 스프링 컨테이너에 등록한다.
@Import({AppV1Config,class, AppV2Config.class})
public class BeanPostProcessorConfig {
@Bean
public PackageLogTraceProxyPostProcessor logTraceProxyProcessor(LogTrace logTrace) {
return new PackageLogTraceProxyPostProcessor("hello.proxy.app", getAdvisor(logTrace));
}
private Advisor getAdvisor(LogTrace logTrace) {
//pointcut
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
//advice
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
//advisor = pointcut + advice
return new DefaultPointcutAdvisor(pointcut, advice);
}
}
Java
복사
그 후 위처럼 빈 후처리기를 스프링 빈으로 등록하면, 이후의 과정은 스프링 내부에서 자동으로 처리된다. 이를 통해서 위에서 작성해왔던 프록시 객체를 생성해 주입하는 과정을 별도로 작성하지 않아도 된다. 추가적으로 컴포넌트 스캔으로 자동으로 등록되는 객체들에 대해서도 적용할 수 있다.
스프링의 빈 후처리기
위 과정을 통해 많은 문제들이 해결됐지만, 패키지 기준으로 설정하는 방법은 일괄적으로 적용하기 어렵다. 이는 어드바이저에서 필터 역할을 하는 포인트컷을 사용하면 깔끔하게 해결할 수 있다. 스프링에서는 이러한 빈 후처리기 이미 만들어서 제공한다.
스프링이 제공하는 빈 후처리기를 사용하기 위해서는 다음 라이브러리를 추가해야 한다.
implementation 'org.springframework.boot:spring-boot-starter-aop'
Java
복사
위 라이브러리를 추가하면 aspectjweaver라는 aspectJ 관련 라이브러리가 등록되고, 스프링 부트가 AOP 관련 클래스를 자동으로 스프링 빈에 등록한다. 이렇게 등록되는 빈 중에는 AnnoationAwareAspectJAutoProxyCreator라는 빈 후처리기가 있다.
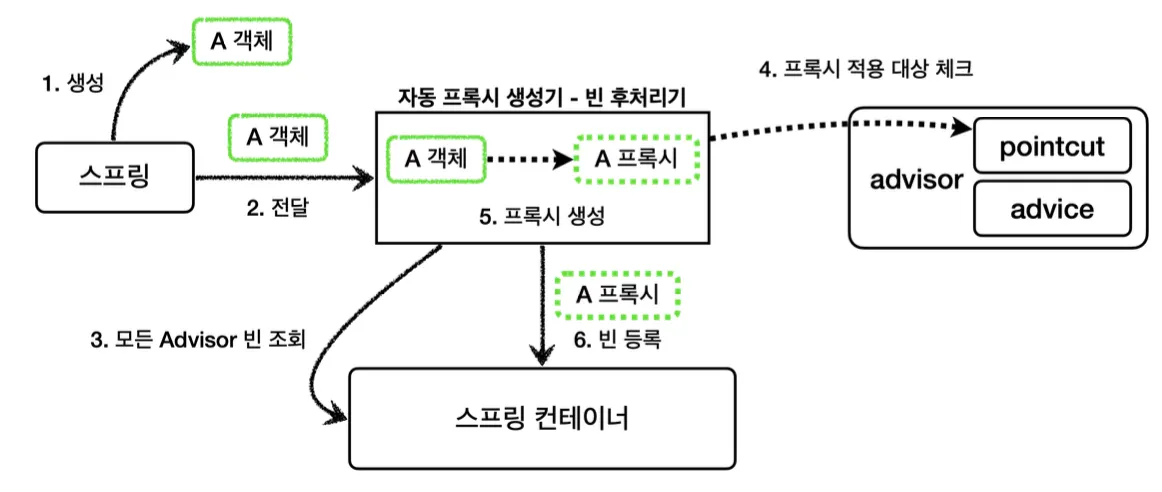
이 빈은 스프링 빈으로 등록된 어드바이저를 자동으로 모두 찾아서, 어드바이저의 포인트컷을 보고 프록시가 필요한 곳에서 자동으로 프록시를 적용해준다.
이처럼 포인트컷은 2가지 목적으로 사용된다.
1.
생성 단계 - 프록시 적용 여부
자동 프록시 생성기는 포인트컷을 확인하여 해당 빈이 프록시를 생성할 필요가 있는지 여부를 확인한다. 클래스 + 메서드 조건을 모두 비교하여, 조건이 하나라도 맞다면 프록시를 생성하고 맞는게 없다면 생성하지 않는다.
2.
사용 단계 - 요청 시 어드바이스 적용 여부 판단
프록시가 호출 되었을 때 어드바이스를 적용할지 할지를 포인트컷을 보고 판단한다.
@Configuration
@Import({AppV1Config.class, AppV2Config.class})
public class AutoProxyConfig {
@Bean
public Advisor advisor1(LogTrace logTrace) {
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
}
Java
복사
사용하는 방법은 이와 같이 어드바이저를 등록하기만 하면 된다. 이후의 과정은 AnnotationAwareAspectJAutoProxyCreator라는 빈에서 빈 후처리기를 자동으로 등록해준다. 실제 실행해보면 로그를 남기는 동작이 잘 수행되는 것을 확인 할 수 있다.
EnableWebMvcConfiguration.requestMappingHandlerAdapter() time=63ms
Plain Text
복사
하지만 애플리케이션을 실행해보면, 위와 같이 기대하지 않은 로그들을 볼 수 있다. 그 이유는 어드바이저에 추가한 포인트컷이 "request*", "order*", "save*"로 되어있기 때문이다. 메서드 이름에 해당 패턴이 일치하는 부분이 있다면 모두 적용되는 것이다.
이러한 문제 때문에 실무에서는 세세한 조건까지 지정할 수 있는 AspectJ 포인트컷 표현식을 주로 사용한다.
@Bean
public Advisor advisor2(LogTrace logTrace) {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("execution(* hello.proxy.app..*(..))");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
Java
복사
이처럼 execution(* hello.proxy.app..*(..))와 같은 AspectJ 포인컷 표현식을 사용할 수 있는 AspectJExpressionPointcut 어드바이저를 사용하여 적용할 수 있다.
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("execution(* hello.proxy.app..*(..)) && "
+ "!execution(* hello.proxy.app..noLog(..))");
Java
복사
여기서 특정 메서드에 로그를 남기고 싶지 않다면 위와 같이 추가 조건을 지정할 수도 있다.
하나의 빈에 여러 어드바이저를 등록하는 것도 가능하다.
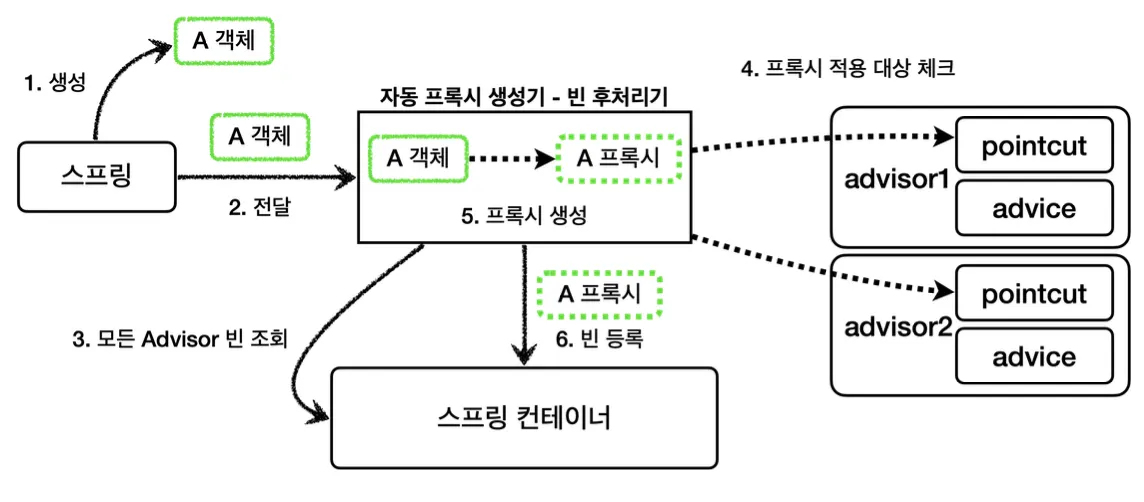
이 역시 단순하게 어드바이저를 빈으로 등록하기만 하면, 자동 프록시 생성기에서 해당 어드바이저를 통해 적용이 필요한 곳에 프록시를 생성하여 준다.
Aspect AOP
위 과정에서 프록시를 적용하기 위해서는 포인트컷과 어드바이스로 구성된 어드바이저를 만들어 스프링 빈으로 등록해야 한다. 그 뒤는 스프링에서 자동 프록시 생성기가 모두 처리해준다.
스프링에서는 이러한 포인트컷과 어드바이스로 구성되어 있는 어드바이스를 @Aspect 애노테이션을 통해 매우 편리하게 생성할 수 있도록 지원한다.
@Aspect 프록시
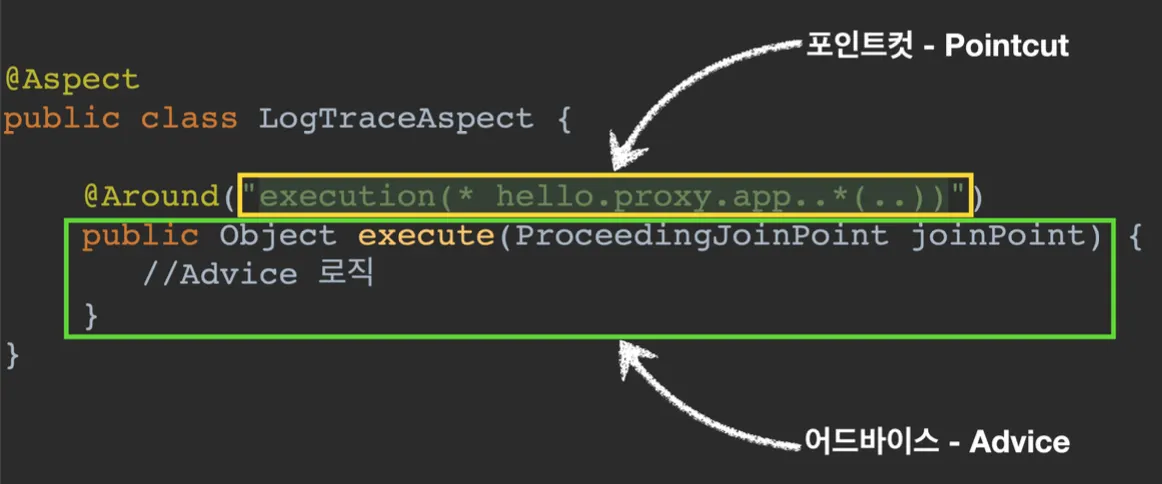
@Slf4j
@Aspect
public class LogTraceAspect {
private final LogTrace logTrace;
public LogTraceAspect(LogTrace logTrace) {
this.logTrace = logTrace;
}
@Around("execution(* hello.proxy.app..*(..))")
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable {
TraceStatus status = null;
try {
String message = joinPoint.getSignature().toShortString();
status = logTrace.begin(message);
// 로직 호출
Object result = joinPoint.proceed();
logTrace.end(status);
return result;
} catch (Exception e) {
logTrace.exception(status, e);
throw e;
}
}
}
Java
복사
@Aspect 애노테이션을 통해 어드바이저를 생성하는 방법은, 위와 같이 @Aspect 애노테이션이 붙어있는 클래스에 @Around 애노테이션을 통해 포인트 컷을 지정하고 메서드에 어드바이스 로직을 작성하면 된다.
@Configuration
@Import({AppV1Config.class, AppV2Config.class})
public class AopConfig {
@Bean
public LogTraceAspect logTraceAspect(LogTrace logTrace) {
return new LogTraceAspect(logTrace);
}
}
Java
복사
그 후 해당 Aspect 클래스를 빈으로 등록하면 끝난다.
자동 프록시 생성기는 2가지 작업을 수행한다.
1.
