분산 시스템의 데이터 일관성
분산 시스템에서는 서비스를 분리할수록 트랜잭션을 보장하기 어려워진다. 특히 이벤트 소싱 패턴과 같이 이벤트를 통해 작업을 처리하는 경우 트랜잭션과 데이터 일관성을 유지하기 위해서는 추가적인 방법이 필요하다.
이와 같은 상황에서 데이터의 일관성을 유지하기 위한 방법으로는 메세징(Messaging) 방식과 Transactional Outbox Pattern, Two-Phase Commit 방식과 Saga 분산 트랜잭션 패턴 등이 있다.
메세징(Messaging)
MSA 애플리케이션에서는 API 호출이 다른 API를 호출하고, 이로 인한 다수의 API 호출의 네트워크 비용과 클라이언트가 호출해야할 API 주소를 모두 알아야한다는 문제가 있다. 추가적으로 트랜잭션을 로직 전체에 유지하면 클라이언트가 호출해야하는 API가 많아질수록 각 API 호출을 받는 서버 중 하나의 장애가 다른 서버의 장애로 이어지는 문제가 발생할 수 있다.
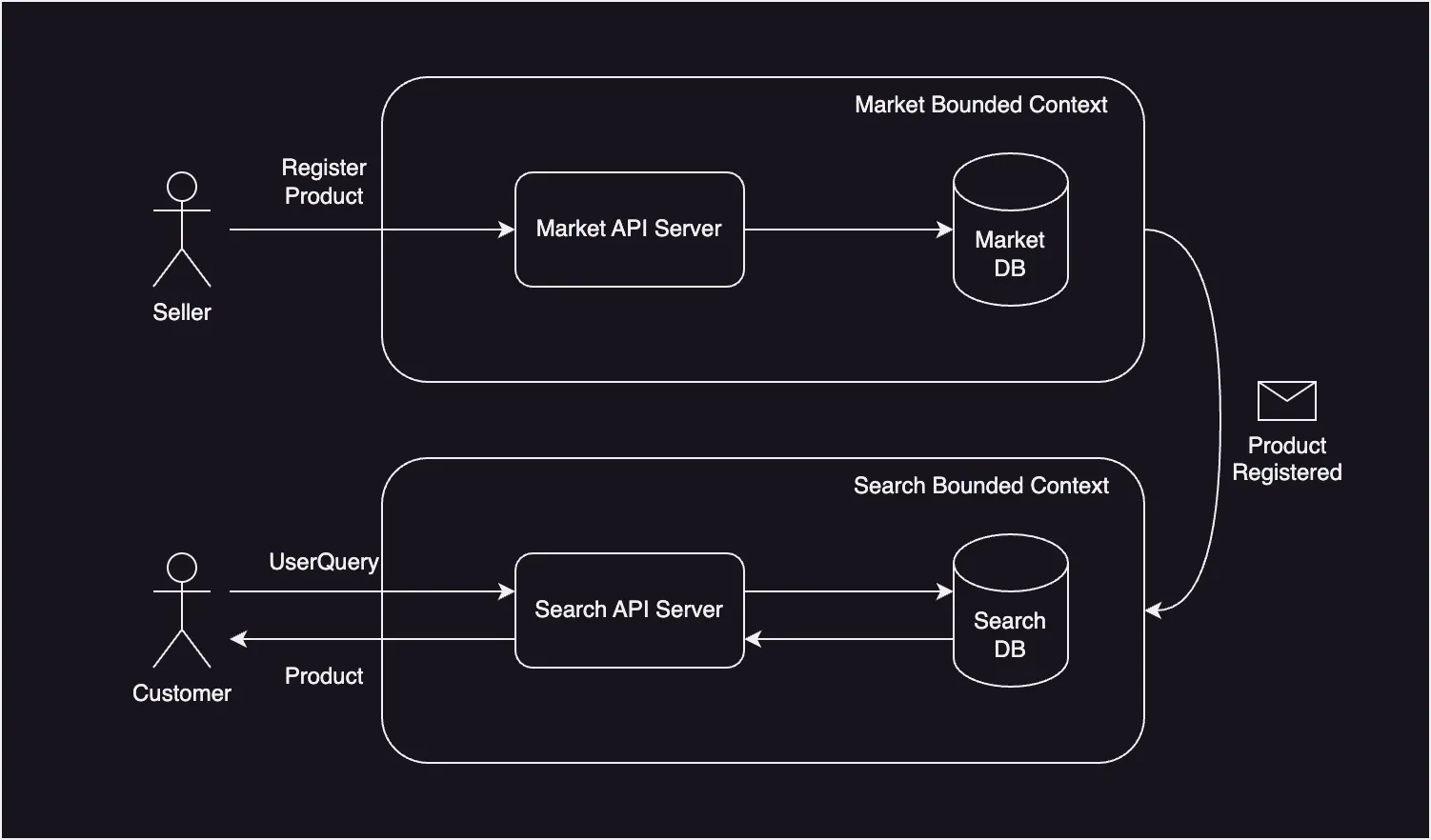
