관계형 데이터베이스 읽고 쓰기
JDBC ItemReader
웹 애플리케이션에서는 ‘일반적으로 ID가 1234인 사용자 조회’와 같이 단일 레코드를 조회한다. 하지만 배치에서는 ‘지난 달에 가입한 모든 사용자’, ‘재고 100개 미만 상품 전체 거래내역’과 같이 대량의 데이터를 한 번에 작업해야한다. 하지만 SELECT * FROM users WHERE created_at >= '2025-10-01' 쿼리를 한 번에 실행시키면 바로 OutOfMemory가 발생할 것이다.
우리는 데이터베이스를 효과적으로 다루기 위해 먼저 Jdbc의 두 가지 배치 구현체를 사용하여 처리하는 방법에 대해 알아보자.
커서 기반 처리 (JdbcCursorItemReader)
커서 기반 처리 방식은 데이터베이스와 연결을 유지한채로 데이터를 순차적으로 가져오는 방식이다. JdbcCursorItemReader가 초기화(open)될 때 지정된 SQL 쿼리를 실행하고, 그 결과를 가리키는 커서를 생성한다. 이후 read가 호출될 때마다 ResultSet.next()를 실행하여 한 행씩 데이터를 가져온다.
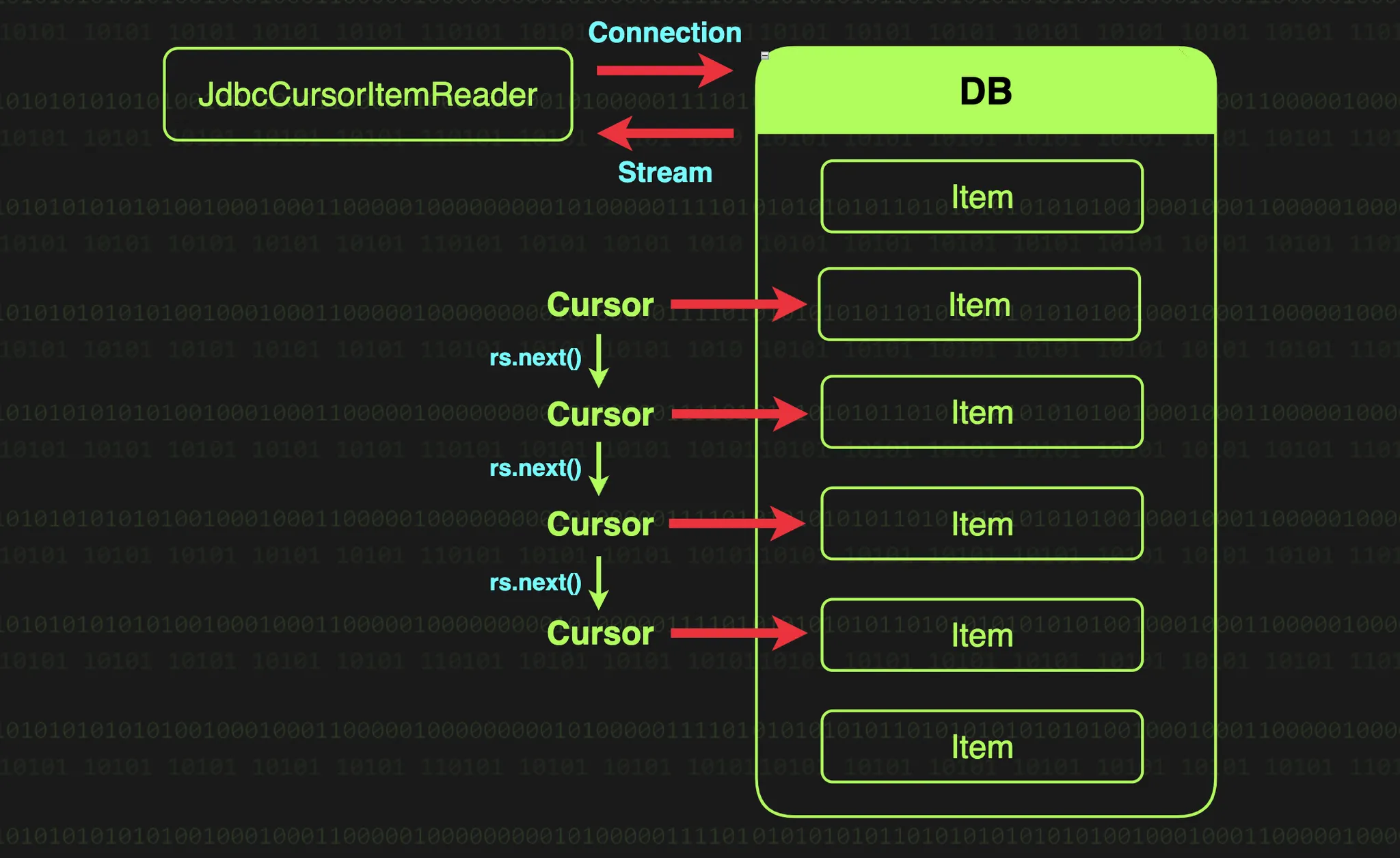
매번 쿼리를 새로 실행하는 것이 아니라, 이미 열린 ResultSet에서 커서를 이동하며 데이터를 하나씩 읽어오는 구조이다. 때문에 대량의 데이터를 한 번에 메모리에 올리지 않고도 처리할 수 있다. 하지만 데이터베이스와 연결을 유지한 채 진행되어 커넥션이 너무 오래 유지되고, JOIN이나 ORDER BY, GROUP BY 등을 사용하면 임시 테이블을 메모리에 얹어두고 있어 스왑이 발생해 성능 병목이 될 수 있다.
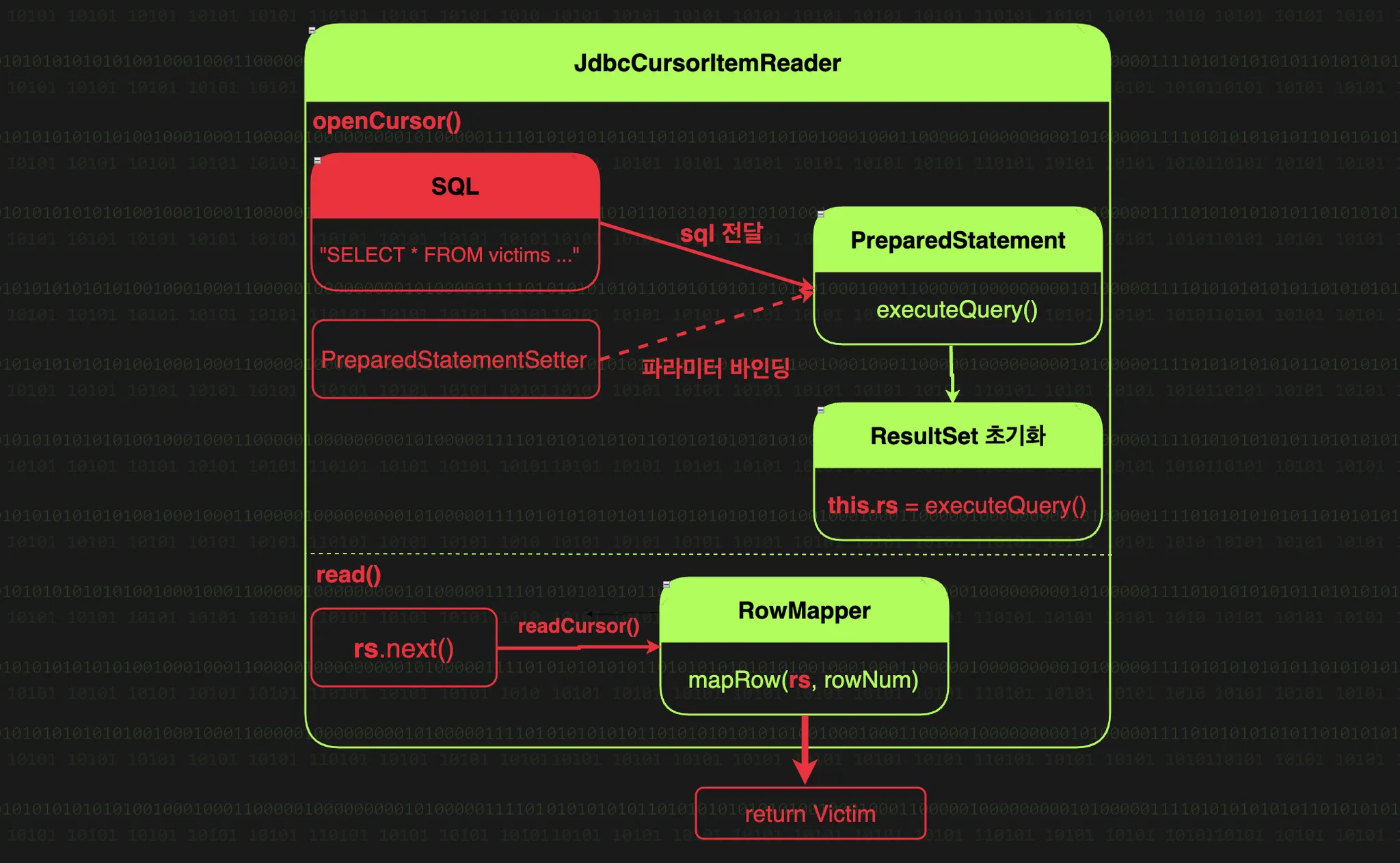
JdbcCursorItemReader 구조
JdbcCursorItemReader
│
├────── DataSource
│ └─ (DB 연결 관리)
│
├────── SQL
│ └─ (데이터 조회 쿼리)
│
├────── RowMapper
│ └─ (ResultSet → Java 객체 변환)
│
├────── PreparedStatement
│ └─ (쿼리 실행 및 결과 조회)
│
└────── PreparedStatementSetter (optional)
└─ (파라미터 동적 바인딩)
Plain Text
복사
•
DataSource : JdbcCursorItemReader가 데이터베이스의 데이터를 읽기 위해서는 먼저 연결을 해야할 것이다. DataSource가 이 연결을 담당하여, application.yml의 데이터 소스 설정을 읽어 HikariCP 기반으로 데이터 소스와 연결을 만들어준다.
•
SQL : JdbcCursorItemReader가 데이터 조회를 위해 사용할 쿼리이다.
•
rowMapper : 데이터베이스에서 가져온 ResultSet을 우리가 원하는 객체로 변환한다. 일반적이라면 다음의 3가지 구현체를 통해 사용된다.
◦
BeanPropertyRowMapper : setter 기반 매핑 방식으로, 자바빈으로 등록된 클래스를 대상으로 데이터베이스 컬럼명과 객체의 필드명이 일치하면 자동으로 매핑해준다.(스네이크케이스  카멜케이스 자동 변환)
카멜케이스 자동 변환)
카멜케이스 자동 변환)◦
DataClassRowMapper : Java Record나 Kotlin Data Class 같은 불변 객체를 위해 설계된 구현체로, 생성자 파라미터를 통해 매핑을 수행한다.(생성자에 없는 필드는 setter로 매핑)
◦
Custom RowMapper : 별도의 복잡한 변환 로직이 필요할 때 직접 구현하여 사용한다.
•
PreparedStatement(쿼리실행기) : PreparedStatement는 쿼리를 실행하고 결과를 ResultSet으로 가져오는 JDBC의 핵심 컴포넌트로, JdbcCursorItemReader는 Spring JDBC의 PreparedStatement를 통해 SQL을 실행한다.
•
PreparedStatementSetter(동적 쿼리 파라미터 주입기) : PreparedStatement에 동적으로 파라미터를 주입하는 역할을 하며, 필수가 아닌 선택사항이다. 만약 PreparedStatementSetter가 설정되어있다면, 쿼리 실행 전에 파라미터를 바인딩한다.
JdbcCursorItemReader는 이러한 컴포넌트들을 통해 데이터베이스에서 우리가 원하는 데이터를 가져온다.
JdbcCursorItemReader 구성하기
@Configuration
class JdbcItemReadConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
private val dataSource: DataSource,
) {
private val log = LoggerFactory.getLogger(this::class.java)
@Bean
fun jdbcItemReadJob(jdbcItemReadStep: Step): Job {
return JobBuilder("jdbcItemReadJob", jobRepository)
.start(jdbcItemReadStep)
.build()
}
@Bean
fun jdbcItemReadStep(
jdbcItemReader: JdbcCursorItemReader<Item>,
jdbcItemWriter: ItemWriter<Item>
): Step {
return StepBuilder("jdbcItemReadStep", jobRepository)
.chunk<Item, Item>(5, transactionManager)
.reader(jdbcItemReader)
.writer(jdbcItemWriter)
.build()
}
@Bean
fun jdbcItemReader(): JdbcCursorItemReader<Item> {
return JdbcCursorItemReaderBuilder<Item>()
.name("jdbcItemReader")
.dataSource(dataSource)
.sql("SELECT id, name, status FROM items WHERE status = ?")