@Aspect 빈을 어드바이저로 변환 후 저장
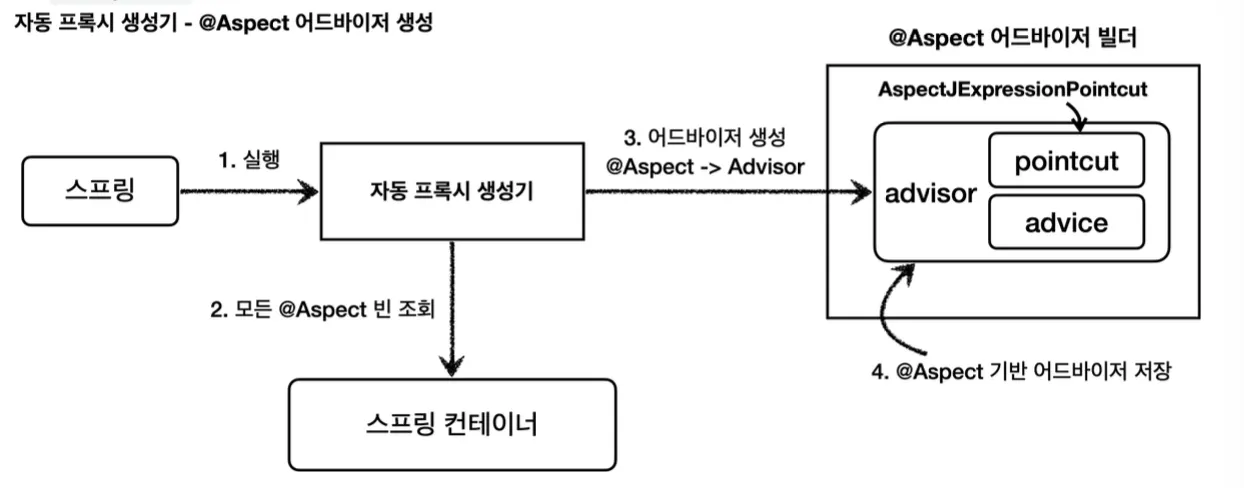
애플리케이션 로딩 시점에 자동 프록시 생성기를 호출하고, @Aspect 애노테이션이 붙은 모든 빈을 조회한다. 그 후 조회한 빈들을 순회하며 @Aspect 어드바이저 빌더를 통해 어드바이저를 생성 후 @Aspect 어드바이저 빌더 내부에 저장한다.
2.
어드바이저를 기반으로 프록시 생성
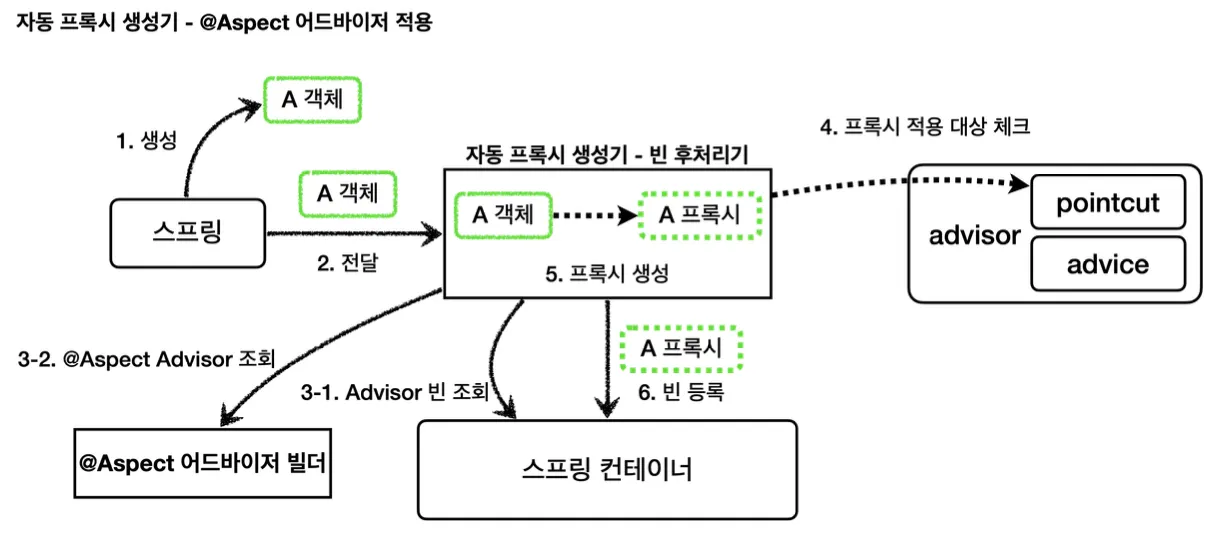
스프링 빈 대상이 되는 객체들의 빈 후처리기 과정에서, 자동 프록시 생성기는 빈으로 등록된 어드바이저들과 @Aspect 어드바이저 빌더 내부에 저장된 모든 어드바이저를 조회하여 프록시 적용 대상을 확인한다. 모든 객체의 클래스와 메서드 정보를 포인트컷에 일일이 비교하여 매칭해보고, 하나라도 매칭이 된다면 프록시 객체를 생성하여 스프링 빈으로 등록한다. 만약 매칭 되는 것이 없다면 원본 객체를 스프링 빈으로 등록한다.
스프링 AOP
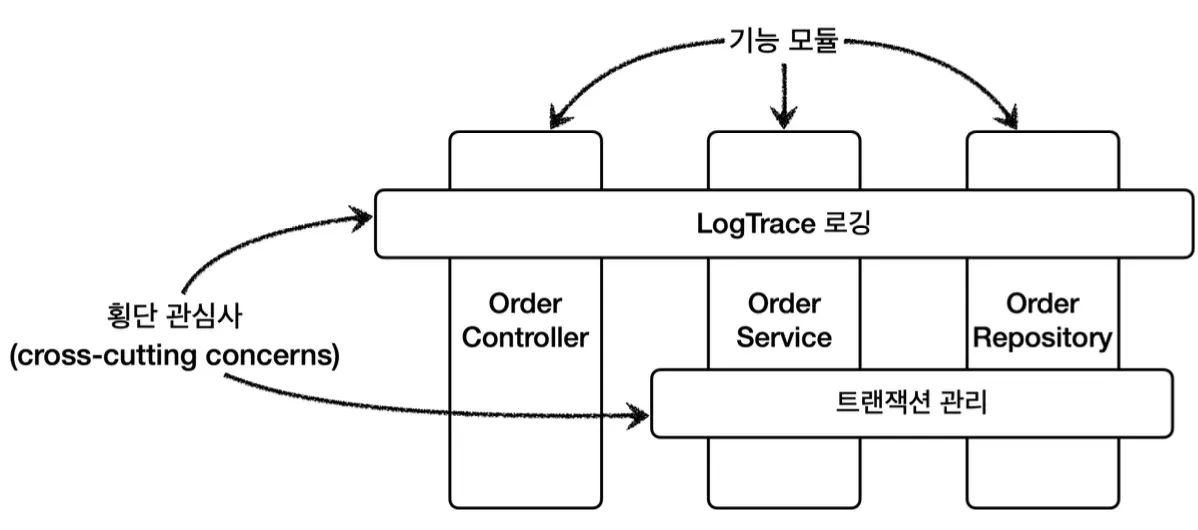
여기까지의 과정은 위 그림처럼 하나의 특정 기능이 아닌 애플리케이션 전반에 걸친 관심사를 처리하는 작업이었다.
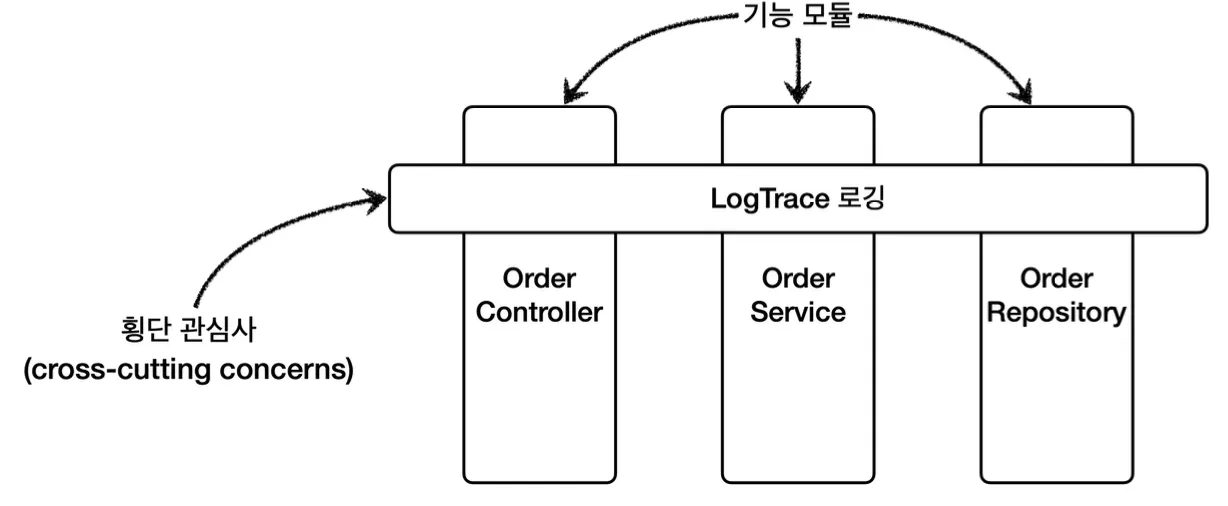
이것을 횡단 관심사(cross-cutting concerns)라고 부르는데, 스프링의 AOP의 @Aspect를 사용해 애노테이션 기반으로 프록시를 편리하게 적용할 수 있다.
스프링 AOP에 대해 제대로 공부해보자.
AOP 개념
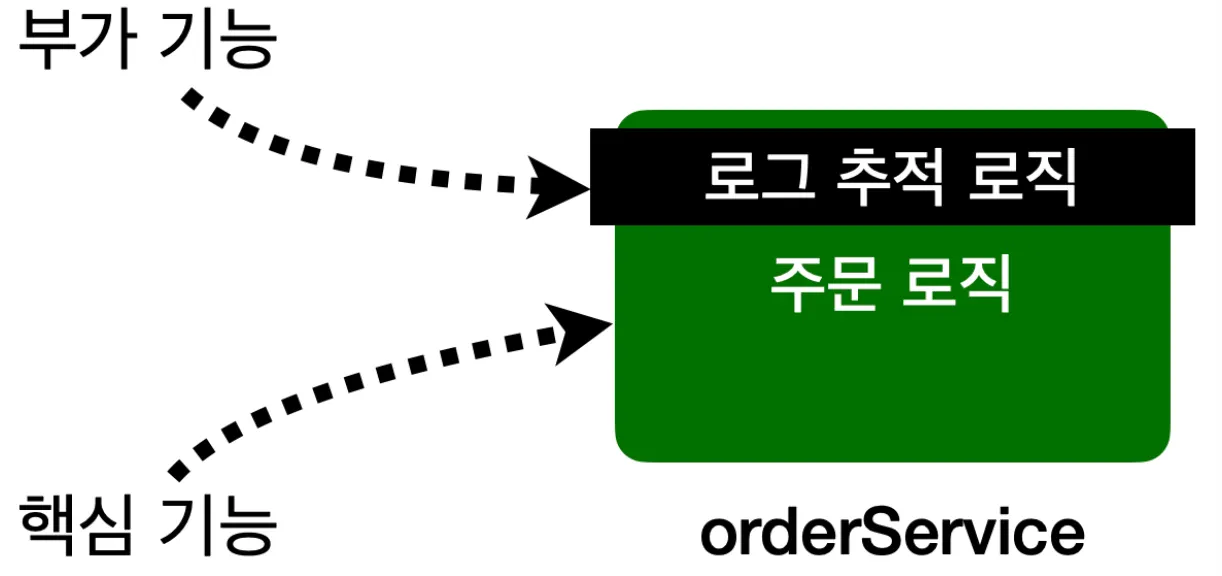
애플리케이션 로직은 위처럼 핵심 기능과 부가 기능으로 나뉜다. 부가 기능은 단독으로 사용되지는 않고, 핵심 기능과 함께 사용된다.

하지만 보통 부가 기능은 위처럼 여러 클래스에 걸쳐 사용된다.

이러한 부가 기능을 횡단 관심사(cross-cutting concerns)이라 한다.
횡단 관심사인 부가 기능을 직접 코드에 적용하려면 여러 곳에 직접 부가 기능 로직을 넣거나, 부가 기능을 수행하는 유틸 클래스를 만들어 모든 곳에서 해당 유틸 클래스를 호출하는 코드를 넣어야한다.
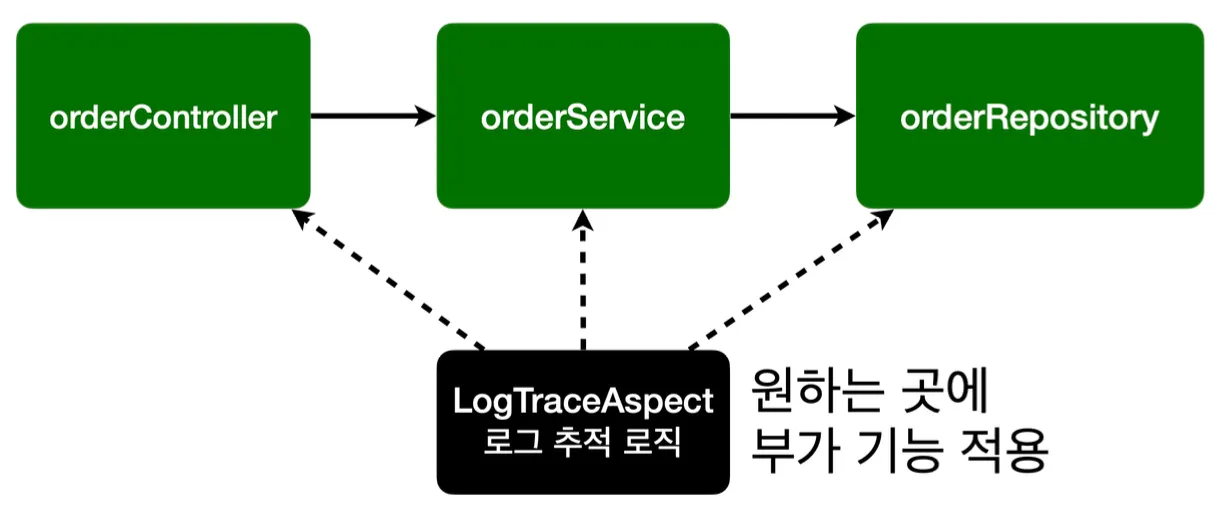
이러한 부가 기능을 도입하는 문제를 해결하기위해, 부가 기능을 분리하고 한 곳에서 관리하는 기능을 만들었다. 부가 기능 로직과 무가 기능을 어디에 적용할지 선택하는 기능을 합쳐, 하나의 모듈로 만들고 이를 애스펙트(Aspect)라 부른다.
