Step의 두 가지 유형
Chunk와 Tasklet
섹션 1에서 Job과 Step에 대해 배우면서, 배치 처리의 일반적인 패턴이 읽고-처리하고-쓰는것이라고 학습했다. 하지만 모든 배치가 이런 식으로 데이터를 다루지는 않는데, 청크 지향 처리 방식과 태스크릿 지향 처리 방식으로 나눌 수 있다.
태스크릿 지향 처리
태스크릿 지향 처리 모델은 스프링 배치의 가장 기본적인 Step 구현 방식으로, 비교적 복잡하지 않은 단순한 작업을 실행할 때 사용된다.
언제 태스크릿 지향 처리를 사용하는가
일반적인 배치의 Step은 읽고-처리하고-쓰는 ETL 작업에 초점을 맞춘다. 하지만 다음과 같은 단순한 시스템 작업이나 유틸성 작업이 필요할 때가 있다.
•
매일 새벽 불필요한 로그 파일 삭제
•
특정 디렉토리에서 오래된 파일을 아카이브
•
사용자에게 단순한 알림 메세지 또는 이메일 발송
•
외부 API 호출 후 결과를 단순히 저장하거나 로깅
태스크릿 지향 처리는 이러한 단일 비지니스 로직 실행을 목적으로 설계된 처리방식이다.
태스크릿 지향 처리 구현 방식
태스크릿 지향 처리가 사용되는 사례들은 대부분 함수 호출 하나로 끝날 법한 단순한 작업들이다.
@FunctionalInterface
public interface Tasklet {
@Nullable
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}
Java
복사
우리는 스프링 배치가 제공하는 Tasklet 인터페이스의 execute() 메서드에 우리가 원하는 로직을 구현하고, 이 구현체를 넘기면 알아서 스프링 배치가 그 이후의 실행과 흐름 관리를 수행한다.
Tasklet 구현 예시
class HelloTasklet: Tasklet {
private val log = org.slf4j.LoggerFactory.getLogger(this::class.java)
private final val totalCount = 10
private var count = 0
override fun execute(
contribution: StepContribution,
chunkContext: ChunkContext
): RepeatStatus {
count++
if (count < totalCount) {
// 더 처리해야할 프로세스가 남아있음
return RepeatStatus.CONTINUABLE
}
log.info("HelloTasklet has finished.")
return RepeatStatus.FINISHED
}
}
Java
복사
RepeatStatus
public enum RepeatStatus {
CONTINUABLE(true),
FINISHED(false);
...
}
Java
복사
스프링 배치에서 Step이 Tasklet의 execute 메서드 실행을 계속 해야할지 멈출지를 결정하는 기준이 RepeatStatus이다.
•
RepeatStatus.FINISHED : 성공/실패 같은 Step의 처리 결과와 관계없이, 스프링 배치에 해당 Step이 완료되었고 더 이상 반복할 필요 없이 다음 Step으로 넘어가도 된다고 알려주는 상태이다. Job에 따라 다음 Step으로 차근차근 진행된다.
•
RepeatStatus.CONFINUABLE : 스프링 배치에 Tasklet의 execute 메서드가 추가로 더 실행되어야 함을 알려주는 상태이다. Step의 종료를 보류하고 필요한만큼 execute 메서드를 반복 호출하게 된다.
while 문법을 통해 반복 작업을 처리하면 되지 않을까? 싶은 사람도 있을 것이다. 하지만 RepeatStatus가 필요한 이유는, 짧은 트랜잭션으로 안전하게 처리하기 위해 배치 처리에 반복문 이상의 제어 구조가 필요하기 때문이다. 스프링 배치에서는 Tasklet의 execute 호출마다 새로운 트랜잭션을 시작하고, execute 메서드가 종료되어 RepeatStatus가 반환되면 해당 트랜잭션을 커밋한다. 이를 execute 내부의 반복문으로 직접 구현한다면, 모든 반복 작업이 하나의 트랜잭션으로 처리되고 실행 도중 예외가 발생하면 반복문으로 했던 모든 결과가 롤백될 것이다.
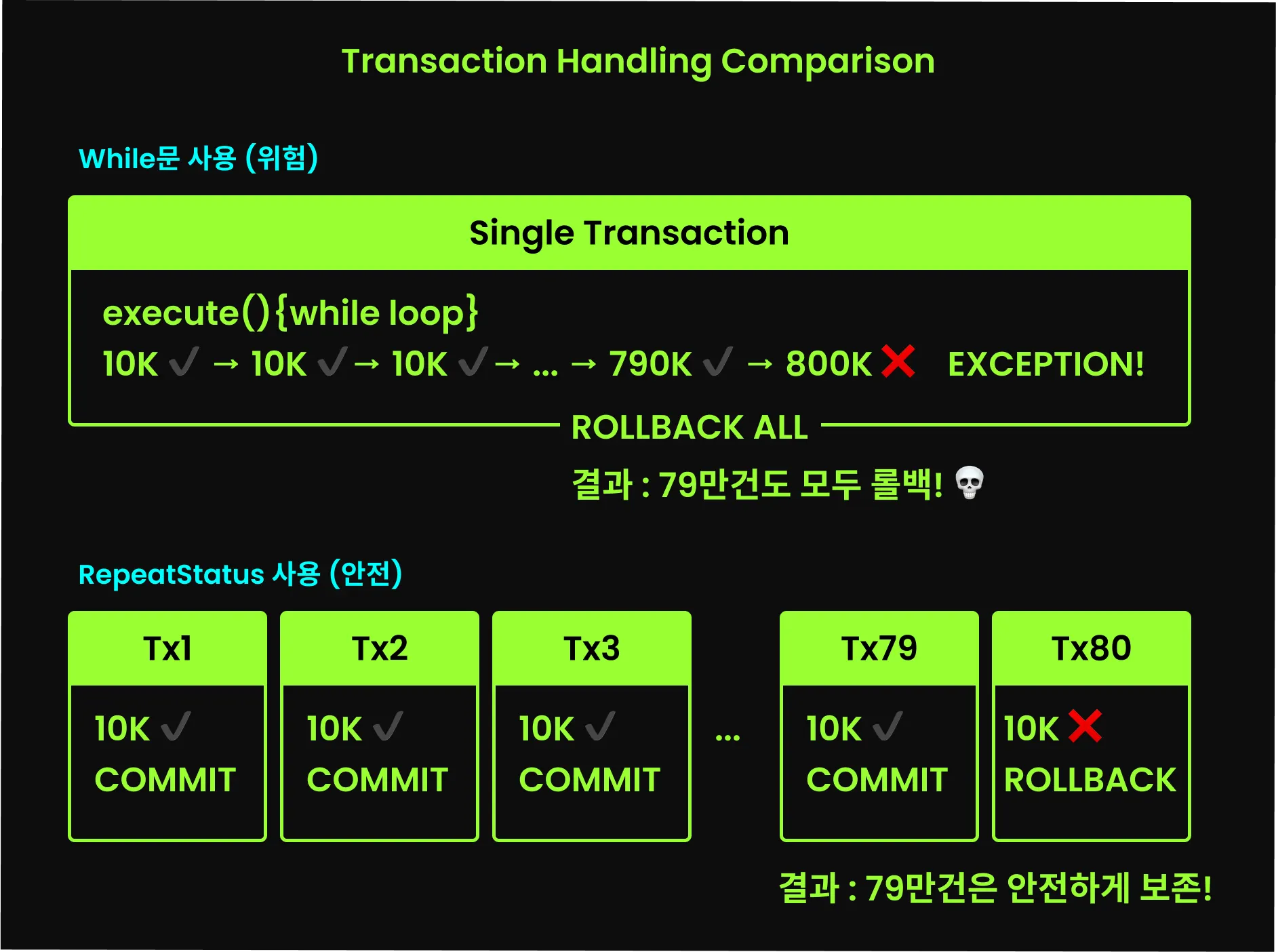
이처럼 RepeatStatus가 필요한 이유는 execute를 반복 실행하기 위해서이고, 반복해서 실행하는 이유는 하나의 거대한 트랜잭션 대신 작은 트랜잭션들로 나누어 안전하게 처리하기 위함이다.
Tasklet을 Step에 등록하기
Tasklet에 로직을 잘 처리하도록 만들었다면, 이제 Step에 등록해보자.
@Bean
fun helloTasklet() = HelloTasklet()
@Bean
fun secondStep(): Step {
return StepBuilder("secondStep", jobRepository)
// HelloTasklet 추가
.tasklet(HelloTasklet(), transactionManager)
.build()
}
Kotlin
복사
Step을 구성할 때는 어떤 처리 방식을 사용할 지를 결정해야하는데, 위의 예시처럼 StepBuilder를 통해 tasklet() 메서드를 호출하면 태스크릿 지향 처리 방식의 Step을 생성한다.
TransactionManager
tasklet 메서드에는 태스크릿 구현체 외에도 PlatformTransactionManager 인스턴스도 같이 전달되는데, 트랜잭션 매니저를 같이 전달함에 따라 execute 메서드 실행 중 발생하는 모든 데이터베이스 작업을 하나의 트랜잭션으로 관리할 수 있게 된다.
@Configuration
class HelloBatchConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
)
Kotlin
복사
위의 예시에서는 Spring boot가 자동으로 구성한 TransactionManager 빈을 주입받아서 사용했다. 하지만 파일을 정리하거나, 외부 API를 호출하거나, 단순한 알림을 보내는 등 모든 Tasklet에서 데이터베이스 작업을 처리하지는 않는다.
이런 경우처럼 DB 트랜잭션을 고려할 필요가 없다면, ResourcelessTransactionManager 구현체를 사용할 수 있다. 이 구현체는 아무것도 하지 않는(no-op) 방식으로 동작하기 때문에, 불필요한 DB 트랜잭션 처리를 생략할 수 있다.
@Bean
fun lastStep(): Step {
return StepBuilder("lastStep", jobRepository)
.tasklet({ contribution, chunkContext ->
println("This is my last step")
RepeatStatus.FINISHED
}, ResourcelessTransactionManager())
.build()
}
Kotlin
복사
PlatformTransactionManager 빈 등록 주의
위의 예시는 ResourcelessTransactionManager 인스턴스를 새로 생성해서 전달하는데, 여러 스텝에서 재사용할 수 있도록 별도의 Bean으로 등록하고 싶을 수 있다. ResourcelessTransactionManager 구현체는 상관이 없지만 PlatformTransactionManager를 빈으로 등록할 때는 주의가 필요하다.
스프링 배치에서는 내부적으로 Job과 Step의 상태 등의 메타데이터를 DB를 통해 관리한다. 이 때에도 트랜잭션이 사용되는데, 별도의 설정 없이 PlatformTransactionManager를 빈으로 정의한다면 메타데이터 관리 트랜잭션과 Step의 비즈니스 로직 처리 트랜잭션이 같은 빈을 사용하여 의도치 않은 문제가 생길 수 있다.
Tasklet 사용 시나리오
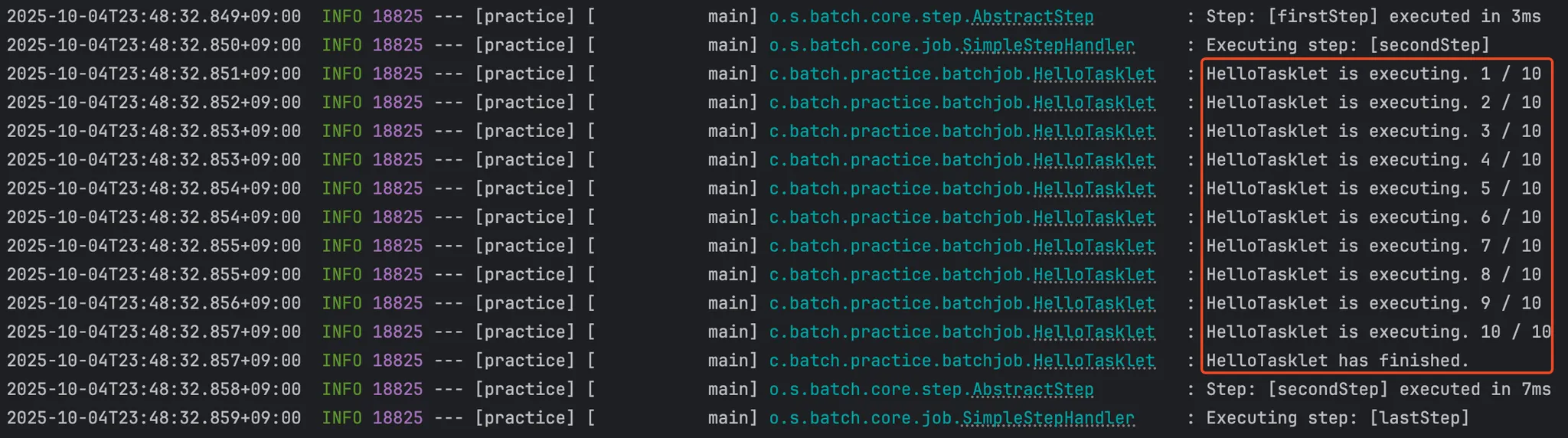
우리가 만든 태스크릿을 실행시키면 이처럼 잘 실행되는 것을 확인할 수 있다.
이제 실제 사례들을 통해 Tasklet이 어떤 작업에 적합한지, 언제 활용해야 하는지에 대해 감을 잡아보자.
•
오래된 파일 삭제
class DeleteOldFilesTasklet(
private val filePath: String,
private val daysOld: Int,
): Tasklet {
private val log = LoggerFactory.getLogger(this::class.java)
override fun execute(
contribution: StepContribution,
chunkContext: ChunkContext
): RepeatStatus {
val dir = File(filePath)
val cutoff = System.currentTimeMillis() - daysOld * 24 * 60 * 60 * 1000L
dir.listFiles()?.forEach { file ->
if (file.lastModified() < cutoff) {
if (file.delete()) {
log.info("Deleted old file: ${file.name}")
} else {
log.warn("Failed to delete file: ${file.name}")
}
}
}
return RepeatStatus.FINISHED
}
}
@Bean
fun deleteOldFilesTasklet() = DeleteOldFilesTasklet("/path/to/directory", 30)
Kotlin
복사
이처럼 Tasklet으로 오래된 파일을 삭제하는 배치 Job을 만들 수 있다.
@Bean
fun deleteOldRecordStep(): Step {
return StepBuilder("deleteOldRecordStep", jobRepository)
.tasklet({ contribution, chunkContext ->
val deleted = jdbcTemplate.update("DELETE FROM records WHERE created_at < NOW() - INTERVAL '30 days'")
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
Kotlin
복사
혹은 간단한 작업이라면 이처럼 람다식으로 처리하기도 한다.