.queryArguments("READY")
.beanRowMapper(Item::class.java)
.build()
}
@Bean
fun jdbcItemWriter(): ItemWriter<Item> {
return ItemWriter { items ->
items.forEach { item ->
log.info("item = {}", item)
}
}
}
}
class Item(
var id: Long? = null,
var name: String = ", // setter 주입 방식이기 때문에 기본 생성자 호출 시의 default 값 필요
var status: String = ", // setter 주입 방식이기 때문에 기본 생성자 호출 시의 default 값 필요
)
data class ImmutableItem(
private val id: Long? = null,
private val name: String,
private val status: String
)
Kotlin
복사
•
dataSource : 주입받은 dataSource를 넘겨준다.
•
sql : 원하는 아이템을 찾는 쿼리를 작성해 전달한다. 동적으로 지정할 바인딩 파라미터인 status에는 ?로 마스킹으로 작성한다.
•
queryArguments : 지정한 쿼리에 바인딩 파라미터 값을 전달해 매핑한다. 리스트, 배열, 가변인자 형태로 전달할 수 있다. 마스킹이 여러 개라면 앞에서부터 순차적으로 바인딩 된다.
•
beanRowMapper : 쿼리 결과인 ResultSet을 객체로 변환해주는 역할을 맡는다. 컬럼명과 필드명을 비교하여 자동으로 매핑한다.
◦
객체 / 불변 객체 매핑
.beanRowMapper(Item::class.java)
.beanRowMapper(ImmutableItem::class.java) // Immutable class 지원
Kotlin
복사
◦
커스텀 매핑
.rowMapper { rs, rowNum ->
Item(
id = rs.getLong("id"),
name = rs.getString("name"),
status = rs.getString("status"),
)
}
Kotlin
복사
예제 실행하기
CREATE TABLE IF NOT EXISTS items(
id BIGSERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
status VARCHAR(50) NOT NULL
);
INSERT INTO item (name, status) VALUES
('Item 1', 'READY'),
('Item 2', 'READY'),
('Item 3', 'FAILED'),
('Item 4', 'COMPLETED');
SQL
복사
먼저 테이블을 생성하고 데이터를 넣어둔다.

실행시키면 이처럼 여러 데이터 중 우리가 원하는 데이터만 읽어온 것을 확인할 수 있다.
JobParameter를 전달하지 않는 배치는, 한 번 실행 시키고 나면 이후 재실행 시에는 배치를 수행하지 않고 이전의 결과를 그대로 가져다가 사용한다. 이를 막고 싶다면 다음 코드를 추가하자.
@Bean
fun jdbcItemReadStep(
jdbcItemReader1: JdbcCursorItemReader<MutableItem>,
jdbcItemWriter1: ItemWriter<MutableItem>
): Step {
return StepBuilder("jdbcItemReadStep", jobRepository)
.chunk<MutableItem, MutableItem>(5, transactionManager)
.reader(jdbcItemReader1)
.writer(jdbcItemWriter1)
.allowStartIfComplete(true)
.build()
}
Kotlin
복사
Curor 기반 방식은 정말 한 행씩 가져올까?
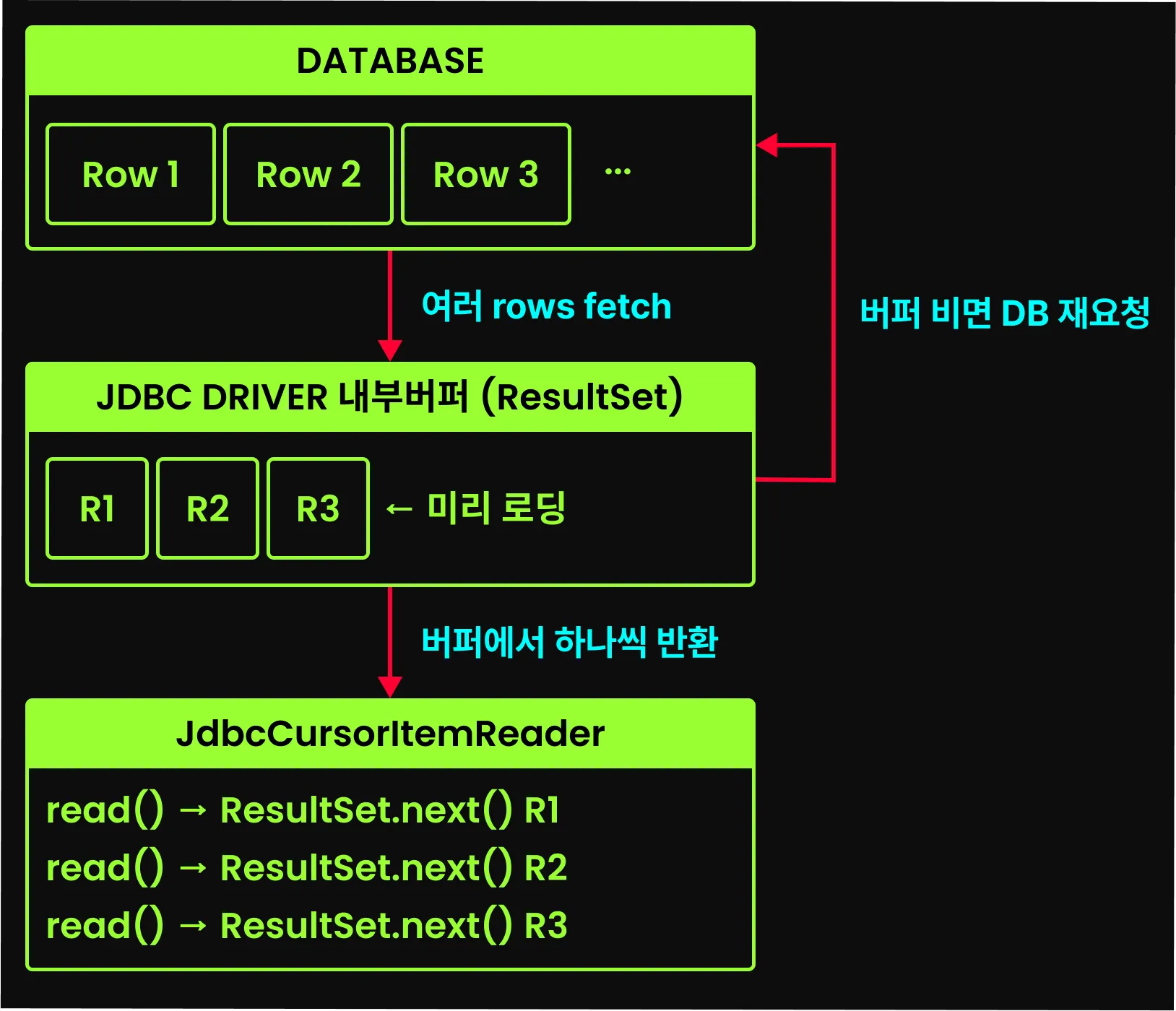
커서 기반 처리 방식은 Result.next() 호출 시 데이터베이스에서 한 행씩 가져오는 것처럼 보이는데, 이를 실제로 한 행씩 가져온다면 성능이 처참할 것이다. 때문에 Jdbc 내부적으로 여러 최적화가 되어있다.
•
ResultSet 내부 버퍼링 : JDBC 드라이버는 기본적으로 여러 개의 row를 미리 가져와 ResultSet의 내부 버퍼에 저장해둔다. 따라서 ResultSet.next()가 호출될 때마다 버퍼에서 데이터를 하나씩 꺼내어 전달하고, 버퍼에서 다음으로 줄 데이터가 없을 때 다음 데이터를 쿼리로 조회한다. 실제적으로는 여러 건을 한 번의 쿼리로 가져와 처리하는 방식이다.
•
FetchSize로 네트워크 비용 최적화 : fetchSize는 드라이버가 한 번에 가져올 row 수를 지정하는 값으로, fetchSize=1000이면 드라이버는 한 번의 네트워크 요청으로 1000건의 데이터를 가져오려 시도한다. 하지만 이 값은 JDBC 드라이버에게 주는 힌트일 뿐, 실제로 가져오는 건수는 드라이버 구현체와 데이터베이스 정책에 따라 달라질 수 있다. 이렇게 fetchSize를 통해 데이터베이스와의 네트워크 통신 횟수를 줄여 성능을 최적화할 수 있다.
MySQL 드라이버는 useCursorFetch 연결 설정이 없으면 기본적으로 쿼리의 모든 행을 한 번에 메모리로 가져온다. 조회 결과가 대용량이면 메모리 자원을 많이 차지하게 되니, 반드시 useCursorFetch=true로 설정하고 분할 로딩하자.
이전 장의 FlatFileItemReader 역시 마찬가지로, read 호출 시마다 한 줄씩 읽는게 아니라 내부적으로 BufferedReader를 사용해 최대 16KB만큼의 데이터를 버퍼에 저장해두었다가 문장 단위로 만환한다.
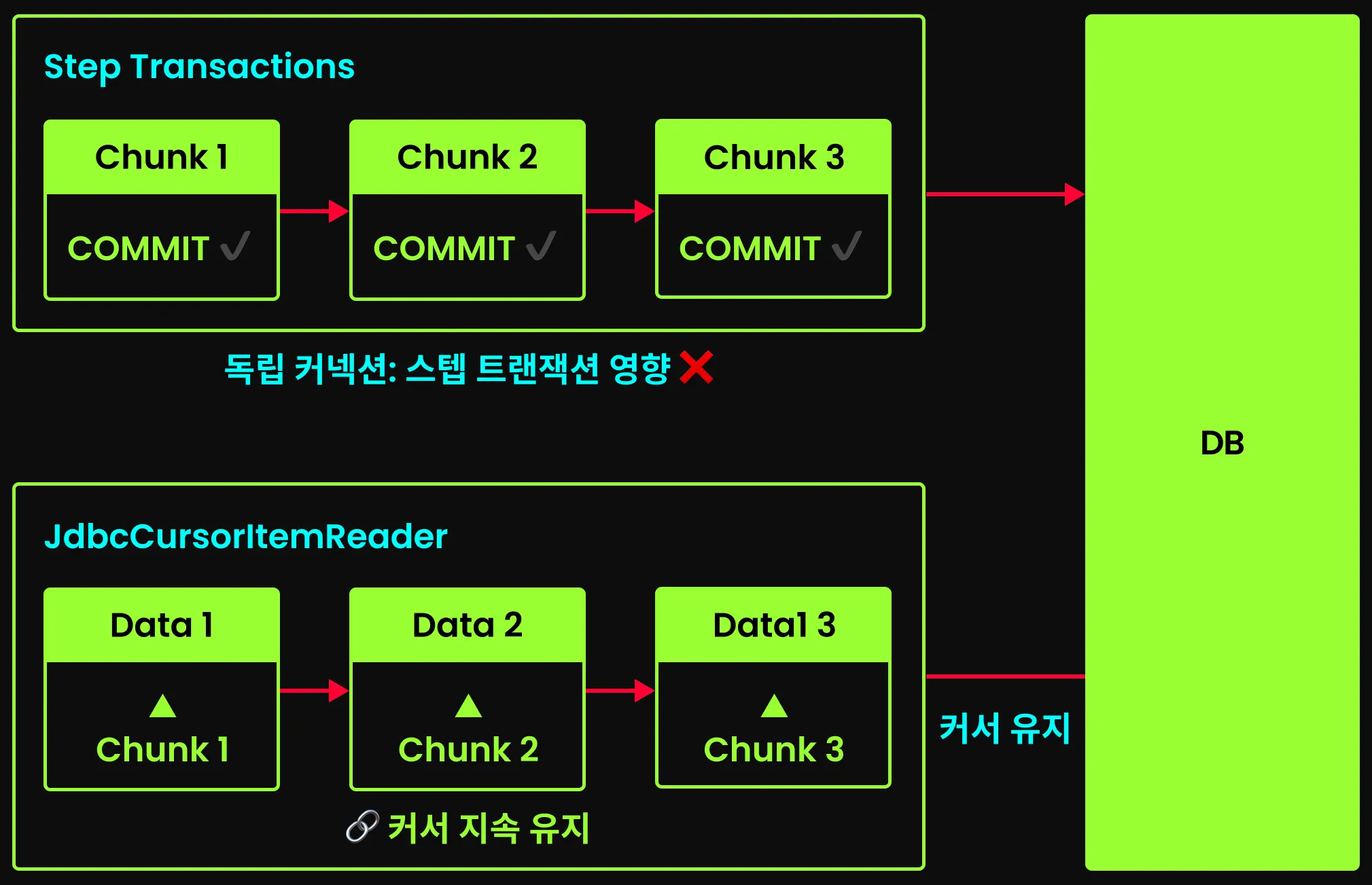
커서의 연속성과 스냅샷
청크 처리마다 트랜잭션이 새로 열리고 커밋될텐데, 커서는 어떻게 데이터를 연속적으로 읽는게 가능한지 궁금할 수 있다. 이는 JdbcCursorItemReader가 기본적으로 Step 트랜잭션과 별도의 데이터베이스 커넥션을 사용하기 때문이다. 이를 통해 Step 트랜잭션이 커밋되더라도 커서는 영향 받지 않고, 처음부터 끝까지 데이터를 연속적으로 읽을 수 있는 것이다.