위에서 직접 구현했던 스프링이 제공하는 어드바이저도 부가 기능(어드바이스)과 적용 대상(포인트컷)을 가지는 하나의 애스펙트 개념이다. 이와 같이 Aspect를 사용한 프로그래밍 방식을 AOP(Aspect-Oriented Programming, 관점 지향 프로그래밍)이라 한다. 참고로 AOP는 OOP를 대체하기 위함이 아니라, 횡단 관심사를 깔끔하게 처리하기 어려운 OOP의 부족한 부분을 보조하는 목적으로 개발되었다.
AOP의 대표적인 구현으로는 AspectJ 프레임워크가 있다. 스프링도 AOP를 지원하긴 하지만, 대부분 AspectJ 문법을 차용하고 AspectJ 기능의 일부분만 제공한다. AsepctJ는 자바 프로그래밍 언어에 대한 완벽한 관점 지향 확장과 횡단 관심사의 깔끔한 모듈화를 목적으로 제공된다.
AOP 적용 방식
AOP를 적용할 때 부가 기능 로직은 3가지 방법으로 적용될 수 있다.
•
컴파일 시점
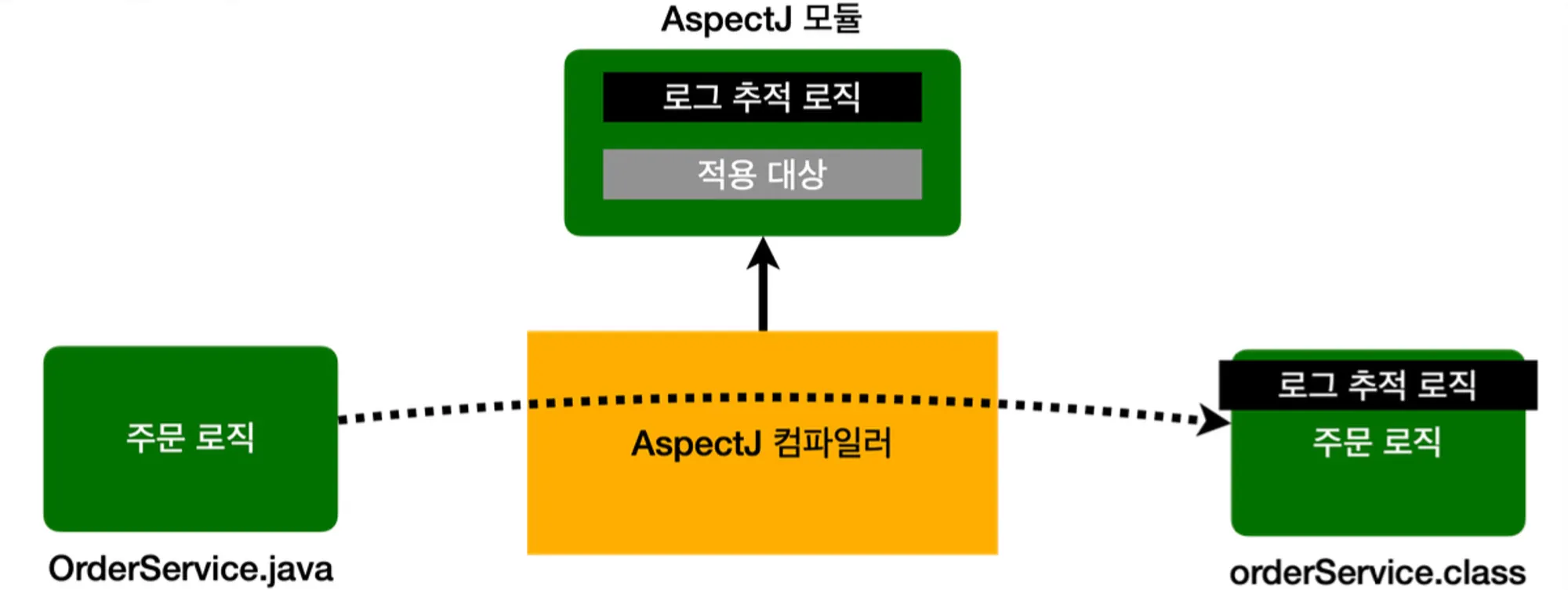
소스 코드를 컴파일을 통해 class 파일을 만드는 시점에 부가 기능 로직을 추가하는 방법이다. AspectJ가 제공하는 특별한 컴파일러를 사용해야 하며, 컴파일된 class 파일을 디컴파일 해보면 애스펙트 관련 호출 코드가 삽입되어 있는 것을 확인할 수 있다. 다시 말해, 소스 코드에 부가 기능 코드를 물리적으로 추가한다고 생각하면 된다.
이와 같이 컴파일 시에 원본 로직에 부가 기능 로직이 추가되는 것을 위빙(Weaving)이라 한다.
단점으로는 특별한 컴파일러를 통해 컴파일해야하며, 그 과정도 복잡하다.
•
클래스 로딩 시점
자바에서는 JVM 내부의 클래스 로더에 class 파일을 보관하는데, JVM에 저장하기 전에 class 파일을 조작할 수 있는 기능을 제공한다. 대부분 모니터링 툴이 이 방식을 사용하며, 이 시점에 애스펙트를 적용하는 것을 로드 타임 위빙이라 부른다.
단점으로는 로드 타임 위빙은 자바를 실행할 때 특별한 옵션(java - javaagent)을 통해 로더 조작기를 지정해야하는데, 이 과정이 번거롭고 운영하기 어렵다.
•
런타임 시점(프록시)
런타임 시점에 로딩을 하는 방법은 여태까지 작성해왔던 프록시 방식의 AOP를 말한다. 스프링과 같은 컨테이너의 도움이 필요하며, 프록시와 DI(의존성 주입), BeanPostProcessor 같은 기능들과 함께 사용되어야 한다.
프록시를 사용하기 때문에, 생성자에는 적용 불가능하고 final과 static이 아닌 메서드에만 적용 가능한 점 등 AOP 기능에 일부 제약이 있다. 하지만 특별한 컴파일러가 필요하지 않고, 자바를 실행할 때 복잡한 옵션을 넣고 클래스 로더 조작기를 설정하지 않아도 되며 스프링만 있다면 AOP를 적용할 수 있다.
AOP 용어 정리
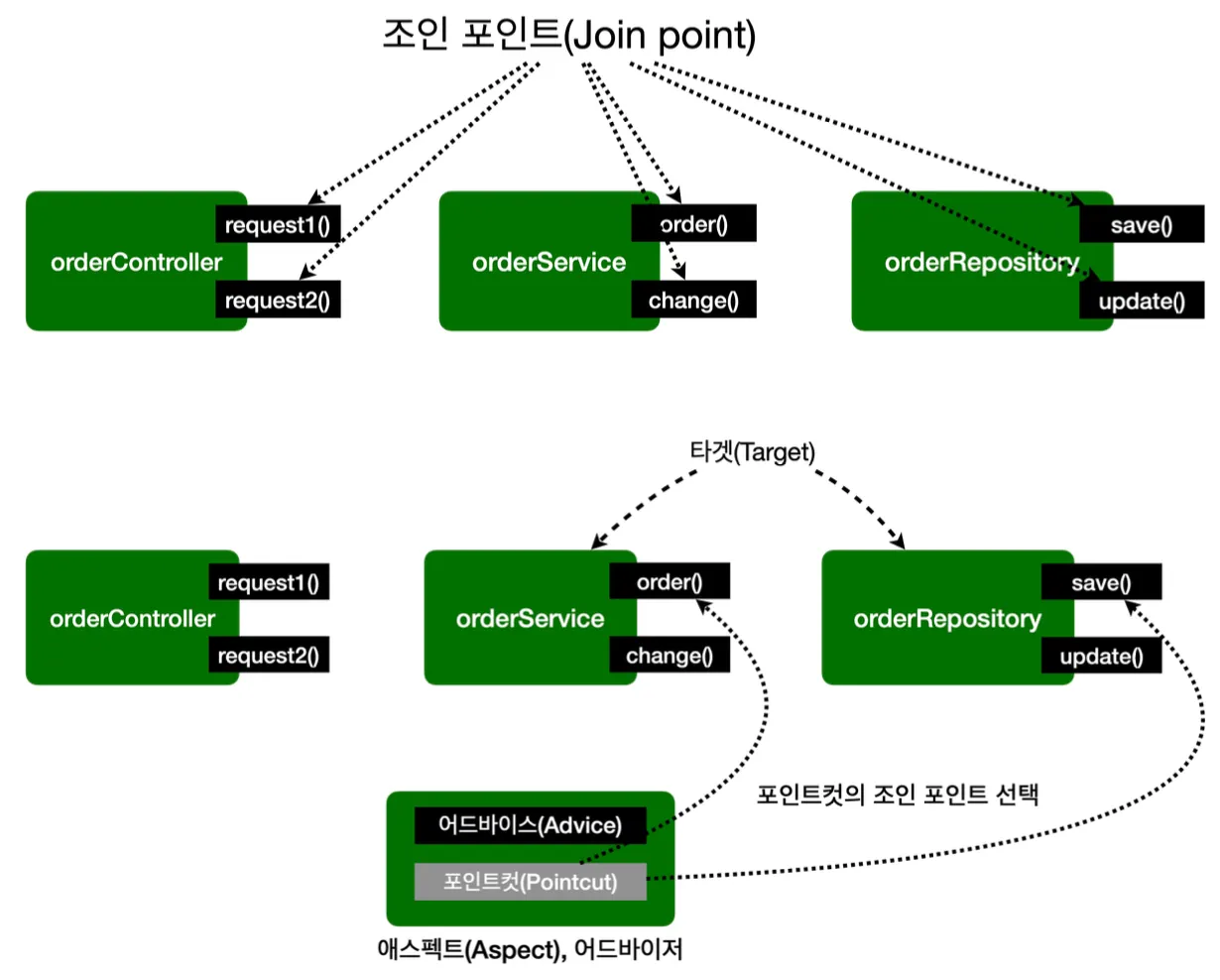
•
조인 포인트(Join Point)
어드바이스가 적용될 수 있는 위치를 말하며, 메서드 실행, 생성자 호출, 필드 값 접근, static 메서드 접근 등 여러 지점을 말한다. 조인 포인트는 추상적인 개념으로 AOP를 적용할 수 있는 모든 지점이라 생각하면 된다. 스프링 AOP는 프록시 방식을 사용하므로 조인 포인트는 항상 메서드 실행 시점으로 제한된다.
•
포인트컷(Pointcut)
조인 포인트 중에서 어드바이스가 적용될 위치를 필터링(선별)하는 기능으로, 주로 AspectJ 표현식을 사용해서 지정된다. 프록시를 사용하는 스프링 AOP는 메서드 실행 지점만 포인트컷으로 지정할 수 있다.
•
타겟(Target)
어드바이스를 받는 객체로, 포인트컷으로 결정된다.
•
어드바이스(Advice)
실제 부가 기능 로직을 말하며, 특정 조인 포인트에서 Aspect에 의해 취해지는 동작을 말한다. Around(주변), Before(전), After(후) 등 다양한 종류의 어드바이스가 있다.
•
애스펙트(Aspect)
어드바이스와 모인트 컷을 모듈화한 것으로, 여러 어드바이스와 포인트 컷이 함께 존재할 수 있다.
•
어드바이저(Advisor)
하나의 어드바이스와 하나의 포인트 컷으로 구성된 모듈을 말하며, 스프링 AOP에서만 사용되는 특별한 용어이다.
•
위빙(Weaving)
포인트컷으로 결정한 타겟의 조인 포인트에 어드바이스를 적용하는 것을 말한다. 위빙을 통해 핵심 기능 코드에 영향을 주지 않고 부가 기능을 추가할 수 있다. AOP 적용을 위해 애스펙트를 객체에 연결한 상태를 말하며, 적용 시점에 따라 컴파일 타임, 로드 타임, 런타임이 있다.
