개요
여러 동시성 제어 방식에 대해 알아보고, 각 시나리오별 가장 적절한 동시성 제어 방식을 고민해본다. 이를 통해 다양한 동시성 제어 방식을 직접 사용하여 구현해보면서 여러 동시성 제어 방식에 대해 학습한다.
동시성 이슈
동시성 관련 개념
동기화
•
A라는 메모리에 10이 저장되어 있고 프로세스 P1에서 해당 메모리를 읽어 10이라는 값을 들고 있는 상황에서, 프로세스 P2에서 A의 값을 15로 바꾸고 나서 프로세스 P1에서 A에 10의 값을 추가하는 동작을 수행하면 15 + 10 = 25가 아닌 10 + 10 = 20의 값이 저장된다.
•
이처럼 다수의 프로세스나 스레드에서 동일한 공유 자원에 동시에 접근해야하는 경우, 일관된 순서가 보장되지 않으면 데이터 일관성이 깨지게 된다. 이러한 상황을 경쟁 상태(Race Condition)이라 하고, 이를 막기 위해 공유자원에 접근할 때 접근 순서를 보장해주는 과정이 동기화다.

데이터 일관성(데이터 정합성, Data Consistency)
데이터들의 값들이 서로 일치되는 상태를 의미한다. 데이터 일관성 문제는 두 개 이상의 프로세스나 스레드가 데이터를 공유하는 환경에서 서로 교차적으로 데이터를 사용할 때 각 스레드에서 데이터가 달라 데이터 정합성이 지켜지지 않는 상황을 말한다.
경쟁 상태(Race Condition)
•
다수의 프로세스나 스레드들이 같은 공유 자원에 동시에 접근하고 값을 조작하는 상황을 의미한다.
•
경쟁 상태가 발생하면 동시성 이슈가 발생할 수 있다.
임계 구역(Critical Section)
•
경쟁 상태에 놓인 프로세스들의 공유 메모리나 스레드의 메모리 영역을 의미하며, 여러 프로세스나 스레드에 의해 동시 다발적으로 접근될 가능성이 있는 영역을 말한다.
•
공유 자원의 데이터 일관성을 지키기 위해 공유 자원에 접근하는 스레드가 하나만 존재하도록 관리해야하는데, 이 공유 자원을 임계 구역이라 부른다.
발생할 수 있는 동시성 이슈
동시성 이슈는 말 그대로 여러 동작이 동시에 수행되며 발생하는 이슈를 말한다. 여기서의 동작은 비즈니스 로직이 수행되는 트랜잭션을 말하며, 동시는 다른 트랜잭션이 끝나기 전으로 정의할 수 있다. 다시말해, 하나의 트랜잭션이 끝나기 전에 다른 트랜잭션이 수행됨으로 인해 발생하는 문제를 말한다.
여러가지 발생할 수 있는 동시성 이슈에 대해 알아보자.
Lost Update
Lost Update는 이름 그대로 다수의 트랜잭션이 수행됨으로 인해, 일부 트랜잭션의 수행 결과를 다른 트랜잭션이 덮어쓰면서 잃어버리는 것을 의미한다.
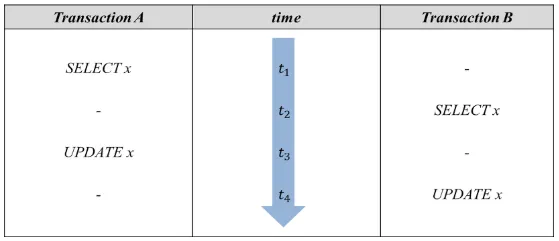
위 그림과 같이 Update를 수행하는 트랜잭션 A와 트랜잭션 B가 동시에 실행된다면, x 레코드에 대한 update가 A에서 수행된 후 B에서 다시 수행되어 덮어쓰이게 된다. 이로 인해 트랜잭션 A가 수행한 결과를 잃어버리게 된다.
MySQL 기준으로 동시성 제어가 없다면, Lost Update가 발생할 수 있는 상황은 트랜잭션 격리레벨 Read Uncommitted, Read Committed, Repeatable Read에서 발생할 수 있다.
트랜잭션 격리수준을 Serializable로 올리거나, 동시성 제어(MVCC)를 수행하여 해당 문제를 해결할 수 있다.
Uncommitted Dependency
Uncommitted Dependency는 dirty read 문제로도 알려져있다. 조회 후 다른 트랜잭션에 의해 수정되거나 롤백 되는 등의 상황으로 인해, 트랜잭션에서 조회했던 값이 일치하지 않게 되는 상황을 말한다.
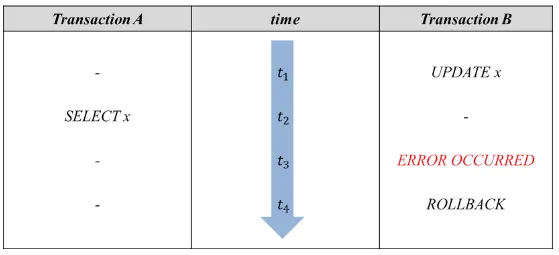
위 그림과 같이 트랜잭션 A에서 조회 이후 트랜잭션 B에서 롤백이 발생해 값이 수정되어, 트랜잭션 A가 읽은 값이 맞지 않게 된다.
MySQL 기준으로, Uncommitted Dependency(Dirty Read)는 Read Uncommitted와 Read Committed에서 발생한다.
해당 문제는 트랜잭션 격리수준을 Repeatable Read 이상으로 올려 간단히 해결할 수 있다.
Inconsistency Analysis
Inconsistency Analysis는 트랜잭션이 실행 중 다른 트랜잭션에서 데이터를 변경하여 원하던 값이 아닌 다른 값이 커밋되어 일관성(정합성)이 깨지는 상황을을 말한다.