이런 문제들의 해결 방안으로 각 서버 간의 의존도를 낮추고 비동기적으로 처리하기 위해 이벤트를 활용한 메세징 처리 방식을 사용한다. 일반적으로 Kafka나 RabbitMQ 같은 Message Broker를 사용하여 메세징을 구현한다.
Transactional Outbox Pattern
메세징 방식에서는 몇 가지 문제가 발생할 여지가 있다. 메세징 큐가 고장나거나 발행한 이벤트의 순서가 섞이는 경우, 이벤트 발행에는 성공했지만 저장에 실패해 DB에는 반영이 안되는 경우, 이벤트를 발행했지만 처리되지 않고 유실되는 경우 등의 상황들에서는 데이터 일관성이 깨지게 된다.
Transactional Outbox Pattern은 이런 문제들을 해결하기 위해, 메세지 큐 대신 Outbox라는 DB 테이블을 이용하는 방식이다. 구체적인 동작 순서는 다음과 같다.
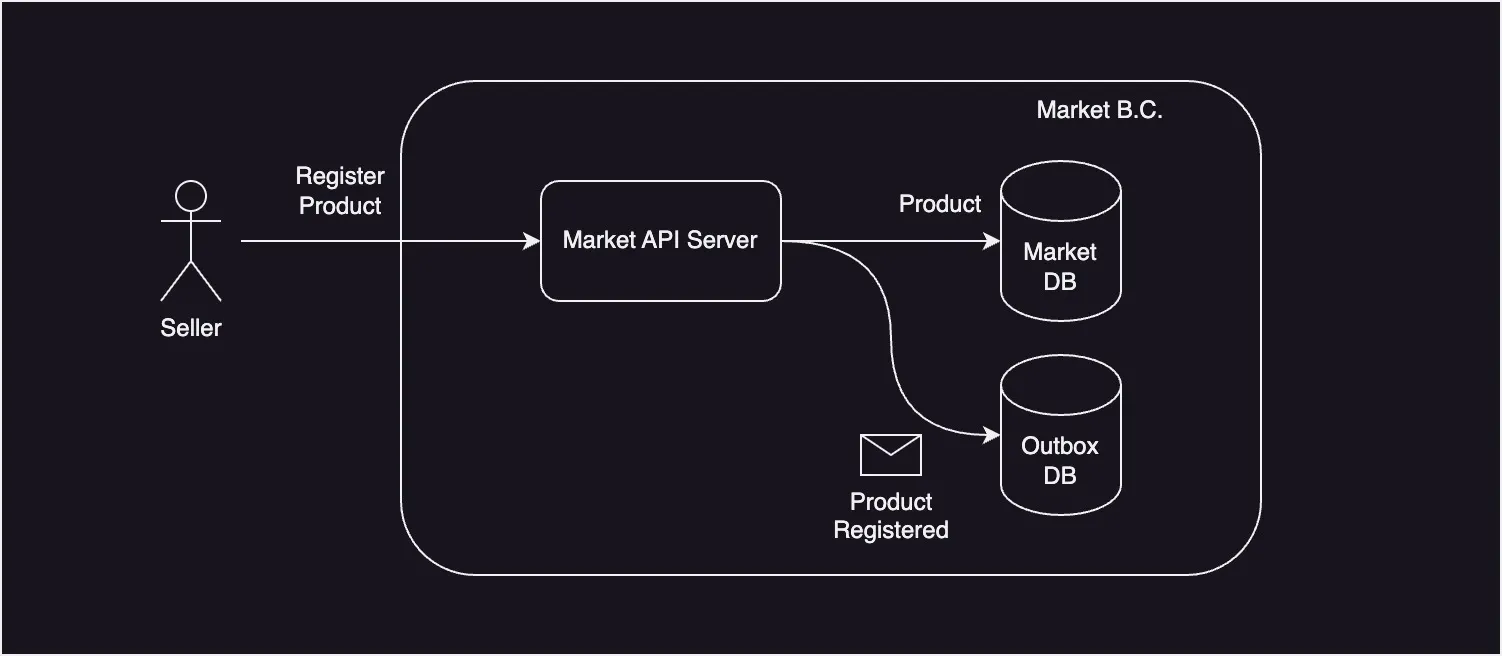
트랜잭션 내에서 Outbox DB 테이블에 데이터를 삽입하여 메세지를 저장한다.