•
재고 현황 알림
class DailyInventoryReportTasklet(
private val alarmService: AlarmService,
private val inventoryService: InventoryService,
): Tasklet {
private val log = LoggerFactory.getLogger(this::class.java)
override fun execute(
contribution: StepContribution,
chunkContext: ChunkContext
): RepeatStatus {
val lowStockItems = inventoryService.findLowStockItems()
if (lowStockItems.isNotEmpty()) {
log.info("Low stock alert sent for items: ${lowStockItems.joinToString(", ")}")
alarmService.sendLowStockAlert(lowStockItems)
} else {
log.info("All inventory levels are sufficient.")
}
return RepeatStatus.FINISHED
}
}
Kotlin
복사
Tasklet 지향 처리 요약
Tasklet 지향 처리는 파일 삭제, 데이터 초기화, 알림 발송 등 단순하고 명확한 작업을 수행하는데 사용되는 Step 유형이다.
•
단순 작업에 적합
•
Tasklet 인터페이스를 구현해 로직 작성 후 tasklet() 메서드로 전달하여 Step 구성
•
RepeatStatus로 반복 실행 여부를 결정
•
Tasklet.execute() 메서드를 하나의 트랜잭션을 처리하여, 데이터베이스 일관성 및 원자성 보장
Chunk 지향 처리
단순한 작업을 처리하는 태스크릿 지향과는 다르게, 데이터를 다루는 대부분의 배치 작업은 읽기-처리-쓰기의 공통 패턴을 보인다. 이러한 패턴을 따르는 방식을 청크 지향 처리라고 부른다.
Chunk란
청크(Chunk)는 데이터를 일정 단위로 쪼갠 덩어리를 말하는데, 스프링 배치에서 데이터 기반 처리 방식은 읽고 처리하고 쓰는 작업을 대규모 데이터를 일정 크기의 데이터 덩어리(청크)로 나누어 처리하기 때문이다. 100만 건의 데이터가 있다고 하면, 100만 건의 데이터를 한 번에 읽고 처리하고 쓰기를 수행할 수 없다. 100개씩 혹은 1000개씩 쪼개어 읽고, 처리하고, 쓰는 것을 반복할 것이다. 이렇게 나뉜 100개의 묶음이 청크이다.
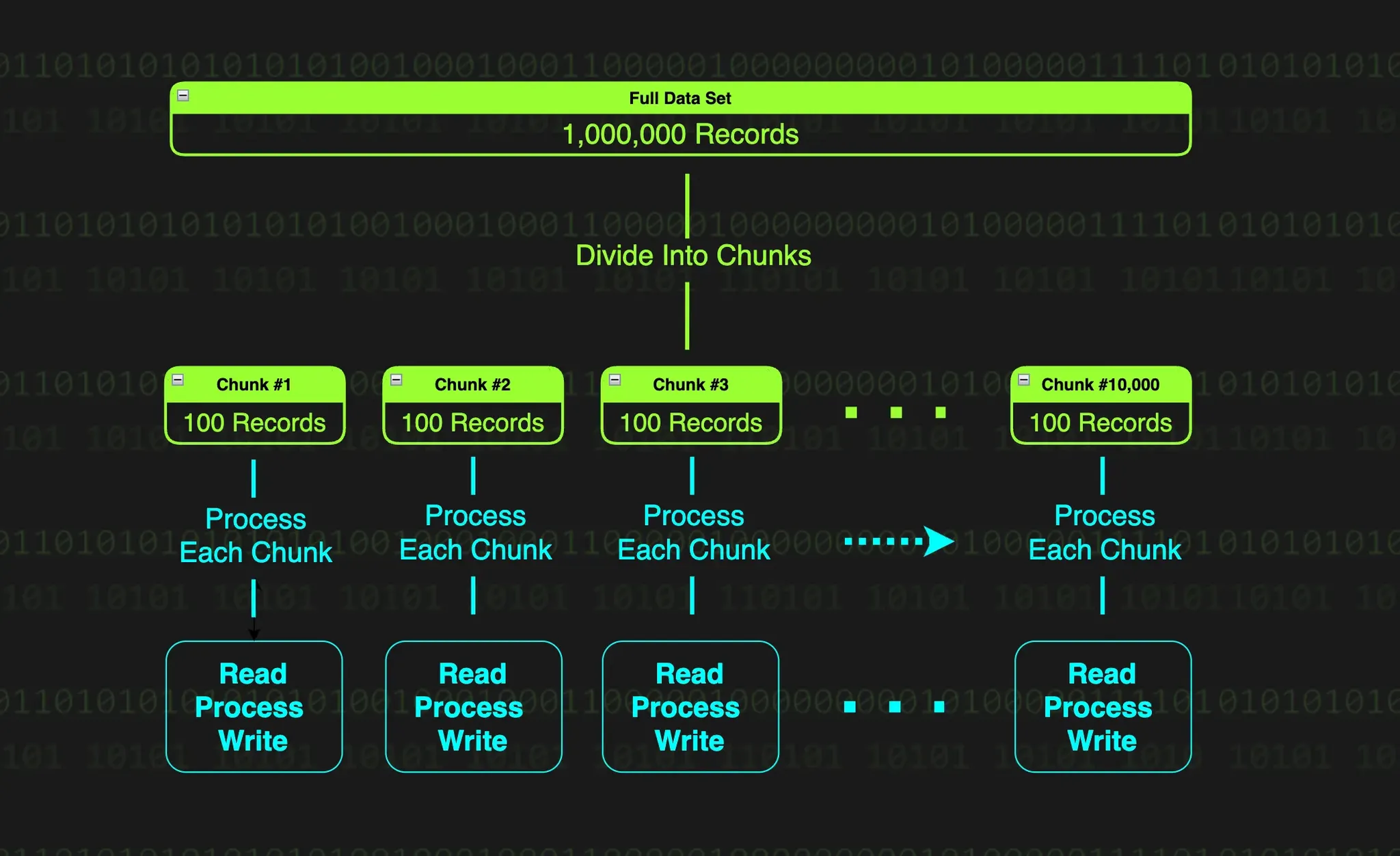
이렇게 청크 단위로 데이터를 나누어 처리하는 이유는 간단하다. 100만 건의 데이터를 한 번에 처리하려고 하면, 메모리가 터지거나 DB에 과부하가 걸리거나, 어찌어찌 처리하더라도 중간에 실패하는 경우 전체가 망가지게 된다. 때문에 청크로 나누어 처리하는 것은 다음과 같은 이점을 가진다.
•
메모리 과부하 방지
◦
청크 단위로 데이터를 불러오기 때문에, 메모리 사용량을 안정적으로 관리할 수 있다.
•
가벼운 트랜잭션(작은 실패)
◦
100만 건을 하나의 트랜잭션으로 처리하면, 중간에 실패하면 100만 건 전부 롤백 된다. 청크 단위로 작업하고 커밋하는 과정을 실패가 발생했을 때 복구가 쉽고 빠르다.
청크 지향 처리 - 읽기 / 처리하기 / 쓰기
스프링 배치에서는 이러한 청크 지향 처리의 방식을 ItemReader, ItemProcessor, ItemWriter 세 가지 컴포넌트로 구현하고 있다.
ItemReader
데이터를 처리하려면 일단 불러와야 한다. ItemReader라는 인터페이스를 통해 다양한 데이터 소스에서 데이터를 불러올 수 있다.
public interface ItemReader<T> {
T read() throws Exception,
UnexcpetedInputException,
PareseException,
NonTransientResourceException;
}
Java
복사
read 메서드의 반환 타입을 보면 컬렉션이 아닌 데이터 하나씩 반환하는 것을 볼 수 있다. ItemReader는 데이터 소스에서 데이터를 하나씩 순차적으로 읽어오고, 데이터가 없으면 null을 반환하여 Step은 종료된다. 여기서 중요한 것은 ItemReader가 null을 반환하는 것이 청크 지향 처리 방식의 Step의 종료 시점이라는 것이다.
ItemProcessor
ItemReader를 통해 데이터를 불러왔다면 이제 가공할 차례이다. ItemProcessor의 인터페이스는 다음과 같다.
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
Java
복사
process 메서드의 역할은 다음과 같다.
•
데이터 가공 : 입력 데이터를 비즈니스 로직에 맞게 가공하거나 출력 시스템이 요구하는 형식으로 변환한다.
•
필터링 : process 메서드가 null을 반환하면 해당 입력 데이터는 ItemWriter로 전달되지 않고, 데이터 처리 흐름에서 제외된다. 이를 통해 유효하지 않은 데이터나 처리할 필요가 없는 데이터를 걸러낼 수 있다.
•
데이터 검증 : 필터링과는 달리 조건에 맞지 않는 데이터를 만나면 예외를 발생시킬 수도 있다. 필수 필드의 누락이나 잘못된 데이터 형식을 발견했을 때 예외를 던져 배치 잡을 중단시키거나 스킵할 수 있다.
여기서 알아야 할 것은 ItemProcessor는 필수가 아니라 생략 가능하다는 점이다. Step이 데이터를 읽은 후 바로 쓰도록 구성할 수 있다.
ItemWriter
ItemWriter는 ItemProcessor가 가공한 데이터를 전달받아 원하는 방식으로 출력하거나 저장한다. DB에 데이터를 저장하거나, 파일에 쓰거나, 메세지 큐어 집어 넣는 등의 작업을 처리한다.
public interface ItemWriter<T> {
void write(Chunk<? extends T> chunk) throws Exception;
}
Java
복사
ItemReader나 ItemProcessor가 하나씩 처리하는 것과 달리, ItemWriter는 위 write 메서드를 보면 알 수 있듯 데이터를 Chunk 단위로 묶어서 한 번에 데이터를 쓴다.
Reader-Processor-Writer 패턴의 장점
이와 같이 ItemReader, ItemProcessor, ItemWriter로 구성된 청크 지향 처리의 장점은 다음과 같다.
•
책임 분리 : ItemReader는 읽기, ItemProcessor는 데이터 가공, ItemWriter는 쓰기에만 집중하여, 각 컴포넌트는 자신의 역할만 수행하면 된다. 이를 통해 코드가 명확해지고 유지보수가 간단해진다.
•
재사용성 극대화 : 각 컴포넌트가 독립적으로 설계되어 있어 어디서든 재사용 가능하다. 새로운 배치를 만들 때 기존 컴포넌트들을 조합 해 빠르게 구성할 수 있다.
•
높은 유연성 : 요구사항이 변경되면 해당 컴포넌트만 수정하면 된다. 독립성을 가지기 때문에 다른 컴포넌트에는 영향이 없다.
•
대용량 처리 표준 : 대규모 데이터를 다루는 배치 작업은 읽기-처리하기-쓰기 패턴을 따르게 되는데, 스프링 배치에서 이 패턴을 완벽히 구조화했다.
청크 지향 처리 조립하기
이제 ItemReader, ItemProcessor, ItemWriter를 Step에 구성하는 방법에 대해 알아보자.
@Bean
fun chunkStep(): Step {
return StepBuilder("chunkStep", jobRepository)
.chunk<CustomerDetail, CustomerSummary>(10, transactionManager)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build()
}
Kotlin
복사
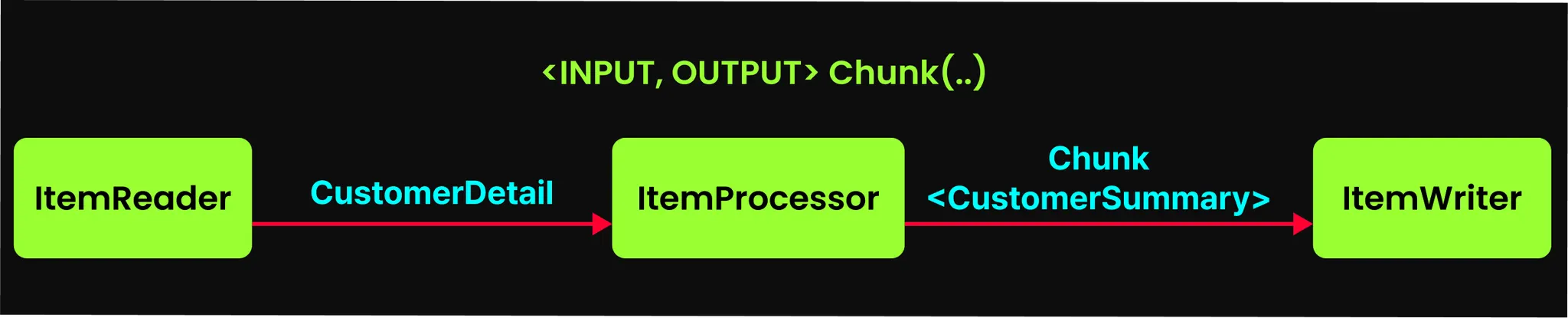
청크 지향 처리는 StepBuilder에서 chunk() 메서드를 호출하는 것으로 메서드 체인을 시작하는데, 이를 통해 Step은 청크 지향 처리 모델로 동작하게 된다. 각 구성 요소를 살펴보자.
•
제네릭 타입으로 데이터 흐름 정의
.chunk<CustomerDetail, CustomerSummary>...
Kotlin
복사
청크 메서드를 사용할 때, 제네릭을 통해 청크 처리 과정에서의 데이터 타입 변환 흐름을 정의한다.
제네릭의 첫 번째 타입은 ItemReader가 읽어서 ItemProcessor에 넘기는 타입이다.
제네릭의 두 번째 타입은 ItemProcessor가 가공 후 ItemWriter에 넘기는 변환 타입이다.
•
청크 사이즈 지정
...(10, transactionManager)
Kotlin
복사
파라미터를 통해 청크의 크기를 지정한다. 여기서는 10개씩 묶어서 처리하도록 지정하였는데, ItemReader가 10개의 데이터를 읽어오면 이를 하나의 청크로 만들어 ItemProcessor에서 처리하고 ItemWriter가 쓰기를 수행한다.
chunk 메서드 체인 이후 StepBuilder에서는 reader(), processor(), writer() 메서드를 통해 각각 구현체를 빌드에 전달한다.
•
reader : ItemReader 구현체를 전달받아 Step의 읽기 작업 담당 컴포넌트로 등록
•
processor : ItemProcessor 구현체를 전달받아 Step의 처리 작업 담당 컴포넌트로 등록(불필요 시 생략 가능)
•
writer : ItemWriter 구현체를 전달받아 Step의 스기 작업 담당 컴포넌트로 등록
청크 지향 처리의 흐름
스프링 배치의 청크 지향 처리는 읽기-가공하기-쓰기를 청크 단위로 묶어서 반복하는게 전부이다.
1.
데이터 읽기
ItemReader가 read 메서드를 호출 할 때마다 데이터 소스에서 하나씩 데이터를 읽어와 반환하며, 청크 사이즈만큼 읽어야 끝난다. 청크가 10이면 read가 10번 호출되어 하나의 청크가 생성된다.
2.