•
AOP 프록시
AOP 기능을 구현하기 위해 만든 프록시 객체로, 스프링에서 AOP 프록시는 JDK 동적 프록시 또는 CGLIB 프록시이다.
스프링 AOP 구현
@Slf4j
@Aspect
public class AspectV1 {
@Around("execution(* hello.aop.order..*(..))")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[log] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
}
Java
복사
AOP는 간단하게 위와 같이 포인트컷과 어드바이스 로직을 작성하여 구현할 수 있다.
표현식을 보면 aop 패키지의 order 하위 모든 클래스에 적용하므로,
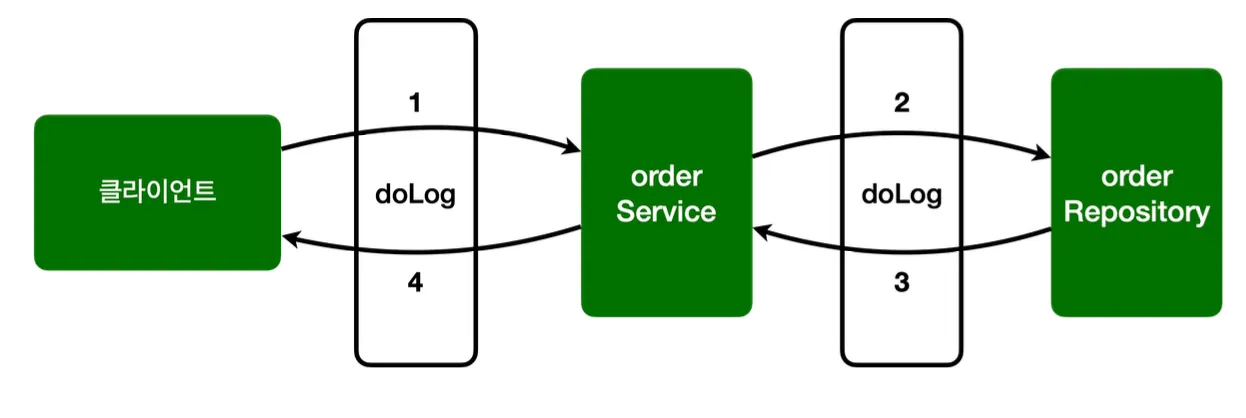
이와 같이 OrderService와 OrderRepository 실행 전에 프록시에서 로그를 남겨줄 것이다.
@Slf4j
@Aspect
public class AspectV2 {
@Pointcut("execution(* hello.aop.order..*(..))")
private void allOrder() {}
@Around("allOrder()")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[log] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
}
Java
복사
여기서 위와 같이 @Pointcut 애노테이션을 통해 포인트컷을 분리할 수 있다. @Pointcut 애노테이션으로 지정된 포인트컷의 메서드 이름과 파라미터를 합쳐 포인트컷 시그니처(signature)라고 한다. @Around 어드바이스에 포인트컷 시그니처를 넣어 사용하여, 동일한 포인트컷에 여러 어드바이스를 적용하는 것이 가능하다.
외부 어드바이스
다른 클래스에 있는 외부 어드바이스에서도 포인트컷을 함께 사용할 수 있다.
public class Pointcut {
@Pointcut("execution(* hello.aop.order..*(..))")
private void allOrder() {}
@Pointcut("execution(* *..*Service.*(..))")
public void allService(){}
@Pointcut("allOrder() && allService()")
public void orderAndService(){}
}
Java
복사
@Slf4j
public class AspectV2 {
@Around("hello.aop.order.Pointcut.allOrder()")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[log] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
}
Java
복사
외부 어드바이스를 포인트컷으로 사용할 때는 위와 같이 패키지 명까지 전부 적어주어야 한다.
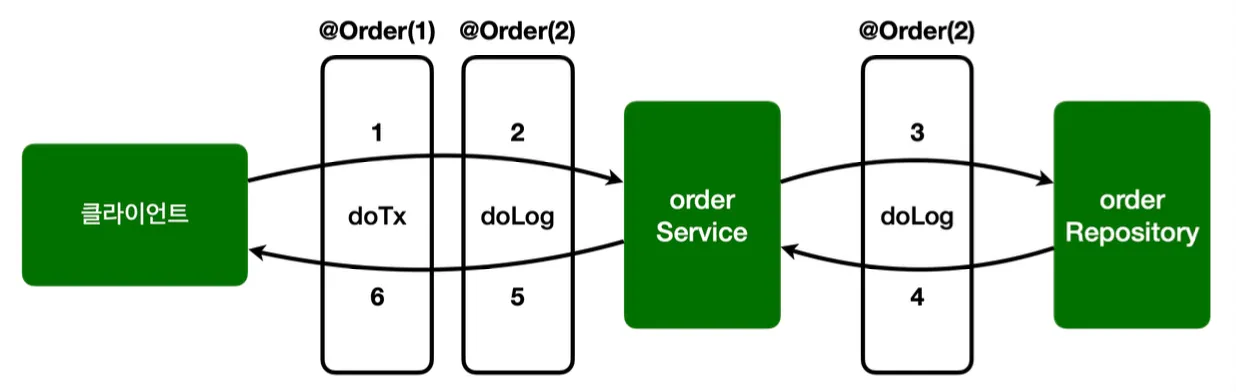
만약 2개 이상의 어드바이스를 적용하면서 그 순서를 지정하고 싶다면,
@Slf4j
public class AspectV3 {
@Aspect
@Order(2)
public static class LogAspect {
@Around("hello.aop.order.Pointcut.allOrder()")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[log] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
}
@Aspect
@Order(1)
public static class TxAspect {
@Around("hello.aop.order.aop.Pointcut.OrderAndService()")
public Object doTransaction(ProceedingJoinPoint joinPoint) throws Throwable {
try {
log.info("[트랜잭션 시작] {}", joinPoint.getSignature());
Object result = joinPoint.proceed();
log.info("[트랜잭션 커밋] {}", joinPoint.getSignature());
return result;
} catch (Exception e) {
log.info("[트랜잭션 롤백] {}", joinPoint.getSignature());
throw e;
} finally {
log.info("[리소스 릴리즈] {}", joinPoint.getSignature());
}
}
}
}
Java
복사
이처럼 @Order 애노테이션을 통해 지정할 수 있다. 여기서 주의할 점은 위와 같이 애스팩트를 별도의 클래스로 분리해야 적용된다는 점이다.
어드바이스 종류
어드바이스의 종류에는 몇 가지가 있다.
•
@Around : 가장 강력한 어드바이스로 메서드 호출 전후에 수행된다. 조인 포인트 실행 여부 선택, 반환 값 변환, 예외 변환 등이 가능하다.
•
@Before : 조인 포인트 실행 직전에 실행
•
@AfterReturning : 조인 포인트가 정상 완료 후 실행
•
@AfterThrowing : 메서드가 예외를 던지는 경우 실행
•
@After : 조인 포인트가 정상 또는 예외에 관계없이 실행(finally)
@Around와 비교하면 어드바이스 종류 별로 실행되는 시점은 다음과 같다.
@Around("hello.aop.order.aop.Pointcut.OrderAndService()")
public Object doTransaction(ProceedingJoinPoint joinPoint) throws Throwable {
try {
// @Before
log.info("[트랜잭션 시작] {}", joinPoint.getSignature());
Object result = joinPoint.proceed();
// @AfterReturning
log.info("[트랜잭션 커밋] {}", joinPoint.getSignature());
return result;
} catch (Exception e) {
// @AfterThrowing
log.info("[트랜잭션 롤백] {}", joinPoint.getSignature());
throw e;
} finally {
// @After
log.info("[리소스 릴리즈] {}", joinPoint.getSignature());
}
}
Java
복사
이를 각각 분리하면 다음과 같이 사용될 수 있다.
@Before("hello.aop.order.aop.Pointcuts.orderAndService()")
public void doBefore(JoinPoint joinPoint) {
log.info("[before] {}", joinPoint.getSignature());
}
@AfterReturning(value = "hello.aop.order.aop.Pointcuts.orderAndService()", returning = "result")
public void doReturn(JoinPoint joinPoint, Object result) {
log.info("[return] {} return={}", joinPoint.getSignature(), result);
}
@AfterThrowing(value = "hello.aop.order.aop.Pointcuts.orderAndService()", throwing = "ex")
public void doThrowing(JoinPoint joinPoint, Exception ex) {
log.info("[ex] {} message={}", joinPoint.getSignature(), ex.getMessage());
}
@After(value = "hello.aop.order.aop.Pointcuts.orderAndService()")
public void doAfter(JoinPoint joinPoint) {
log.info("[after] {}", joinPoint.getSignature());
}
Java
복사
위 어드바이스들을 모두 적용했을 때의 순서는 다음과 같다.
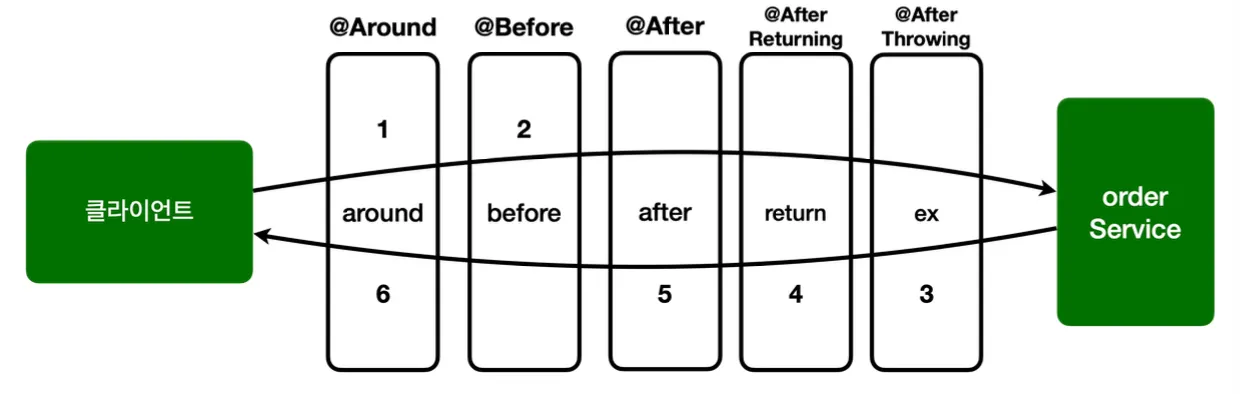
@Around → @Before → @After → @AfterReturning → @AfterThrowing
어드바이스 적용 순서는 이와 같지만, 리턴 순서는 호출 순서와 반대로 진행된다. 물론 @Aspect 안에 동일한 종류의 어드바이스가 2개 이상 있다면 순서가 보장되지 않는다. 이와 같은 경우에는 위에서 했던 것처럼 @Aspect를 분리하고 @Order를 적용해야한다.
가장 큰 차이점으로는, 모든 어드바이스는 첫 번째 파라미터에 JoinPoint를 사용하거나 생략할 수 있지만, @Around는 반드시 ProceedingJoinPoint를 사용해야 한다는 것이다.
@Before 같은 경우에는 ProceedingJoinPoint.proceed()를 호출하지 않더라도, 메서드 종료 시에 자동으로 다음 타겟이 호출된다(예외가 발생하지 않는다면). 하지만 @Around의 경우 proceed 메서드를 호출하지 않으면, 다음 타겟이 실행되지 않는다.
@Around 하나로 모든 기능을 수행할 수 있지만, 다른 어드바이스가 존재하는 이유가 여기에 있다. @Around를 사용하면 proceed 메서드를 실수로 호출하지 않게 되는 경우 큰 장애가 발생할 수 있는데, @Before를 사용하면 애플리케이션에서 호출하기 때문에 그러한 부분을 신경쓰지 않아도 된다. 때문에 실수할 가능성도 낮고 코드도 단순하여, 해당 코드의 작성 의도가 명확하게 드러난다는 점이다.
포인트컷 지시자
포인트컷 지시자
AspectJ는 포인트컷을 편하게 표현하기 위해 AspectJ pointcut expression이라는 특별한 표현식을 제공한다. 줄여서 포인트컷 표현이라 부른다.
이러한 포인트컷 표현식은 포인트컷 지시자(Pointcut Designator)로 시작하는데, 줄여서 PCD라 부른다.
•
execution : 메서드 실행 조인 포인트를 매칭한다. 스프링 AOP에서 가장 많이 사용하고 기능도 복잡하다.
•
within : 특정 타입 내의 조인 포인트를 매칭한다.
•
args : 인자가 주어진 타입의 인스턴스인 조인 포인트를 매칭한다.
•
this : 스프링 빈 객체(스프링 AOP 프록시)를 대상으로 조인 포인트를 매칭한다.
•
target : target 객체(스프링 AOP 프록시가 가리키는 실제 객체)를 대상으로 조인 포인트를 매칭한다.
•
@target : 실행 객체의 클래스에 주인 타입의 애노테이션이 있는 조인 포인트를 매칭한다.