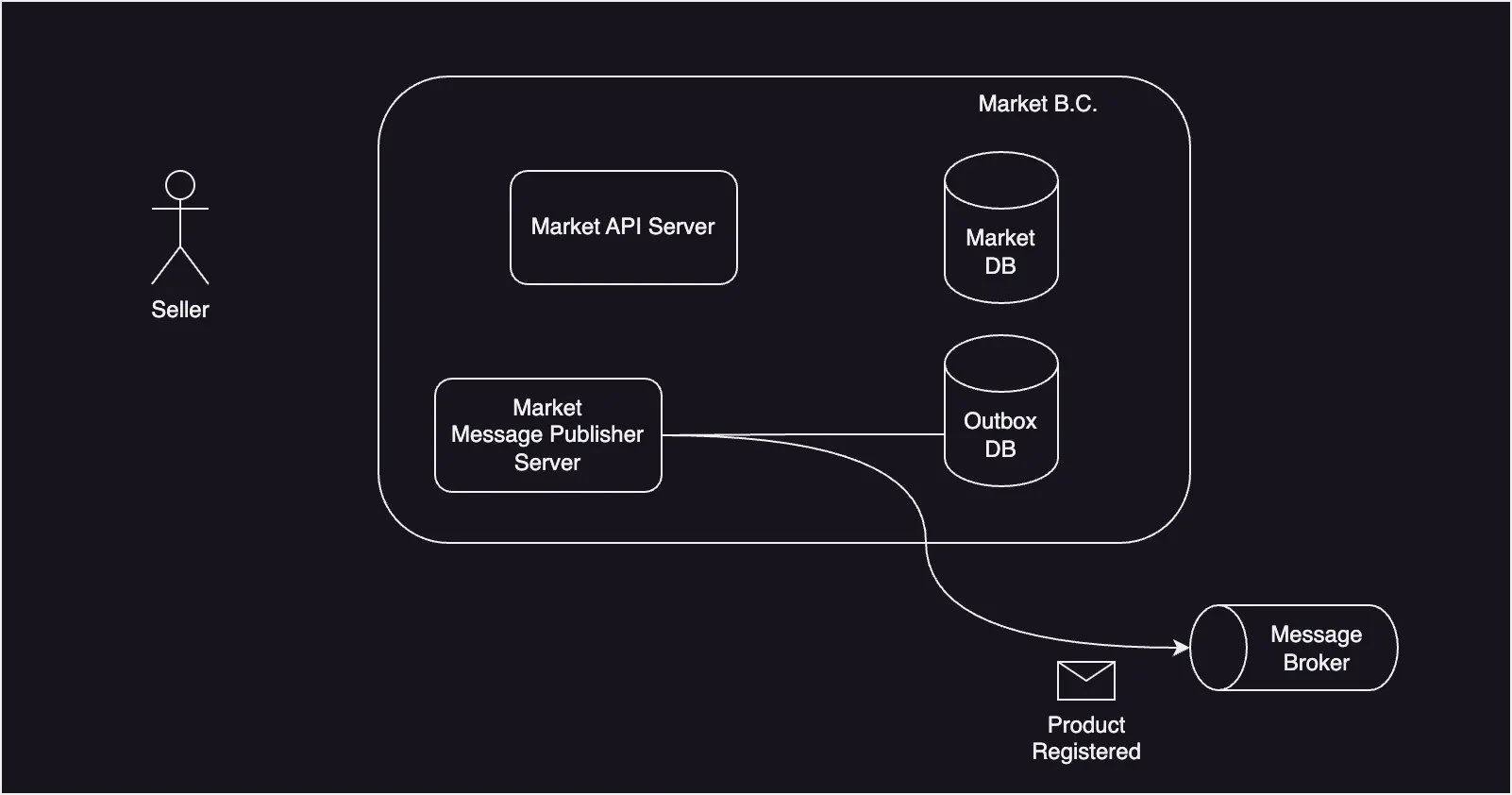
Message Publisher에서 CDC(Change Data Capture)나 Poll 방식 등을 이용해 변경 감지하고, Outbox DB 