데이터 가공하기
ItemProcessor는 ItemReader가 읽어온 청크의 각 아이템을 하나씩 처리한다. 여기서 중요한 점은 process 메서드는 청크 전체를 입력 받는게 아니라, 청크의 각 아이템을 하나씩 받아서 처리한다는 점이다. 청크의 아이템마다 process 메서드를 반복 호출해 데이터를 가공한다. 청크가 10이면 process가 10번 호출된다.
3.
데이터 쓰기
ItemReader와 ItemProcessor에서는 아이템을 하나씩 처리하는 것과는 달리, ItemWriter는 청크 전체를 한 번에 입력받는다. write 메서드 입력만 봐도 알 수 있듯, 청크가 10개여도 write 메서드는 1번만 호출된다.
위 과정을 모든 데이터를 전부 처리할 때까지 반복하고, 이를 청크 단위 반복이라고 부른다.
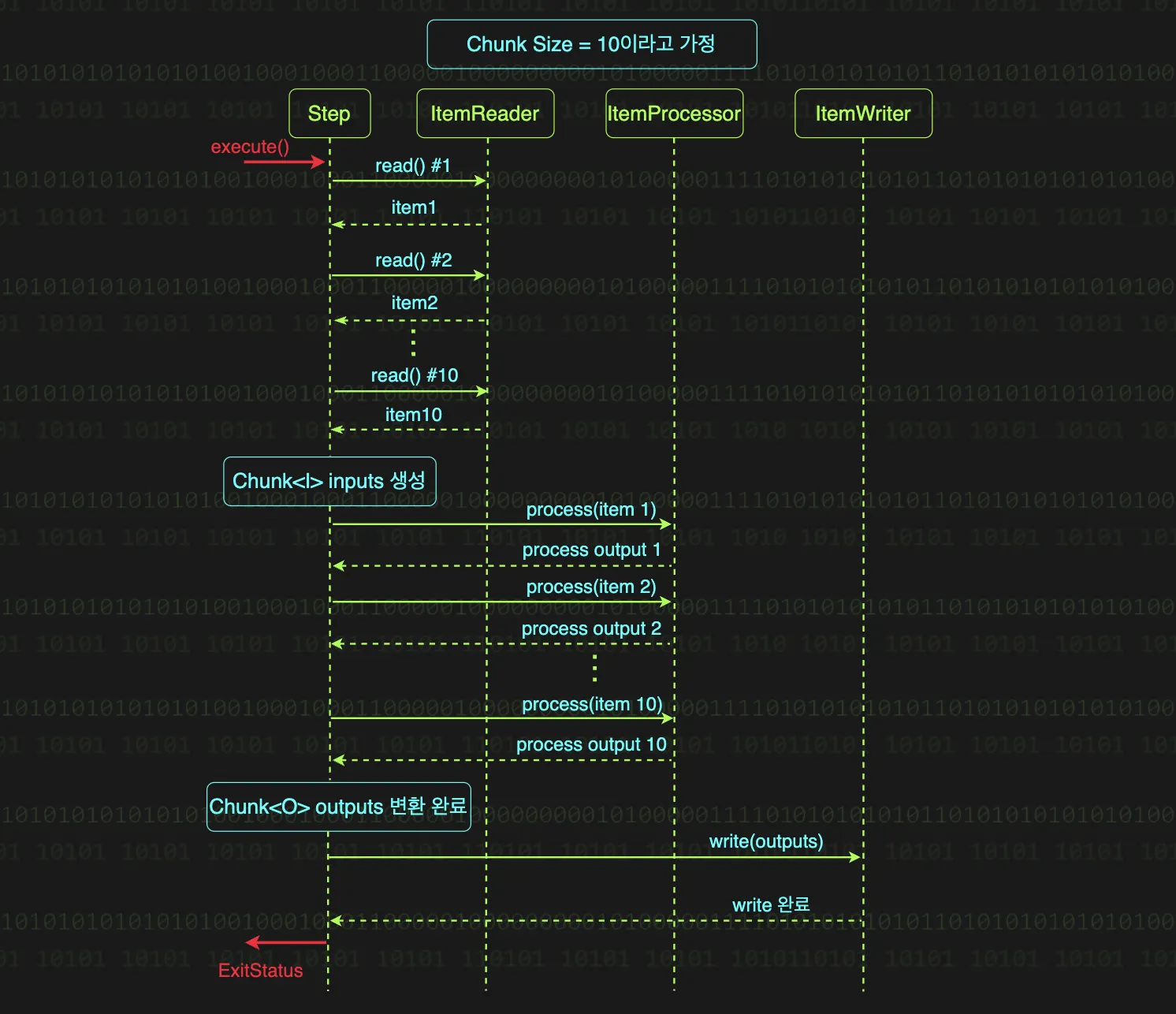
위 플로우 차트를 보면 알 수 있듯, 청크 크기만큼 ItemReader가 모두 호출된 후에, 그 다음 청크의 크기만큼 ItemProcessor가 호출된다.
청크 단위 반복의 종료 조건
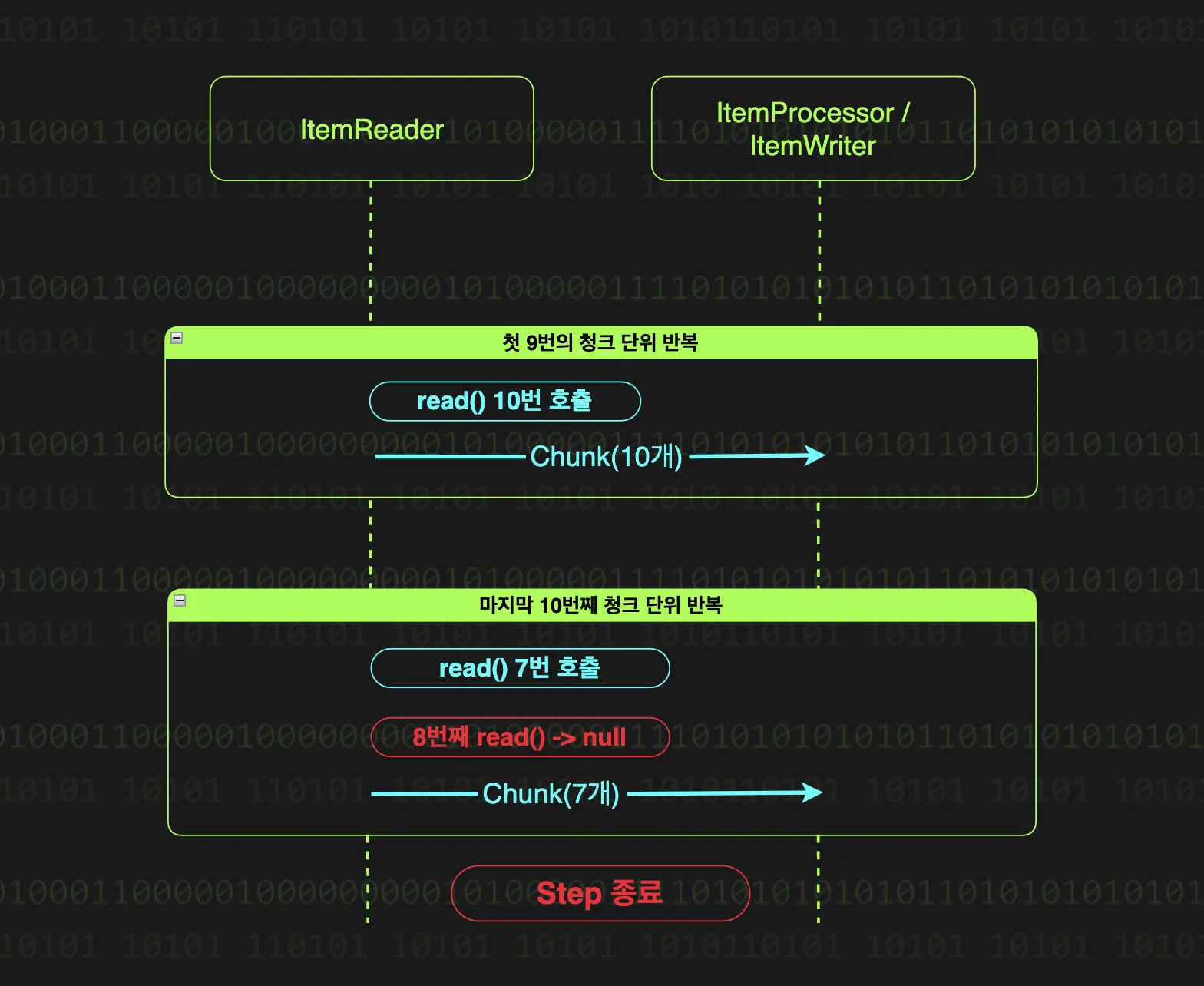
위에서 스프링 배치가 모든 데이터를 처리할 때까지 과정을 반복한다고 했는데, 모든 데이터를 처리했다는 것은 어떻게 알 수 있을까? 그 해답은 더 이상 읽을 데이터가 없을 때 모든 데이터를 처리했다고 판단한다. 다시말해 ItemReader가 null을 반환할 때, 스프링 배치는 모든 데이터를 다 읽었다고 인식하고 청크 단위 반복을 종료한다.
예시로 97개의 데이터를 10의 청크 크기로 처리하는 상황을 살펴보자.
•
처음 9번의 반복 시에는 청크 사이즈만큼 데이터가 있기 때문에, 매번 10개의 데이터를 읽어와 처리하게 된다.
•
마지막 10번째의 반복 시에, 남은 데이터인 7개만큼은 정상적으로 읽어오고 8번째 read 메서드 호출에서 null이 반환된다. 이를 통해 마지막임을 인지하고 읽어온 7개의 데이터로 청크를 구성해 ItemProcessor에 넘기게 된다.
청크 처리와 트랜잭션
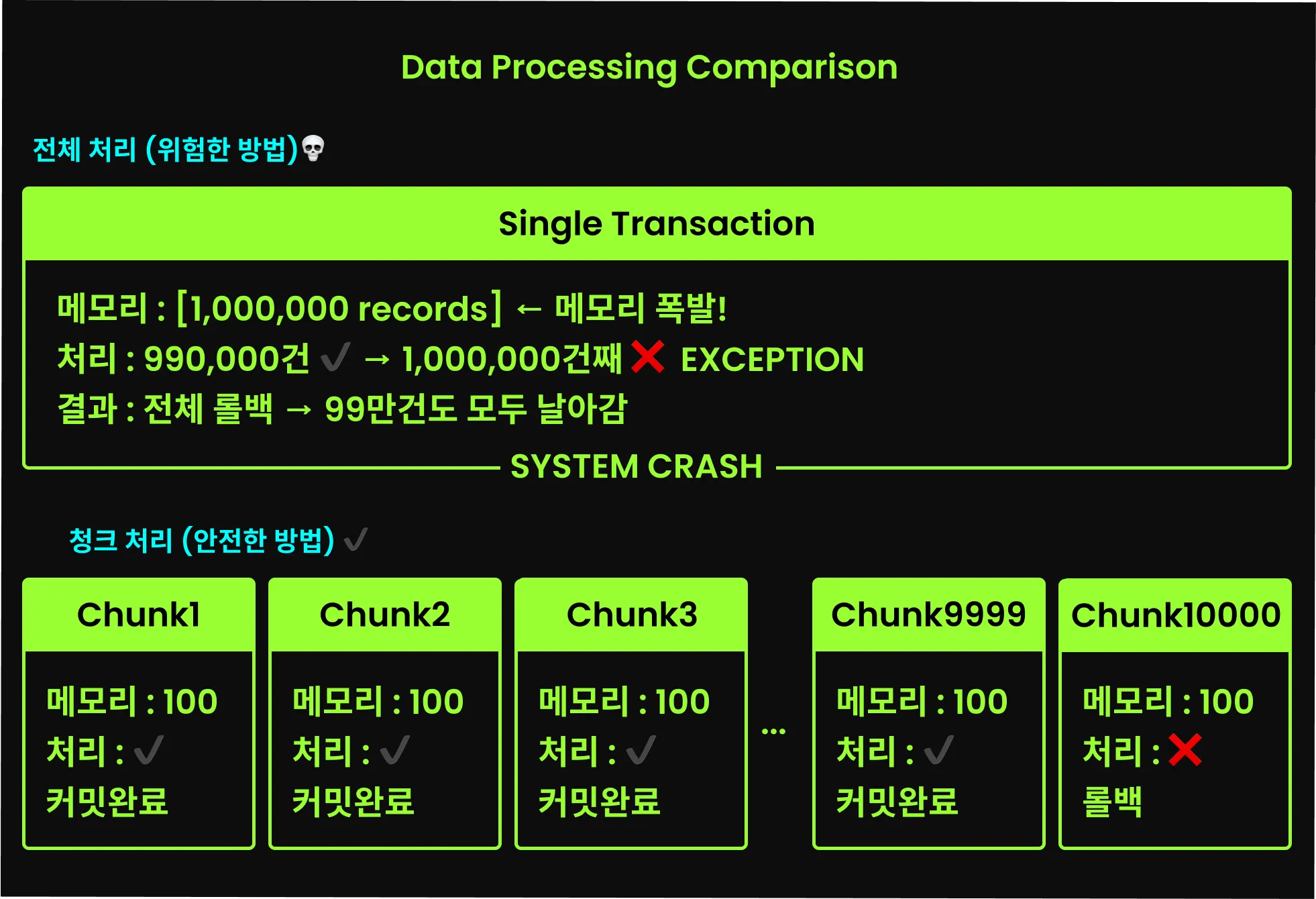
태스크릿 지향 처리에서는 transactionManager를 함께 넘겨, execute 메서드가 실행될 때 트랜잭션을 시작하여 메서드가 끝나면 커밋하며 트랜잭션도 종료된다. 하지만 청크 지향 처리에서는 트랜잭션도 청크 단위로 관리된다. 즉, 각각의 청크 단위 반복마다 별도의 트랜잭션이 시작되고 커밋된다.
청크 단위로 트랜잭션이 시작되고 커밋된다는 것은, 대용량 데이터를 처리하는 도중에 Step이 실패하더라도 이전 청크 반복에서 처리된 데이터는 안전하게 커밋이 완료되어 작업 내용이 보존된다는 의미이다. 실패한 청크만 롤백되므로, 전체 데이터를 처음부터 다시 처리할 필요가 없다.
적절한 청크 사이즈
사실 적절한 청크 사이즈에 대한 정답은 없다. 아래에 소개할 두 가지 트레이드오프와 비즈니스 요구사항, 처리할 데이터의 양을 고려해 적절히 선택해야한다.
•
청크 사이즈가 클 때 : 메모리에 많은 데이터를 로드하고, 트랜잭션의 경계가 커져 문제 발생 시 롤백되는 데이터의 양도 많아진다.
•
청크 사이즈가 작을 때 : 트랜잭션의 경계가 작아져 문제 발생 시 롤백되는 데이터가 최소화되지만, 그만큼 읽기/쓰기 I/O가 자주 발생해 속도가 느려진다.