•
@within : 주어진 애노테이션이 있는 타입 내 조인 포인트를 매칭한다.
•
@annotaion : 주어진 애노테이션을 가지고 있는 메서드에 조인 포인트를 매칭한다.
•
@args : 전달된 실제 인수의 런타임 타입이 주어진 타입의 애노테이션을 갖는 조인 포인트를 매칭한다.
•
bean : 스프링 전용 포인트컷 지시자로, 빈의 이름으로 포인트컷을 지정한다.
execution
execution은 포인트컷 표현식과 메서드 정보를 매칭해 대상을 찾아낸다. execution의 문법은 다음과 같다.
"execution(modifiers-patterns? ret-type-pattern declaring-type-pattern?name-pattern(param-pattern) throws-pattern?)"
"execution(접근제어자? 반환타입 선언타입?메서드이름(파라미터) 예외?)"
Java
복사
위 문법을 통해 메서드 실행 조인 포인트를 매칭한다. ?는 생략할 수 있는 문법을 말하며, *을 통해 패턴을 지정하는 것도 가능하다.
@Component
public class MemberServiceImpl implements MemberService {
@Override
@MethodAop("test value")
public String hello(String param) {
return "ok";
}
public String internal(String param) {
return "ok";
}
}
Java
복사
Method helloMethod = MemberServiceImpl.class.getMethod("hello", String.class);
Java
복사
이를 통해 여러 예제를 테스트 해보며 execution 문법을 사용해보자.
pointcut.setExpression("execution(public String hello.aop.member.MemberServiceImpl.hello(String))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
위는 정확하게 접근 제어자부터 반환 타입, 메서드 이름 등 모든 값을 지정하여, 해당 값과 일치하는 메서드 찾는다.
pointcut.setExpression("execution(* *(..))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
모든 표현식을 전부 생략하고 * 패턴을 통해 생략하면 위와 같이 쓸 수도 있다.
pointcut.setExpression("execution(* hello.aop.member.*.*(..))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
이처럼 패키지 이름 중간에 넣어, 해당 패키지 전부를 지정할 수도 있고,
pointcut.setExpression("execution(* hello.aop.member..*.*(..))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
혹은 ..을 통해 해당 위치와 하위 패키지를 모두 포함시켜 간단하게 표현할 수도 있다.
pointcut.setExpression("execution(* hello.aop.member.MemberService.*(..))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
이처럼 MemberServiceImpl이 아닌 부모 인터페이스인 MemberService를 통해 매칭하는 것도 가능하다.
pointcut.setExpression("execution(* hello.aop.member.MemberService.*(..))");
Method internalMethod = MemberServiceImpl.class.getMethod("internal", String.class);
assertThat(pointcut.matches(internalMethod, MemberServiceImpl.class)).isFalse();
Java
복사
하지만 부모 인터페이스에는 없고 자식에만 있는 메서드는 부모 인터페이스 포인트컷으로 매칭할 수 없다.
pointcut.setExpression("execution(* *(String))");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isTrue();
Java
복사
위처럼 파라미터를 특정하여 지정하는 것도 가능하다.
pointcut.setExpression("execution(* *())");
Java
복사
파라미터가 없는 경우는 이처럼 표현하고,
pointcut.setExpression("execution(* *(*))");
Java
복사
하나의 파라미터이면서 모든 타입을 허용하는 경우에는 이와 같이 표현한다.
pointcut.setExpression("execution(* *(..))");
Java
복사
파라미터 개수 상관없이 받고 싶다면 이와 같이 표현하고,
pointcut.setExpression("execution(* *(String, ..))");
Java
복사
이와 같이 앞의 특정 인자를 타입으로 지정하여 받는 것도 가능하다.
within
within 지시자는 특정 선언 타입 내의 조인 포인트들로 매칭을 제한한다.
pointcut.setExpression("within(hello.aop.member.MemberServiceImpl)");
Java
복사
execution에서 처럼 특정 패키지의 클래스 선언 타입을 지정해주면 된다.
pointcut.setExpression("within(hello.aop.member.*Service*)");
pointcut.setExpression("within(hello.aop..*)");
Java
복사
마찬가지로 *을 통한 패턴 매칭도 가능하다.
pointcut.setExpression("within(hello.aop.member.MemberService)");
assertThat(pointcut.matches(helloMethod, MemberServiceImpl.class)).isFalse();
Java
복사
하지만 주의해야할 점은 execution과는 달리 부모 타입을 지정하면 동작하지 않는다. 선언 타입이 정확하게 맞아야 동작한다.
이러한 이유로 보통 within은 잘 사용되지 않고 execution을 사용한다.
args
args는 인자의 타입을 통해 지정된 타입과 인스턴스의 파라미터 타입이 동일한 것만 조인 포인트로 매칭한다.
// 성공
pointcut.setExpression("args(String)");
pointcut.setExpression("args(Object)");
pointcut.setExpression("args(java.io.Serializable)");
pointcut.setExpression("args(..)");
pointcut.setExpression("args(*)");
pointcut.setExpression("args(String, ..)");
// 실패
pointcut.setExpression("args()");
pointcut.setExpression("execution(Object)");
pointcut.setExpression("execution(java.io.Serializable)");
Java
복사
execution에서 파라미터에 사용된 표현식을 전부 사용할 수 있다.
다만 Object나 java.io.Serializable를 넣어도 성공하는 것을 보면 알 수 있듯, execution과의 차이는 args는 부모 타입도 받을 수 있다는 것이다. 이는 args는 런타임에 동적으로 매칭을 확인하고, execution은 정적으로 매칭을 확인하기 때문이다.
args는 단독으로 사용되기 보다는, 주로 파라미터 바인딩에서 사용된다.
@target, @within
@target과 @within은 둘 다 클래스에 적용된 애노테이션이 있는 조인 포인트로 판단한다.
하지만 @target은 인스턴스의 모든 메서드를 조인 포인트로 적용하는 반면, @within은 해당 타입 내에 있는 메서드만 조인 포인트로 적용한다.
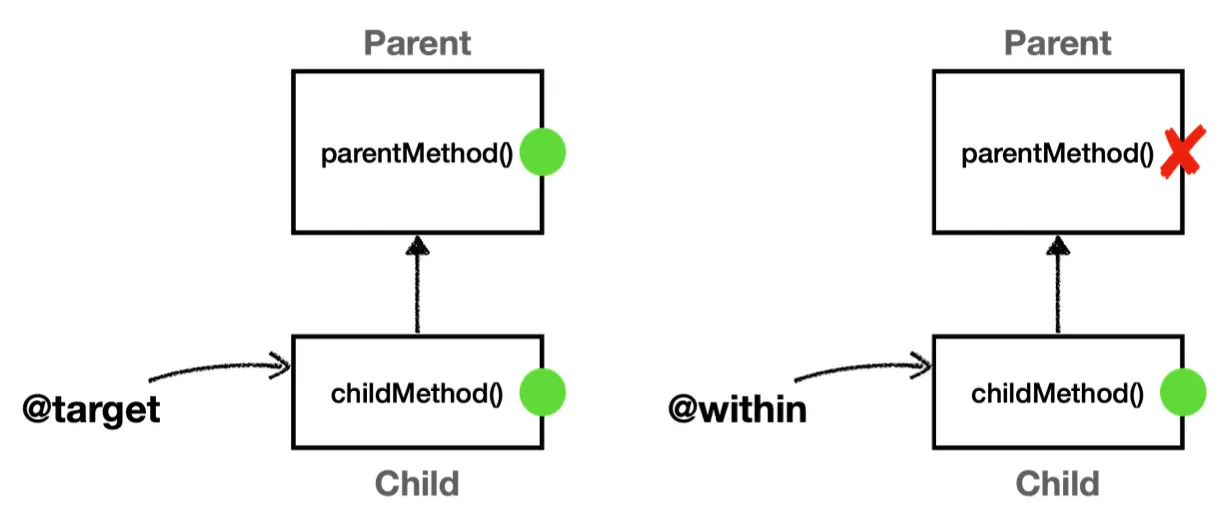
쉽게 말해서, 위 그림처럼 @target은 상속받은 부모 클래스의 메서드까지 어드바이스를 적용하고, @within은 자신의 클래스에 정의된 메서드에만 어드바이스를 적용한다.
@Slf4j
@Import({AtTargetAtWithinTest.Config.class})
@SpringBootTest
public class AtTargetAtWithinTest {
static class Config {
@Bean
public Parent parent() {
return new Parent();
}
@Bean
public Child child() {
return new Child();
}
@Bean
public AtTargetAtWithinAspect atTargetAtWithinAspect() {
return new AtTargetAtWithinAspect();
}
}
static class Parent {
public void parentMethod(){} //부모에만 있는 메서드
}
@ClassAop
static class Child extends Parent {
public void childMethod(){}
}
}
Java
복사
이와 같이 Parent 클래스와 Child 클래스가 있고 @ClassAop 애노테이션을 Child에만 붙였다.
@Around("execution(* hello.aop..*(..)) && @target(hello.aop.member.annotation.ClassAop)")
public Object atTarget(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[@target] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
@Around("execution(* hello.aop..*(..)) && @within(hello.aop.member.annotation.ClassAop)")
public Object atWithin(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[@within] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
Java
복사
그 후 포인트컷에 각각 @target과 @within을 지정하여 넣으면,
[@target] void hello.aop.pointcut.AtTargetAtWithinTest$Child.childMethod()
[@within] void hello.aop.pointcut.AtTargetAtWithinTest$Child.childMethod()
[@target] void hello.aop.pointcut.AtTargetAtWithinTest$Parent.parentMethod()
Plain Text
복사
이와 같이 @target은 부모까지 출력되지만 @within은 자기 자신만 출력된다.
@target과 @within 지시자는 파라미터 바인딩과 함께 사용된다.

args, @args, @target 지시자는 단독으로 사용하면 안된다.
args, @args, @target 지시자는 실제 객체 인스턴스가 생성되고 실행될 때 어드바이스 적용 여부를 판단할 수 있다. 이처럼 실행 시점에 포인트컷 적용 여부를 판단하는 것들은 결국 프록시가 있어야 판단을 할 수 있는데, 스프링 컨테이너가 프록시를 생성하는 로딩 시점에 적용할 수 있다. 때문에 위에서도 스프링 부트 테스트와 클래스를 빈으로 등록하여 작성된 것을 볼 수 있다.
문제는 위 지시자들을 단독으로 사용하여 모든 스프링 빈에 AOP 프록시를 적용하려하면, 스프링 내부에서 사용하는 빈 중 fianl로 지정된 빈들 때문에 오류가 발생한다. 위 예시에서도 execution으로 적용 대상 범위를 줄여서 사용한 것을 볼 수 있다. 이처럼 반드시 적용 대상을 축소하는 표현식과 함께 사용되어야 한다.
@annotaion
@annotaion 지시자는 주어진 애노테이션을 가지고 있는 메서드로 조인 포인트를 매칭한다.
@MethodAop("test value")
public String hello(String param) {
return "ok";
}
Java
복사
이와 같이 애노테이션이 붙어있는 메서드이 있고,
@Around("@annotation(hello.aop.member.annotation.MethodAop)")
public Object doAtAnnotation(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[@annotation] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
Java
복사
이처럼 해당 애노테이션을 @annotaion 지시자로 지정하여 조인 포인트를 지정할 수 있다.
@args
@args 지시자는 전달된 실제 인수의 런타임 타입이 주어진 애노테이션을 갖는 메서드를 조인 포인트로 매칭한다.
public String hello(@Check String param) {
return "ok";
}
Java
복사
이와 같이 파라미터에 특정 애노테이션이 붙어있다면,
@Around("@args(hello.aop.member.annotation.Check)")
public Object doAtAnnotation(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[@args] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
Java
복사
이처럼 조인 포인트로 지정할 수 있다.
실무에서는 거의 사용되지 않는다.
bean
bean 지시자는 스프링 전용 포인트컷 지시자로, 빈의 이름을 지정하여 조인 포인트를 매칭한다.
@Slf4j
@Import(BeanTest.BeanAspect.class)
@SpringBootTest
public class BeanTest {
@Autowired
OrderService orderService;
@Test
void success() {
orderService.orderItem("itemA");
}
@Aspect
static class BeanAspect {
@Around("bean(orderService) || bean(*Repository)")
public Object doLog(ProceedingJoinPoint joinPoint) throws Throwable {
log.info("[bean] {}", joinPoint.getSignature());
return joinPoint.proceed();
}
}
}
Java
복사
이처럼 특정 빈 이름을 통해 조인 포인트로 지정할 수 있다.
args
args 지시자를 통해 어드바이스에 매개 변수를 전달할 수 있다.
@Pointcut("execution(* hello.aop.member..*.*(..))")
private void allMember() {}
@Around("allMember()")
public Object logArg1(ProceedingJoinPoint joinPoint) throws Throwable {
Object arg = joinPoint.getArgs()[0];
log.info("[logArgs1]{}, args={}", joinPoint.getSignature(), arg);
return joinPoint.preceed();
}
Java
복사
기존의 방식에서는 이와 같이 joinPoint를 통해 인자를 꺼내는 것이 가능하다.