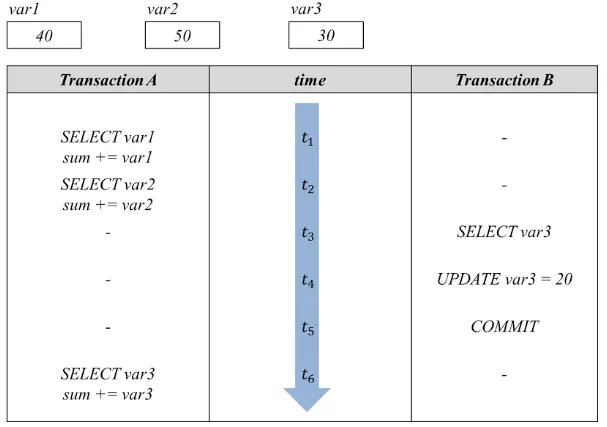
위 그림과 같이 트랜잭션 A 수행 중 트랜잭션 B에서 var3에 값을 변경하여, 트랜잭션 A의 수행 결과가 var1(40) + var2(50) + var3(30)로 원하던 값인 120이 아닌 110이 커밋된다.
MySQL 기준으로, Inconsistency Analysis는 Read Uncommitted와 Read Committed에서 발생한다.
추가적으로 트랜잭션 A에서 var3에 값을 바꾸기 위해 SELECT var3 … FOR UPDATE를 수행하는 경우에는 Repeatable Read에서도 발생할 수 있다.
만약 동일한 상황에서 FOR UPDATE로 조회하지 않는다면, Repeatable Read에서는 Lost Update가 발생하게 된다.
해당 문제는 트랜잭션 격리수준을 Repeatable Read 이상으로 올려 해결하거나, 동시성 제어(MVCC)를 통해 해결할 수 있다.
동시성 제어 방법
동시성 이슈는 공유 자원에 다양한 프로세스(스레드)에서 접근하여 조회하거나 수정을 하는 과정에서 발생한다. 위의 사례를 통해 대표적인 동시성 이슈에 대해 확인했으니, 이러한 동시성 문제를 해결하기 위한 동시성 제어 방법에 대해 알아보자.
낙관적 락
낙관적 락이란?
낙관적 락 방식은 별도의 동시성 제어를 하지 않고 있다가 충돌이 발생하면 그때 동시성 제어를 하는 방식이다. 말 그대로 상황을 충돌이 발생하지 않을 것이라 낙관적으로 보다가, 충돌이 발생하면 이에 대한 별도의 처리를 통해 문제를 해결하는 방법을 말한다.
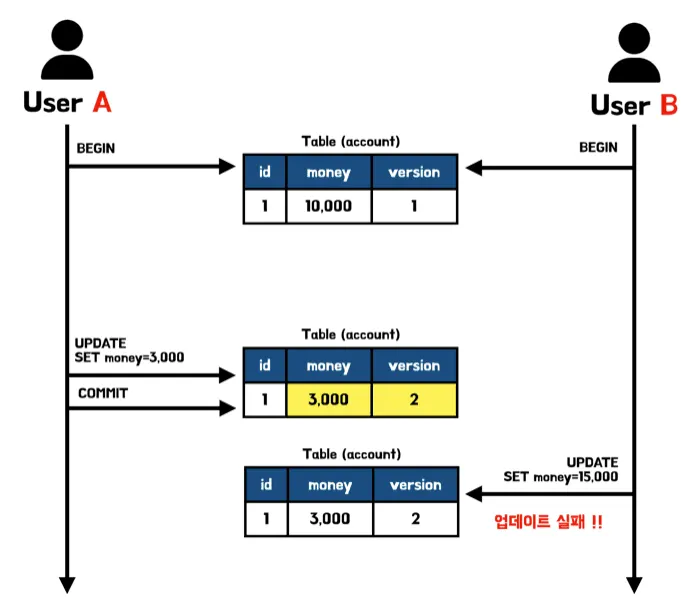
이러한 낙관적 락은 Long, UUID, hashcode, Timestamp 등의 별도의 버전을 나타내는 고유한 값을 가지는 컬럼을 두고, 트랜잭션 시작 시점에 버전을 기억해두었다가 커밋 시점에 버전과 함께 업데이트하면서 저장한다. 이때 트랜잭션 시작 시의 커밋 버전과 다르다면 예외를 발생시키고 해당 트랜잭션을 롤백한다.
낙관적 락 방식 왜 써야하나(장점)
•
별도의 락을 통해서 동시성 제어를 하는게 아닌, 커밋 시점에만 컬럼을 확인해 성공-실패를 결정한다. 때문에 여러 트랜잭션이 동시에 수행되어도 CPU의 스레드 실행 순서에만 영향을 받을 뿐, 트랜잭션 동작 자체는 서로 간의 영향을 전혀 받지 않는다.
•
충돌이 발생했을 때 개발자가 직접 개입하여 어떻게 충돌을 해결할 지 결정할 수 있다.
낙관적 락 방식 왜 쓰지 말아야하나(단점)
•
별도의 버전 컬럼을 두기 때문에 DB에 약간의 데이터의 추가 저장이 발생한다.
•
낙관적 락 방식을 적용하는 로직마다 try-catch와 같은 별도의 예외처리를 해줄 필요가 있다.
•
ORM에 따라 다를 수 있지만, 낙관적 락이 적용된 엔티티는 모든 수정 로직에서 버전 컬럼이 증가되어 낙관적 락이 암시적으로 적용된다.
•
동시에 한 번의 커밋만 인정되기 때문에, 충돌이 많은 상황에서 발생하면 매우 비효율적으로 동작한다. 예를 들면, 100개의 자리가 있는데 1000명의 유저가 동시에 신청하더라도 1명만 성공 후 999명은 다시 시도해야한다.
JPA의 낙관적 락 방식
JPA에서는 엔티티로 등록한 클래스에 @Version 애노테이션을 추가한 별도의 버전 필드를 추가하여 구현할 수 있다. 해당 필드 값은 JPA가 직접 관리하는 값으로, 엔티티가 수정할 때마다 버전이 하나씩 자동으로 증가한다.
벌크 연산을 구현해서 사용하는 경우 해당 수정은 JPA가 관리하지 못하므로, 개발자가 직접 버전을 관리해주어야한다.
충돌 발생 시 ObjectOptimisticLockingFailureException 예외가 발생한다.
JPA에서는 낙관적 락과 관련하여 Lock 애노테이션과 LockModeType 애노테이션을 통해 기능을 제공한다. 그 중 LockModeType에는 낙관적 락과 관련해 다음과 같은 기능을 제공한다.
•
NONE
◦
조회한 엔티티를 수정하는 시점에 다른 트랜잭션으로부터 변경되지 않았음을 보장한다.
◦
엔티티에 버전 필드가 존재하는데 락 모드가 정의되지 않았다면 적용되는 옵션이다.