JobParameters와 Spring Batch Scope
JobParameters란?
JobParameters는 단순히 배치에 전달하는 매개변수 같지만, 특정 날짜, 파일 경로, 쿼리 조건 등 배치가 어떤 조건에서 어떤 데이터를 다룰지를 결정하는 아주 중요한 통제 변수다. 오래된 로그 파일을 삭제하는 배치를 생각해보자.
•
어떤 날짜의 로그 파일을 제거할 것인가? (targetDate=2024-01-01)
•
어떤 디렉토리의 파일들을 제거할 것인가?(basePath=/var/log/system)
•
어떤 파일명 패턴을 가진 로그를 제거할 것인가?(filePattern=*.log)
이 모든 처리 대상과 조건을 JobParameters를 통해 동적으로 결정할 수 있다.
매일 실행되는 배치 작업에서 날짜나 파일 경로는 매일마다 달라질 수 있다. JobParameters가 없다면 이 배치를 실행시키기 위해서는 매번 수정하고 실행시켜야 할 것이다. 하지만 JobParameters를 통해 우리는 수정 없이 유연하게 배치를 실행 시킬 수 있다.
프로퍼티와 JobParameters의 차이
우리는 -D 옵션을 통해 프로퍼티로 우리가 원하는 값을 전달할 수 있다. 하지만 JobParameters와 프로퍼티는 완전히 다른 목적을 가지고 있다.
1. 입력값 동적 변경
./gradlew bootRun --args='--spring.batch.job.name=helloJob'
Shell
복사
우리는 이와 같이 배치를 실행 시킬 수 있는데, 이 정도의 단순한 흐름이라면 프로퍼티만으로 충분할 수 있다. 하지만 현실에서는 배치를 그렇게 단순하게 사용하지 않기도 한다.
예를 들어, 웹 요청이 들어올 때마다 비동기로 배치 Job을 실행하는 온라인 배치 앱이 있을 때, 요청이 올 때마다 새로운 Job을 실행하게 될 것이다. 이런 상황에서 웹 요청으로 전달된 값을 Job의 제어 변수로 주입하는 것은 프앱 시작 시 한 번 주입되는 정적인 값인 로퍼티로는 불가능하다. JobParameters는 별도의 부가적인 처리없이 실행 중인 앱에도 동적으로 값을 변경할 수 있다.
2. 메타데이터
스프링 배치는 JobParameters의 모든 값을 메타저장소에 기록하는데, 이를 통해 다음과 같은 중요한 기능을 제공한다.
•
Job 인스턴스 식별 및 재시작 처리
•
Job 실행 이력 추적
반면 프로퍼티는 메타데이터로 기록되지 않기 때문에, Job 인스턴스 식별 및 재시작 처리에 활용할 수 없고 실행 이력 관리도 불가능하다.
배치 메타데이터
스프링 배치는 JobRepository를 통해 Job과 Step의 실행 이력을 메타데이터 저장소에 기록한다. 여기에는 Job과 Step의 시작/종료 시간, 실행 상태, 처리된 레코드 수 등을 포함한다.
JobParameters 전달하기
CLI로 파라미터 전달하기
Spring Boot 3와 Spring Batch 5 기준으로 커맨드 라인을 통해 파라미터를 전달하는 방식을 알아보자.
./gradlew runBoot --args='--spring.batch.job.name=dataProcessJob inputFilePath=/data/input/user.csv,java.lang.String'
Shell
복사
실무에서 가장 자주 사용되는 시나리오로 파일 경로를 파라미터로 넘기는 방법이다. --spring.batch.job.name으로 전달한 Job 이름 뒤에 파라미터인 inputFilePath=/data/input/user.csv,java.lang.String를 넘기고 있다. key=value,type 형태로 JobParameters가 주입되고 있다.
JobParameters 기본 표기법
parameterName=parameterValue,parameterType,identificationFlag
Shell
복사
JobParameters는 기본적으로 위의 형식을 따른다.
•
parameterName : 배치 Job에서 파라미터를 찾을 때 사용하는 key 값이다. 이 이름을 통해 Job의 파라미터에 접근할 수 있다.
•
parameterValue : 전달할 파라미터의 실제 값
•
parameterType : 전달할 파라미터의 타입으로, 타입을 명시하기 않을 경우 스프링 배치에서는 String으로 가정한다.(java.lang.String, java.lang.Integer처럼 fully qualified name으로 사용)
•
identificationFlag : 스프링 배치에서 해당 파라미터가 JobInstance를 식별에 사용할 파라미터인지를 나타내는 플래그이다. true로 설정하면 해당 파라미터가 식별에 사용되고, 생략할 경우 true 설정된다.
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob inputFilePath=/data/input/users.csv,java.lang.String userCount=5,java.lang.Integer,false'
Shell
복사
만약 여러 개의 파라미터를 전달해야한다면, 이처럼 같이 공백으로 구분하여 전달하면 된다.
JobParameterType
전달된 JobParameters는 스프링 배치의 DefaultJobParameterConverter라는 컴포넌트를 통해 타입이 변환된다. DefaultJobParameterConverter는 내부적으로 DefaultConversionService를 사용하기 때문에 Integer, Boolean 같은 기본 타입 외에도 DefaultConversionService가 제공하는 다양한 타입으로 변환이 가능하다. 추가적으로 LocalDate, LocalDateTime 같은 시간 관련 변환 타입도 지원한다.
기본 데이터 타입 전달해보기
@Configuration
class DataProcessingBatchConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
) {
@Bean
fun dataProcessingJob(dataProcessingStep: Step): Job {
return JobBuilder("dataProcessingJob", jobRepository)
.start(dataProcessingStep)
.build()
}
@Bean
fun dataProcessingStep(dataProcessingTasklet: Tasklet): Step {
return StepBuilder("dataProcessingStep", jobRepository)
.tasklet(dataProcessingTasklet, transactionManager)
.build()
}
@Bean
@StepScope
fun dataProcessingTasklet(
@Value("#{jobParameters['dataId']}") dataId: String,
@Value("#{jobParameters['targetCount']}") targetCount: Int,
): Tasklet {
return Tasklet() { contribution, chunkContext ->
log.info("data process start : dataId=$dataId")
for (i in 1..targetCount) {
log.info("data processing... $i / $targetCount")
// data processing
}
RepeatStatus.FINISHED
}
}
}
Kotlin
복사
Tasklet을 살펴보면, @Value 애노테이션과 EL 문법을 통해 JobParameter를 주입받을 수 있다. 여기서 @StepScope 애노테이션을 같이 사용하는데, 추후 다룰 예정이니 지금은 @Value 애노테이션으로 파라미터를 전달하려면 @StepScope 애노테이션이 필요하다 정도만 이해하자.
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob dataId=123 targetCount=10,java.lang.Integer'
Shell
복사
그 후 JobParameters를 CLI로 전달하면,
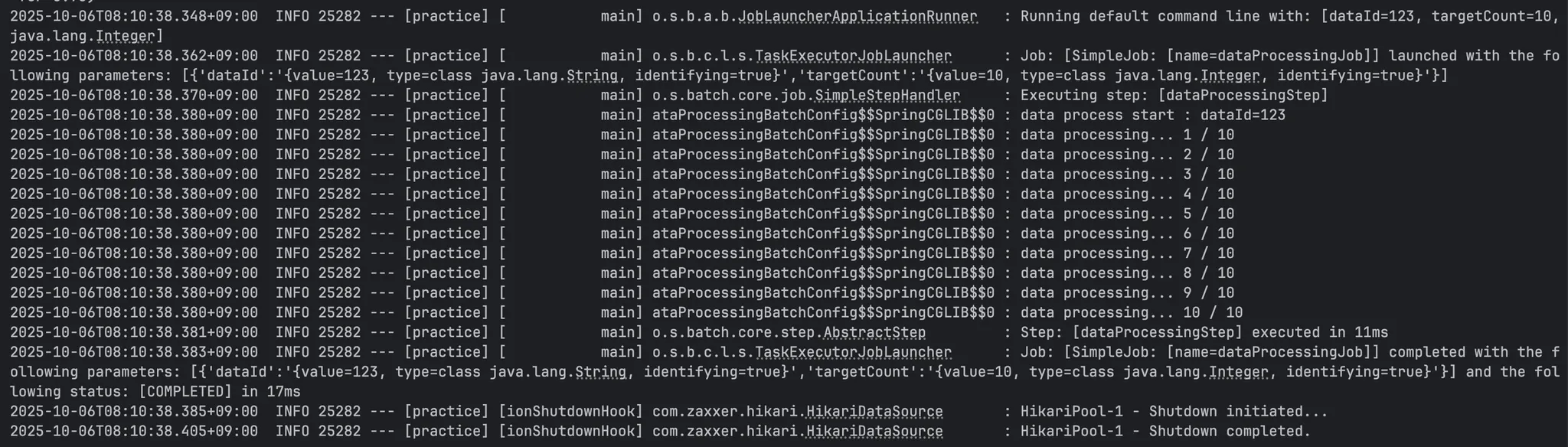
이처럼 파라미터가 잘 전달된 것을 확인할 수 있다.
날짜와 시간 파라미터 전달
이번에는 LocalDate와 LocalDateTime 타입을 파라미터로 전달해보자.
@Bean
@StepScope
fun timeProcessingTasklet(
@Value("#{jobParameters['processTime']}") processTime: LocalDateTime,
@Value("#{jobParameters['expectedCompletionDate']}") expectedCompletionDate: LocalDate,
): Tasklet {
return Tasklet { contribution, chunkContext ->
log.info("time process start : processTime=$processTime, expectedCompletionDate=$expectedCompletionDate")
// time processing logic here
RepeatStatus.FINISHED
}
}
Kotlin
복사
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob processTime=2025-10-06T10:45:12,java.time.LocalDateTime expectedCompletionDate=2025-10-10,java.time.LocalDate'
Shell
복사

위처럼 두 타입도 파라미터로 전달할 수 있는데, 여기서 주의할 점이 있다. LocalDate는 yyyy-MM-dd 형식을 맞춰서 전달해야하고, LocalDateTime은 yyyy-MM-ddThh:mm:ss 형식을 맞춰서 전달해야한다. 그 이유는 DefaultJobParametersConverter가 DateTimeFormatter의 ISO_LOCAL_DATE와 ISO_LOCAL_DATE_TIME 형식에 맞춰서 변환을 하기 때문이다.

파라미터를 잘못 전달하지 않거나 잘못 전달하면 다음과 같은 에러가 발생한다.
•
전달하지 않은 경우
Error creating bean with name 'scopedTarget.timeProcessingTasklet' defined in class path resource [com/batch/practice/batchjob/dataProcessingBatchConfig.class]: Unsatisfied dependency expressed through method 'timeProcessingTasklet' parameter 0: Failed to convert value of type 'null' to required type 'long'; Failed to convert from type [null] to type [@org.springframework.beans.factory.annotation.Value long] for value [null]
Plain Text
복사
•
잘못 전달한 경우
Error creating bean with name 'scopedTarget.timeProcessingTasklet' defined in class path resource [com/batch/practice/batchjob/dataProcessingBatchConfig.class]: Unsatisfied dependency expressed through method 'timeProcessingTasklet' parameter 1: Failed to convert value of type 'java.time.LocalDate' to required type 'java.time.LocalDateTime'; Cannot convert value of type 'java.time.LocalDate' to required type 'java.time.LocalDateTime': no matching editors or conversion strategy found
Plain Text
복사
열거형(Enum) 파라미터 전달
서비스의 안정성을 높이기 위해 미리 지정된 값(Enum)을 파라미터로 받고 싶을 수 있다. 열거형(Enum)을 파라미터로 전달하는 방법을 알아보자.
@Configuration
class DataProcessingBatchConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
) {
...
@Bean
@StepScope
fun enumProcessingTasklet(
@Value("#{jobParameters['processOption']}") processOption: MyEnum,
): Tasklet {
return Tasklet { contribution, chunkContext ->
log.info("enum process start : processOption=$processOption")
when (processOption) {
MyEnum.OPTION1 -> log.info("Processing with OPTION1")
MyEnum.OPTION2 -> log.info("Processing with OPTION2")
MyEnum.OPTION3 -> log.info("Processing with OPTION3")
}
RepeatStatus.FINISHED
}
}
enum class MyEnum {
OPTION1,
OPTION2,
OPTION3
}
}
Kotlin
복사
위처럼 enum이 다른 클래스 내부에 있는 경우에는
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob processOption=OPTION2,com.batch.practice.batchjob.DataProcessingBatchConfig$MyEnum'
Shell
복사
이처럼 {외부클래스명}${내부클래스명} 형태로 파라미터를 전달해야하고,
@Configuration
class DataProcessingBatchConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
) {
...
@Bean
@StepScope
fun enumProcessingTasklet(
@Value("#{jobParameters['processOption']}") processOption: MyEnum,
): Tasklet {
return Tasklet { contribution, chunkContext ->
log.info("enum process start : processOption=$processOption")
when (processOption) {
MyEnum.OPTION1 -> log.info("Processing with OPTION1")
MyEnum.OPTION2 -> log.info("Processing with OPTION2")
MyEnum.OPTION3 -> log.info("Processing with OPTION3")
}
RepeatStatus.FINISHED
}
}
}
enum class MyEnum {
OPTION1,
OPTION2,
OPTION3
}
Kotlin
복사
이처럼 클래스 외부나 별도의 클래스에 있다하면,
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob processOption=OPTION2,com.batch.practice.batchjob.MyEnum'
Shell
복사
클래스 위치만 전달하면 된다.
하나의 Step에 여러 Tasklet을 지정하는 경우
@Bean
fun dataProcessingStep(
dataProcessingTasklet: Tasklet,
timeProcessingTasklet: Tasklet,
enumProcessingTasklet: Tasklet,
): Step {
return StepBuilder("dataProcessingStep", jobRepository)
.tasklet(dataProcessingTasklet, transactionManager)
.tasklet(timeProcessingTasklet, transactionManager)
.tasklet(enumProcessingTasklet, transactionManager)
.build()
}
Kotlin
복사
위 처럼 하나의 Step에 여러 Tasklet을 지정하는 경우, 마지막으로 지정된 tasklet만 수행된다. 위 케이스에서는 enumProcessingTasklet이 수행된다.

실행해보면 이처럼 Enum 타입에 잘 전달된 것을 확인할 수 있다.
POJO를 활용한 JobParameters 주입
단순한 타입이 아닌 POJO 데이터 클래스로 파라미터를 전달할 필요도 있을 것이다.