또한 ItemReader가 조회하는 테이블을 ItemWriter에서 수정하는데, 커서는 그 변경된 값을 읽어오는 것은 아닐까 하는 의문이 들 것이다. 하지만 각 데이터베이스는 최초의 조회 시점에 MVCC를 통해 커서 트랜잭션의 버전을 기억하고 ItemWriter에서 변경이 발생하여 커밋된 경우 트랜잭션 번호가 달리지게 되어, 커서가 지속적으로 데이터를 읽어가더라도 변경된 데이터는 조회되지 않는 것이다.
수천만 건의 데이터를 커서로 처리하는 경우, 최초 조회 시점의 트랜잭션 ID와 데이터베이스 최신의 트랜잭션 ID 간의 차이가 극심하게 벌어지는 경우가 발생할 수 있다. 또한 ItemWriter가 아닌, 실제 사용자가 수정하는 경우에도 반영된 내용을 읽지 못한다는 문제가 있다. 이렇게 데이터가 많은 경우에는 아래에서 배울 페이징 기반 처리 방식을 사용하는 것이 권장된다.
JdbcCursorItemReader의 SQL ORDER BY 설정
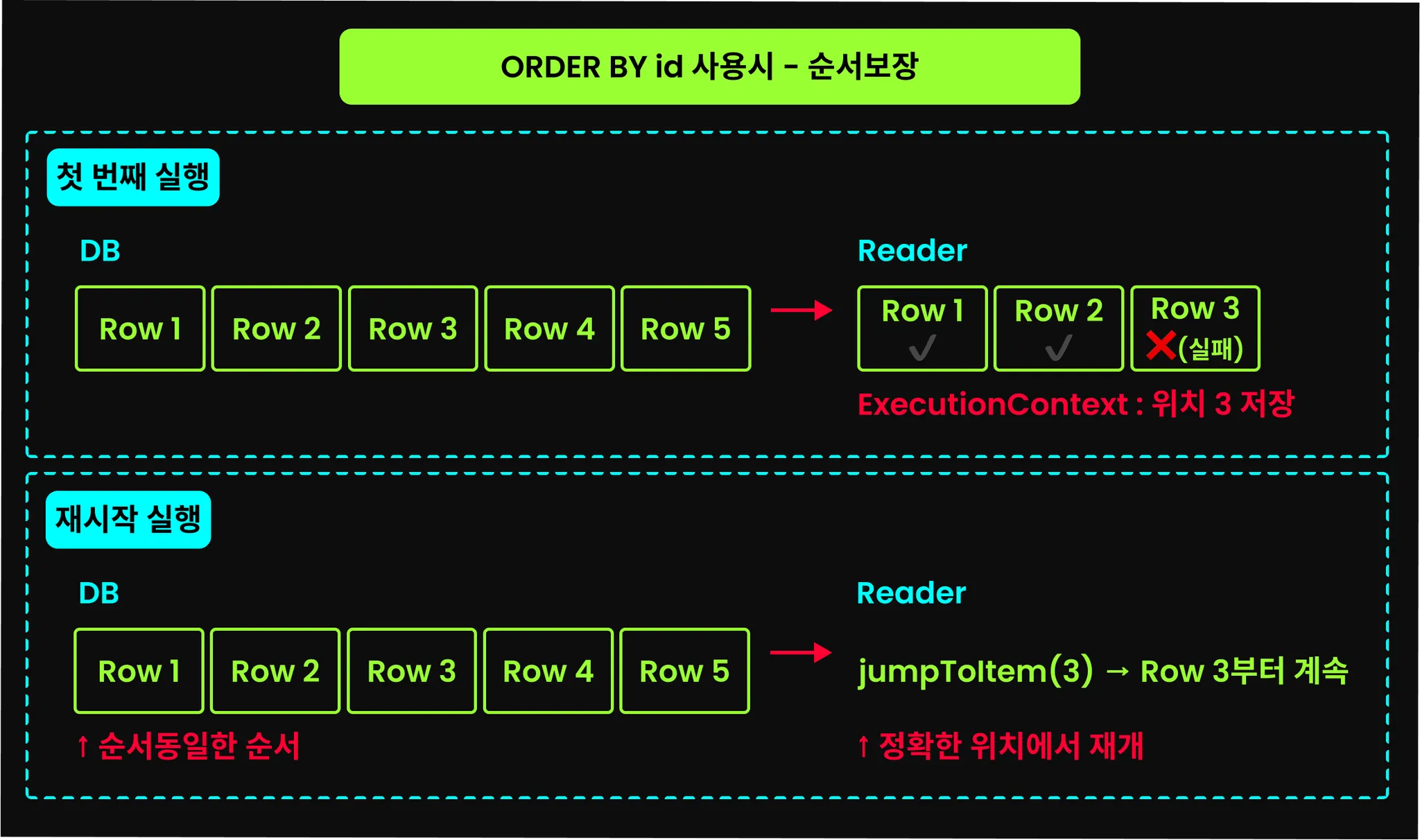
이후의 페이징 기반 처리 방식인 JdbcPagingItemReader에서도 마찬가지지만, JdbcCursorItemReader에서도 order by 절은 굉장히 중요하다. 초기화(open) 시점에 쿼리를 한 번 실행한 후 ResultSet.next를 통해 데이터를 순차적으로 가져오는데, Step이 실패해 재시작하게 되면 jumpToItem() 메서드를 호출해 커서를 이전에 실패한 지점으로 이동시킨다. 하지만 쿼리 결과의 순서가 매번 다르다면, jumpToItem으로 이동한 커서가 이전에 실패했던 그 지점임을 보장할 수 없다.
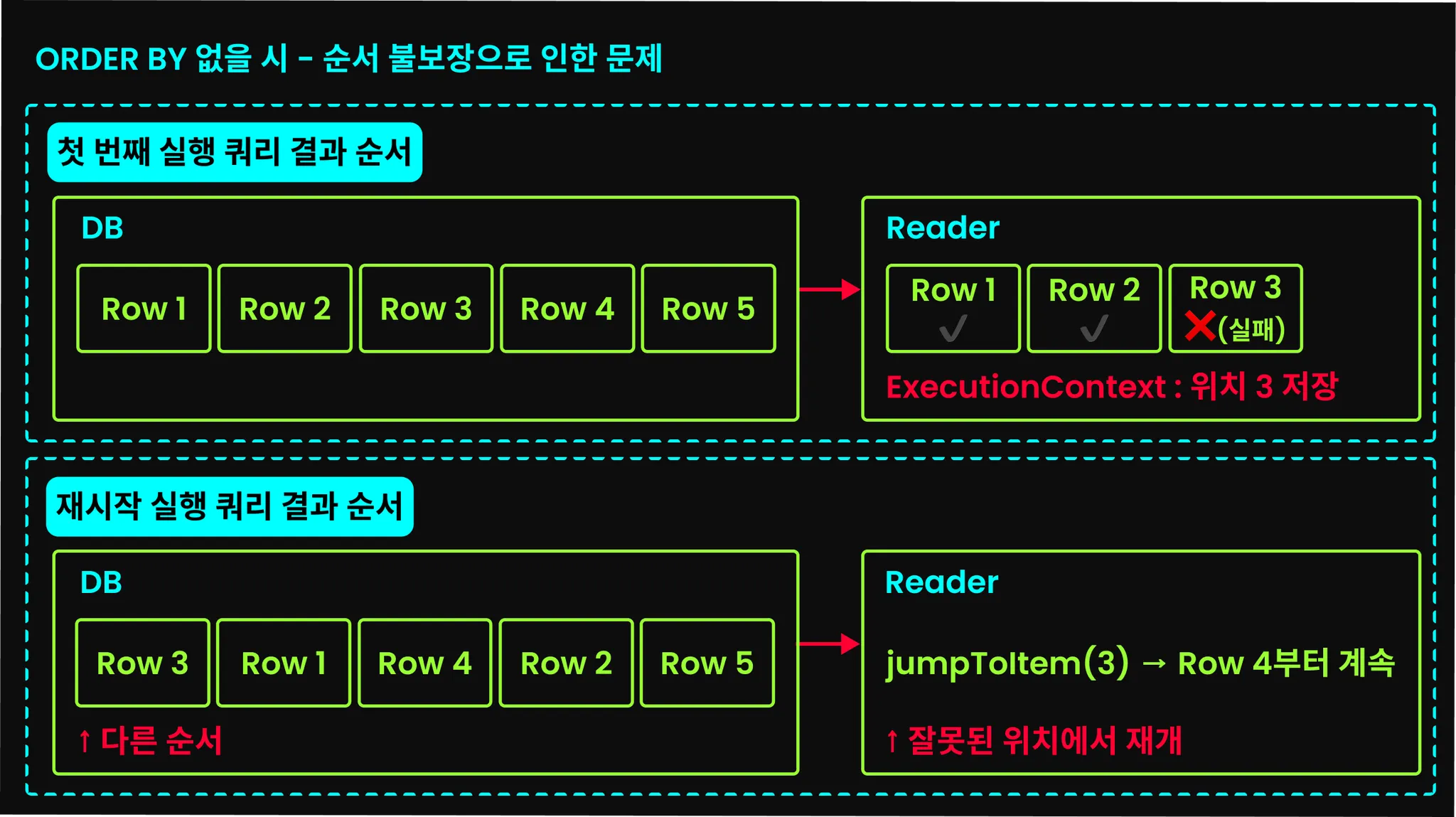
때문에 반드시 order by 절을 추가하고, 가급적 order by 절에는 유니크한 값(일반적으로 PK)을 포함하는 것이 좋다.
페이징 기반 처리 (JdbcPagingItemReader)
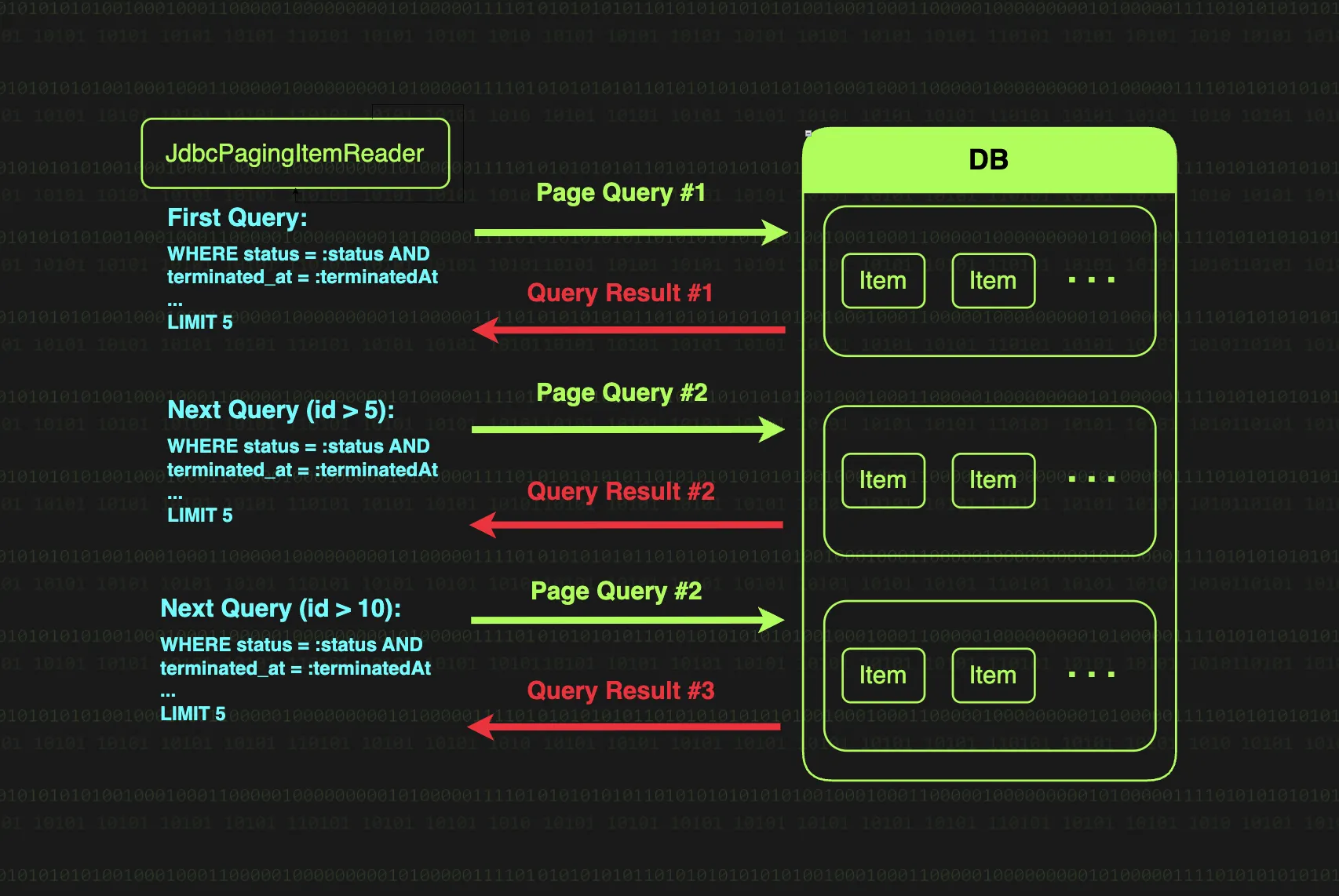
페이징 기반 처리는 대규모 데이터를 일정한 크기로 잘라서 순차적으로 가져오는 방식이다. JdbcPagingItemReader는 페이징 기반 쿼리로 데이터를 조회하는데, KeySet 기반의 페이징을 수행한다.