•
OPTIMISTIC
◦
NONE의 경우 엔티티를 수정할 때만 버전을 체크하지만, OPTIMISTIC 옵션은 엔티티를 조회만 해도 버전을 체크하고 트랜잭션이 종료될 때까지 다른 트랜잭션에 변경되지 않았음을 감지한다.
◦
READ 타입과 동일
•
OPTIMISTIC_FORCE_INCREMENT
◦
낙관적 락을 사용하며 버전을 강제로 증가 시킨다. 엔티티가 물리적으로 변경되지 않더라도, 논리적으로 변경되었을 때 증가 시킬 수 있다.(논리적 단위로 엔티티 관리)
◦
1:N 관계에서 1에는 변화가 없고 N에 데이터가 추가되거나 제거되면, 1에 물리적 변화는 없지만 논리적 변화가 발생하기 때문에 버전 정보를 증가시킨다.
◦
WRITE 타입과 동일
비관적 락
비관적 락 방식
비관적 락 방식은 트랜잭션이 시작될 때 데이터에 락을 걸어, 해당 트랜잭션이 끝나기 전까지 다른 트랜잭션이 해당 데이터에 접근하지 못하게 해 동시성 제어를 하는 방식이다. 말 그대로 비관적으로 충돌이 발생한다고 가정하고, 충돌을 방지하도록 동시성 제어를 하는 방법을 말한다.
비관적 락 방식 왜 써야하나(장점)
•
아무리 많은 요청이 동시에 들어와도 한 번에 하나의 요청을 처리함을 보장할 수 있다.
•
공유 락(Shared Lock)과 배타 락(Exclusive Lock)을 통해 비즈니스 상황에 맞춰 동시성 제어를 할 수 있다.
비관적 락 방식 왜 쓰지 말아야하나(단점)
•
락을 잘못 사용하면 교착상태(DeadLock)가 발생할 수 있다.
•
동시에 하나의 트랜잭션만 수행될 수 있기 때문에 처리 속도가 느리다.
•
락을 획득하지 못한 트랜잭션들은 트랜잭션을 열고 락을 획득할 때까지 대기해, 트랜잭션에 대한 리소스가 낭비될 수 있다.
•
락 반환이 늦어진다면, 그로 인한 병목이 발생할 수 있다.
JPA의 비관적 락 방식
비관적 락은 낙관적 락과는 다르게 별도의 컬럼이 필요없기 때문에, 조회 시 @Lock 애노테이션과 @LockModeType 애노테이션을 통해 락을 부여하여 조회하면 된다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
fun findByNameOrNull(name: String): User?
Kotlin
복사
LockModeType에는 비관적 락과 관련해 다음과 같은 기능을 제공한다.
•
PESSIMISTIC_READ
◦
SELECT … FOR SHARE 를 통해 공유 락(Shared Lock, S-Lock)을 건다.
◦
일반적으로 잘 사용하지 않는다.
•
PESSIMISTIC_WRITE
◦
SELECT … FOR UPDATE 를 통해 배타 락(Exclusive Lock, X-Lock)을 건다.
◦
비관적 락을 적용 시 일반적으로 사용되는 옵션으로, Non-Repeatable Read 문제를 방지할 수 있다.
•
PESSIMISTIC_FORCE_INCREMENT
◦
비관적 락에 버전 정보를 사용하여, 버전 정보를 강제로 증가시킨다.
분산 락
분산 락이란?
분산 락이란 여러 서버(인스턴스)에서의 공유 데이터에 대한 접근을 제어하기 위한 기술로, 특정 공유 자원에 접근할 수 있는 권한을 락을 획득한 서버 혹은 프로세스(스레드)만 가지고 있어 서버가 다름에도 데이터의 원자성을 보장하는 방식이다.
서버는 스케일 아웃이 가능하지만, DB는 스케일 아웃이 불가능하고 Master/Slave의 Replica 혹은 파티셔닝/샤딩으로만 사용할 수 있다. 여기서 각 스케일 아웃된 다수의 서버는 각각 DB 커넥션을 보유하고 있는데, DB 입장에서는 다수의 서버에서 요청을 받아야한다. 때문에 각 서버는 커넥션 풀을 소중히 여겨야하고, 이러한 개념에서 분산 락이 권장된다.
왜 분산 락을 써야하는가(장점)
•
동시성 제어 포인트의 트랜잭션이 반드시 한 개만 열리는 것이 보장되어 DB 부담을 줄일 수 있다.
•
데드락을 방지하면서, 락의 획득과 해제를 통해 데이터의 원자성을 보장할 수 있다.
•
분산 환경에서 예측 가능한 동작을 보장하고, 시스템의 일관성을 유지할 수 있게 도와준다.
왜 분산락을 쓰지 말아야하는가(단점)
•
락 반환이 늦어진다면, 그로 인한 병목이 발생할 수 있다.(Timeout 설정을 반드시 해야한다)
•
분산 락을 구현하기 위한 추가적인 인프라가 필요하고, 그로 인해 디버깅과 문제 해결의 어려움이 발생할 수 있다.
분산락의 종류
•
Redis
◦
인메모리 기반이라 속도가 굉장히 빠르고, Key-Value 형태로 데이터를 저장하는 데이터베이스이다.
◦
SETNX 명령어를 통해 해당 key가 존재하지 않으면 생성 및 락을 획득, 존재한다면 대기하도록 해 분산 락을 구현한다.
•
Zookeeper
◦
분산 서버 관리시스템으로 분산 서비스 내 설정을 공유해주는 시스템이다.
◦
Ephemeral Node 생성을 통해 락을 획득하고 세션 종료로 락 해제를 구현할 수 있다.
•
데이터베이스를 이용한 구현
◦
데이터베이스에 별도의 락 테이블을 두고, SELECT … FOR UPDATE 쿼리를 활용해 분산 락을 구현할 수 있다.
Redis의 분산 락
Redis에는 SETNX(Set if Not Exist)라는 명령어를 통해 키가 없으면 생성하고 있다면 실패하는 원자적 연산을 제공한다. 이를 통해 분산 락을 구현하거나 구현된 분산 락 라이브러리를 제공한다.
자바 진영에서 사용할 수 있는 레디스 클라이언트는 Jedis, Lettuce, Redisson 세 가지가 있다.