테이블에 저장된 메세지를 읽어 Broker에 이벤트를 발행한다.
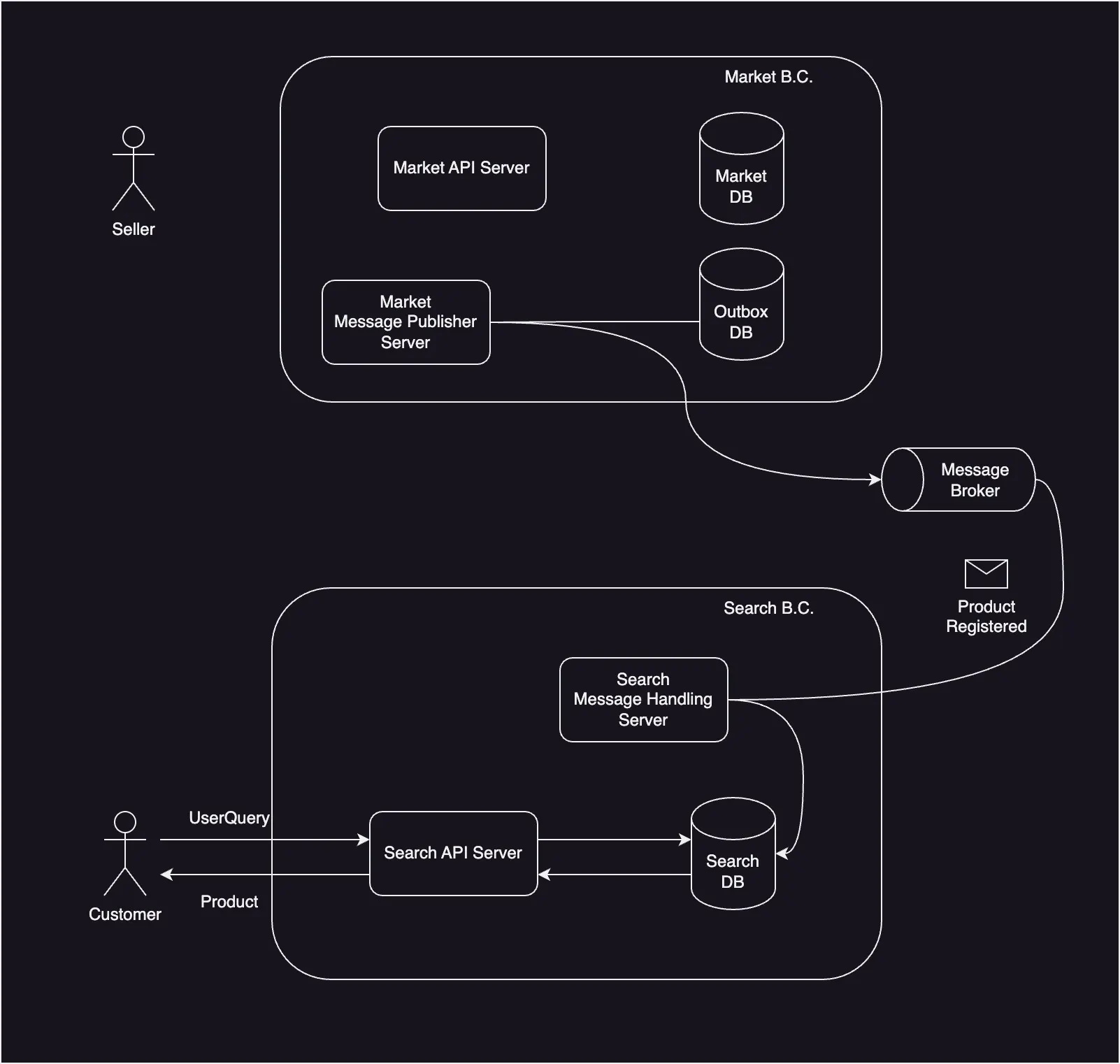
Broker에서 발행된 이벤트를 알맞는 서비스에 데이터를 전달하여 이벤트를 처리한다.