페이징 처리 방식
•
Offset 기반 페이징 : 데이터베이스 결과셋을 정렬한 후, OFFSET만큼 건너뛰고 LIMIT 개수만큼 데이터를 가져오는 방식이다. 이 방식은 앞에서부터 데이터를 스캔하기 때문에, OFFSET만큼의 데이터를 스맨 후 버리게 된다. 때문에 페이지 번호가 뒤로 갈수록 성능이 급격히 저하된다.
SELECT * FROM items ORDER BY id LIMIT 10 OFFSET 20
SQL
복사
•
KeySet 기반 페이징 : 이전 페이지의 마지막 키(id) 값을 기준으로 그 다음 데이터를 가져온다. 정확히 이전에 가져온 마지막 값 이후부터 읽어오기 때문에 성능이 일정하게 유지된다.
SELECT * FROM items WHERE id > 1000 ORDER BY id LIMIT 10
SQL
복사
JdbcPagingItemReader 구조
JdbcPagingItemReader
│
├────── DataSource
│ └─ (DB 연결 관리)
│
├────── RowMapper
│ └─ (ResultSet → Java 객체 변환)
│
├────── NamedParameterJdbcTemplate
│ └─ (SQL 실행 및 파라미터 바인딩)
│
└────── PagingQueryProvider
├─ (쿼리 생성 및 페이징 전략)
└─ (DB별 SQL 최적화)
Plain Text
복사
•
DataSource : 데이터베이스 연결을 담당하여, Spring Boot가 application.yml과 spring.datasource 설정을 읽어 생성한 DataSource를 사용한다.
•
RowMapper : 조회 결과를 객체로 매핑하는 역할을 한다. beanRowMapper를 사용하면 내부적으로 BeanPropertyRowMapper가 RowMapper 구현체로 사용된다.
•
NamedParameterJdbcTemplate : JdbcTemplate에서 한단계 발전한 템플릿으로, 위치를 기반으로 ? 마스킹을 매핑하는 대신 이름을 가진 파라미터를 사용할 수 있다.
•
PagingQueryProvider : KeySet 기반 페이징을 위해 특별환 쿼리 생성 도구가 필요한데, 스프링 배치에서 각 데이터베이스에 최적화된 PagingQueryProvider 구현체를 제공한다. 우리가 직접 구현체를 지정해서 사용할 수 있지만, 일반적으로 JdbPagingItemReaderBuilder가 제공하는 쿼리 설정 메서드들을 사용하면 내부적으로 데이터베이스 타입에 맞는 적절한 PagingQueryProvider를 구성해준다.
◦
selectClause : 가져올 컬럼 지정
◦
fromClause : 데이터를 가져올 테이블 지정
◦
whereClause : (선택) 필요한 데이터를 필터링
◦
groupClause : (선택) 데이터 집계가 필요 시 사용
◦
sortKeys : ORDER BY 절에서 사용될 정렬 키를 지정. 여기서 지정된 키가 keySet 기반 페이징으로 WHERE 절에서도 사용된다. 이 키는 반드시 유니크한 값이여야하고, 데이터의 순서가 보장되어야하기 때문에 주로 PK나 유니크 인덱스가 존재하는 컬럼이 많이 사용된다.
JdbcPagingItemReader 구성하기
@Bean
fun jdbcPagingItemReader(): JdbcPagingItemReader<MutableItem> {
log.info(">> jdbcPagingItemReader")
return JdbcPagingItemReaderBuilder<MutableItem>()
.name("jdbcPagingItemReader")
.dataSource(dataSource)
.pageSize(3)
.selectClause("SELECT id, name, status")
.fromClause("FROM items")
.whereClause("WHERE status = :status")
.sortKeys(mapOf("id" to Order.ASCENDING))
.parameterValues(mapOf("status" to "READY"))
.beanRowMapper(MutableItem::class.java)
.build()
}
Kotlin
복사
•
pageSize : 한 번에 조회되는 페이지의 크기를 결정한다. 이는 SQL의 LIMIT 절로 반영되어 한 번의 쿼리 실행 시 데이터의 양을 제어할 수 있다. 가급적 pageSize와 chunkSize를 동일한 값으로 설정하는 것을 권장한다. 청크 크기와 페이지 사이즈가 같으면 청크마다 한 번의 쿼리 호출이 이루어져, 데이터베이스와의 상호작용을 보다 쉽게 이해할 수 있다.
•
selectClause : 쿼리의 SELECT 절에 해당하며, 어떤 컬럼을 조회할 것인지 설정한다.
•
fromClause : 쿼리의 FROM 절에 해당하며, 어떤 테이블에서 데이터를 조회할 지 지정한다.
•
whereClause : 쿼리의 WHERE 절로 조건을 설정하여 특정 조건을 만족하는 데이터만 조회하도록 한다. 위 처럼 :를 통해 어떤 값을 매핑할 지 이름으로 지정할 수 있다. ? 마스킹을 사용할 수도 있지만, 둘을 혼용해서 사용하는 것은 불가능하다.
•
sortKeys : 정렬 기준을 설정하는 부분으로, 위는 id 컬럼을 기준으로 오름차순으로 정렬하였다. KeySet Pagination 방식으로 사용하기 위해서는 정렬 키가 필수로 추가되어야한다.
•
PagingQueryProvider (자동생성) : JdbcPagingItemReaderBuilder는 selectClause, fromClause, sortKeys를 설정하게되면 자동으로 데이터베이스 타입에 맞춰 PagingQueryProvider 구현체를 생성해 페이징 쿼리를 구성한다. 커스텀 모델을 만들어 사용하고 싶다면 JdbcPagingItemReaderBuilder.queryProvider 메서드를 직접 구현한 커스텀 객체러르 전달하면 사용할 수 있다.
예제 실행하기
CREATE TABLE IF NOT EXISTS items(
id BIGSERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
status VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO items (name, status) VALUES
('Item 1', 'READY'),
('Item 2', 'READY'),
('Item 3', 'READY'),
('Item 4', 'READY'),
('Item 5', 'READY'),
('Item 6', 'FAILED'),
('Item 7', 'FAILED'),
('Item 8', 'COMPLETED'),
('Item 9', 'COMPLETED'),
('Item 10', 'COMPLETED');
SQL
복사
먼저 페이징 쿼리가 잘 동작하는지를 보기위해 데이터를 조금 넉넉히 넣어주고 실행시켜보면,

이처럼 첫 번째 쿼리에서는 LIMIT 절만 추가되어 조회되지만,

두 번째 쿼리부터는 WHERE 절에 id 조건이 추가되어 KeySet Pagination이 동작하는 것을 확인해볼 수 있다.
데이터베이스 쿼리 로그 남기기
데이터베이스에 발생하는 쿼리를 로그로 남기고 싶다면, application.yml 파일에 아래의 설정을 추가하면 된다. 다만 기본 로그 레벨이 TRACE라 배치 실행 시 발생되는 수많은 쿼리가 로그에 남게 된다.
# SQL 로깅 설정
logging:
level:
org.springframework.jdbc.core.JdbcTemplate: DEBUG
org.springframework.jdbc.core.StatementCreatorUtils: TRACE
YAML
복사
JdbcBatchItemWriter
JdbcBatchItemWriter는 스프링 배치에서 제공하는 가장 기본적인 관계형 데이터베이스 쓰기 도구이다. 내부적으로 NamedParameterJdbcTemplate을 사용하며, JdbcTemplate의 batchUpdate를 활용해 청크 단위로 모아진 아이템을 효율적으로 데이터베이스에 저장한다.
INSERT 방식 비교
•
일반 INSERT : 매 쿼리마다 네트워크 패킷 발생
INSERT INTO items (id, name, status) VALUES (1, "아이템1", "READY");
INSERT INTO items (id, name, status) VALUES (2, "아이템2", "COMPLETE");
SQL
복사
•
Multi-Value INSERT : 여러 값을 하나의 쿼리로 처리
INSERT INTO items (id, name, status) VALUES (1, "아이템1", "READY"), (2, "아이템2", "COMPLETE");
SQL
복사
batch update는 PreparedStatement를 재사용하여 쿼리 템플릿 하나에 여러 파라미터 세트를 함께 전송하고, 이 작업은 하나의 트랜잭션 내에서 수행되어 원자성을 보장한다.
// 쿼리 : INSERT INTO items (id, name, status) VALUES (?, ?, ?)
// 첫 번째 레코드
ps.setLong(1, 1);
ps.setString(2, "아이템1");
ps.setString(3, "READY");
ps.addBatch();
// 두 번째 레코드
ps.setLong(1, 2);
ps.setString(2, "아이템2");
ps.setString(3, "COMPLETE");
ps.addBatch();
Java
복사
위는 예시일 뿐 실제 데이터베이스에 전달되는 형식은 각 데이터베이스 드라이버 구현체별로 다르다.
JdbcBatchItemWriter 구조
JdbcBatchItemWriter
│
├────── NamedParameterJdbcTemplate
│ └─ (쿼리 실행)
│
├────── SQL
│ └─ (데이터 삽입/수정을 위한 쿼리)
│
└────── ItemSqlParameterSourceProvider or ItemPreparedStatementSetter
└─ (Java 객치 → SQL 파라미터 매핑)
Plain Text
복사
•
NamedParameterJdbcTemplate : 네임드 파라미터 바인딩을 지원하는 JdbcTemplate로, SQL 실행과 처리를 수행한다.
•
SQL : JdbcBatchItemWriter가 실행할 SQL 구문을 정의한다. INSERT, UPDATE, DELETE 등의 DML 구문이 될 수 있고, ? 마스킹 방식 플레이스홀더와 네임드 파라미터 모두 지원한다.
•
ItemSqlParameterSourceProvider : Java 객체의 프로퍼티를 SQL 네임드 파라미터에 매핑하는 역할을 수행한다. JdbcBatchWriterBuilder의 beanMapped 메서드를 사용하면, JdbcBatchItemWriter가 ItemSqlParameterSourceProvider의 구현체 중 BeanPropertyItemSqlParameterSourceProvider를 사용한다.
•
ItemPreparedStatementSetter : Java 객체의 데이터를 PreparedStatement의 파라미터에 설정하는 역할을 한다.
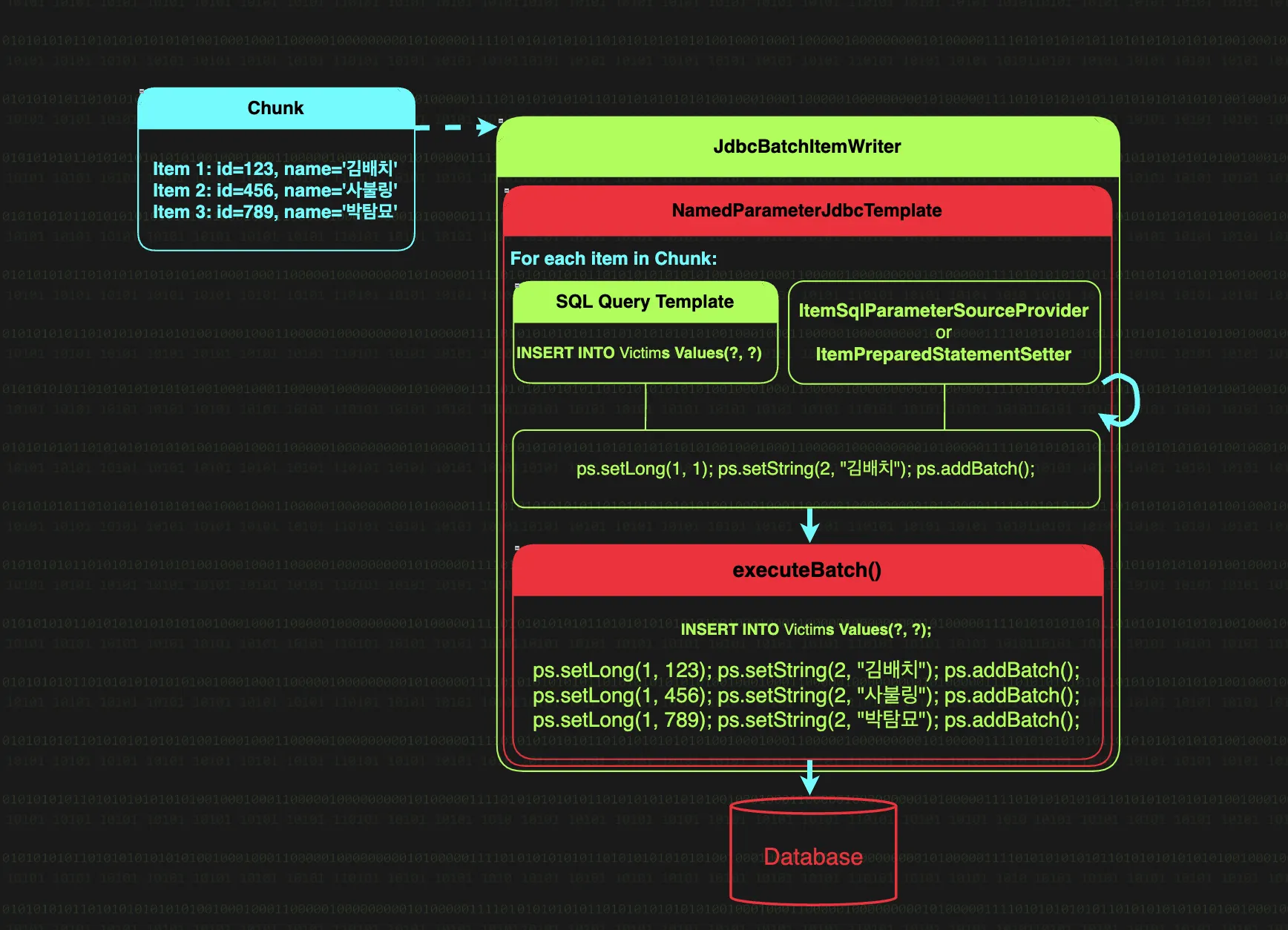
동작 과정을 살펴보면,
•
청크로 모아진 아이템들이 JdbcBatchItemWriter에 전달
•
NamedParameterJdbcTemplate가 ItemSqlParameterSourceProvider 혹은 ItemPreparedStatementSetter를 사용해 SQL의 파라미터를 설정 후 배치에 추가
•
각 아이템마다 PreparedStatement 파라미터 설정이 끝나 마지막 아이템까지 처리가 완료되면, 누적된 모든 PreparedStatement를 단일 네트워크 호출로 데이터베이스에 전송
JdbcBathItemWriter 구성하기
@Bean
fun itemStatusProcessor(): ItemProcessor<MutableItem, MutableItem> {
log.info(">> itemStatusProcessor")
return ItemProcessor { item ->
log.info("process item = {}", item)
item.status = "PROCESSED"
item
}
@Bean
fun jdbcBatchItemWriter(): ItemWriter<MutableItem> {
log.info(">> jdbcBatchItemWriter")
return JdbcBatchItemWriterBuilder<MutableItem>()
.dataSource(dataSource)
.sql("UPDATE items SET status = :status WHERE id = :id")
.beanMapped()
.assertUpdates(true)
.build()
}
@Bean
fun jdbcItemReadStep(
jdbcPagingItemReader: JdbcPagingItemReader<MutableItem>,
itemStatusProcessor: ItemProcessor<MutableItem, MutableItem>,
jdbcBatchItemWriter: ItemWriter<MutableItem>,
): Step {
return StepBuilder("jdbcItemReadStep", jobRepository)
.chunk<MutableItem, MutableItem>(3, transactionManager)
.reader(jdbcPagingItemReader)
.processor(itemStatusProcessor)
.writer(jdbcBatchItemWriter)
.allowStartIfComplete(true)
.build()
}
Kotlin
복사
이와 같이 status를 PROCESSED로 변경하는 ItemProcessor와 status를 업데이트 치는 쿼리를 넣은 JdbcBatchItemWriter를 빈으로 등록하고, 등록된 빈으로 Step에서 설정한다.