@Component
@StepScope
class PojoParameters(
@Value("#{jobParameters['stringParam']}") val stringParam: String,
@Value("#{jobParameters['intParam']}") val intParam: Int,
)
Kotlin
복사
@Bean
fun pojoProcessingTasklet(pojoParameters: PojoParameters): Tasklet {
return Tasklet { contribution, chunkContext ->
log.info("pojo process start : stringParam=${pojoParameters.stringParam}, intParam=${pojoParameters.intParam}")
// pojo processing logic here
RepeatStatus.FINISHED
}
}
Kotlin
복사
이처럼 파라미터로 받을 클래스를 선언해 파라미터로 두고,
./gradlew bootRun --args='--spring.batch.job.name=dataProcessingJob stringParam=문자열파라미터,java.lang.String intParam=12345,java.lang.Integer'
Shell
복사
이처럼 POJO 클래스 내에 @Value로 매핑해둔 파라미터를 넣어주면 동작한다.

JobParameters의 JSON 기반 표기법
만약 옵션1,옵션2,옵션3처럼 문자열 내 쉼표를 포함하는 경우에는, 파라미터 전달이 제대로 이루어지지 않고 에러가 발생한다. 이런 문제점을 JSON 기반 표기법으로 해결할 수 있다.
stringParam='{"value": "옵션1, 옵션2, 옵션3"}, "type": "java.lang.String"}'
Shell
복사
이처럼 JSON 기반으로 전달하여 쉼표가 파라미터로 전달하는 문자열의 일부임을 명확히 할 수 있게 된다. JSON 표기법에서도 value, type, identifying 구성 요소들은 동일한 의미를 가지고, 마찬가지로 identifying은 생략 가능하여 생략 시 true로 설정된다.
JSON 기반 파라미터 표기법 사용하기
JSON 기반 파라미터 표기법을 사용하기 위해서는 JSON 라이브러리가 필요하다.
implementation("org.springframework.boot:spring-boot-starter-json")
Shell
복사
의존성을 추가해주고,
@Configuration
class JsonConfig {
@Bean
fun jobParametersConverter(): JobParametersConverter {
return JsonJobParametersConverter()
}
}
Kotlin
복사
위처럼 JobParameteresConverter에 JsonJobParametersConverter 인스턴스를 생성해 Job 파라미터 컨버터로 등록해주면 된다.
./gradlew bootRun --args="--spring.batch.job.name=dataProcessingJob \
stringParam='{\"value\": \"문자열1,문자열2,문자열3\", \"type\": \"java.lang.String\"}' \
intParam='{\"value\": 123, \"type\": \"java.lang.Integer\"}'"
Shell
복사
•
위에서 큰 따옴표를 이스케이프 처리한 것을 볼 수 있는데, Gradle bootRun을 통해 JSON 기반 표기법으로 파라미터를 넘길 때는 JSON 내 문자열 큰 따옴표를 이스케이프 처리해야만 인식한다.
•
java -jar를 사용해 직접 애플리케이션을 실행시킬 때는 아래처럼 JSON 표기법을 그대로 사용할 수 있다.
java -jar batch-practice-0.0.1-SNAPSHOT.jar --spring.batch.job.name=dataProcessingJob \
stringParam='{"value": "문자열1,문자열2,문자열3", "type": "java.lang.String"}' \
intParam='{"value": 123, "type": "java.lang.Integer"}'"
Shell
복사
•
IntelliJ에서 실행 시킬 때는 Program arguments에 아래와 같이 입력하면 된다.
--spring.batch.job.name=dataProcessingJob \
stringParam='{"value": "문자열1,문자열2,문자열3", "type": "java.lang.String"}' \
intParam='{"value": 123, "type": "java.lang.Integer"}'"
Shell
복사
그 후 명령어를 통해 실행하면 배치가 정상적으로 동작하는 것을 볼 수 있다.

CLI에서 파라미터가 Job으로 전달되는 과정
Spring Batch를 Spring Boot와 함께 사용하게 되면 애플리케이션이 시작될 때 JobLauncherApplicationRunner라는 특별한 컴포넌트가 자동으로 등록된다. 이 JobLauncherApplicationRunner는 스프링 부트가 제공하는 ApplicationRunner 중 하나로, 커맨드 라인으로 전달된 스프링 배치 Job의 파라미터를 해석하여 이를 가지고 실제 Job을 실행하는 역할을 수행한다.
JobLauncherApplicationRunner의 처리 과정은 다음과 같다.
•
Job 목록 준비 : 스프링 부트에 의해 ApplicationContext에 등록된 모든 Job 타입 빈이 JobLauncherApplicationRunner에 자동으로 주입된다.
•
유효성 검증 : 애플리케이션 컨텍스트에 만약 Job 타입의 빈이 여러 개인데, --spring.batch.job.name을 지정하지 않은 경우나 이름으로 Job을 찾을 수 없을 때는 실패 처리한다.(Job 빈이 하나인 경우 생략 가능)
•
명령어 해석 : 커맨드라인으로 전달된 값을 파싱한다. DefaultJobParametersConverter 혹은 JsonParametersConverter 등으로 key=value 형식의 파라미터들을 JobParameters로 변환한다.
•
Job 실행 : 주입 받은 Job 목록에서 job name과 일치하는 것을 찾고, 앞서 변환된 파라미터와 함께 JobLauncher에 의해 실행된다.
다양한 방식으로 실행하며 파라미터 전달하기
커맨드라인을 통해 파라미터를 전달하는 방법은 이제 이해하였으나, 실무에서는 커맨드라인 외에도 다양한 방식으로 배치를 실행시킨다.
•
REST API를 통해 외부 시스템에서 배치를 트리거
•
메세지 큐에서 특정 메세지가 도착했을 때 배치를 트리거
•
파일 업로드 완료, 주문 처리 완료 등 특정 비즈니스 이벤트가 발생했을 때 배치를 트리거
•
@Scheduled 태스크에서 동적 파라미터와 함께 배치를 실행해야 하는 경우
이러한 상황들에서는 프로그래밍 내부적으로 JobParameters를 생성하고 전달하는 방법이 필요하다.
프로그래밍 방식으로 JobParameters 생성/전달하기
프로그래밍 방식으로 JobParameters를 생성해서 전달하려면 JobParametersBuilder라는 컴포넌트가 필요하다.
@RestController
@RequestMapping("/api/batch")
class BatchController(
private val jobLauncher: JobLauncher,
@Qualifier("dataProcessingJob")
private val dataProcessingJob: Job
) {
@PostMapping("/data-processing/job-parameters-test")
fun jobParametersBuilderTest() {
val jobParameters = JobParametersBuilder()
.addJobParameter("stringParam", "문자열1,문자열2,문자열3", String::class.java)
.addJobParameter("intParam", 12345, Int::class.java)
.toJobParameters()
jobLauncher.run(dataProcessingJob, jobParameters)
}
}
Kotlin
복사
이처럼 JobParametersBuilder의 API 메서드 체인으로, addJobParameter() 메서드를 호출하여 파라미터 이름, 값, 타입을 전달해 JobParameters를 생성할 수 있다. 또한 identifying 변수를 받을 수 있는 오버로딩 메서드도 존재하니, 필요하다면 identifying 변수를 넣어서 처리할 수도 있다.
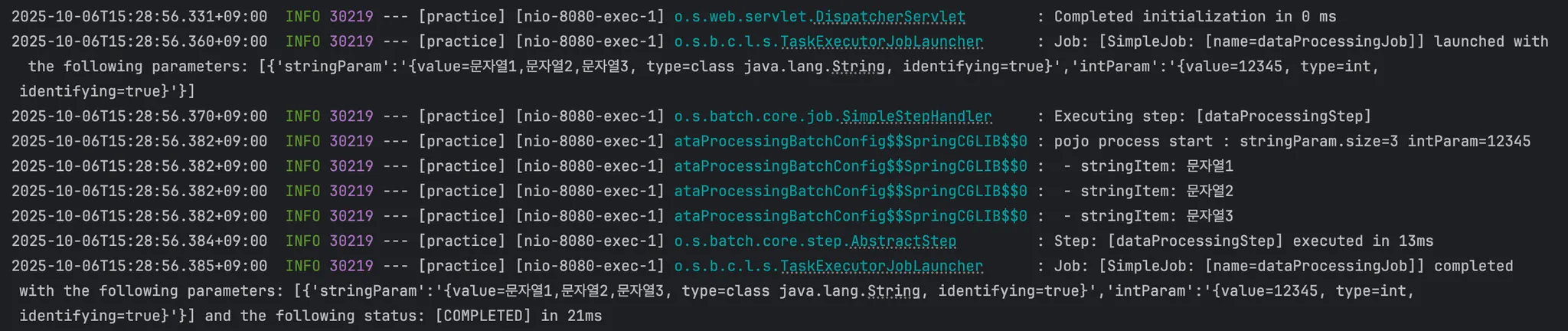
이처럼 웹 서버를 실행시키고 생성한 API 엔드포인트를 호출해보면 Job이 트리거 되었고 잘 동작하는 것을 확인할 수 있다.
JobParameters 직접 접근하기
위의 과정을 통해 커맨드라인과 프로그래밍 방식으로 JobParameters를 배치 Job에 전달하는 방법을 배웠다. 여기서 @StepScope와 @Value 애노테이션으로 Job 구성 코드에서 파라미터를 참조하게 만들었다. 하지만 @Value를 사용하지 않고도 JobParameters에 접근할 수 있는 또 다른 방식에 대해 알아보자.
스프링 배치에서는 JobExecution 컴포넌트가 JobParameters를 포함한 Job의 실행 정보를 가지고 있다. JobExecution은 Job 실행 시점에 생성되어 Job의 실행 상태, JobParameters, 실행 결과를 가지고 있는데, 이 JobExecution을 통해 JobParameters를 가져올 수 있다.
@Bean
fun jobExecutionParameterTasklet(): Tasklet {
return Tasklet { contribution, chunkContext ->
val jobParameters = chunkContext.stepContext.jobParameters
log.info("Job Parameters:")
(jobParameters["stringParam"] as String?)
?.split(",")
?.forEach { log.info(" - stringParam item: $it") }
(jobParameters["intParam"] as Int?)?.let { log.info(" - intParam: $it") }
RepeatStatus.FINISHED
}
}
Kotlin
복사
로직을 보면 chunkContext에서 stepContext를 꺼내고, 그 안에서 jobParameters를 꺼내는 것을 알 수 있다.
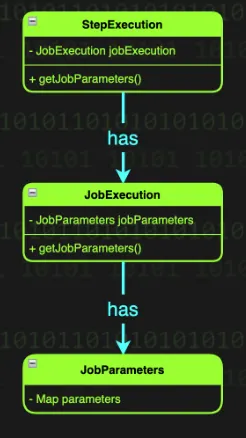
public class StepExecution extends Entity {
private final JobExecution jobExecution;
...
}
Kotlin
복사
이처럼 StepExecution은 JobExecution을 참조하고 있고 JobExecution이 JobParameters를 참조하고 있어, StepExecution으로 JobParameters를 가져오는 것이 가능하다.
이렇게 설정한 후 실행시켜보면

JobParameters를 잘 읽어온 것을 확인할 수 있다.
JobParametersValidator
웹 서버를 만들다보면 우리가 파리미터를 전달받기 전에 검증을 해야하는 경우가 많다. 배치 작업 역시 배치 실행을 위해 전달 받은 파라미터를 검증하여, 의도치 않은 파라미터가 들어오는 것을 막아 장애를 예방하는 것이 좋다. JobParametersValidator는 이러한 역할을 맡아 JobParameters에 잘못된 값이 들어오는 경우 배치가 실행되지 않게 할 수 있다.
public interface JobParametersValidator {
void validate(@Nuallable JobParameters parameters) throws JobParametersInvalidException;
}
Java
복사
JobParametersValidator는 이름에 맞게 validate 하나의 메서드만 들고 있다.
@Component
class DataProcessingBatchJobParametersValidator: JobParametersValidator {
override fun validate(parameters: JobParameters?) {
if (parameters?.isEmpty == true) {
throw IllegalArgumentException("배치 파라미터가 없습니다.")
}
val stringParam = parameters!!.getString("stringParam")
if (stringParam.isNullOrBlank()) {
throw IllegalArgumentException("stringParam 파라미터가 없습니다.")
}
// val intParam = parameters.getLong("intParam") // Int 타입으로 받는게 불가능
val intParam = parameters.getParameter("intParam")?.let {
if (it.type != Int::class.java && it.type != Integer::class.java) {
throw IllegalArgumentException("intParam 파라미터 타입이 Int 타입이 아닙니다.")
}
it.value as Int
}
if (intParam == null || intParam <= 0) {
throw IllegalArgumentException("intParam 파라미터가 없거나 0 이하입니다.")
}
}
}
Kotlin
복사
이렇게 JobParametersValidator를 구현하고,
@Bean
fun dataProcessingJob(dataProcessingStep: Step): Job {
return JobBuilder("dataProcessingJob", jobRepository)
.validator(dataProcessingBatchJobParametersValidator)
.start(dataProcessingStep)
.build()
}
Kotlin
복사
JobBuilder에서 start 메서드 전에 검증을 수행하도록 구성해주면 검증 로직을 사용할 수 있다.
•
정상 파라미터 입력

•
파라미터 검증 실패 (intParam=-1 입력)

JobParameters를 검증하기 위해 매번 이와 같은 JobParametersValidator를 구현하는 것은 너무 번거로운 일이다. 때문에 스프링 배치에서는 DefaultJobParametersValidator라는 기본 구현체를 제공한다. DefaultJobParametersValidator는 파라미터의 존재 여부만 검증하기 때문에, 그 정도의 검증이면 충분한 케이스에서는 따로 구현할 필요없이 그냥 사용할 수 있다.
@Bean
fun dataProcessingJob(dataProcessingStep: Step): Job {
return JobBuilder("dataProcessingJob", jobRepository)
.validator(DefaultJobParametersValidator(
arrayOf("stringParam"), // 필수 파라미터
arrayOf("intParam"), // 선택 파라미터
))
.start(dataProcessingStep)
.build()
}
Kotlin
복사

이처럼 옵셔널한 파라미터는 선택 파라미터로 넘겨서 없더라도 검증에 통과하게 만들 수 있다. 위에 등록되지 않은 파라미터를 허용하지 않기 때문에 그러한 경우에도 배치에 수행하지 않고 오류를 반환한다.
검증은 필요하지만 간단한 검증만 수행할 것이라 구현체를 만들기에는 귀찮다면 람다와 익명함수를 활용할 수도 있다.
Job과 Step의 Scope
스프링 배치는 일반적인 Spring 애플리케이션의 기본 스코프인 싱글톤과는 다른 특별한 스코프인 JobScope와 StepScope를 제공한다. JobScope와 StepScope가 선언되어있는 빈은 애플리케이션 구동 시점에는 우선 프록시 객체로만 존재하다가, 이후 Job이나 Step이 실행된 후에 객체에 접근을 시도할 때 실제 빈이 생성된다.