이처럼 Outbox 패턴을 적용하게 되면, DB를 통해 데이터 일관성을 유지하기 때문에 이벤트 순서가 섞이지 않으며, 로그 테일링(Log Tailing)이나 배치 작업 등을 이용해 이벤트가 유실되거나 이벤트 발행 이후 실패하더라도 재발행하여 최소 한 번의 메세지 전달(ALO, At-Least Once)을 보장한다.
2PC(Two-Phase Commit)
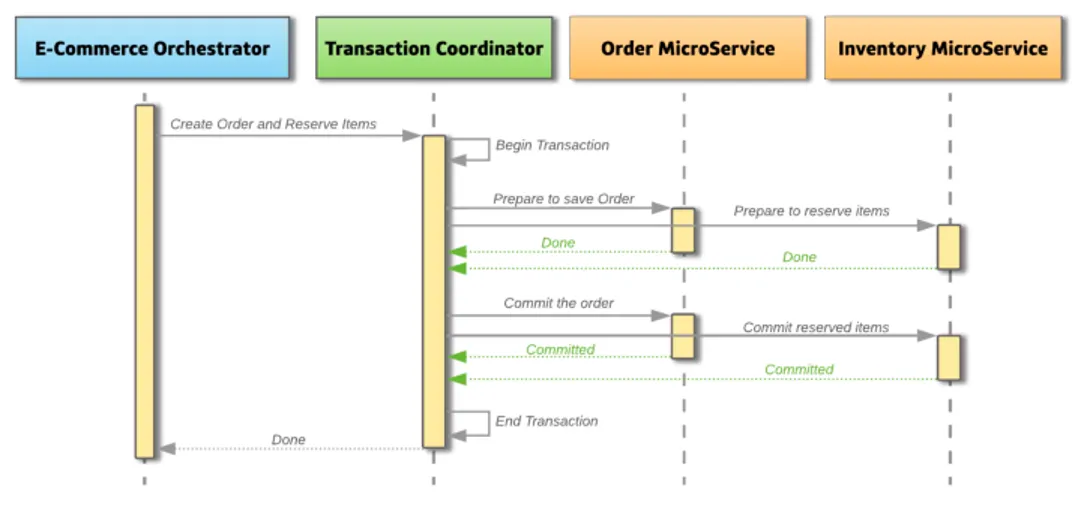
그 외에도 분산 시스템에서 분산 트랜잭션에 사용되는 패턴 중에 2PC 방식이 있다. 2PC 방식은 관련된 모든 서비스가 Commit을 준비하는 Prepare 단계를 거친 후 모든 서비스가 준비가 되면 일괄적으로 Commit을 수행하는 방식이다. 2PC 방식은 Prepare 단계와 Commit 단계로 구성된다.
•
Prepare Phase
관련된 모든 서비스는 Commit을 준비한다. 준비가 완료되면 Transaction Coordinator에 트랜잭션을 시작할 준비가 되었음을 알린다.