•
Jedis
◦
Lettuce에 뒤쳐졌기 때문에 생략
•
Lettuce
◦
SETNX, SETEX를 통해 직접 분산락을 구현해야한다.(retry, timeout 설정)
◦
일반적으로 구현의 귀찮음으로 인해 스핀락 방식으로 구현하게 되는데 성능상 좋지 않다.
•
Redisson
◦
별도의 Lock 인터페이스를 제공하며, 락에 대한 여러 설정을 지원해 쉽고 안전하게 사용할 수 있다.
◦
Pub/Sub 방식을 이용하여 구현되어 있기 때문에 부하가 적다.
왜 레디스의 분산락을 써야하는가(장점)
•
Redis는 인메모리 기반의 데이터베이스로 처리 속도가 빠르다.
•
만료 시간(TTL)을 설정하여 락 해제를 보장할 수 있다.
왜 레디스의 분산락을 쓰지말아야하는가(단점)
•
디스크에 비해 용량이 작은 메모리를 사용하기 때문에, 너무 많은 락을 요청하게 되면 Out-Of-Memory가 발생할 수 있다.
•
인메모리 기반이기 때문에 Redis 서버가 다운되는 경우, Snap-shotting이나 AOF 같은 별도의 백업이 없다면 정보를 모두 잃어버릴 수 있다.
분산 락 적용 시 주의사항
분산 락의 존재 목적은 DB의 커넥션 풀 연결을 최소화하고 트랜잭션을 가능한 짧게 열어두기 위함이다. 때문에 분산 락을 적용할 때, 반드시 분산 락을 획득 이후 트랜잭션을 열어야한다. 분산 락을 획득 전에 트랜잭션을 열면, 분산 락을 사용하는 이유가 없어지는 것과 동일하다. 반대로 트랜잭션 커밋 전에 락을 해제하면, 그 사이에 다른 트랜잭션에서 데이터를 읽어갈 가능성이 생기게 된다.
메세지 큐 순서제어
메세지 큐를 통한 순서 제어 방식
메세지 큐를 통해 동시성을 제어하는 방식은, 메시지 큐가 FIFO(First-In Frist-Out)로 동작하기 때문에 싱글 컨슈머 패턴을 통해 하나의 소비자가 모든 메세지(이벤트)를 순차적으로 소비하여 순서와 동시성을 같이 제어하는 방식이다.
왜 메세지 큐 방식을 써야하는가(장점)
•
메세지 큐를 사용하기 때문에 순서를 정확하게 보장할 수 있다.
•
메세지 큐를 통해 시스템 간의 결합도를 낮추는 것이 가능하다.
•
실패 시에도 소비되지 않은 메세지가 브로커에 남기 때문에, 장애에 대응해 복원이 용이하다.
•
브로커에 Topic만 추가하면 되기 때문에, 확장성이 용이하다.
왜 메세지 큐 방식을 쓰지 말아야하는가(단점)
•
순서 보장을 위해 발행된 이벤트를 소비하는 포인트를 한 곳만 열어두면, 동시에 매우 많은 요청이 몰리는 경우 발행되는 이벤트를 모두 소비하는데 많은 시간이 소요된다.(병목지점이 될 수 있다)
•
추가적인 인프라를 구성해야하고, Topic에 대한 관리나 Dead Letter Queue에 대한 설계를 고려할 필요가 있다.
주관적으로 요약한 각 제어 방식의 적절한 사용처
•
낙관적 락
◦
충돌이 거의 발생하지 않지만, 정합성을 지킬 필요가 있거나 Lost Update를 방지해야하는 경우
•
비관적 락
◦
정합성이 중요하고 동시성 문제가 어느정도 발생될 것으로 예상되는 경우
•
분산 락
◦
정합성이 중요하며 동시성 문제가 매우 자주 발생될 것으로 예상되는 경우
•
메세지 큐 순서제어
◦
선착순과 같이 순서의 보장이 필요한 경우
동시성 제어
콘서트 예약 시스템에서 동시성을 제어해야하는 비즈니스 로직은 다음과 같다.
•
포인트 사용, 충전
◦
금전과 관련된 문제로 정합성이 중요
•
좌석 예약
◦
많은 요청이 몰려 동시성 이슈가 자주 발생할 것으로 예상
•
결제
◦
금전과 관련된 문제로 정합성이 중요
위에서 각 동시성 제어 장단점을 학습한 내용을 기반으로, 상기 시나리오마다 적합한 동시성 제어 방식을 살펴보고 그 장단점과 성능, 효율, 구현 복잡도를 순위를 비교해보자.
포인트 사용 및 충전 시나리오
동시성 제어 포인트
•
금전적인 로직에 있어서는 데이터 정합성이 굉장히 중요하므로 동시성 제어가 필요하다.
•
포인트에 대한 사용과 충전은 특정 유저의 포인트에 대한 처리하는 시나리오이기 때문에, 다수의 유저에 의해 동시성 충돌이 발생할 가능성이 매우 낮다.
•
하지만 흔히 “따닥” 이라고 불리는 마우스 클릭에 따라 연달아 요청이 들어오는 경우도 있기 때문에, Lost Update를 피하기 위해 동시성 제어가 필요하다.
동시성 제어 방식 분석
장점 | 단점 | 성능/효율 | 구현 난이도 | |
낙관락 | 동시성 제어로 인한 성능 저하 거의 없음 | 동시에 요청이 몰려도 1개만 성공
충돌 시 에러 핸들링 필요
(위 두 가지는 해당 시나리오에서 장점이 될 수도) | 2 | 3 |
비관락 | 정합성이 거의 깨지지 않음 | DB 락에 의한 성능 저하
외래키 잘못쓰면 교착상태 발생(MySQL) | 3 | 2 |
분산락 | DB 부담 저하
트랜잭션 커넥션 수 제어
(해당 시나리오에서 메리트 없음) | 높은 구현 복잡도(인프라 추가 필요) | 4 | 4 |
메세지 큐 | DB 부담 저하
트랜잭션 커넥션 수 제어
(해당 시나리오에서 메리트 없음) | 높은 구현 복잡도(인프라 추가 필요)
순서 보장이 불필요한 시나리오 | 5 | 5 |
DB 제약조건 | 성능 저하 없음 | 구현 불가
(포인트 생성, 유저 잔액 변경 로직에 제약 조건 지정 불가) | 1 | 1 |
위 상황을 종합해 보았을 때, 충돌 가능성이 낮지만 데이터 정합성이 중요하므로 효율성과 성능을 올리기 위해 낙관적 락 방식이 적합해보인다. 부가적으로 충돌이 발생하는 경우, 두 번째 요청은 잘못 들어온 요청으로 판단해 그대로 예외를 발생시켜 처리하지 않도록 구현 해볼 수 있다.