예제 실행하기
예제를 실행하기 전, 먼저 데이터의 상태를 확인해보자.
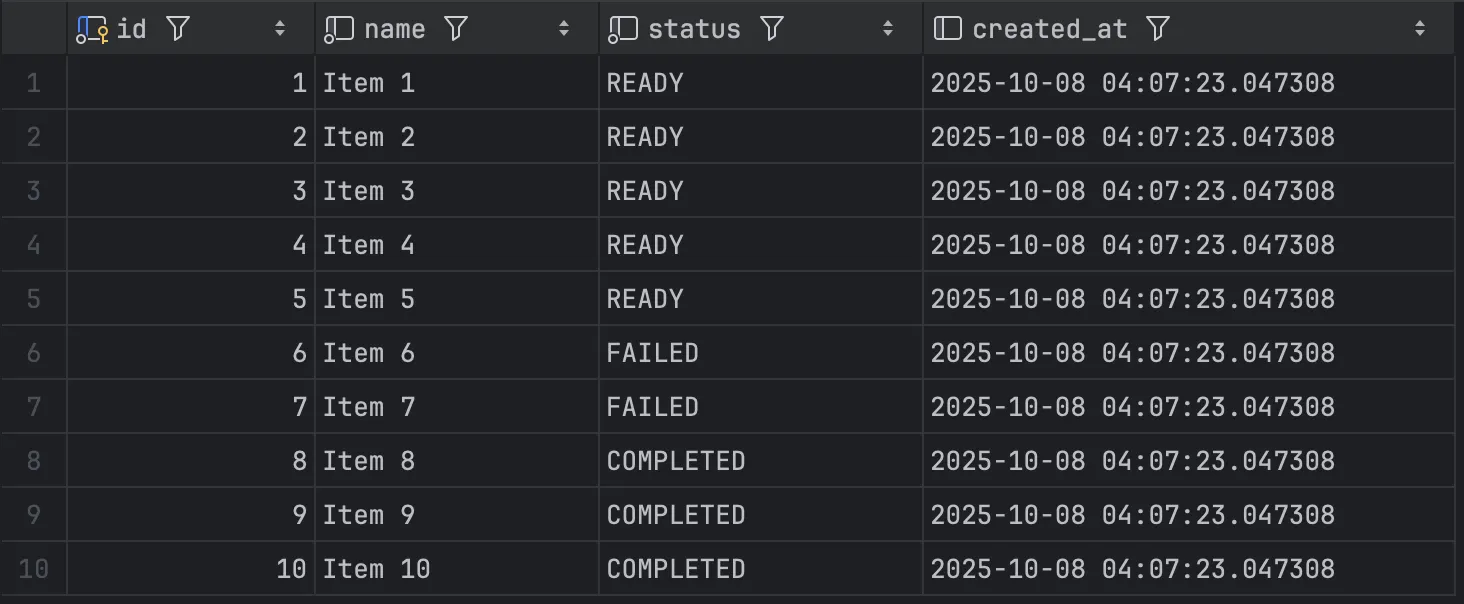
우리는 READY 상태를 조회하여 PROCESSED로 변경하여 저장할 예정이니, id가 1~5인 item들을 잘 살펴보자.


그 후 배치를 실행시키면, 이처럼 청크 사이즈 3에 맞춰 2번의 쿼리가 발생하게 된다.
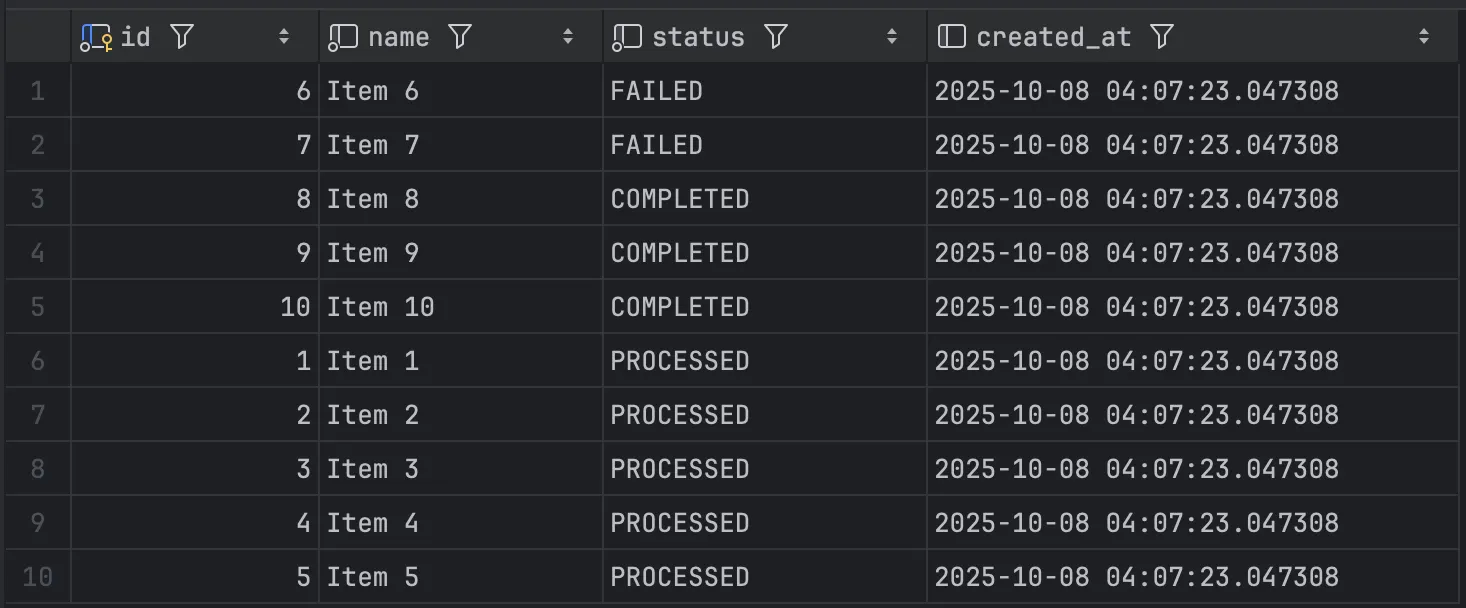
실행 결과 데이터가 변경된 채로 잘 저장되어 있는 것을 확인 할 수 있다.
JPA ItemReader / ItemWriter
최근에는 Java 진영에서는 JdbcTemplate보다는 JPA를 사용하는 경우가 대부분일 것이다. 스프링 배치 역시 JPA를 지원한다.
plugins {
kotlin("jvm") version "1.9.25"
kotlin("plugin.spring") version "1.9.25"
kotlin("plugin.jpa") version "1.9.25"
...
}
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
Kotlin
복사
코틀린을 위한 JPA 플러그인과 JPA 의존성을 추가해주고,
spring:
jpa:
show-sql: true
properties:
hibernate:
format_sql: true
highlight_sql: true
YAML
복사
SQL 관련 설정도 추가해주자.
JpaCursorItemReader
이전에 JdbcCursorItemReader를 사용해보았기 때문에, JpaCursorItemReader 또한 이름만 보아도 어떤 역할을 할 지 짐작이 될 것이다. JpaCursorItemReader는 커서 기반으로 데이터를 순차적으로 읽어오되, JPA 기반으로 읽어오는 ItemReader이다. JdbcCursorItemReader와의 차이점은 내부적으로 entityManager를 통해 데이터를 읽기 때문에, 엔티티 중심의 처리가 가능해진다는 것이다.
JpaCursorItemReader 구조
JpaCursorItemReader
│
├────── queryString(JPQL) or JpaQueryProvider
│ └─ (쿼리 생성)
│
├────── EntityManager
│ └─ (JPA 핵심 엔진)
│
└────── Query
└─ (EntityManager가 생성하는 실행 가능한 쿼리 인스턴스)
Plain Text
복사
•
queryString : JpaCursorItemReader가 데이터를 조회하기 위한 JPQL(Java Persistence Query Language) 쿼리이다. EntityManager가 이 queryString을 사용하여 실제 실행 가능한 Query 객체를 생성한다. 만약 queryString 대신 JpaQueryProvider를 사용하고 싶다면, queryProvioder 메서드를 통해 JpaQueryProvider 구현체를 설정할 수 있다.
•
EntityManager : JPA의 핵심 컴포넌트로, 엔티티의 생명주기를 관리하고 실제 데이터베이스 작업을 수행하는 역할을 한다. JpaCursorItemReader는 EntityManager를 통해 커서 기반의 데이터 조회를 수행한다. entityManagerFactory 메서드를 통해 EntityManagerFactory 인스턴스를 전달하면, 내부적으로 EntityManager를 생성하여 데이터를 조회하는데 사용한다.
•
Query : JpaCursorItemReader는 EntityManager를 통해 Query 객체를 생성하고, 이를 사용해 데이터를 스트리밍 방식으로 읽어온다. Query 객체의 getResultStream 메서드를 호출해 수행된다. Hibernate는 이 gerResultStream 메서드를 재구현하여 스트리밍을 지원하지만, 다른 JPA 구현체들은 기본 구현을 사용한다.
public interface Query {
...
default Stream getResultStream() {
return getResultList().stream();
}
}
Java
복사
기본 구현인 getResultStream은 위 코드를 보면 전체 데이터를 한 번에 로딩하고 실제 스트리밍이 아니므로, Hibernate가 아닌 타 JPA 구현체를 사용 시 주의가 필요하다.