•
Commit Phase
Prepare 단계에서 모든 서비스가 트랜잭션을 시작할 준비가 되었다면, Coordinator가 Commit을 요청한다.
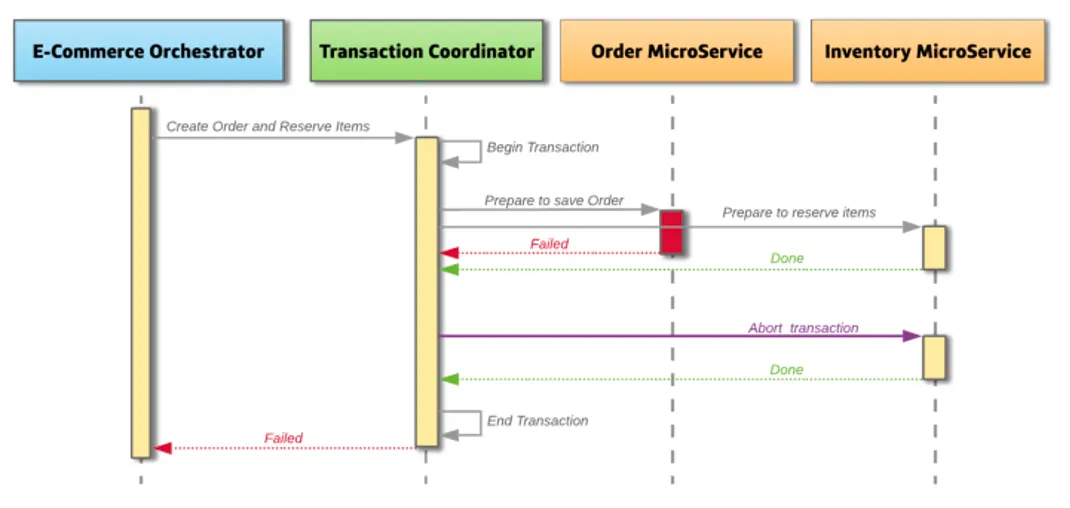
만약 Commit 단계에서 하나의 서비스라도 실패한다면, Coordinator가 모든서비스에 트랜잭션 롤백을 요청한다.
2PC 방식은 트랜잭션의 원자성을 보장하고, Coordinator를 통해 모든 서비스의 트랜잭션이 성공하거나 롤백된 상태를 만들어 데이터 일관성을 유지한다.
분산 트랜잭션 처리를 위한 전통적인 방법이지만, Coordinator에 의존적인 방식이고 모든 서비스가 준비될 때까지 Lock을 걸고 대기하기 때문에 성능 측면에서 별로 효율적이지 않다. 또한 NoSQL의 일부는 2PC 방식을 지원하지 않아 제약이 있다.
Saga Pattern
Saga 패턴은 각 서비스를 업데이트하고 메세지나 이벤트를 게시해서 다음 트랜잭션 실행을 트리거하여 순차적으로 처리하는 방식이다. 연속적으로 로컬 트랜잭션을 실행하다가 실패하면 이전 로컬 트랜잭션에 의해 변경했던 사항을 취소하는 보상 트랜잭션을 실행한다.
일반적으로 Orchestration 방식과 Choreography 방식 두 가지로 구분된다.