좌석 예약 시나리오
구현 과정에서 트랜잭션을 짧게 가져가기 위해 각 기능별로 서비스를 구현하고 Facade가 아닌 각 기능별로 트랜잭션을 묶었다. 좌석 예약 시나리오는 좌석 선점 → 예약 생성의 두 가지 서비스 로직으로 구성되어 있다. 트랜잭션이 분리되어 있기 때문에, 각각 동시성 제어가 필요하다고 판단했다.
1.
좌석 선점
동시성 제어 포인트
•
좌석 예약의 경우 다수의 유저에 의한 요청이 동시에 발생할 가능성이 매우 높다.
•
여러 유저가 하나의 좌석을 동시에 예약하는 상황이 발생하면 안되기 때문에, 좌석 점유에 대한 동시성 제어가 중요하다.
동시성 제어 방식 분석
장점 | 단점 | 성능/효율 | 구현 난이도 | |
낙관락 | 동시성 제어로 인한 성능 저하 거의 없음 | 동시에 요청이 몰려도 1개만 성공
(해당 시나리오에서는 치명적인 단점이 된다) | 4 | 3 |
비관락 | 정합성이 거의 깨지지 않음 | DB 락에 의한 성능 저하
외래키 잘못쓰면 교착상태 발생(MySQL) | 3 | 2 |
분산락 | DB 부담 저하
트랜잭션 커넥션 수 제어 | 높은 구현 복잡도(인프라 추가 필요) | 2 | 4 |
메세지 큐 | DB 부담 저하
트랜잭션 커넥션 수 제어 | 높은 구현 복잡도(인프라 추가 필요)
순서 보장이 불필요한 시나리오
해당 시나리오는 요청이 매우 많이 몰리기 때문에, 싱글 컨슈머패턴으로 인해 병목 지점이 될 수 있다. | 5 | 5 |
DB 제약조건 | 성능 저하 없음 | 구현 불가
(이미 생성되어 있는 좌석에 만료 시간을 통해 선점을 구현하기 때문에 제약 조건으로 구현 불가) | 1 | 1 |
이러한 이유로, 비관적 락과 분산 락이 괜찮아 보인다. 요청이 너무 많지 않다면 비관적 락이 성능상으로 더 유리하겠지만, 요청이 매우 많아진다면 분산 락의 효율이 좋다.
학습을 위해 분산 락을 통해 트랜잭션이 열리는 개수를 제한하여 DB 부담을 낮추면서도 여러 동시성 충돌에 대해 정합성을 보장하는 방식으로 구현해보자. 분산 락 적용을 위해 Redis를 추가적으로 적용하고, AOP를 통해 분산락 적용 관심사를 분리해야하기 때문에 구현 복잡도는 조금 높을 수 있다.
2.
예약 생성
동시성 제어 포인트
•
예약 생성의 경우 비즈니스 로직상 좌석 선점 이후 수행되기 때문에, 좌석 선점의 동시성 제어가 충분하다면 예약 생성 시 동시성 충돌이 사실상 발생할 일이 거의 없다.
예약 생성의 경우,
1.
예약 만료 시간 컬럼이 존재하기 때문에 동일한 좌석에 대해 여러 예약이 저장될 수 있어, DB의 제약 조건을 통한 제어를 수행할 수 없다.
2.
Insert 쿼리를 수행하기 때문에, 특수한 방법을 제외하면 비관적 락도 사용할 수 없다.
3.
마찬가지로 엔티티의 버전 컬럼을 사용하는 낙관적 락 방식도 제대로 동시성 제어를 수행할 수 없다.
위의 사유로 인해 분산 락 제어 방식을 적용하였다.
결제 시나리오
구현한 결제 로직도 마찬가지로 서비스 별로 기능이 분리되어, 포인트 차감, 결제, 예약 만료 해제, 좌석 만료 해제, 토큰 비활성화 순의 5개의 기능 로직에 대해 각각 트랜잭션이 적용되어 있다.
1.
포인트 차감
위의 포인트 충전 & 사용 시나리오에서 적용된 낙관적 락을 통해 제어된다.
2.
결제
결제도 위와 동일하게 Insert 쿼리를 수행하기 때문에, 비관적 락과 낙관적 락을 통한 동시성 제어가 불가능하다.
하지만 중복 컬럼이 없기 때문에, 예약 1개당 결제 1번의 Unique 제약 조건을 통해 제어하는 것이 가능하다.
3.
나머지 로직
•
Reservation 만료 시간 해제, ConcertSeat 예약 만료 시간 해제
◦
만료 시간을 null로 바꾸는 멱등성 보장되는 로직으로, 반복적으로 수행되도 문제가 없기 때문에 동시성 제어 X
•
토큰 비활성화
◦
토큰의 상태를 DEACTIVATED로 바꾸는 멱등성 보장되는 로직으로, 중복하여 비활성화하여도 문제가 없기 때문에 동시성 제어 X
구현 및 테스트
포인트 충전 및 사용(낙관적 락)
구현 과정
1.
User 내 버전 컬럼 추가
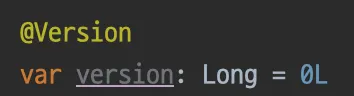
2.