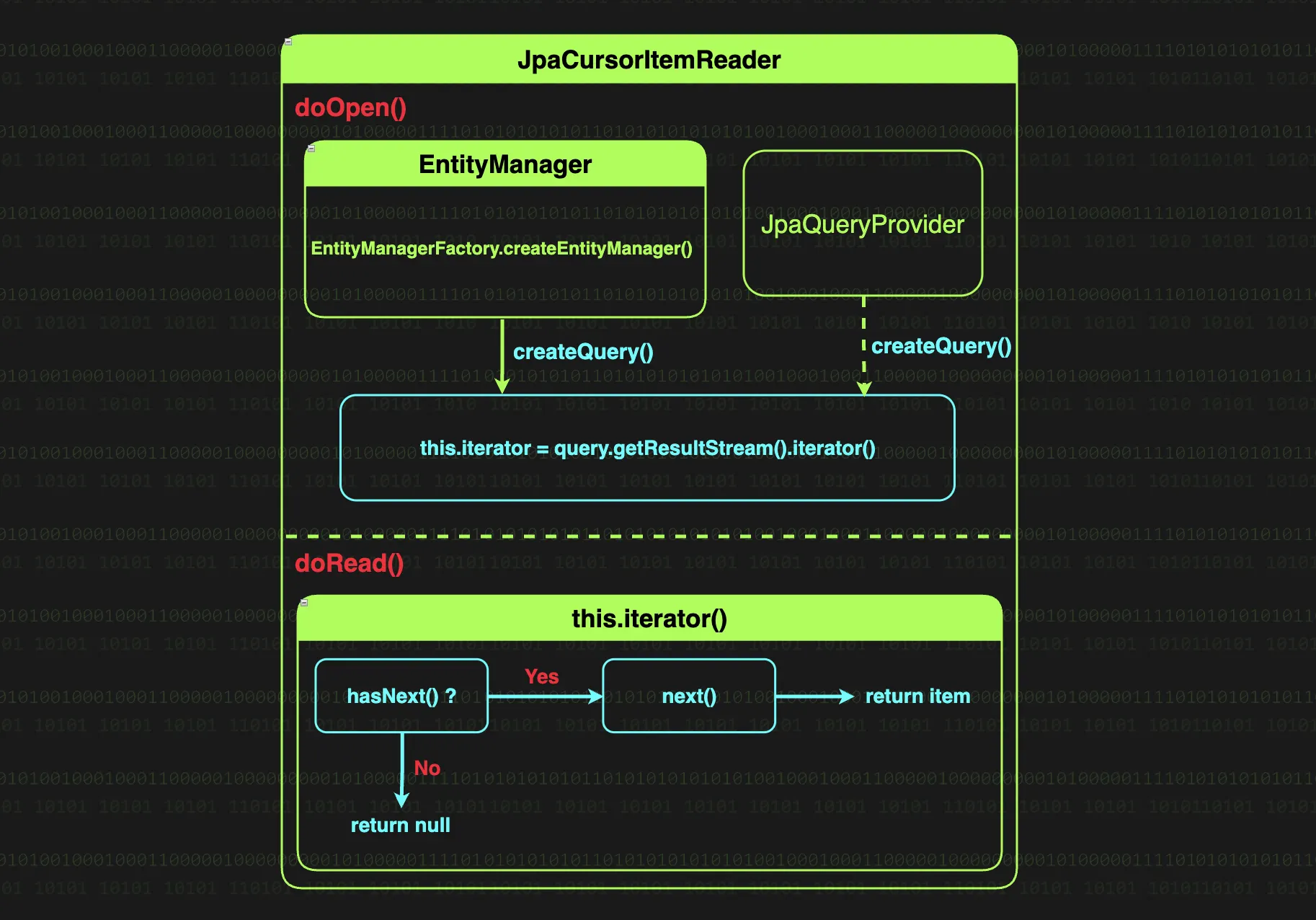
실행 흐름을 살펴보면,
•
JdbcCursorItemReader 초기화 시점에 doOpen 호출
•
doOpen 메서드 내에서 EntityManager와 JpaQueryProvider가 협력하여 실행 가능한 Query 생성
•
Query 객체의 getResultStream 메서드를 호출하여 데이터베이스 커서를 순회할 Iterator를 준비
•
조회 시점에 JpaCursorItemReader의 doRead 메서드 호출
•
doReade 메서드 내에서 준비된 Iterator를 통해 실제 데이터를 조회
•
iterator.hasNext 메서드를 통해 다음 데이터의 존재 여부를 확인하고, 있다면 next 메서드를 호출해 읽어오고 없다면 null을 반환해 종료
JpaCursorItemReader 구성하기
CREATE TABLE IF NOT EXISTS
items(
id BIGSERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
status VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO items (id, name, status)
VALUES
(1, 'Item 1', 'READY'),
(2, 'Item 2', 'READY'),
(3, 'Item 3', 'READY'),
(4, 'Item 4', 'READY'),
(5, 'Item 5', 'READY'),
(6, 'Item 6', 'PROCESSING'),
(7, 'Item 7', 'PROCESSING'),
(8, 'Item 8', 'COMPLETED'),
(9, 'Item 9', 'COMPLETED'),
(10, 'Item 10', 'COMPLETED');
CREATE TABLE IF NOT EXISTS
orders(
id BIGSERIAL PRIMARY KEY,
item_id BIGINT NOT NULL,
quantity INT NOT NULL,
price INT NOT NULL,
status VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO orders (item_id, quantity, price, status)
VALUES
(1, 2, 200, 'PENDING'),
(1, 1, 100, 'PENDING'),
(2, 5, 500, 'PENDING'),
(3, 3, 300, 'PENDING'),
(4, 4, 400, 'PENDING'),
(4, 2, 200, 'PENDING'),
(5, 1, 100, 'PENDING'),
(6, 5, 500, 'DELIVERING'),
(7, 3, 300, 'DELIVERING'),
(8, 4, 400, 'DELEVERED'),
(9, 1, 300, 'DELEVERED'),
(10, 2, 100, 'DELEVERED');
SQL
복사
@Entity
@Table(name = "items")
class Item(
@Column(nullable = false)
private var name: String,
@Column(nullable = false)
private var status: String,
@Column(name = "created_at", nullable = false, updatable = false)
private val createdAt: LocalDateTime = LocalDateTime.now(),
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private val id: Long = 0L,
// 도메인이 맞지도 않고 양방향 매핑도 하지 않지만, JPA 방식으로 조회하는 배치를 연습하기 위해 추가
@OneToMany(mappedBy = "item")
private val orders: MutableList<Order> = mutableListOf()
) {
fun process() {
status = "PROCESSING"
orders.forEach { it.process() }
}
override fun toString(): String {
return "Item(id=$id, name='$name', status='$status', createdAt=$createdAt)"
}
}
@Entity
@Table(name = "orders")
class Order(
@Column(nullable = false)
private var quantity: Int,
@Column(nullable = false)
private var status: String,
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private val id: Long = 0L,
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "item_id")
private val item: Item
) {
fun process() {
status = "DELIVERING"
}
override fun toString(): String {
return "Order(id=$id, quantity=$quantity, status='$status')"
}
}
Kotlin
복사
이처럼 테이블을 셋팅하고 JPA 엔티티를 구현하자.
@Configuration
class JpaItemConfig(
private val jobRepository: JobRepository,
private val transactionManager: PlatformTransactionManager,
private val entityManagerFactory: EntityManagerFactory,
) {
private val log = LoggerFactory.getLogger(this::class.java)
@Bean
fun jpaItemJob(
jpaItemStep: Step,
): Job {
return JobBuilder("jpaItemJob", jobRepository)
.start(jpaItemStep)
.build()
}
@Bean
fun jpaItemStep(
jpaCursorItemReader: JpaCursorItemReader<Item>,
jpaItemProcessor: ItemProcessor<Item, Item>,
jpaItemWriter: ItemWriter<Item>,
): Step {
return StepBuilder("jpaItemStep", jobRepository)
.chunk<Item, Item>(3, transactionManager)
.reader(jpaCursorItemReader)
.processor(jpaItemProcessor)
.writer(jpaItemWriter)
.allowStartIfComplete(true)
.build()
}
@Bean
fun jpaCursorItemReader(): JpaCursorItemReader<Item> {
return JpaCursorItemReaderBuilder<Item>()
.name("jpaCursorItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("""
SELECT i FROM Item i
LEFT JOIN FETCH i.orders o
WHERE i.status = :status
""".trimIndent())
.parameterValues(mapOf("status" to "READY"))
.build()
}
@Bean
fun jpaItemProcessor(): ItemProcessor<Item, Item> {
log.info(">> jpaItemProcessor")
return ItemProcessor { item ->
log.info("before process >> item = $item")
item.getOrders().forEachIndexed { index, order ->
log.info(" >> order[$index] = $order")
}
item.process()
item
}
}
@Bean
fun jpaItemWriter(): ItemWriter<Item> {
return ItemWriter { items ->
items.forEach { item ->
log.info("after process >> item = $item")
item.getOrders().forEachIndexed { index, order ->
log.info(" >> order[$index] = $order")
}
}
}
}
}
Kotlin
복사
그 후 이처럼 배치 Job을 구성한다. Item을 읽어서 process를 호출해 Item과 order의 status를 바꾼 후 writer로 출력을 찍는 로직이다.
예제 실행하기
배치를 실행시켜보면,
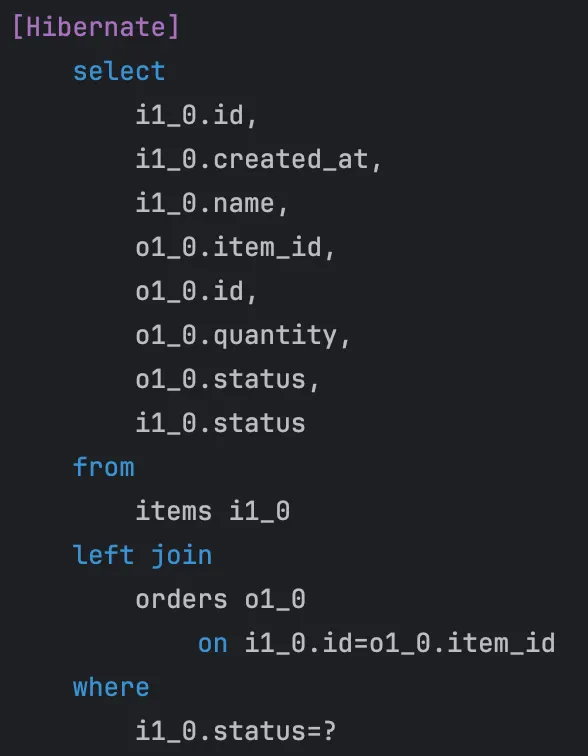
JPQL 쿼리대로 조회를 1번만 수행하는 것을 확인할 수 있고,
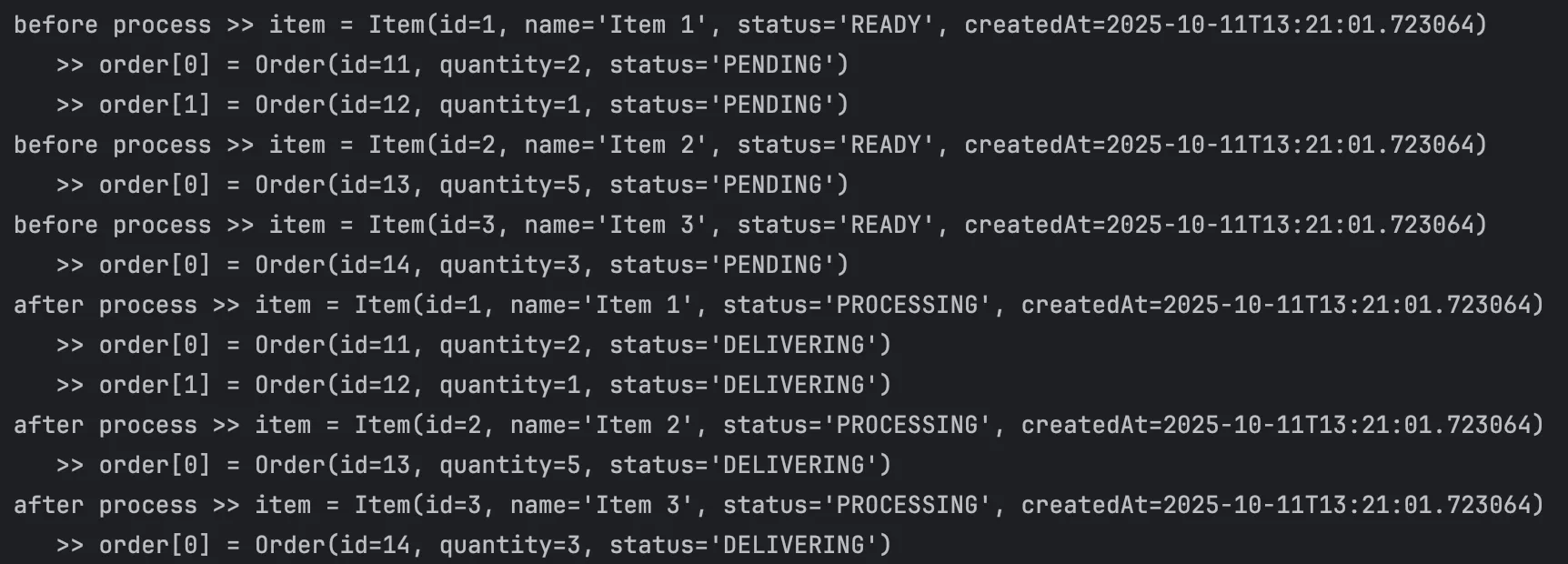
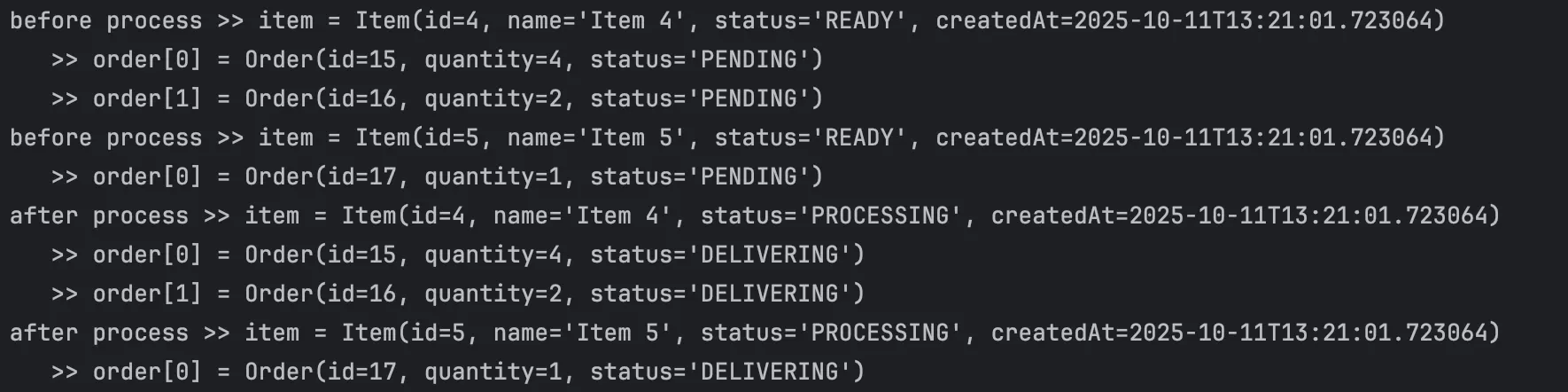
item의 status는 READY로, order의 status는 DELIVERING으로 전부 잘 변경되어 출력되는 것을 확인할 수 있다.