•
Orchestration 방식
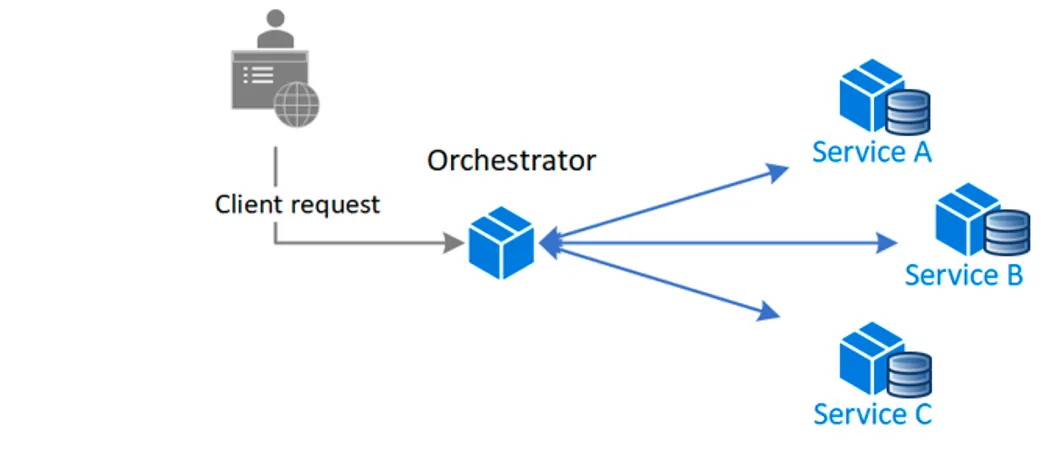
Orchestrator가 중앙 집중식 컨트롤러 역할을 수행하고, 각 서비스에 실행할 트랜잭션을 알려주는 방법이다. Orchestrator가 각 서비스의 상태를 확인하고, 만약 트랜잭션이 실패하면 그동안의 호출에 대한 보상 이벤트를 호출하여 데이터 정합성을 맞춘다.
Choreography 방식에 비해 서비스의 복잡도가 낮기 때문에, 많은 서비스가 있는 복잡한 워크플로우나 서비스 및 워크플로우에 제어가 필요한 경우에 적합하다.
하지만 Orchestrator 전체 워크플로우의 단일 장애 포인트가 될 수 있다.
•
Choreography 방식
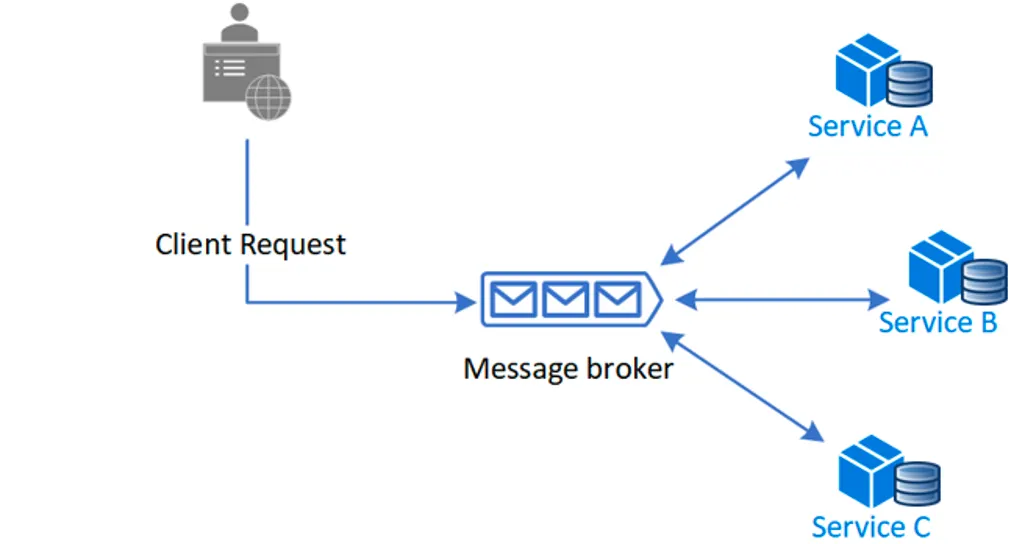
각 로컬 트랜잭션이 다른 서비스의 로컬 트랜잭션 이벤트를 트리거하는 방식으로, 중앙 집중된 지점 없이 이벤트를 교환하고 모든 서비스가 메세지 브로커를 통해 이벤트를 Publish/Subscribe한다.
단일 장애 포인트가 없고, 구축하기 쉬워 서비스가 많지 않은 간단한 워크플로우에 적합하다.
하지만 각 서비스가 이벤트를 구독(Listen)하고 있어야하고, 개별 트랜잭션이 공통된 공유 ID를 정의해야한다는 단점이 있다. 추가적으로 이벤트 추적이나 디버깅이 어렵고, 새로운 스텝이 추가될 경우 복잡도가 높아진다.