트랜잭션 내에서 수정 발생 시 낙관적 락 적용
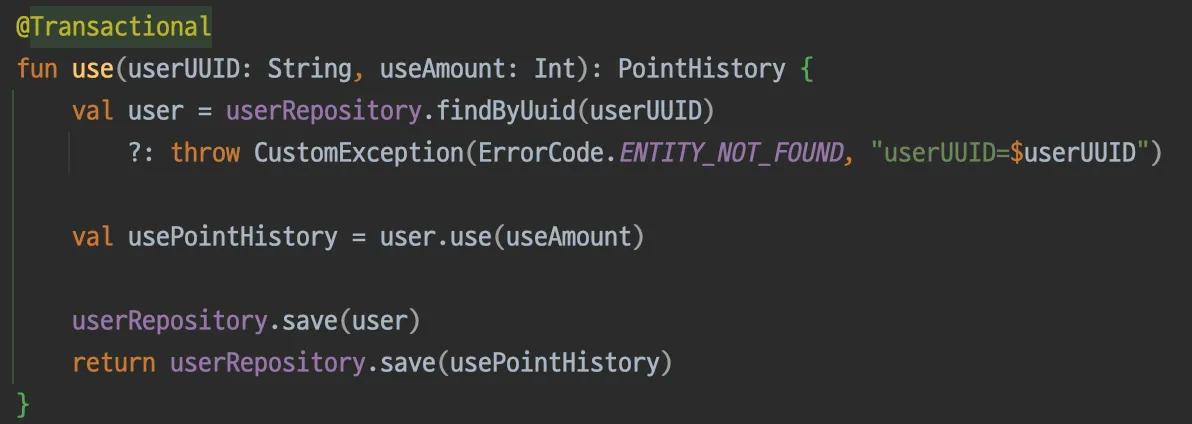
테스트
•
동일한 유저가 3번의 포인트 사용을 동시에 시도 시(when)
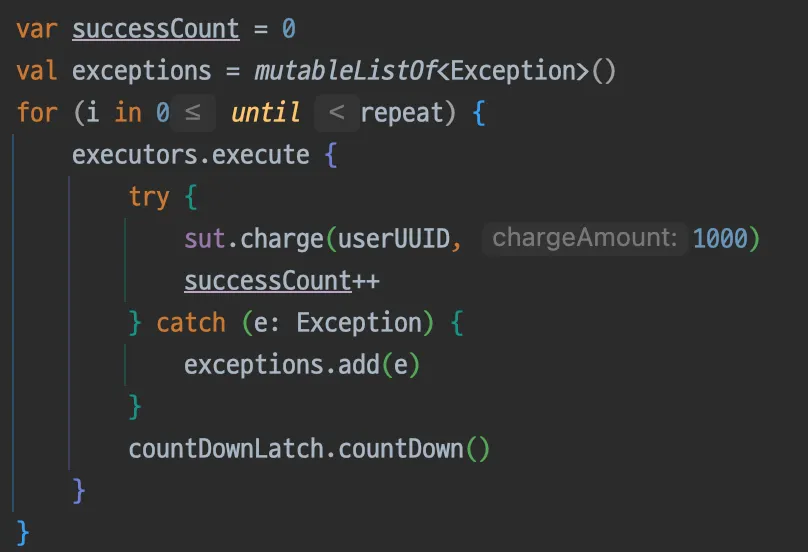
•
1번의 요청만 성공, 2번은 OptimisticLockingFailureException 발생(then)
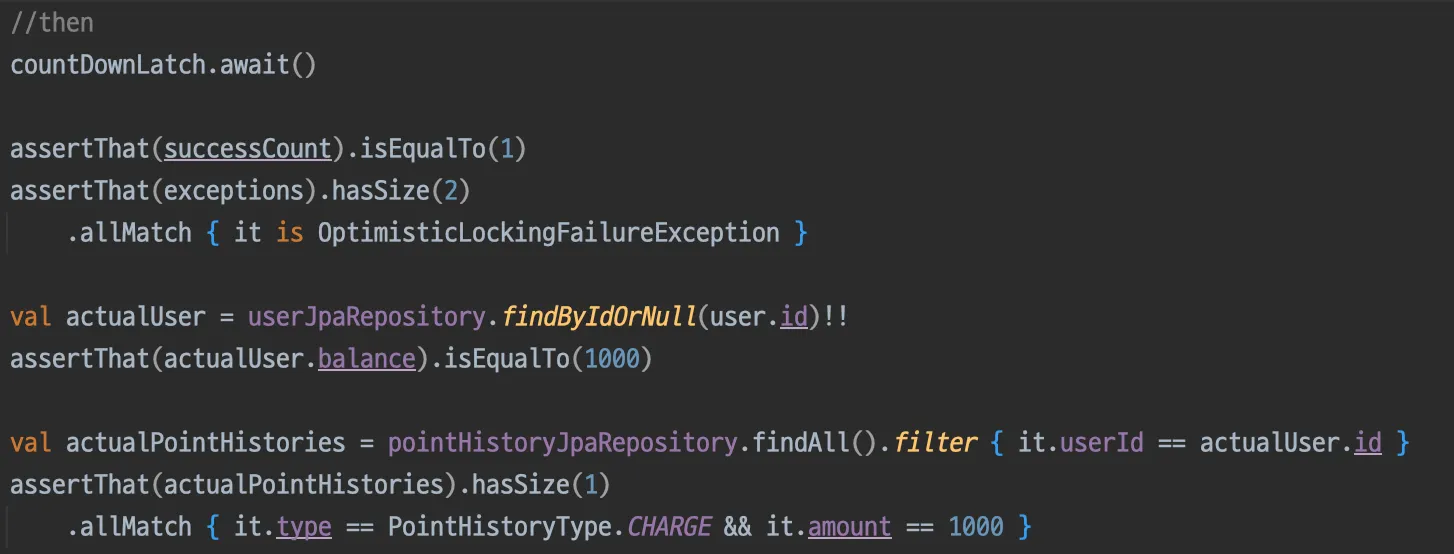
•
테스트 수행 결과(낙관적 락 적용 시)

•
테스트 수행 결과(낙관적 락 미적용 시)

좌석 선점 / 예약 생성(분산 락)
구현 과정
마켓 컬리의 테크 블로그 글을 많이 참고했습니다.1.