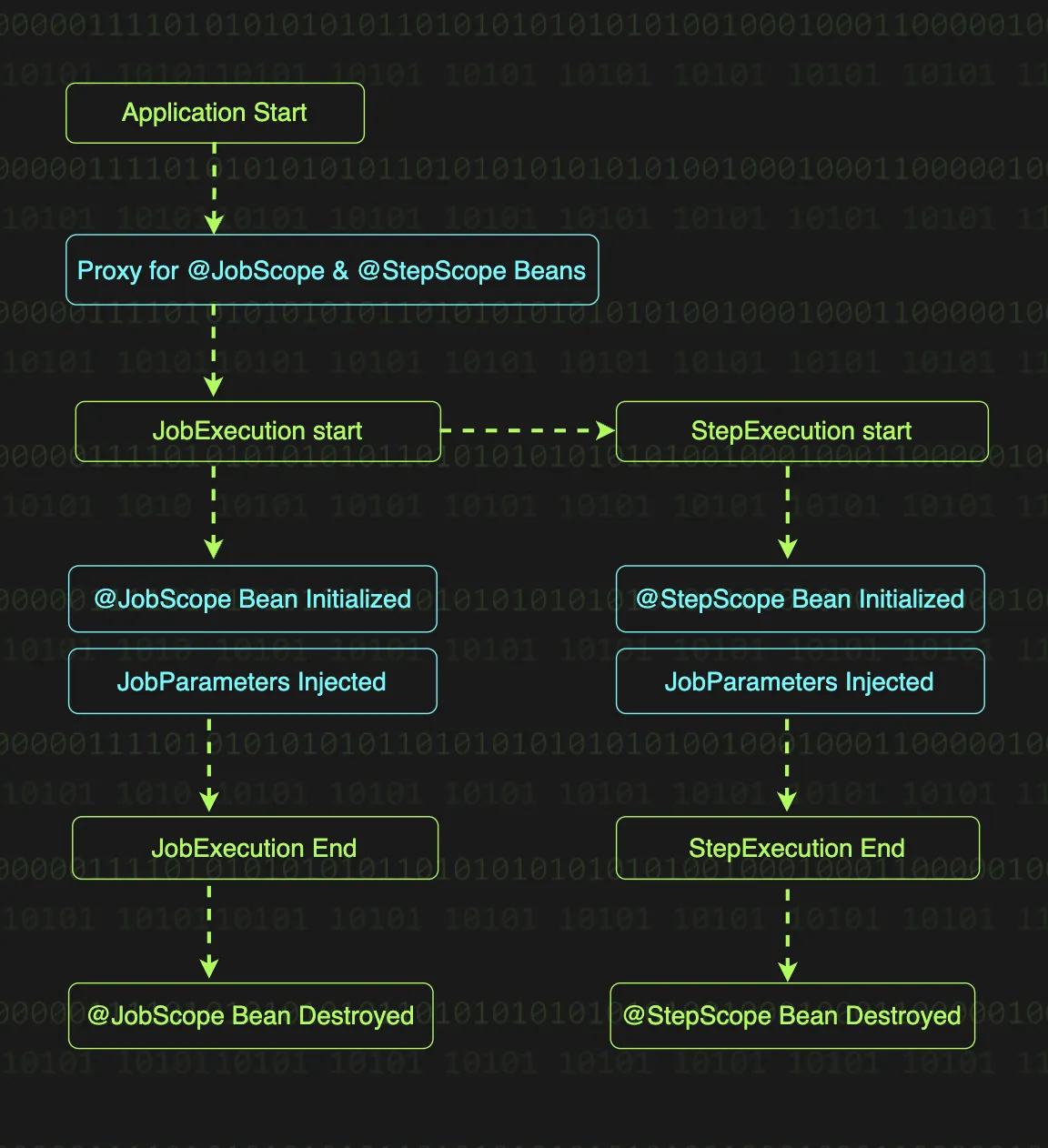
위 그림은 JobScope와 StepScope의 생명 주기를 보여주는데, 각각의 스코프 빈은 Job과 Step의 실행(Execution) 시점에 생성되고 종료 때 함께 소멸된다. 이렇게 프록스 객체를 통해 주입 받는 시점을 지연시키는 것으로 다음과 같은 이점을 얻을 수 있다.
•
런타임에 결정되는 JobParameters를 실행 시점에 주입 받을 수 있다.
•
동시에 여러 Job이 실행되더라도 각각 독립적인 빈을 사용하게 되어 동시성 문제가 해결된다.
•
Job이나 Step의 실행이 끝나면 빈도 함께 제거되어 리소스 관리 측면에서 효율적이다.
@JobScope
@JobScope는 Job이 실행될 때 실제 빈이 생성되고 Job이 종료될 때 함께 제거되는 스코프이다. 즉, JobExecution과 생명주기를 같이 한다는 의미이고, 이는 웹 요청이 들어올 때 빈이 생성되고 응답 나갈 때 제거되는 Spring MVC의 @RequestScope와 비슷한 개념이라 볼 수 있다.
@Bean
@JobScope
fun scopeStep(
@Value("#{jobParameters['stepParam']}") stepParam: String,
): Step {
return StepBuilder("scopeStep", jobRepository)
.tasklet({ contribution, chunkContext ->
log.info("This is scope step. stepParam = {}", stepParam)
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
Kotlin
복사
위 코드를 보면 @JobScope가 선언되어있는데, 이로 인해 다음과 같은 영항이 발생한다.
•
지연된 빈 생성 : @JobScope가 적용된 빈은 애플리케이션 구동 시점에는 프록시 객체만 생성되고, 실제 Job이 실행될 때 인스턴스가 생성된다.
•
Job 파라미터와의 연동 : 지연된 빈 생성이 가능하다보니, 애플리케이션 실행 중에 전달되는 JobParameters를 Job 실행 시점에 생성되는 실제 인스턴스에 주입해주는게 가능하다. 커맨드라인으로 실행시키면 이 부분이 잘 와닿지 않을 수 있지만, REST API를 통해 배치를 실행하는 경우를 생각해보자. 이 경우에는 @JobScope가 없다면 Step은 애플리케이션 구동 시점에 생성되어 파라미터를 주입해줄 수 없다.
•
병렬 처리 지원 : 동시에 여러 요청이 같은 배치 Job을 서로 다른 파라미터로 실행시킨다고 하면, @JobScope를 통해 각각의 요청에 따라 시작된 Job 실행은 서로 다른 JobExecution을 가진다. 하지만 @JobScope가 없다면 각각의 Job을 실행하는 여러 스레드가 동일한 Tasklet 빈을 공유하게되고, Tasklet의 인스턴스 상태를 동시에 접근하면서 동시성 이슈가 발생할 수 있다.
@StepScope
@StepScope는 기본적으로 @JobScope와 동일한 방식으로 동작하지만, 적용 범위에서 차이가 있다. @JobScope가 Job의 실행 범위에서 빈을 관리한다면, @StepScope는 Step의 실행 범위에서 빈을 관리한다.
@Bean
@StepScope
fun scopeTasklet(
@Value("#{jobParameters['taskletParam']}") taskletParam: String,
) = Tasklet { contribution, chunkContext ->
log.info("This is scope tasklet. taskletParam = {}", taskletParam)
RepeatStatus.FINISHED
}
Kotlin
복사
위 코드는 @StepScope가 선언되어있는데, 이를 통해 위 Tasklet이 Step의 생명주기와 함께 한다는 것을 의미한다. 각각의 Step마다 새로운 scopeTasklet 인스턴스가 생성되고 Step이 종료될 때 함께 제거된다. 만약 동시에 여러 Step이 실행되더라도 @StepScope가 있기 때문에 각 Step마다 독립된 Tasklet 인스턴스가 생성되어 동시성 이슈가 발생하지 않는다. 또한 @JobScope와 동일한 개념으로, @StepScope를 선언되어있기 때문에 Step 실행 시점에 동적으로 JobParameters를 주입 받을 수 있다.
JobScope와 StepScope 주의사항
1.
프록시 대상이 클래스인 경우 반드시 상속 가능한 클래스여야 한다.
@JobScope의 정의를 살펴보면,
@Scope(value = "job", proxyMode = ScopedProxyMode.TARGET_CLASS)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface JobScope {}
Kotlin
복사
이 스코프들은 CGLIB를 사용해 클래스 기반의 프록시를 생성한다. 때문에 프록시를 생성하기 위해서는 대상 클래스가 상속 가능해야한다. 같은 맥락에서 kotlin의 data class도 사용은 가능하지만 사용하지 않는 것이 좋다.
2.
Step 빈에는 @StepScope와 @JobScope를 사용하지 말자
@Bean
@StepScope
fun dataProcessingStep(jobExecutionParameterTasklet: Tasklet): Step {
return StepBuilder("dataProcessingStep", jobRepository)
.tasklet(jobExecutionParameterTasklet, transactionManager)
.build()
}
Kotlin
복사
이처럼 Step 빈에 @StepScope를 등록하면,

이와 같은 오류가 발생한다. 오류가 발생하는 이유는 스프링 배치에서 Step을 실행하기 전에 메타데이터 관리를 위해 Step 빈에 접근하는데, 이 시점에는 아직 Step이 실행되지 않아 @StepScope가 활성화되지 않았기 때문에 오류가 발생한다. 스코프가 활성화되지 않은 상태에서 프록시 객체에 접근하려하니 시스템이 에러를 발생시키는 것이다.
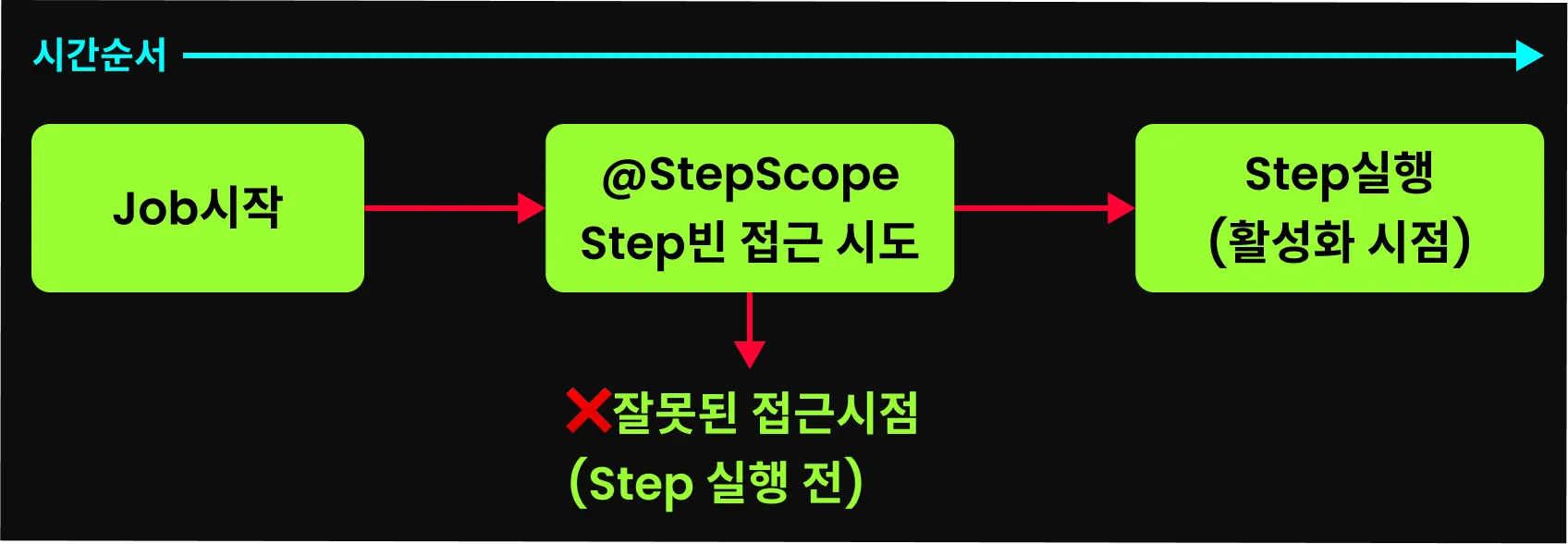
Job에 @JobScope 선언
Job 빈에 JobScope를 등록하는 경우에도 비슷한 이유로 에러가 발생한다.

추가적으로 Step 빈에 @JobScope를 사용하는 것도 권장되지 않는다. 단순한 배치에서는 문제가 없어 보일 수 있지만, JobOperator를 통한 Step 실행 제어할 때나 Spring Integration(Remote Partitioning)을 활용한 배치 확장 기능 사용 시 예상치 못한 문제가 발생할 수 있다. 이는 공식 문서에도 명확히 안내가 나와있다.

@JobScope를 사용하지 못하면 JobParameters도 사용하지 못한다. 때문에 우리가 예제에서 사용한 예시인
@Bean
@JobScope
fun scopeStep(@Value("#{jobParameters['stepParam']}") stepParam: String): Step {
return StepBuilder("scopeStep", jobRepository)
.tasklet({ contribution, chunkContext ->
log.info("This is scope step. stepParam = {}", stepParam)
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
Kotlin
복사
위 코드도 Step에서 jobParameters를 처리하는게 아니라, Tasklet 클래스에서 JobParameters를 처리하게 내리고 Tasklet 클래스에 @JobScope 혹은 @StepScope를 붙이는 것이 바람직하다.
컴파일 시점에 없는 값을 어떻게 참조할 것인가?
앞선 예제 중
@Bean
@JobScope
fun scopeStep(@Value("#{jobParameters['stepParam']}") stepParam: String): Step {
return StepBuilder("scopeStep", jobRepository)
.tasklet({ contribution, chunkContext ->
log.info("This is scope step. stepParam = {}", stepParam)
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
Kotlin
복사
위 scopeStep 메서드는 String 타입의 stepParam을 입력받고 있다. 만약 JobBuilder에서 컴파일 시점에 해당 JobParameter(stepParam)이 없는데 이 scopeStep 메서드를 어떻게 참조할 수 있는 방법을 알아보자.
1.
빈 주입 방식
@Bean
fun scopeJob(scopeStep: Step) { // Spring이 빈으로 주입
return JobBuilder("scopeStep", jobRepository)
.start(scopeStep)
.build()
}
Kotlin
복사
2.
메서드 직접 호출 방식
@Bean
fun scopeJob(): Job {
return JobBuilder("scopeJob", jobRepository)
.start(scopeStep(""))
.build()
}
Kotlin
복사
위 방식 중 첫 번째인 빈 주입 방식으로 참조하는 것이 가장 깔끔한 방법이다.
하지만 직접 메서드를 호출할 필요가 있다면 두 번째 방식처럼 null 혹은 빈 문자열, 의미 없는 값을 전달한다. 컴파일 시점에는 JobParameters 값을 알 수도 없고 전달할 방법도 없기 때문에, 우선 null이나 의미 없는 값을 전달하여 당장의 코드 레벨에서의 참조를 만족시키고 이후 Job이 실행될 때 JobParameters 값으로 주입될 것이다. 이것이 스프링 배치의 지연 바인딩(late binding) 특성이다.