JpaPagingItemReader
JpaPagingITemReader는 JPA 기술을 통해 페이지 단위로 조회해오는 ItemReader이다. JdbcPagingItemReader와 유사하지만, 내부적으로 JPA 구현체를 사용한다는 점과 페이징 방식에서 차이가 있다.
OFFSET 기반 페이징
JdbcPagingItemReader와 달리 JpaPagingItemReader는 offset 기반으로 페이징을 수행한다.
SELECT * FROM items ORDER BY id LIMIT 10 OFFSET 0;
SELECT * FROM items ORDER BY id LIMIT 10 OFFSET 10;
SELECT * FROM items ORDER BY id LIMIT 10 OFFSET 20;
...
SQL
복사
이러한 페이징 방식은 몇가지 문제점을 가지고 있다.
•
데이터 정합성 깨짐 : offset 페이징 방식은 실시간 데이터 변경에 취약하다.
◦
페이지 1을 읽은 후 새로운 데이터가 맨 앞으로 추가된다면 페이지 2를 읽어올 때 일부 레코드 중복이 발생한다.
◦
반대로 페이지 1을 읽은 후 맨 앞의 데이터를 삭제하면 기존 페이지 2의 일부 레코드가 누락될 수 있다.
원론적으로는 실시간 데이터셋에 배치를 돌리는게 잘못이지만, 실무에서는 어쩔 수 없이 실시간으로 변경되는 데이터셋에 배치 처리를 해주어야할 때가 있다. 이런 경우에는 가급적 스트리밍 처리와 실시간 처리 방식을 고려해보자.
•
성능 저하 : 페이징 기반 조회 요청은 매 페이지 요청마다 DB는 전체 데이터를 읽어 정렬 후 필요 위치까지 건너뛴다. 때문에 전체 데이터 조회 및 정렬로 인한 성능저하와 OFFSET이 커질수록 건너뛰는 데이터가 많아져 성능이 저하되는 것도 문제이다.
•
메모리 고갈 : 페이징 기반 조회 요청은 DB 내부적으로 전체 데이터를 읽는다고 했는데, 이로 인해 메모리도 많이 차지하여 고갈시키게 된다.
JpaPagingItemReader 구조
JpaCursorItemReader
│
├────── queryString(JPQL) or JpaQueryProvider
│ └─ (쿼리 생성)
│
├────── EntityManager
│ └─ (JPA 핵심 엔진)
│
└────── Query
└─ (EntityManager가 생성하는 실행 가능한 쿼리 인스턴스)
Plain Text
복사
내부 컴포넌트만 보았을 때는 JpaCursorItemReader와 동일하고, JPQL query String 혹은 JpaQueryProvider를 통해 EntityManager로 실행 가능한 Query를 생성한다는 점에서 같다.
하지만 데이터를 읽는 방식에서 근본적인 차이가 있는데,
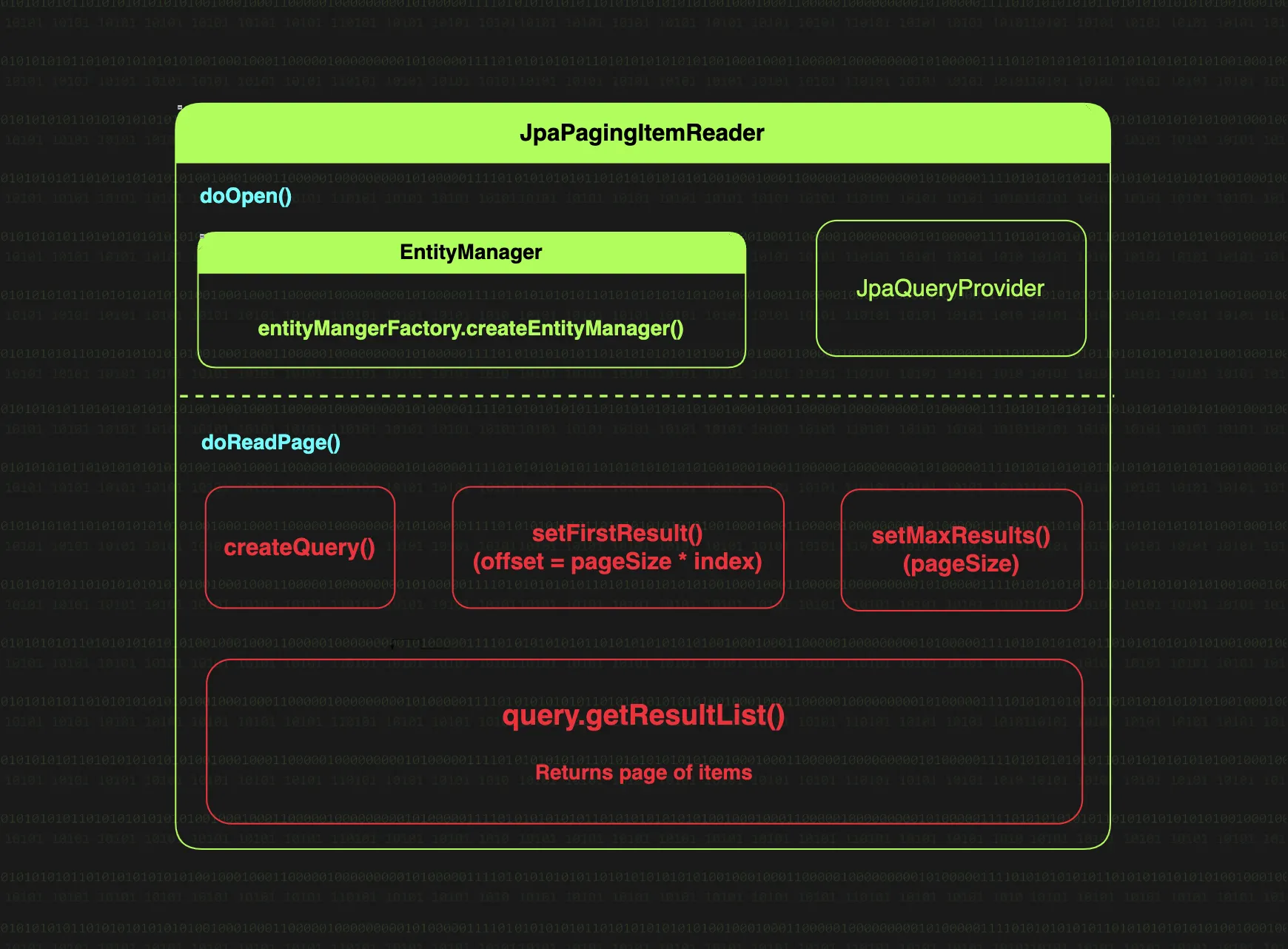
JpaCursorItemReader는 초기화 시점(doOpen)에 단 한 번의 Query를 수행하고, 그 후 Iterator를 순차 조회한다. 하지만 JpaPagingItemReader는 doReadPage 메서드가 호출 될 때마다 offset과 setMaxResult로 크기를 설정하여 새로운 쿼리를 작성해 데이터를 가져온다.
JpaPagingItemReader 구성하기
@Bean
fun jpaPagingItemReader(): JpaPagingItemReader<Item> {
return JpaPagingItemReaderBuilder<Item>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("""
SELECT i FROM Item i
LEFT JOIN i.orders o
WHERE i.status = :status
ORDER BY i.id ASC
""".trimIndent())
.parameterValues(mapOf("status" to "READY"))
.pageSize(3)
.build()
}
Kotlin
복사
기본적인 구성은 동일하지만, queryString을 보면 jdbcPagingItemReader 때와는 몇 가지 다른점이 있다.
1) FETCH JOIN 사용 금지
queryString을 살펴보면 FETCH JOIN이 빠진 것을 알 수 있다. Hibernate에서 Fetch Join과 페이징(LIMIT/OFFSET)을 함께 사용하면 페이징 쿼리로 가져오는게 아니라 전체 데이터를 메모리에 올린 후 애플리케이션에서 페이징을 수행한다. 심각한 메모리 낭비가 발생하고 심각하면 메모리 고갈로 서버가 다운될 수 있다.
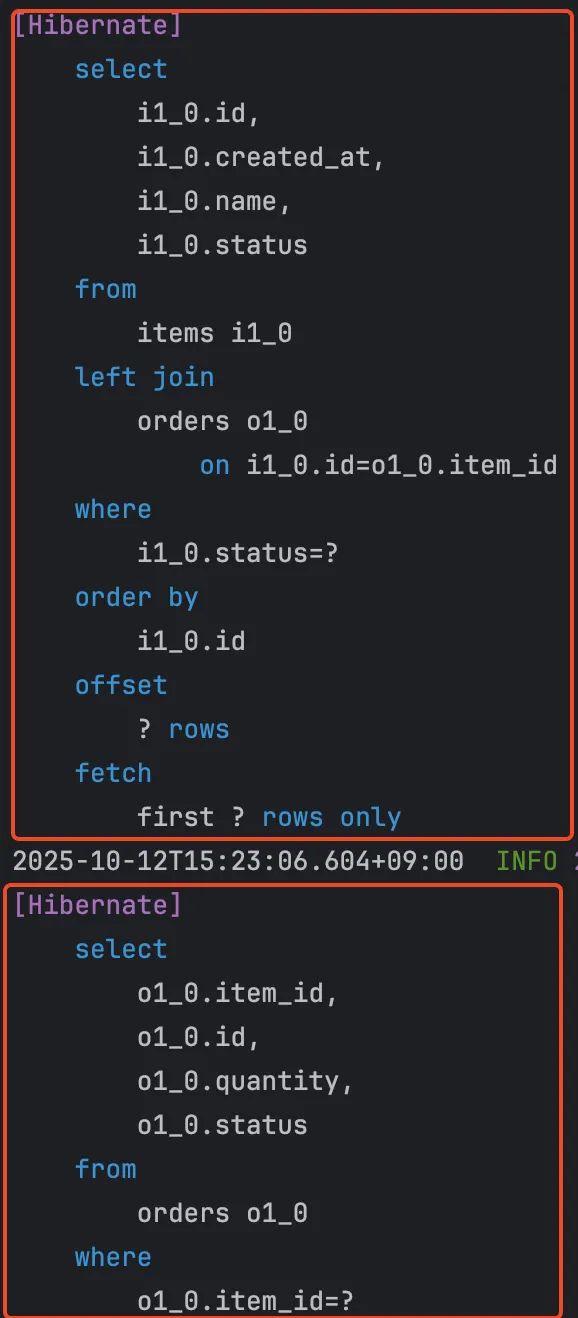
실제 쿼리를 실행시켜보면, items를 조회하는 쿼리에 left join이 포함되어 있지만 이후 orders를 단독으로 조회하는 N+1이 발생함을 알 수 있다.
@OneToMany(mappedBy = "item", fetch = FetchType.EAGER)
@BatchSize(size = 5)
private val orders: MutableList<Order> = mutableListOf()
Kotlin
복사
이를 해결하기 위해서는 이처럼 EAGER 로딩으로 바꾼 후 @BatchSize를 통해 IN절로 한 번에 조회하도록 최적화 하는 수 밖에 없다. EAGER 로딩으로 바꾸는 이유는, 트랜잭션 처리 로직상 LAZY 로딩 방식에는 @BatchSize가 적용되지 않기 때문이다.