@Around("allMember() && args(arg, ..)")
public Object logArg1(ProceedingJoinPoint joinPoint, Object arg) throws Throwable {
log.info("[logArgs1]{}, args={}", joinPoint.getSignature(), arg);
return joinPoint.preceed();
}
Java
복사
하지만 arg 지시자를 사용하면 joinPoint에서 꺼내는 절차를 생략할 수 있다. 거기에 더해 매개 변수가 없다면 해당 어드바이스가 동작하지 않게 되므로 오류가 발생하지 않는다.
this, target
this 지시자는 스프링 빈 객체(스프링 AOP 프록시)를 대상으로 하는 조인 포인트이고, target 지시자는 target 객체(스프링 AOP 프록시가 가리키는 실제 대상)를 대상으로 하는 조인 포인트이다.
"this(hello.aop.member.MemberService)"
"target(hello.aop.member.MemberService)"
Java
복사
둘 다 * 같은 패턴을 사용할 수 없고, 부모 타입을 허용한다.
4가지 예제를 통해 둘의 차이점을 비교해보자.
@Before("this(hello.aop.member.MemberService)")
public void thisInterface(JoinPoint joinPoint) {
log.info("[this-interface] {}", joinPoint.getSignature());
}
Java
복사
@Before("target(hello.aop.member.MemberService)")
public void targetInterface(JoinPoint joinPoint) {
log.info("[target-interface] {}", joinPoint.getSignature());
}
Java
복사
@Before("this(hello.aop.member.MemberServiceImpl)")
public void thisImpl(JoinPoint joinPoint) {
log.info("[this-impl] {}", joinPoint.getSignature());
}
Java
복사
@Before("target(hello.aop.member.MemberServiceImpl)")
public void targetImpl(JoinPoint joinPoint) {
log.info("[target-impl] {}", joinPoint.getSignature());
}
Java
복사
이를 실행시켜보면, CGLIB를 사용할 때는
memberService Proxy=class hello.aop.member.MemberServiceImpl$$EnhancerBySpringCGLIB$$7df96bd3
[target-impl] String hello.aop.member.MemberServiceImpl.hello(String)
[target-interface] String hello.aop.member.MemberServiceImpl.hello(String)
[this-impl] String hello.aop.member.MemberServiceImpl.hello(String)
[this-interface] String hello.aop.member.MemberServiceImpl.hello(String)
Plain Text
복사
이와 같이 모두 적용되지만, JDK 동적 프록시를 사용할 때는
memberService Proxy=class com.sun.proxy.$Proxy53
[target-impl] String hello.aop.member.MemberService.hello(String)
[target-interface] String hello.aop.member.MemberService.hello(String)
[this-interface] String hello.aop.member.MemberService.hello(String)
Plain Text
복사
이와 같이 this-impl이 적용되지 않는 것을 볼 수 있다.
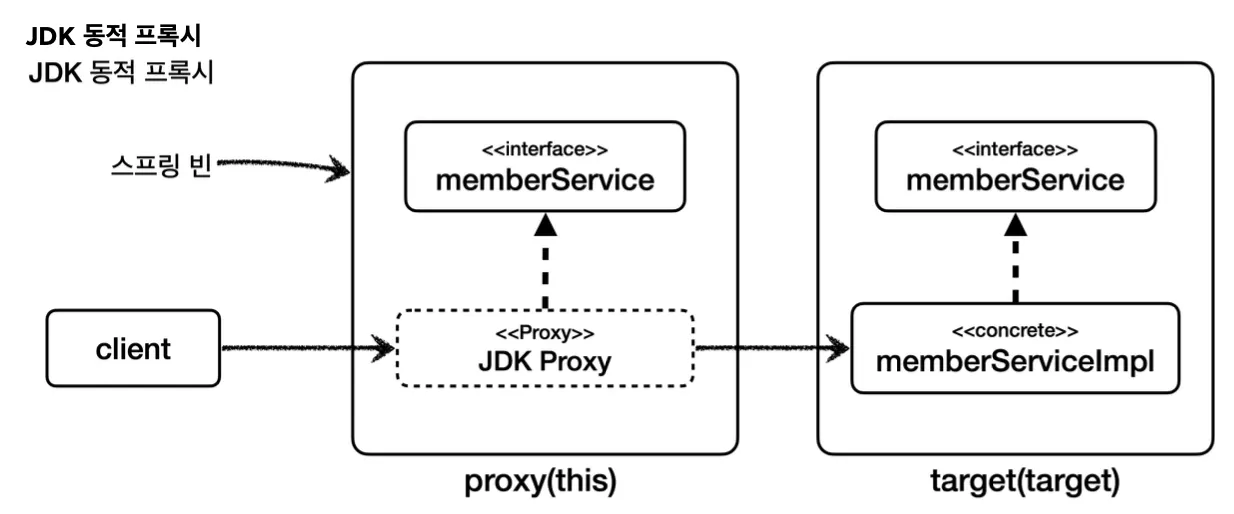
JDK 동적 프록시의 경우
1.
포인트컷에 MemberService 인터페이스 지정
•
this(…MemberService) : 프록시 객체(JDK Proxy)를 보고 판단하고 부모 타입을 허용하기 때문에 AOP가 적용된다.
•
target(…MemberService) : 실제 객체(memberServiceImpl)를 보고 판단하고 부모 타입을 허용하기 때문에 AOP가 적용된다.
2.
포인트컷에 MemberServiceImpl 구체 클래스 지정
•
this(…MemberServiceImpl) : 프록시 객체(JDK Proxy)를 보고 판단하기 때문에 AOP가 적용되지 않는다. 같은 부모를 둔 객체일 뿐 서로 부모-자식 관계가 아니라서 적용되지 않는다.
•
target(…MemberServiceImpl) : 실제 객체(memberServiceImpl)를 보고 판단하기 때문에 AOP가 적용된다.
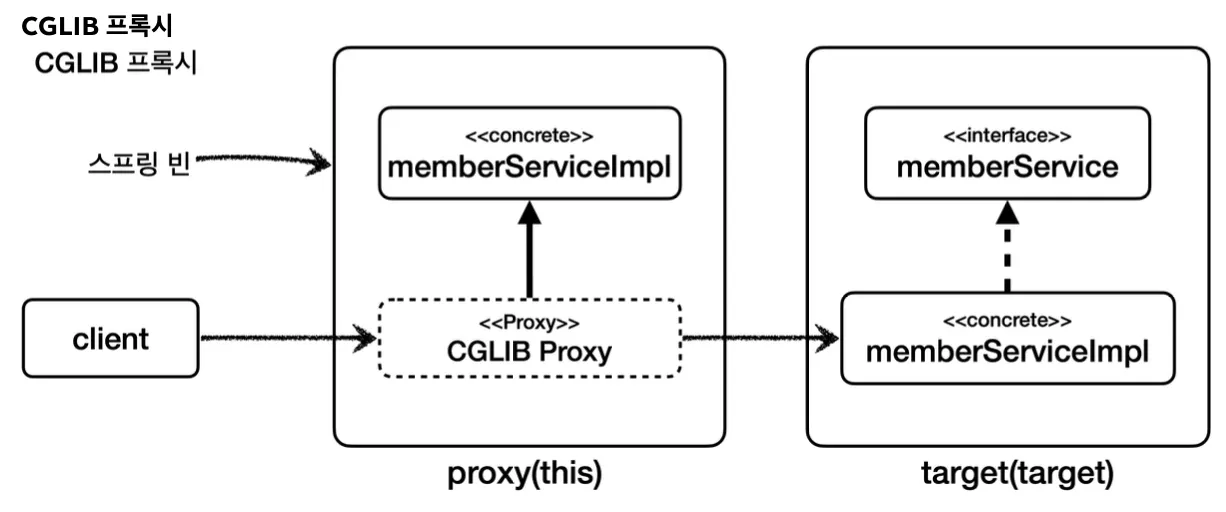
CGLIB의 경우
1.
포인트컷에 MemberService 인터페이스 지정
•
this(…MemberService) : 프록시 객체(CGLIB Proxy)를 보고 판단하고 부모 타입을 허용하기 때문에 AOP가 적용된다.
•
target(…MemberService) : 실제 객체(memberServiceImpl)를 보고 판단하고 부모 타입을 허용하기 때문에 AOP가 적용된다.
2.
포인트컷에 MemberServiceImpl 구체 클래스 지정
•
this(…MemberServiceImpl) : 프록시 객체(CGLIB)를 보고 판단하고 부모 타입을 허용하기 때문에 AOP가 적용된다. CGLIB 프록시 객체는 구체 클래스를 상속 받아 생성된 객체이기 때문이다.
•
target(…MemberServiceImpl) : 실제 객체(memberServiceImpl)를 보고 판단하기 때문에 AOP가 적용된다.
JDK 동적 프록시 사용 설정하기
JDK 동적 프록시를 사용하도록 설정하는 방법은 다음과 같다.
1. 설정 파일에 spring.aop.proxy-target-class=false 추가하기
2. 스프링 부트 테스트에 @SpringBootTest(properties = "spring.aop.proxy-target-class=false" 속성 추가하기
기본 설정은 true이기 때문에 스프링이 AOP를 생성할 때 CGLIB로 사용하고, 이를 false로 바꾸면 JDK 동적 프록시로 사용한다.
여기서 중요한 점은 this는 프록시 객체를 대상으로, target은 타겟이 되는 실제 객체를 대상으로 적용된다는 점이다. this와 target 지시자는 단독으로 사용되기 보다는 파라미터 바인딩에서 주로 사용된다.
스프링 AOP 실전 예제
실전 예제
지금까지 학습한 내용으로 @Trace 애노테이션으로 로그 출력하는 AOP와 @Retry 애노테이션으로 예외 발생 시 재시도하도록 하는 AOP를 만들어보자.
@Repository
public class ExamRepository {
private static int seq = 0;
public String save(String itemId) {
if (++seq % 5 == 0) {
throw new IllegalStateException("예외 발생");
}
return "ok";
}
}
@Service
public class ExamService {
private final ExamRepository examRepository;
public void request(String itemId) {
examRepository.save(itemId);
}
}
Java
복사
이와 같은 서비스와 주기적으로 예외를 던지는 레포지토리가 있고,
@Test
void test() {
for (int i = 0; i < 5; i++) {
examService.request("data" + i);
}
}
Java
복사
위 테스트를 실행할 것이다.
로그 출력 AOP
@Target(ElementType.METHOD)
@Retention(RetentinoPolicy.RUNTIME)
public @interface Trace {
}
Java
복사
@Slf4j
@Aspect
public class TraceAspect {
@Before("@annotation(hello.aop.exam.annotation.Trace)")
public void doTrace(JoinPoint joinPoint) {
Object[] args = joinPoint.getArgs();
info.log("[trace] {} args={}", joinPoint.getSignature(), args);
}
}
Java
복사
이와 같이 애노테이션을 새로 생성하고, 해당 애노테이션을 포인트컷으로 지정하는 어드바이스를 만들면 된다.
재시도 AOP
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Retry {
int value() default 3;
}
Java
복사
@Slf4j
@Aspect
public class RetryAspect {
@Around("@annotation(retry)")
public Object doRetry(ProceedingJoinPoint joinPoint, Retry retry) throws Throwable {
log.info("[retry] {} retry={}", joinPoint.getSignature(), retry);
int maxRetry = retry.value();
Exception exceptionHolder = null;
for (int retryCount = 1; retryCount <= maxRetry; retryCount++) {
try {
log.info("[retry] try count={}/{}", retryCount, maxRetry);
return joinPoint.proceed();
} catch (Exception e) {
exceptionHolder = e;
}
}
throw exceptionHolder;
}
}
Java
복사
이와 같이 특정 횟수까지 반복적으로 실제 객체를 호출하도록 작성한다. 만약 모두 실패한다면 마지막 예외를 던지도록 만든다.
스프링 AOP 주의 사항
프록시 내부 호출
스프링은 프록시 방식의 AOP를 사용하는데, 때문에 AOP를 적용하려면 항상 프록시를 통해 대상 객체(target)를 호출해야한다. 이를 스프링에서는 스프링 빈으로 프록시 객체를 등록하여 의존성 주입 시 프록시 객체를 주입하는 방식으로 구현한다.
이러한 방식은 일반적으로는 문제가 없지만, 대상 객체의 내부에서 메서드 호출이 발생하면 프록시를 거치지 않고 직접 호출하는 문제가 발생한다.
@Slf4j
@Aspect
public class CallLogAspect {
@Before("execution(* hello.aop.internalcall..*.*(..))")
public void doLog(JoinPoint joinPoint) {
log.info("aop={}", joinPoint.getSignature());
}
}
Java
복사
@Slf4j
@Component
public class CallServiceV0 {
public void external() {
log.info("call external");
internal(); //내부 메서드 호출(this.internal())
}
public void internal() {
log.info("call internal");
}
}
Java
복사
이와 같이 external 메서드에서 내부 메서드인 internal 메서드를 직접 호출하는 경우,
CallLogAspect : aop=void hello.aop.internalcall.CallServiceV0.external()
CallServiceV0 : call external
CallServiceV0 : call internal
Plain Text
복사
이처럼 internal 메서드를 직접 호출할 때 AOP가 적용되지 않는다.