빈 문자열을 넣었음에도 실제 Job 실행 시점에 JobParameters가 주입되어 stepParam이 잘 입력된 것을 볼 수 있다.
ExecutionContext
스프링 배치는 JobExecution과 StepExecution을 사용하여, 배치 Job의 시작 시간, 종료 시간, 실행 상태 등의 메타데이터를 관리한다. 하지만 이런 기본적인 실행 정보만으로는 시스템을 완벽하게 제어하기 부족할 때가 있다. 비즈니스 로직 처리 중에 발생하는 커스텀 데이터를 관리할 방법이 필요한데, 이 때 ExecutionContext라는 데이터 컨테이너를 사용한다.
ExecutionContext를 활용하면 커스텀 컬렉션의 마지막 처리 인덱스나 집계 중간 결과물 등의 데이터를 저장할 수 있다. 이는 특히 Job이 중단되었다가 재시작이 된 경우 유용한데, 스프링 배치가 Job 재시작 시 ExecutionContext의 데이터를 자동으로 복원하여 중단된 지점부터 처리를 이어갈 수 있기 때문이다.
스프링 배치는 JobExecution, StepExecution과 마찬가지로, ExectuionContext도 메타데이터 저장소에 보관하여 관리한다. 이를 통해 모든 상태 정보를 안전하게 보존할 수 있다.
ExectuionContext 사용하기
이제 JobScope와 StepScope 내에서 ExecutionContext의 데이터에 접근하는 방법을 알아보자.
@Bean
@JobScope
fun scopeStep(
// JobExecution의 ExecutionContext에서 이전 시스템의 상태를 주입 받는다.
@Value("#{jobExecutionContext['previousSystemState']}") previousSystemState: String,
): Step {
...
}
@Bean
@StepScope
fun scopeTasklet(
// StepExecution의 ExecutionContext에서 이전 시스템의 상태를 주입 받는다.
@Value("#{stepExecutionContext['currentSystemState']}") currentSystemState: String,
) = Tasklet { contribution, chunkContext ->
...
}
Kotlin
복사
ExecutionContext의 데이터 역시 JobParameters처럼 @Value를 통해 주입 받을 수 있는데, 위 코드의 jobExecutionContext와 stepExecutionContext는 서로 다른 범위를 가진다. Job의 ExecutionContext는 Job에 속한 모든 컴포넌트에서 접근 가능하지만, Step의 ExecutionContext는 오직 해당 Step에 속한 컴포넌트에서만 접근할 수 있다. 반대로 말하면 Step의 ExecutionContext에 저장된 데이터는 @Value(”#{jobExecutionContext[’key’]}”)로 접근하거나 가져올 수 없고, 다른 Step에서도 접근하거나 가져올 수 없다.
스프링 배치가 Step의 ExecutionContext의 접근을 엄격하게 제한하는 이유는 Step 간의 데이터 독립성을 완벽하게 보장하기 위해서이다. 만약 이전 Step의 처리 결과를 다음 Step에서 활용하고 싶다면, Job 수준의 ExecutionContext는 서로 다른 Step에서도 공유할 수 있으니 이 방법을 통해 해결할 수 있다.
Spring Batch Listener
리스너는 배치 처리 중 발생하는 특정 이벤트를 감지하고 원하는 로직을 실행할 수 있게 해주는 강력한 도구이다. Job의 시작 전후, Step의 시작 전후는 물론, 청크 단위 또는 아이템 단위 처리 시점까지 모든 과정에 개입할 수 있고, 이를 통해 모니터링, 로깅, 에러 처리 등 우리가 원하는 로직을 자유롭게 추가할 수 있다.
스프링 배치의 여러 리스너들
먼저 스프링 배치에서 제공하는 리스너의 종류에 대해서 알아보자.
JobExecutionListener
JobExecutionListener는 Job의 실행의 시작과 종료 시점에 호출되는 리스너 인터페이스이다.
public interface JobExecutionListener {
default void beforeJob(JobExecution jobExecution) { }
default void afterJob(JobExecution jobExecution) { }
}
Java
복사
인터페이스를 보면 beforeJob과 afterJob 두 개의 메서드를 통해 리스너에 동작을 추가할 수 있는 것을 알 수 있다.
•
beforeJob : Job 실행 직전에 호출되며, Job 시작 전 필요한 리소스를 준비하는 등의 초기화 작업을 수행할 수 있다.
•
afterJob : Job 실행 직후에 호출되며, Job 실행 결과를 이메일로 전송하거나 Job이 끝난 후 리소스를 정리하는 등의 부가 작업을 수행할 수 있다. 또한 Job의 실행 정보가메타데이터 저장소에 저장되기 직전에 호출되기 때문에, 이를 활용하면 특정 조건에 따라 실행된 Job의 상태를 변경할 수 있다.
StepExecutionListener
StepExecutionListener는 Step 실행의 시작과 종료 시점에 호출되는 리스너 인터페이스이다.
public interface StepExecutionListener extends StepLister {
default void beforeStep(StepExecution stepExecution) { }
@Nullable
default ExitStatus afterStep(StepExecution stepExecution) { return null }
}
Java
복사
Step의 시작 시간, 종료 시간, 처리된 데이터 수를 로그로 기록하는 등의 사용자 정의 작업을 추가할 수 있다.
ChunkListener
ChunkListener는 청크 지향 처리에서 하나의 청크 단위가 시작 되기 전, 완료 후, 실행 도중 에러가 발생했을 때 호출되는 리스너 인터페이스이다.
public interface ChunkListener extends StepListener {
default void beforeChunk(ChunkContext context) { }
default void afterChunk(ChunkContext context) { }
default void afterChunkError(ChunkContext context) { }
}
Java
복사
각 청크의 현황을 모니터링하거나 로깅하는데 사용할 수 있다. 여기서 afterChunk는 트랜잭션이 커밋된 후에 호출되지만, 청크 처리 도중 예외가 발생하면 트랜잭션이 롤백된 후 afterChunkError가 호출된다.
Item[Reader | Processor | Writer]Listener
ItemReaderListener와 ItemProcessorListener, ItemWriterListener는 각각 아이템의 읽기, 처리, 쓰기 작업이 수행되는 시점에 호출되는 리스너 인터페이스들이다.
public interface ItemReadListener<T> extends StepListener {
default void beforeRead() { }
default void afterRead(T item) { }
default void onReadError(Exception ex) { }
}
public interface ItemProcessListener<T> extends StepListener {
default void beforeProcess(T item) { }
default void afterProcess(T item, @Nuallable S result) { }
default void onProcessError(T item, Exception ex) { }
}
public interface ItemWriteListener<T> extends StepListener {
default void beforeWrite(Chunk<? extends S> items) { }
default void afterWrite(Chunk<? extends S> items) { }
default void onWriteError(Exception ex, Chunk<? extends S> items) { }
}
Java
복사
각 리스너의 메서드 이름에서 알 수 있듯, 아이템 단위의 처리 전후와 에러 발생 시점에 호출된다.
•
ItemReadListener : afterRead는 itemReader.read() 호출 후에 호출되지만, ItemReader.read()가 더 읽을게 없어 null을 반환하면 호출되지 않는다.
•
ItemProcessListener : afterProcess는 ItemProcessor.process() 메서드가 null을 반환하더라도 호출된다.(null을 반환한다는건 필터링 하겠다는 의미)
•
ItemWriteListener : afterWrite는 트랜잭션이 커밋되기 전, 그리고 ChunkListener.afterChunk()가 호출되기 전에 호출된다.
각 리스너 호출 플로우
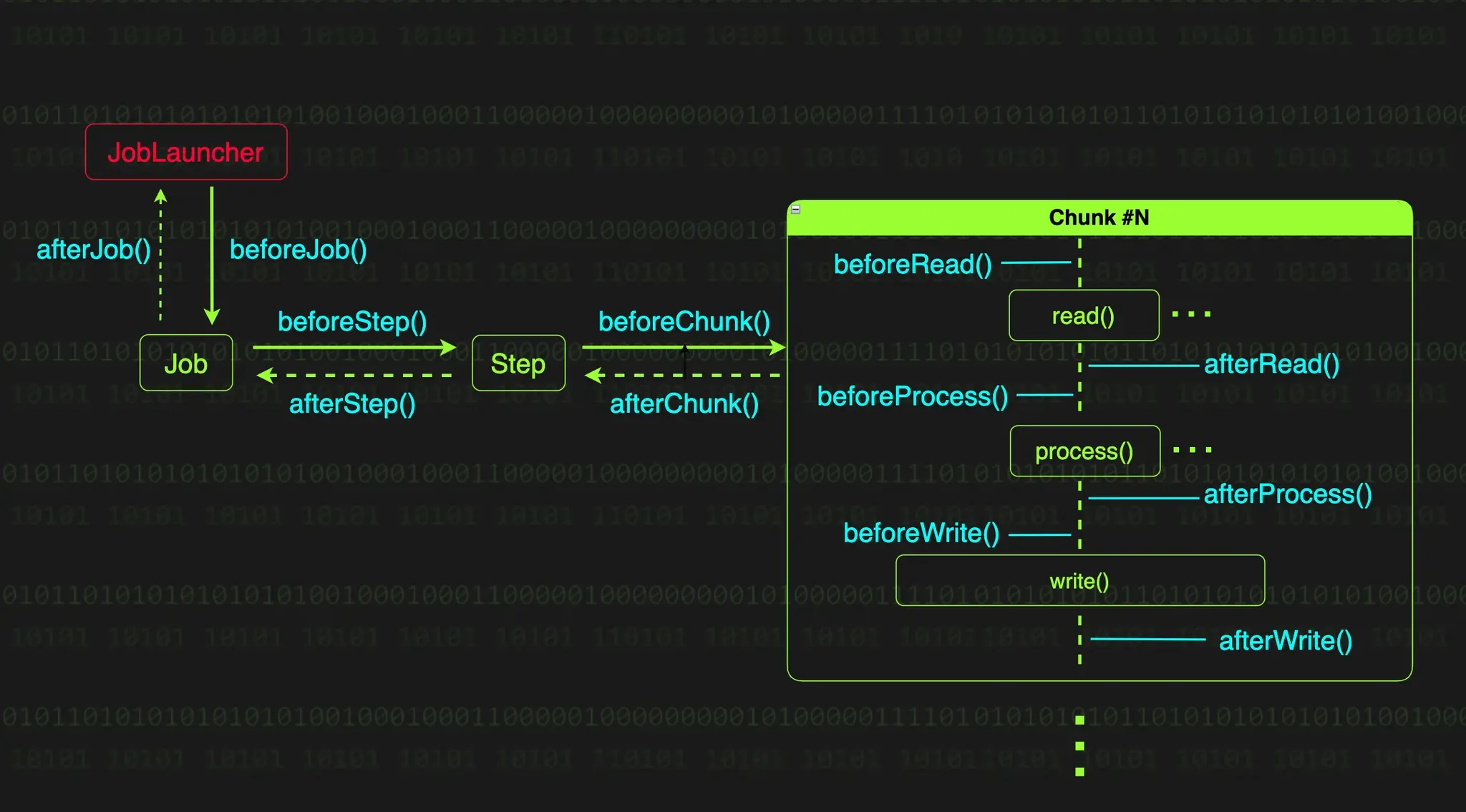
위 다이어그램을 보면 각각의 리스너가 언제 어떤 순서로 호출되는지 한눈에 보일 것이다.
리스너 활용하기
•
단계별 모니터링과 추적 : 배치 작업에서 언제 시작하고 언제 끝났는지, 몇 개의 데이터를 처리했는지 등 기록하고 추적할 수 있다.
•
실행 결과에 따른 후속 처리 : Job과 Step의 실행 상태를 리스너에 직접 확인하고 상태에 따른 후속 조치를 할 수 있다.
•
데이터 가공 및 전달 : 실제 처리 로직 전후에 데이터를 정제하거나 변환할 수 있다. StepExecutionListener나 ChunkListener를 사용해 ExecutionContext의 데이터를 수정하거나 필요한 정보를 추가할 수 있다. 이를 통해 Step 간 데이터를 전달하거나, 다음 처리에 필요한 정보를 미리 준비할 수 있다.
•
부가 기능 분리 : 주요 처리 로직과 부가 로직을 깔끔하게 분리할 수 있다. ChunkListener에서 오류가 발생한 경우 afterChunkError 메서드를 통해 관리자에게 알림을 보내는 등 부가적인 일에 대한 로직을 분리할 수 있다.
배치 리스너 구현 방법
배치 리스너를 구현하는 방법은 전용 리스너 인터페이스를 직접 구현하거나 리스너 특화 애노테이션을 사용하는 방법이 있다.
인터페이스 구현
@Component
class MyJobExecutionListener: JobExecutionListener {
private val log = LoggerFactory.getLogger(this::class.java)
override fun beforeJob(jobExecution: JobExecution) {
log.info("JobExecutionListener - beforeJob")
}
override fun afterJob(jobExecution: JobExecution) {
log.info("JobExecutionListener - afterJob")
}
}
Kotlin
복사
@Component
class MyStepExecutionListener: StepExecutionListener {
private val log = LoggerFactory.getLogger(this::class.java)
override fun beforeStep(stepExecution: StepExecution) {
log.info("StepExecutionListener - beforeStep")
}
override fun afterStep(stepExecution: StepExecution): ExitStatus? {
log.info("StepExecutionListener - afterStep")
return ExitStatus.COMPLETED
}
}
Kotlin
복사
이처럼 인터페이스를 구현하여, 명시적이고 직관적으로 우리만의 리스너를 만들 수 있다.
@Bean
fun dataProcessingJob(dataProcessingStep: Step, myJobExecutionListener: MyJobExecutionListener): Job {
return JobBuilder("dataProcessingJob", jobRepository)
.listener(myJobExecutionListener)
.start(dataProcessingStep)
.build()
}
@Bean
fun dataProcessingStep(
jobExecutionParameterTasklet: Tasklet,
myStepExecutionListener: MyStepExecutionListener,
): Step {
return StepBuilder("dataProcessingStep", jobRepository)
.listener(myStepExecutionListener)
.tasklet(jobExecutionParameterTasklet, transactionManager)
.build()
}
Kotlin
복사
구현한 리스너는 이와 같이 Job과 Step의 Builder에서 등록할 수 있다.
애노테이션 기반 구현
스프링 배치에서 제공하는 @BeforeJob, @AfterJob, @BeforeStep, @AfterStep과 같은 리스너 특화 애노테이션을 사용하면 리스너 기능을 훨씬 간단하게 구현할 수 있다.