Redis 환경 구축(docker-compse.yml에 Redis 컨테이너 설정 추가, Redisson 라이브러리 의존성 추가)
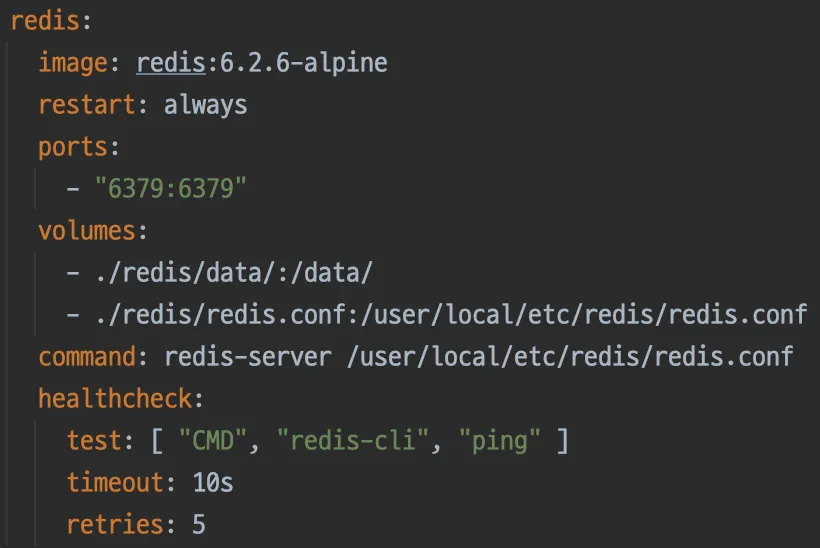
docker-compose.yml

build.gradle.kts
2.
AOP를 적용할 joinpoint 애노테이션 생성

3.
분산 락을 적용할 AOP Aspect 생성
@Aspect
@Order(0)
@Component
class DistributedLockAspect(
private val redissonClient: RedissonClient
) {
private val log = LoggerFactory.getLogger(javaClass)
@Around("@annotation(DistributedLock)")
fun lockByRedisson(joinPoint: JoinPoint): Any {
val signature = joinPoint.signature as MethodSignature
val distributedLock = signature.method.getAnnotation(DistributedLock::class.java)
val lockKey = distributedLock.prefix + parseExpressionLanguage(signature.parameterNames, joinPoint.args, distributedLock.key)
val lock = redissonClient.getLock(lockKey)
try {
val available = lock.tryLock(distributedLock.starvationTime, distributedLock.lockTimeToLive, TimeUnit.MILLISECONDS)
require(available) { return false }
return (joinPoint as ProceedingJoinPoint).proceed()
} catch (e: InterruptedException) {
throw e
} finally {
runCatching { lock.unlock() }
.onFailure { log.warn("Redis distributed lock is already unlocked : key={}", lockKey) }
.getOrNull()
}
}
fun parseExpressionLanguage(parameterNames: Array<String>, args: Array<Any>, keyEL: String): Any? {
val parser = SpelExpressionParser()
val context = StandardEvaluationContext()
parameterNames.forEachIndexed { index, param -> context.setVariable(param, args[index]) }
return parser.parseExpression(keyEL).getValue(context, Any::class)
}
}
Kotlin
복사
4.
애노테이션을 통한 분산락 적용

테스트
•
동일한 좌석에 대해 동시에 5번의 선점 요청 시(when)
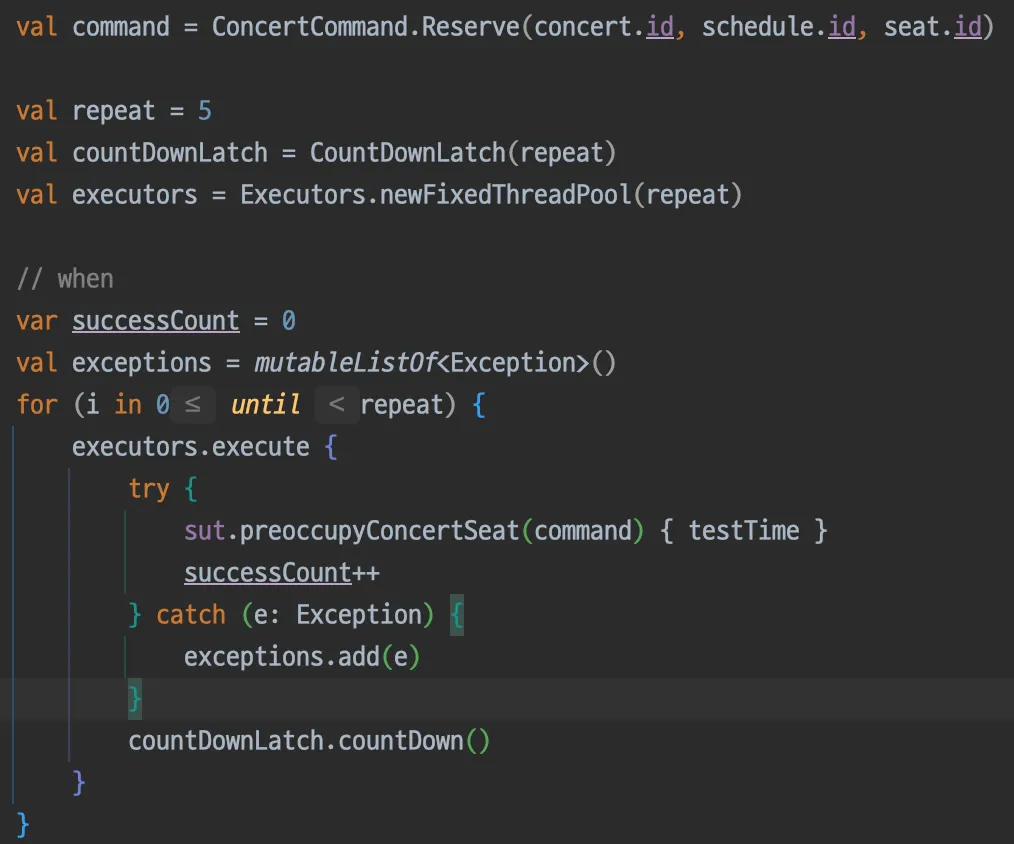
•
1개의 요청만 선점에 성공, 4번의 요청은 예약 실패 Exception 발생(then)
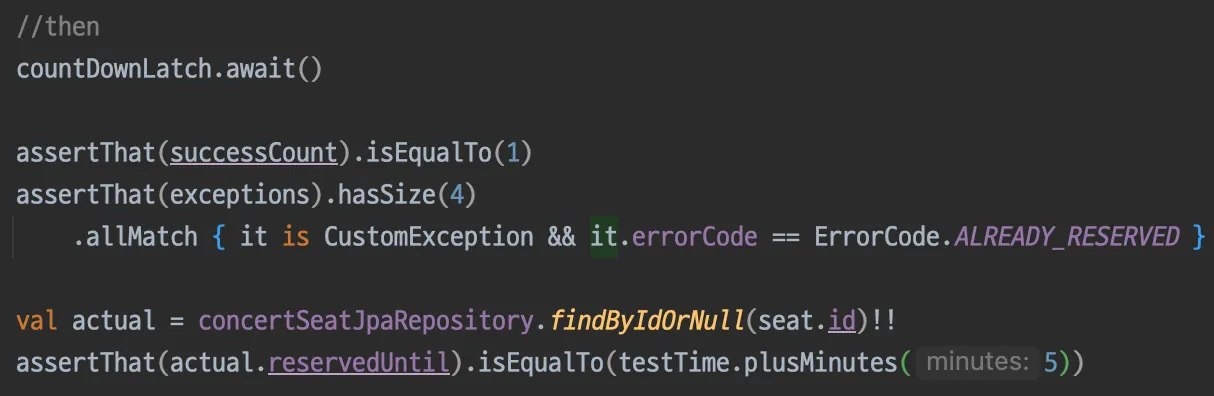
•
테스트 수행 결과(분산 락 적용 시)

•
테스트 수행 결과(분산 락 미적용 시)

결제 생성(DB 제약조건 제어)
구현 과정
1.