위 그림을 보면, 외부에서 호출하는 경우에는 스프링 컨테이너에서 의존성 주입 때 넣어둔 프록시 객체를 통해 호출하기 때문에 CallLogAspect 어드바이스가 적용된다. 하지만 내부에서 호출하는 경우에는 자기 인스턴스를 직접 호출하기 때문에, CallLogAspect 어드바이스가 호출되지 않는다.
이에 대한 대안은 3가지 정도 있다.
1.
자기 자신 주입
@Slf4j
@Component
public class CallServiceV1 {
private CallServiceV1 callServiceV1;
@Autowired
public void setCallServiceV1(CallServiceV1 callServiceV1) {
this.callServiceV1 = callServiceV1;
}
public void external() {
log.info("call external");
callServiceV1.internal();
}
public void internal() {
log.info("call internal");
}
}
Java
복사
첫 번째 방법은 위처럼 자기 자신을 의존성 주입하여, 내부 호출 시 주입 받은 자기 자신의 인스턴스를 통해 호출하는 방법이다.
여기서 중요한 점은 생성자 주입을 통해 자기 자신을 주입 받으려하면, 자신의 인스턴스 생성 시에 자신을 주입 받으려하는 상황으로 순환 참조가 발생하게 된다. 때문에 위처럼 setter를 통해 주입 받아야 한다.
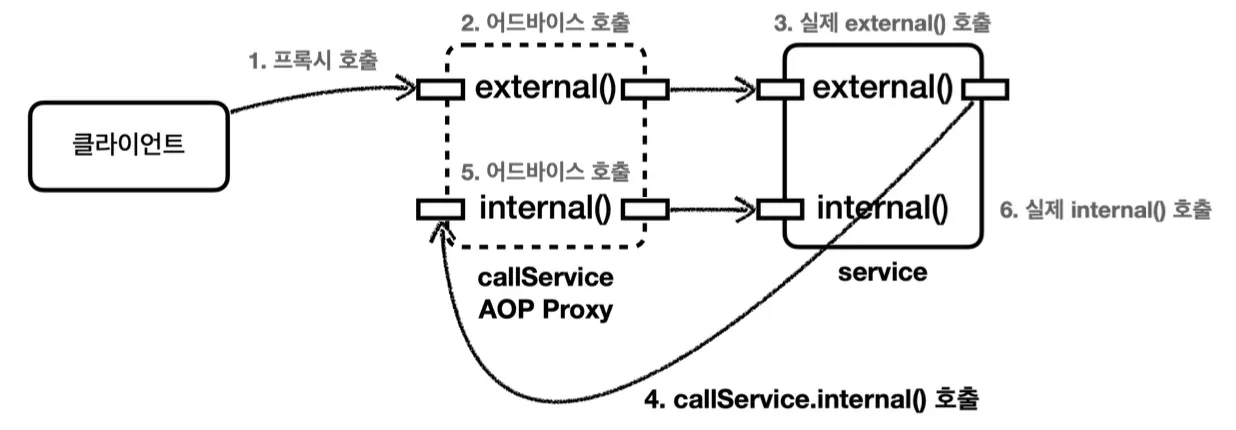
이와 같은 순서로 호출하게 되어,
CallLogAspect : aop=void hello.aop.internalcall.CallServiceV0.external()
CallServiceV0 : call external
CallLogAspect : aop=void hello.aop.internalcall.CallServiceV1.internal()
CallServiceV0 : call internal
Plain Text
복사
어드바이스가 잘 적용되는 것을 확인할 수 있다.
2.
지연 조회
@Slf4j
@Component
@RequiredArgsConstructor
public class CallServiceV2 {
// private final ApplicationContext applicationContext;
private final ObjectProvider<CallServiceV2> callServiceProvider;
public void external() {
log.info("call external");
// CallServiceV2 callServiceV2 = applicationContext.getBean(CallServiceV2.class);
CallServiceV2 callServiceV2 = callServiceProvider.getObject();
callServiceV2.internal();
}
public void internal() {
log.info("call internal");
}
}
Java
복사
두 번째 방식은 스프링 컨테이너에서 직접 스프링 빈을 꺼내와 조회하는 지연 조회 방식이다. ApplicationContext에서 직접 꺼내도 되고 ObjectProvider를 통해 꺼내도 되지만, ApplicationContext 너무 많은 기능을 제공하기 때문에 ObjectProvider를 사용하는 것이 권장된다.
3.
구조 변경
@Slf4j
@Component
@RequiredArgsConstructor
public class CallServiceV3 {
private final InternalService internalService;
public void external() {
log.info("call external"); internalService.internal(); //외부 메서드 호출
}
}
Java
복사
@Slf4j
@Component
public class InternalService {
public void internal() {
log.info("call internal");
}
}
Java
복사
마지막 방법은 위와 같이 구조를 변경하는 방법이다.
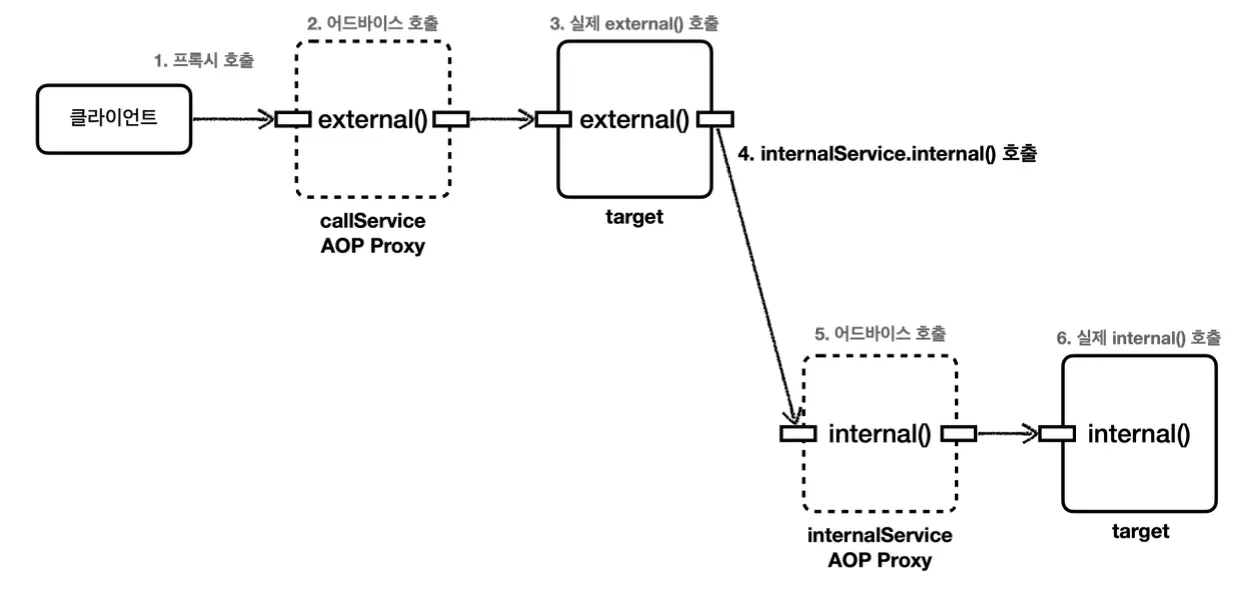
이를 통해 내부 호출 자체가 사라지고, setter나 ObjectProvider 없이도 자연스럽게 AOP가 적용되도록 만들 수 있다. 이러한 구조 변경 방식은 위 방식 외에도 클라이언트에서 external과 internal을 순차적으로 호출하도록 바꾸는 방법 등 여러 방식으로 바꿀 수 있다.
일반적으로 AOP는 public 메서드에만 적용하는데, AOP를 적용하기 위해 private 메서드를 외부 클래스로 변경하는 일은 거의 없다. public에서 public을 부르는 경우가 대다수이기 때문에, 이런 경우에는 구조 변경을 고려해보자.
타입 캐스팅과 의존성 주입
JDK 동적 프록시와 CGLIB를 통해 프록시를 생성하는 방법에는 각각 장단점이 있다. JDK 동적 프록시는 인터페이스가 반드시 필요하고 CGLIB는 구체 클래스를 기반으로 프록시를 생성하는데, 인터페이스가 있는 경우에는 둘 중 아무거나 선택하여 사용할 수 있다. 그런 경우에 발생할 수 있는 문제를 알아보자.
@Slf4j
public class ProxyCastingTest {
@Test
void jdkProxy() {
MemberServiceImpl target = new MemberServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.setProxyTargetClass(false); // JDK 동적 프록시
MemberService memberServiceProxy = (MemberService) proxyFactory.getProxy();
// JDK 동적 프록시를 구현 클래스로 캐스팅 시도
assertThrows(ClassCastException.class, () -> {
MemberServiceImpl castingMemberService
= (MemberServiceImpl) memberServiceProxy;
});
}
}
Java
복사
먼저 JDK 동적 프록시를 통해 프록시 객체를 생성한 경우에는, 위와 같이 구체 클래스로 캐스팅할 때 ClassCastException 예외가 발생한다.
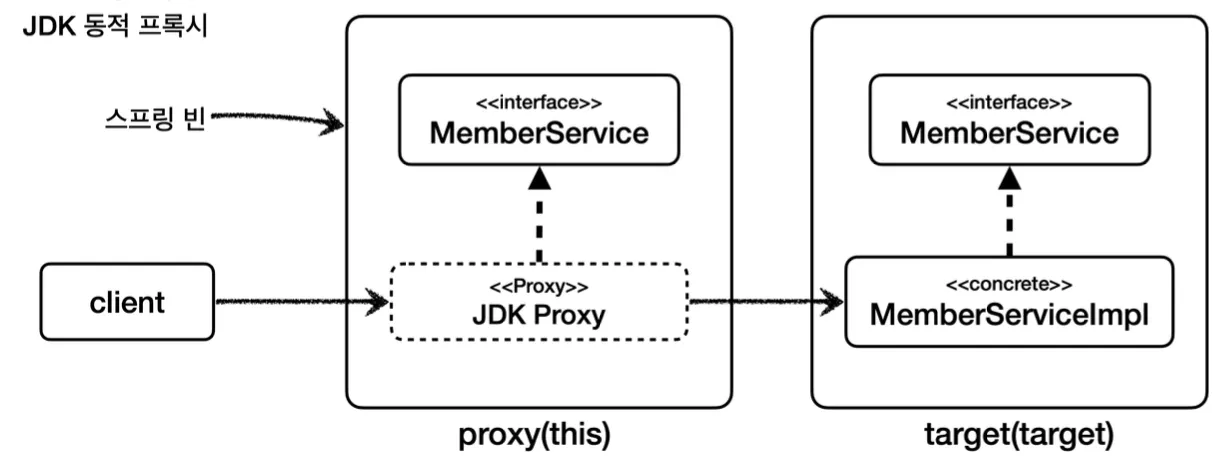
그 이유는 JDK 동적 프록시로 생성된 프록시 객체는 MemberService 인터페이스를 기준으로 생성되었기 때문이다.
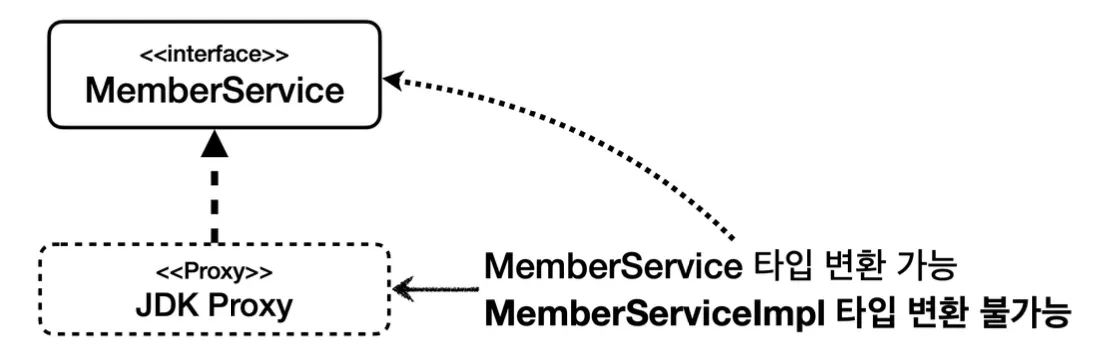
MemberServiceImpl은 프록시 객체와 같은 부모를 공유할 뿐, 어떤 객체인지 전혀 알 지 못하기 때문에 캐스팅이 불가능하다.