@Component
class MyJobExecutionListener {
private val log = LoggerFactory.getLogger(this::class.java)
@BeforeJob
fun beforeJob(jobExecution: JobExecution) {
log.info("JobExecutionListener - beforeJob")
}
@AfterJob
fun afterJob(jobExecution: JobExecution) {
log.info("JobExecutionListener - afterJob")
}
}
@Component
class MyStepExecutionListener {
private val log = LoggerFactory.getLogger(this::class.java)
@BeforeStep
fun beforeStep(stepExecution: StepExecution) {
log.info("StepExecutionListener - beforeStep")
}
@AfterStep
fun afterStep(stepExecution: StepExecution): ExitStatus? {
log.info("StepExecutionListener - afterStep")
return ExitStatus.COMPLETED
}
}
Kotlin
복사
이처럼 애노테이션 방식을 통하여 리스너를 간단하게 구현할 수 있다. 애노테이션 방식은 애노테이션만 달면 되기 때문에 반환 타입을 놓치기 쉬운데, @AfterStep 애노테이션을 사용할 때는 반드시 ExitStatus 반환 타입을 지켜줘야 한다는 것이다. 위에서는 Job과 Step에 관련된 애노테이션만 다루었지만, @AfterChunk, @AfterChunkError, @AfterProcess, @OnSkipInRead, @OnSkipInWrite 등 위에서 언급했던 모든 리스너를 구현 가능하다.
ExecutionContext와 ExecutionListener를 활용한 동적 데이터 전달
Step에 동적으로 데이터 전달하기
JobParameters만으로 전달할 수 없는 동적인 데이터가 필요한 경우가 있다. 이럴 때 JobExecutionListener의 beforeJob 메서드를 활용하면 동적 데이터를 각 Step에 전달할 수 있다.
@Component
class DynamicDataListener {
private val log = LoggerFactory.getLogger(this::class.java)
private val DYNAMIC_DATA_CANDIDATE1 = listOf("A", "B", "C")
private val DYNAMIC_DATA_CANDIDATE2 = listOf("1", "2", "3")
@BeforeJob
fun beforeJob(jobExecution: JobExecution) {
// 동적 데이터 주입
val randomData1 = DYNAMIC_DATA_CANDIDATE1.shuffled().first()
val randomData2 = DYNAMIC_DATA_CANDIDATE2.shuffled().first()
jobExecution.executionContext.put("dynamicData1", randomData1)
jobExecution.executionContext.put("dynamicData2", randomData2)
log.info("DynamicDataListener - beforeStep : dynamic data injected - dynamicData1 = {}, dynamicData2 = {}", randomData1, randomData2)
}
}
Kotlin
복사
이와 같이 beforeJob에서 데이터를 동적으로 넣어준다면,
@Configuration
class DynamicDataProcessConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
) {
private val log = LoggerFactory.getLogger(this::class.java)
@Bean
fun dynamicDataProcessJob(
dynamicDataProcessFirstStep: Step,
dynamicDataProcessSecondStep: Step,
dynamicDataListener: DynamicDataListener
): Job {
return JobBuilder("dynamicDataProcessJob", jobRepository)
.listener(dynamicDataListener)
.start(dynamicDataProcessFirstStep)
.next(dynamicDataProcessSecondStep)
.build()
}
@Bean
fun dynamicDataProcessFirstStep(): Step {
return StepBuilder("dynamicDataProcessFirstStep", jobRepository)
.tasklet({ contribution, chunkContext ->
val data = chunkContext.stepContext.jobExecutionContext["dynamicData1"]
log.info("This is dynamic data process first step. dynamicData1 = {}", data)
org.springframework.batch.repeat.RepeatStatus.FINISHED
}, transactionManager)
.build()
}
@Bean
@JobScope
fun dynamicDataProcessSecondStep(
@Value("#{jobExecutionContext['dynamicData2']}") dynamicData2: String?,
): Step {
return StepBuilder("dynamicDataProcessSecondStep", jobRepository)
.tasklet({ contribution, chunkContext ->
log.info("This is dynamic data process second step. dynamicData2 = {}", dynamicData2)
org.springframework.batch.repeat.RepeatStatus.FINISHED
}, transactionManager)
.build()
}
}
Kotlin
복사
각 Step에서 람다식의 chunkContext나 @Value를 통해서 주입된 JobExecutionContext의 동적 데이터를 꺼내서 사용할 수 있다.

실행을 시켜보면, 값을 잘 전달한 것을 확인할 수 있다.
JobParameters 대신 ExecutionContext
위의 예제에서 JobParameters 대신 ExcecutionContext를 사용하는 이유는, 한 번 생성된 JobParameters는 변경할 수 없기 때문이다. 스프링 배치에서는 배치 작업의 재현 가능성(Repeatability)과 일관성(Consistency)을 보장하는 것이 핵심 철칙이다. 이를 위해 JobParameters가 불변하게 설계되었다.
•
재현 가능성 : 동일한 JobParameters로 실행한 Job은 항상 동일한 결과를 생성해야한다. 실행 도중에 JobParameters가 변경되면 이를 보장할 수 없다.
•
추적 가능성 : 배치 작업의 실행 기록(JobInstance, JobExecution)과 JobParameters는 메타데이터 저장소에 보관된다. JobParameters가 변경 가능하다면 기록과 실제 작업의 불일치가 발생할 수 있다.
이러한 이유로 Job 실행 중에 동적으로 생성되거나 변경이 필요한 데이터는 ExecutionContext를 통해 관리하는 것이 좋다.
JobExecutionListener와 ExecutionContext를 사용해 데이터를 전달하는 방법은 유용하고 강력하다. 하지만 JobParameters만으로 충분히 처리할 수 있음에도 이 방법을 사용하는 것은 바람직하지 않다.
override beforeJob(jobExecution: JobExecution) {
jobExecution.getExecutionContext().put("targetDate", LocalDate.now())
}
Kotlin
복사
이 방식은 재현 불가능한 배치 처리 방식이다. 프로그램을 수정하지 않는다면 내일 똑같이 호출해도 전혀 다른 결과가 발생한다. 이러한 처리 방식은 배치의 유연성을 떨어뜨리고 필요한 순간에 데이터를 처리할 수 없게 만든다.
--spring.batch.job.name=dynamicDataProcessJob tragetDate="2025-10-06"
Shell
복사
대신 이처럼 JobParameters로 넘겨 외부에서 데이터를 받을 수 있게 만들면, 배치의 유연성을 제대로 활용할 수 있다.
StepExecutionContext 간의 데이터 공유와 ExecutionContextPromotionListener
위의 예제를 통해 Job 수준의 ExecutionContext를 통해 동적 데이터를 전달하는 방법에 대해 알게 되었다. Job 수준의 ExecutionContext는 Job 내 모든 Step에서 접근할 수 있다. 하지만 Step 수준의 ExecutionContext에 저장된 데이터는 해당 Step에서만 접근 가능하고, 다른 Step과의 공유는 불가능하다.
val stepExecution = contribution.stepExecution
val contextData = stepExecution.executionContext["dynamicData"]
stepExecution.jobExecution.executionContext.put("dynamicData", contextData)
Kotlin
복사
다른 Step과 데이터를 공유하고 싶다면, 위처럼 공유하고 싶은 모든 데이터를 Step 수준의 ExecutionContext에 있는 데이터를 Job 수준의 ExecutionContext로 올려주어야 한다. 코드도 지저분하고, 이 과정 자체도 매우 불편하게 느껴진다. 스프링 배치에서는 이러한 반복적인 불편한 과정을 해결하기 위해 ExecutionContextPromotionListener라는 StepExecutionListener 구현체를 제공한다.
ExecutionContextPromotionListener
ExectuionContextPromotionListener는 Step 수준의 ExecutionContext의 데이터를 Job 수준의 ExecutionContext에 등록시켜주는 StepExecutionListener의 구현체이다. Step 수준의 데이터를 Job 수준의 데이터로 옮기는 것을 승격(Promote)이라 부르고, 이 과정을 처리해주는 리스너가 PromotionListener인 것이다.
@Bean
fun promotionListener(): ExecutionContextPromotionListener {
return ExecutionContextPromotionListener().apply {
setKeys(arrayOf("randomData"))
}
}
Kotlin
복사
먼저 PromotionListener를 빈으로 등록해주고,
@Bean
fun dynamicDataProcessFirstStep(): Step {
return StepBuilder("dynamicDataProcessFirstStep", jobRepository)
.tasklet({ contribution, chunkContext ->
val randomData = Random.nextInt(1000)
contribution.stepExecution.executionContext.put("randomData", randomData)
log.info("This is dynamic data process first step. randomData = {}", randomData)
RepeatStatus.FINISHED
}, transactionManager)
.listener(promotionListener())
.build()
}
@Bean
@JobScope
fun dynamicDataProcessSecondStep(
@Value("#{jobExecutionContext['randomData']}") randomData: Int?,
): Step {
return StepBuilder("dynamicDataProcessSecondStep", jobRepository)
.tasklet({ contribution, chunkContext ->
log.info("This is dynamic data process second step. randomData = {}", randomData)
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
@Bean
fun dynamicDataProcessingThirdStep(): Step {
return StepBuilder("dynamicDataProcessingThirdStep", jobRepository)
.tasklet({ contribution, chunkContext ->
val data = chunkContext.stepContext.jobExecutionContext["randomData"]
log.info("This is dynamic data process third step. randomData = {}", data)
RepeatStatus.FINISHED
}, transactionManager)
.build()
}
Kotlin
복사
위처럼 Step 단계에서 데이터를 넣어준 후 promotionListener를 등록하면, 자동으로 Job 수준의 ExecutionContext로 올려줘서 이후의 Step에서 데이터를 꺼내서 사용할 수 있게 된다.
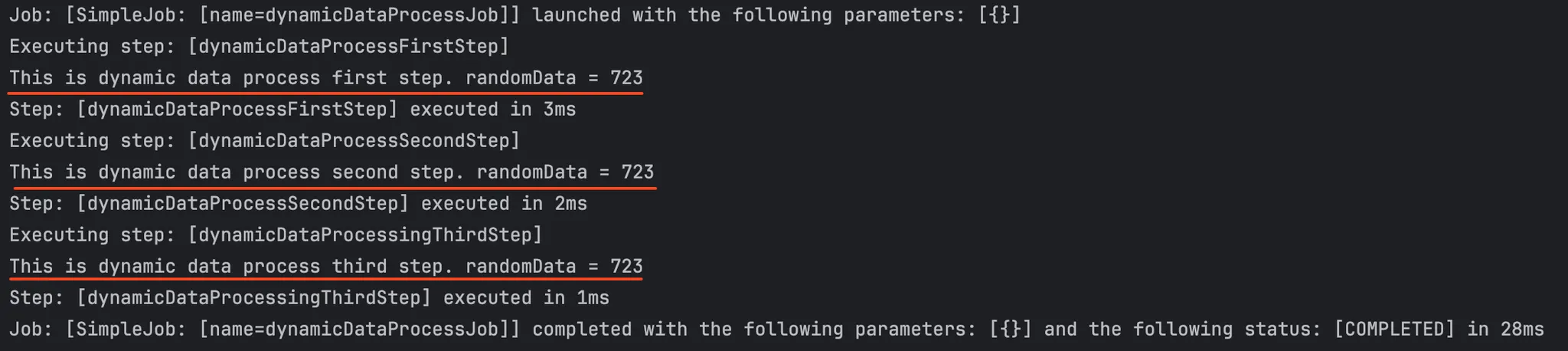
Step 간에 이런 방식으로 데이터를 공유할 수 있지만, 각 Step은 가능한 독립적으로 설계해 재사용성과 유지보수성을 높이는 것이 좋다. 불가피한 경우가 아니라면 Step간 데이터 의존성은 최소화하는 것이 좋다. Step 간 데이터 공유가 늘어날수록 의존과 복잡도가 증가하게 된다.
Listener와 @JobScope, @StepScope 통합
리스너와 스프링 배치 스코프를 통합하면 리스너에서 JobParameters를 매우 쉽게 다룰 수 있다. 이를 통해 실행 시점에 결정되는 값들을 리스너 내부에서도 가져올 수 있게 된다는 의미이다.
@Bean
@JobScope
fun scopeIntegrationListener(
@Value("#{jobParameters['listenerParam']}") listenerParam: String,
): JobExecutionListener {
return object: JobExecutionListener {
override fun beforeJob(jobExecution: JobExecution) {
log.info("This is scope listener. listenerParam = {}", listenerParam)
}
override fun afterJob(jobExecution: JobExecution) {
log.info("This is scope listener after job.")
}
}
}
Kotlin
복사
리스너에 붙은 애노테이션을 보면 @JobScope 애노테이션이 선언되어있는데, JobExecutionListener는 Job의 실행(JobExecution)과 생명주기를 함께하기 때문에 @StepScope 대신 @JobScope를 선언한다.
Listener 성능과 모범 사례
리스너를 효율적으로 사용하기
1.
적절한 리스너 선택하기 : 사용의 목적과 범위에 따라 적절한 리스너를 선택하는 것이 중요하다.
•
JobExecutionListener : 전체 Job 범위의 시작과 종료 시 처리 필요한 경우
•
StepExecutionListener : 각 Step 단계마다 처리가 필요한 경우
•
ChunkListener : 시스템을 청크 단위로 작업하면서, 청크 반복마다 처리가 필요한 경우
•
Item … Listener : 개별 아이템을 식별하여 처리가 필요한 경우
2.
예외 처리는 신중하게 처리하기 : JobExecutionListener의 beforeJob과 StepExecutionListener의 beforeStep에서 예외가 발생하면, Job과 Step이 실패한 것으로 판단된다. 하지만 모든 예외가 Job이나 Step을 중단 시킬만큼 치명적이지는 않으니, 경우에 따라 예외를 직접 잡아서 무시하고 진행하는 것도 현명한 방법일 수 있다.
JobExecutionListener의 afterJob과 StepExecutionListener의 afterStep에서 예외가 발생하면 무시된다. 다시말해, 예외가 발생해도 Job과 Step의 결과에 영향을 미치지 않는다.
3.
단일 책임 원칙 준수 : 리스너는 감시와 통제만 담당하며, 실제 비즈니스 로직은 Tasklet 구현체이나 ItemProcess 구현체로 분리하자. 리스너가 너무 많은 일을 처리하면, 유지보수가 어려워지고 시스템 동작을 파악하기 힘들어진다.
리스너 성능 최적화
1.
실행 빈도 고려하기
•
JobExecutionListener / StepExecutionListener
◦
Job, Step 실행마다 한 번씩만 호출되므로 비교적 안전
◦
무거운 로직이 들어가도 전체 성능에 큰 영향 없음
•
ItemReadListener / ItemProcessListener
◦
매 아이템마다 호출되기 때문에 성능에 치명적
◦
무거운 로직이 들어가는 경우 시스템이 마비됨
2.
리소스 사용량 최소화
•
데이터베이스 연결, 파일 I/O, 외부 API 호출 최소화
•
리스너 내 로직은 가능한 가볍게 유지
•
특히 호출이 잦은 Item 단위 리스너에서는 신경써서 로직을 더 가볍게 유지