DB 제약 조건 추가
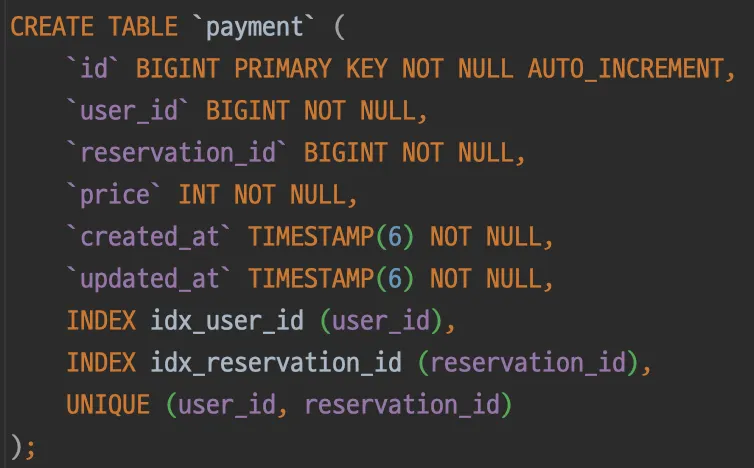
테스트
•
3번의 결제 생성 요청이 동시에 들어오면(when)
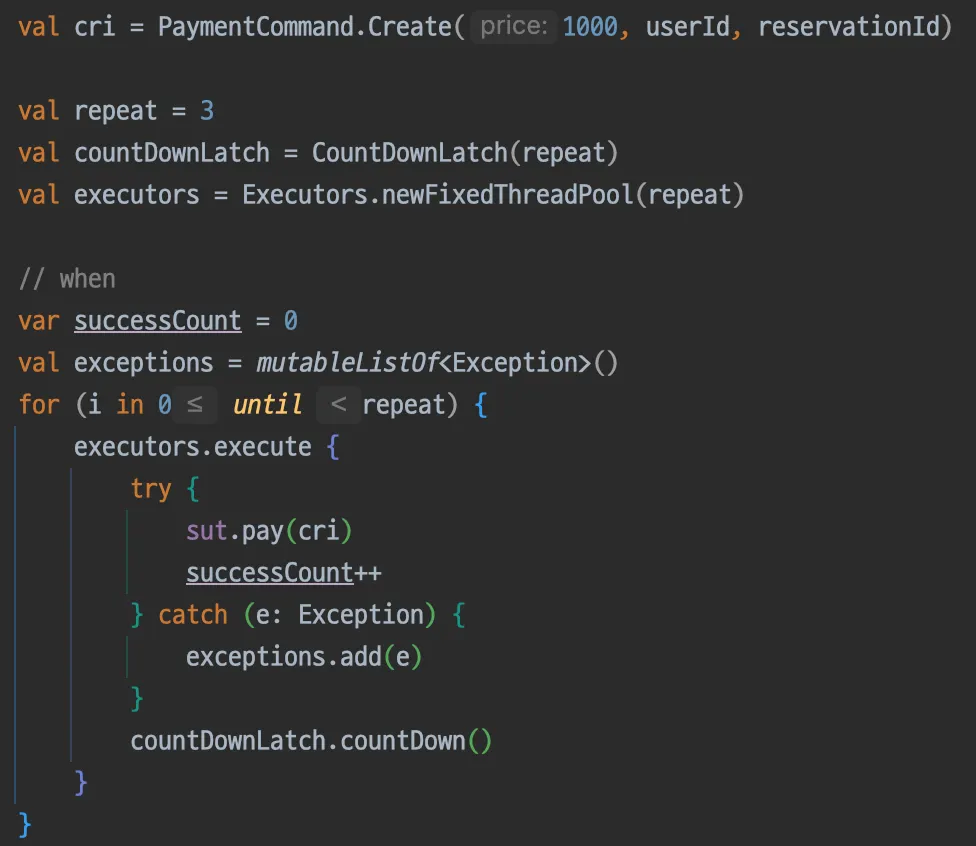
•
1개의 결제만 생성, 2번의 요청은 DataIntegrityViolationException 발생(then)
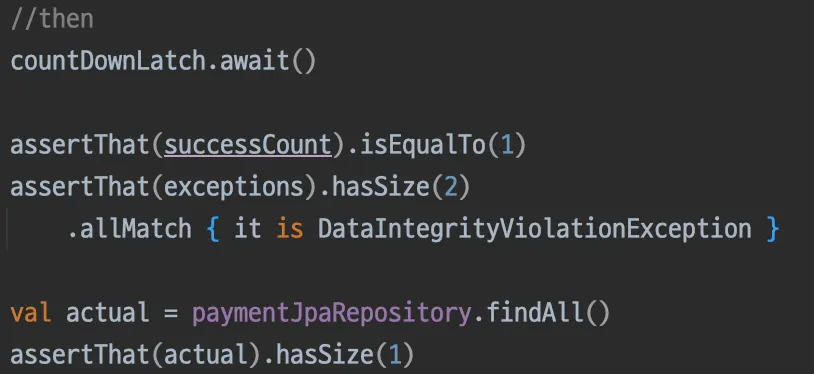
•
테스트 수행 결과(Unique 제약조건 설정 시)

•
테스트 수행 결과(Unique 제약조건 해제 시)