@Slf4j
public class ProxyCastingTest {
@Test
void jdkProxy() {
MemberServiceImpl target = new MemberServiceImpl();
ProxyFactory proxyFactory = new ProxyFactory(target);
proxyFactory.setProxyTargetClass(true); // CGLIB 프록시
MemberService memberServiceProxy = (MemberService) proxyFactory.getProxy();
// JDK 동적 프록시를 구현 클래스로 캐스팅 시도 성공
MemberServiceImpl castingMemberService = (MemberServiceImpl) memberServiceProxy;
}
}
Java
복사
반면 CGLIB를 통해 생성된 프록시 객체는 구체 클래스로 캐스팅에 성공한다.
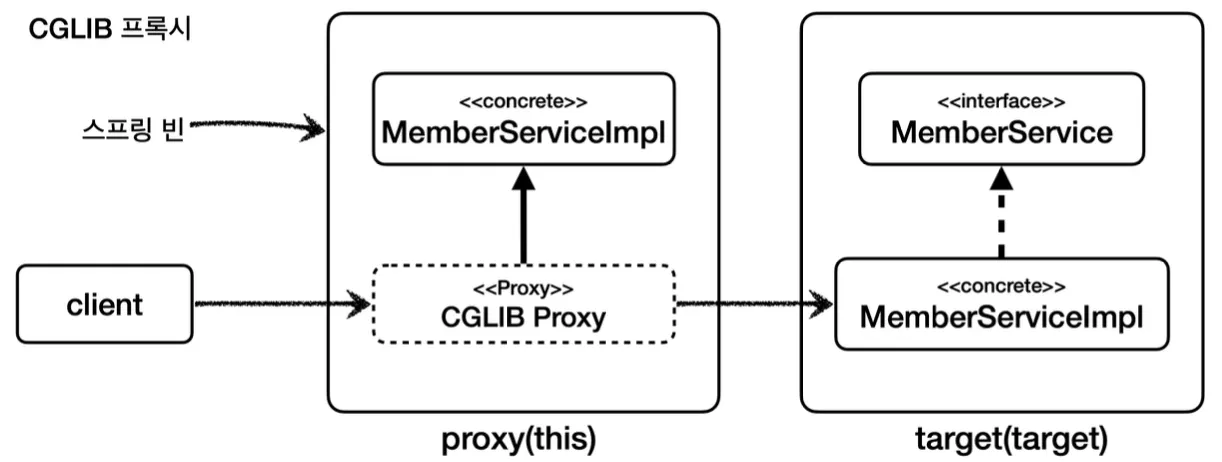
이는 구체 클래스를 기반으로 프록시가 생성되었기 때문에 당연한 결과이며,
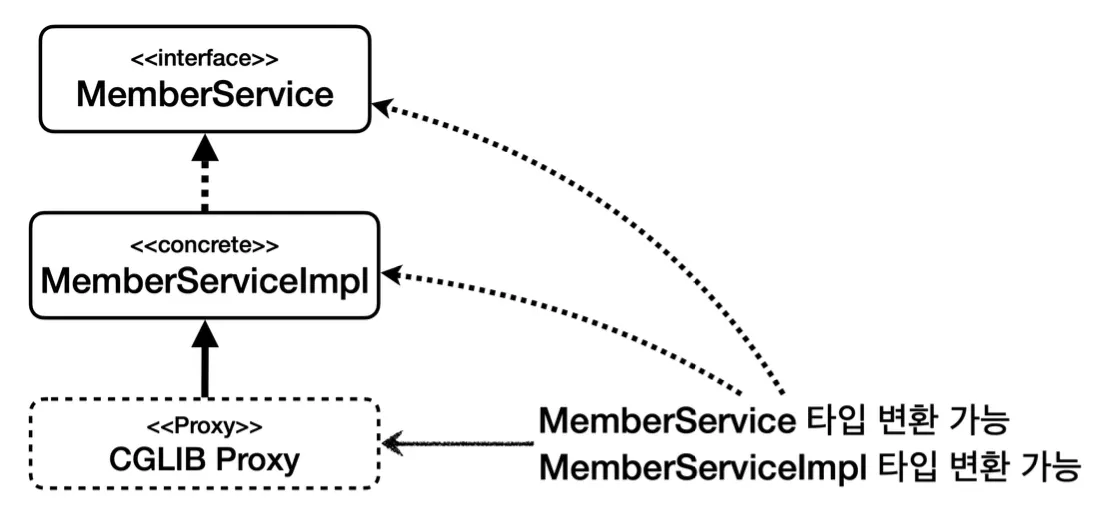
MemberServiceImpl이 구현한 인터페이스인 MemberService 인터페이스로 캐스팅하는 것도 가능하다.
이러한 차이로 인해 의존성 주입 시 다음과 같은 문제가 발생한다.
@Slf4j
@Aspect
public class ProxyDIAspect {
@Before("execution(* hello.aop..*.*(..))")
public void doTrace(JoinPoint joinPoint) {
log.info("[proxyDIAdvice] {}", joinPoint.getSignature());
}
}
Java
복사
이러한 로그 AOP를 프록시로 적용한다고 하면,
@Slf4j
@SpringBootTest(properties = {"spring.aop.proxy-target-class=false"}) //JDK 동적 프록시
@Import(ProxyDIAspect.class)
public class ProxyDITest {
@Autowired MemberService memberService; //JDK 동적 프록시 OK, CGLIB OK
@Autowired MemberServiceImpl memberServiceImpl; //JDK 동적 프록시 X, CGLIB OK
@Test
void go() {
log.info("memberService class={}", memberService.getClass());
log.info("memberServiceImpl class={}", memberServiceImpl.getClass());
memberServiceImpl.hello("hello");
}
}
Java
복사
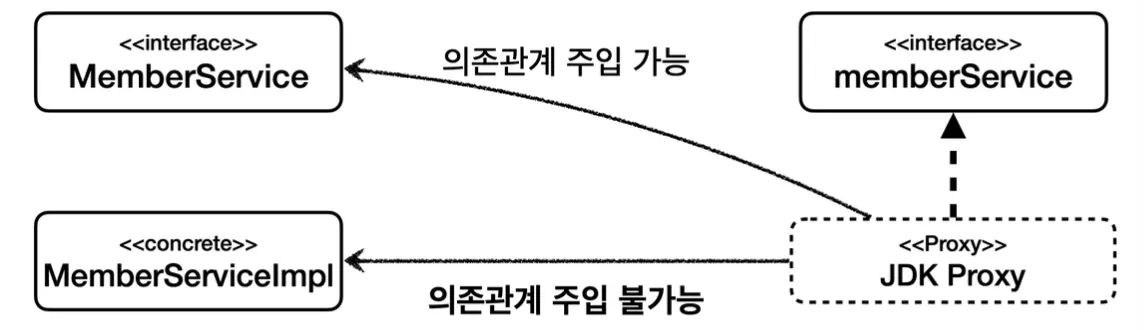
이와 같이 MemberService를 의존성 주입하는 경우에는 문제가 없지만 JDK 동적 프록시를 사용하는 경우에 MemberServiceImpl에 의존성 주입이 되지 않고 예외가 발생한다.
@Slf4j
@SpringBootTest(properties = {"spring.aop.proxy-target-class=true"}) //CGLIB 프록시
@Import(ProxyDIAspect.class)
public class ProxyDITest {
@Autowired MemberService memberService; //JDK 동적 프록시 OK, CGLIB OK
@Autowired MemberServiceImpl memberServiceImpl; //JDK 동적 프록시 X, CGLIB OK
@Test
void go() {
log.info("memberService class={}", memberService.getClass());
log.info("memberServiceImpl class={}", memberServiceImpl.getClass());
memberServiceImpl.hello("hello");
}
}
Java
복사
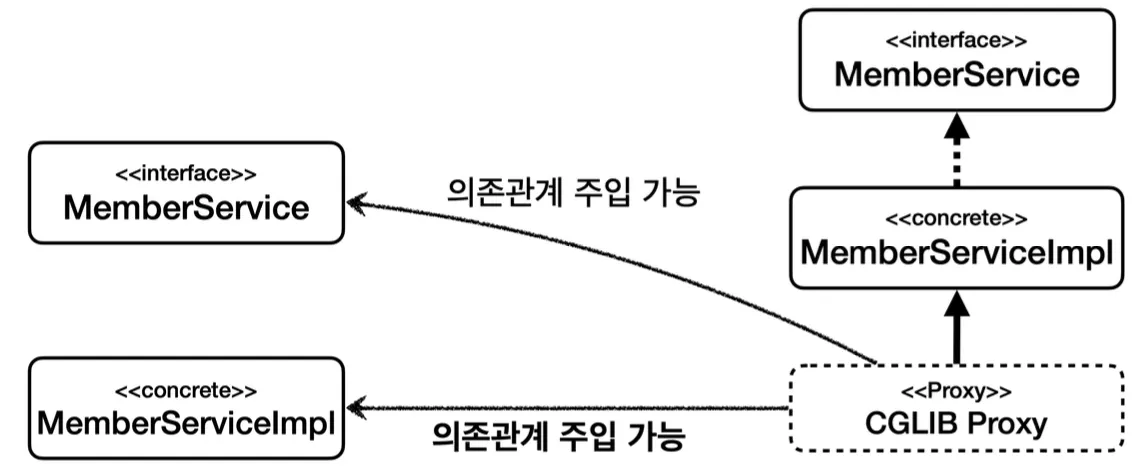
하지만 CGLIB를 사용하면 MemberService와 MemberServiceImpl 모두에 문제 없이 의존성 주입이 된다.
위 내용을 볼 때, CGLIB를 사용하면 인터페이스와 구체 클래스에 대한 고민 없이 사용할 수 있을 것 같다. 하지만 이전에도 언급했듯, CGLIB는 구체 클래스를 상속받아 프록시 객체를 생성하기 때문에 상속의 문제점을 그대로 안고 간다.
•
대상 클래스에 기본 생성자가 반드시 존재해야함
프록시 객체를 상속받아 생성하기 때문에, 자식 클래스를 생성할 때 부모 클래스의 생성자(super)를 호출해야 한다.
•
생성자를 2번 호출(프록시 객체 생성 시 super 호출, 실제 객체 생성)
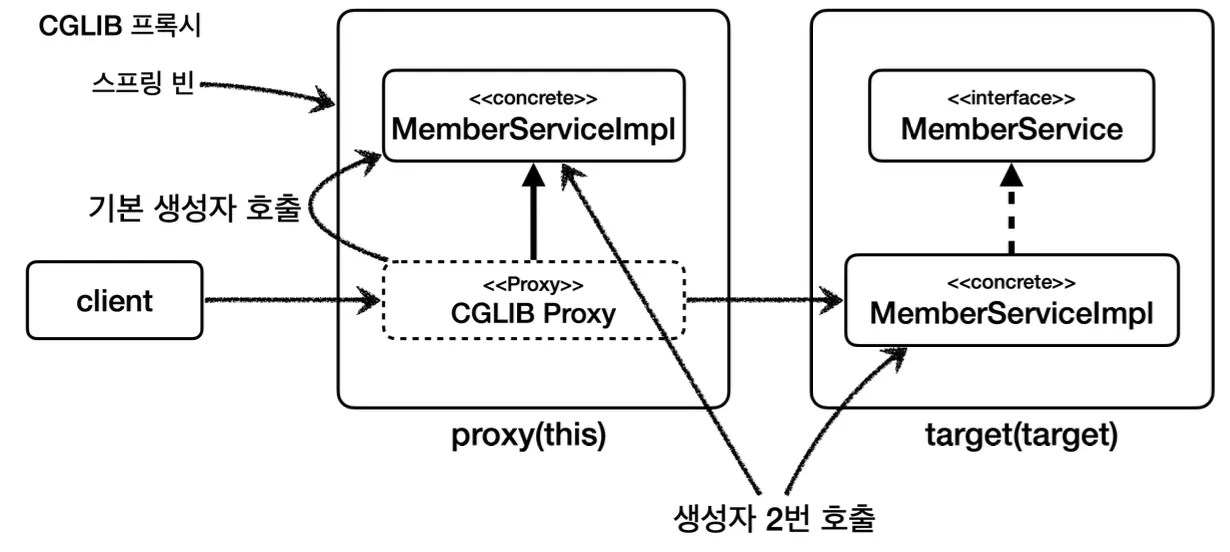
위와 동일한 이유로 구체 클래스의 생성자가 2번 호출되게 된다.
•
final 클래스, 메서스 사용 불가
클래스에 final 키워드가 붙어있다면 상속이 불가능하고, 메서드에 붙어있다면 재정의하는 것이 불가능하다.
현재 스프링 3.0 이후부터는 CGLIB를 기본으로 설정하고 있는데, 이는 objenesis라는 특별한 라이브러리를 도입하였기 때문이다.
objenesis는 기본 생성자 없이도 객체 생성을 가능하게 해주는 라이브러리인데, 이를 통해 구체 클래스의 기본 생성자가 필요하다는 문제와, 생성자가 2번 호출되는 문제가 해결되어 CGLIB를 기본으로 사용하도록 설정해두는 것이다.
추가적으로 final 키워드는 잘 사용하지 않기 때문에 큰 문제가 발생하지 않아 무시되었다.