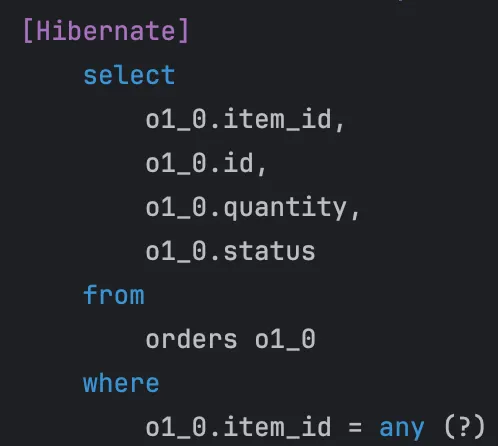
실행시켜보면, 이처럼 in절을 통해 쿼리가 단 한 번만 발생한다.
LAZY 로딩일 때 @BatchSize가 안 먹는 이유
EntityTransaction tx = null;
if (transacted) {
tx = entityManager.getTransaction();
tx.begin();
entityManager.flush();
entityManager.clear();
} // end if
...
if (!transacted) {
List<T> queryResult = query.getResultList();
for (T entity : queryResult) {
entityManager.detach(entity);
results.add(entity);
} // end if
}
else {
results.addAll(query.getResultList());
tx.commit();
}
Java
복사
doReadPage 메서드는 청크 단위 트랜잭션과 별개로 새로운 트랜잭션을 시작할 지 여부인 transacted 설정에 따라 두 가지 동작으로 나뉜다.
•
transacted가 true인 경우(기본값)
◦
새로운 트랜잭션을 시작하고 데이터 조회 후 커밋
•
transacted가 false인 경우
◦
데이터 조회 후 비영속화(detach)
위 두 케이스 모두 조회가 끝나면 commit이든 detach든 호출되어 비영속화 상태로 관리된다.
•
EAGER 로딩인 경우, query.getResultList를 호출할 때 영속화된 상태에서 연관된 엔티티를 조회하기 때문에 IN절을 통한 한 번에 조회 가능
•
LAZY 로딩인 경우, processor나 writer의 실제 사용 시점에 조회가 발생하여 엔티티를 비영속화된 상태라 IN절을 통한 조회 불가능(N+1 발생)
동작을 테스트 하던 중 발견한 버그
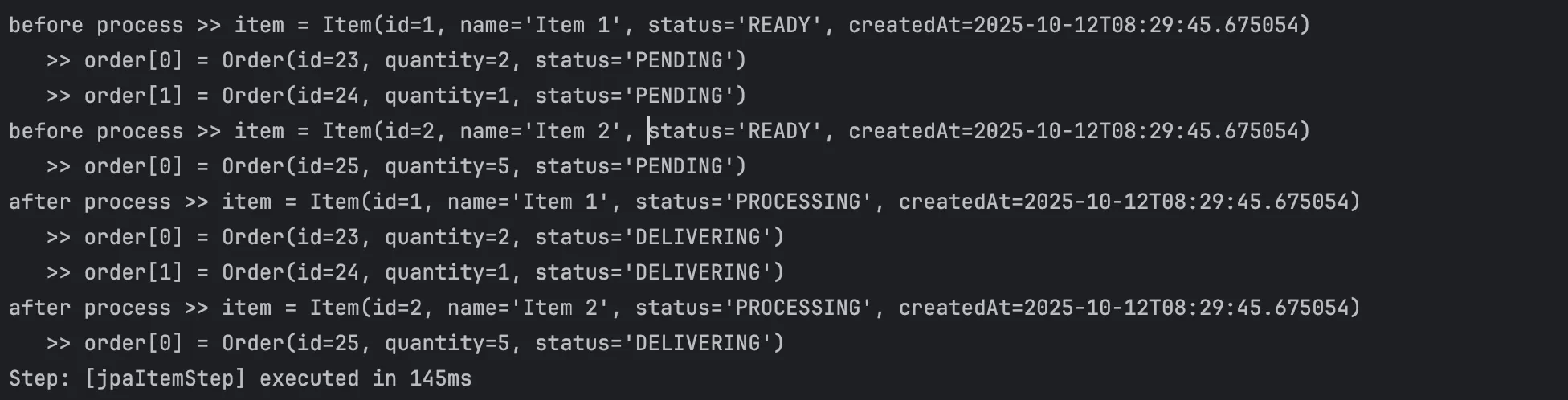
데이터를 5개를 세팅해두고 3개 단위로 조회하도록 구현을 했는데, 이처럼 데이터를 2개만 읽고 배치가 끝나버리는 버그를 발견했다.
확인해보니 이는 일대다 연관관계를 가진 테이블을 JOIN하게 되어 데이터가 뻥튀기 되어, 의도한 개수와 다르게 측정을 해서 가져오는 개수도 다르고 끝나는 시점도 다른 것이다. LEFT JOIN을 제거하고 수행했을 때는 제대로 데이터를 가져오는 것을 확인했다. EAGER 로딩과 @BatchSize를 통한 IN절 일괄 조회를 수행하고 있다면, 결과는 동일하니 일대다 연관관계는 LEFT JOIN을 빼고 쿼리를 작성하자.
2) ORDER BY 추가
이전의 JdbcPagingItemReader나 JpaPagingItemReader 모두 동일하게, 페이징 기반의 ItemReader는 반드시 ORDER BY 절을 추가해야한다. 정렬 기준이 없다면 매 페이지를 읽을 때마다 데이터의 순서가 보장되지 않아 데이터가 누락되거나 중복될 수 있다.
transacted 필드와 시스템 안전성
위에서 살펴본 내용에 따르면, JpaPagingItemReader에서 transacted 필드가 true인 경우 새로운 트랜잭션이 시작되어 관리된다. 하지만 이걸 true로 사용하는 경우 @BatchSize가 무효화 되는 것 외에도 또 다른 잠재적인 위험이 존재한다.
if (transacted) {
tx = entityManager.getTransaction();
tx.begin();
entityManager.flush(); // 잠재적 위험
entityManager.clear();
} // end if
Java
복사
doReadPage 메서드를 살펴보면, 메서드 초반부에 entityManager.flush를 호출하는 것을 알 수 있다.
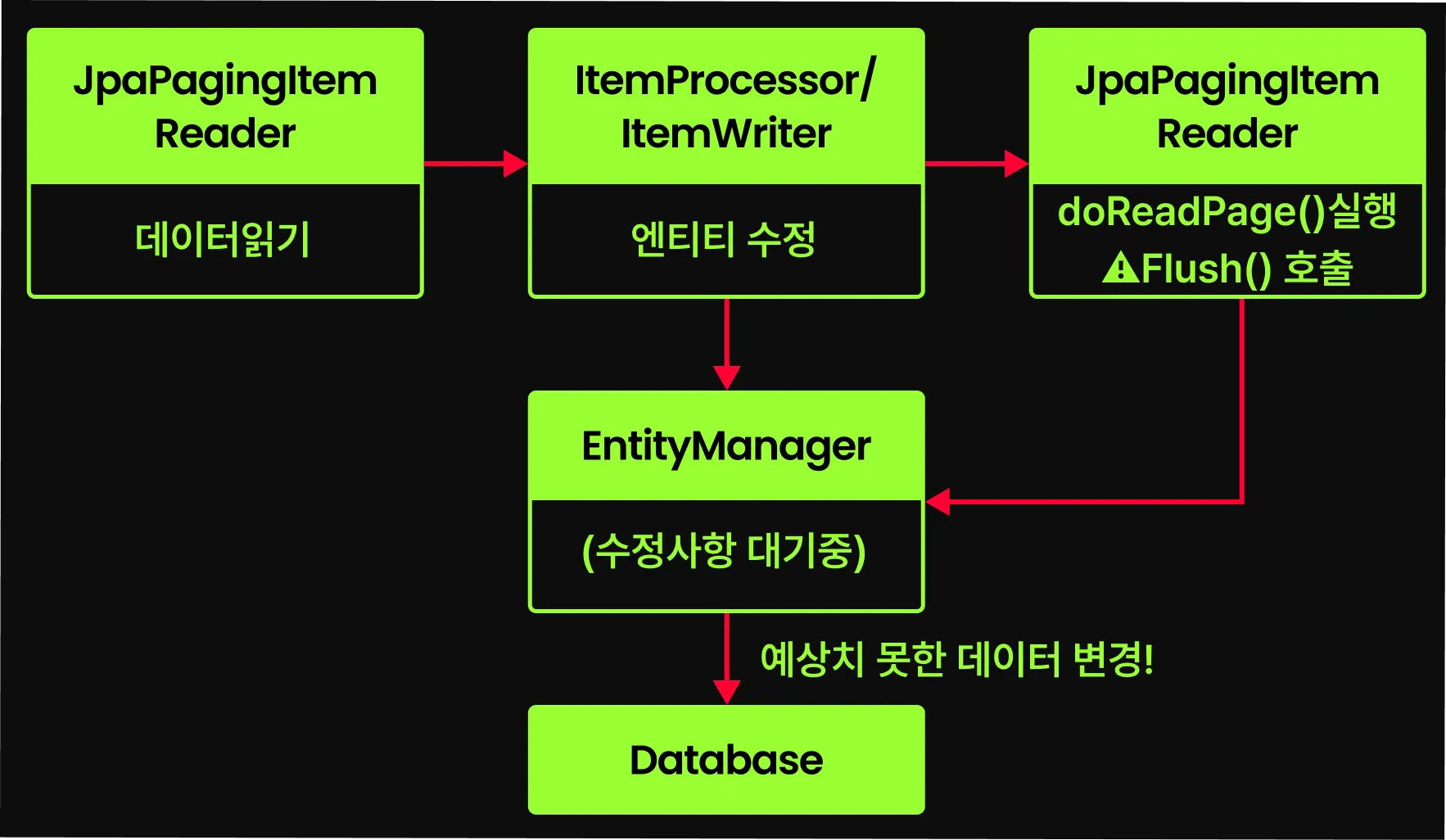
만약 이전 청크의 ItemProcessor에서 엔티티를 수정했다면 의도치 않게 저장이 발생할 수 있다. 이처럼 불필요한 트랜잭션 관리에 더해 의도하지 않은 동작이 발생할 수 있으니 가급적 transacted를 false로 설정해놓고 사용하자.
이러한 한계점을 해결하기 위한 커스텀 구현체가 개발자 커뮤니티에 공유되어있다. offset 기반의 페이징 한계를 해결하고, 트랜잭션 관리도 최적화되어있으며, QueryDSL까지 도입되어 있다. JpaPagingItemReader를 꼭 사용해야겠다면, 이를 참고해 적절히 사용해보자.
JpaItemWriter
JpaItemWriter는 넘겨받은 엔티티를 영속성 컨텍스트에 올리고, DB에 저장하는 것이다. EntityManager를 사용하기 때문에, 대상이 JPA Entity이기만 하면 되고, 별도의 SQL 쿼리를 작성할 필요도 없다.
JpaItemWriter를 사용해보기 전에, 기존에 사용했던 PlatformTransactionManager를 JpaTransactionManager로 바꾸어주자.
@Bean
public JpaTransactionManager transactionManager(EntityManagerFactory emf) {
return new JpaTransactionManager(emf);
}
Java
복사
스프링 부트를 사용한다면 자동으로 주입되겠지만, 주입이 안된다면 이처럼 생성해 넣을 수 있다.
JpaItemWriter 구성하기
@Bean
fun jpaItemWriter(): ItemWriter<Item> {
return JpaItemWriterBuilder<Item>()
.entityManagerFactory(entityManagerFactory)
.usePersist(true)
.build()
}
Kotlin
복사
구성이 상당히 간단한데, EntityManagerFactory를 주입하고 엔티티 저장 시 persist를 사용할 지 merge를 사용할 지만 결정하면 된다. usePersist 메서드에 true를 전달하면 persist를 사용하고, false를 전달하면 merge가 사용된다. 생략하는 경우 기본값인 false가 전달된다.
새로운 데이터를 추가하는 시나리오라면 persist를 사용하고, 기존 데이터를 수정하는 시나리오라면 merge를 사용하자.
예제 실행하기

실행 시키면 이처럼 데이터를 조회하고,
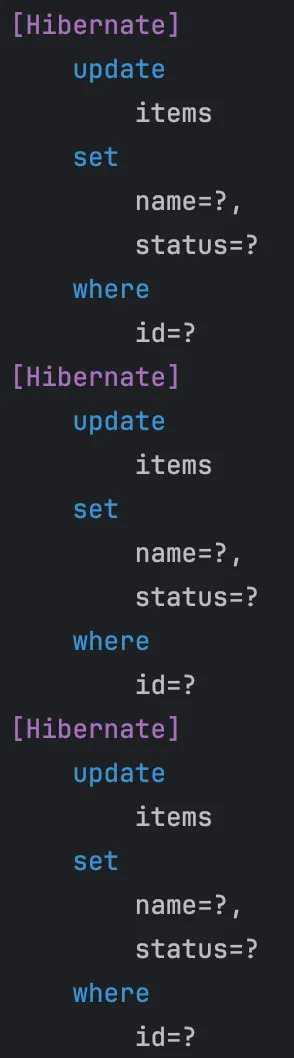
update 쿼리가 발생하는 것처럼 보인다. 하지만 Hibernate 로그는 단순히 쿼리가 어떻게 생성되는지만 보여줄 뿐이고, 실제로는 JdbcBatchUpdate로 쿼리가 처리되기 때문에 DB의 reWriteBatchInsert 설정이 true로 되어있다면 한 번의 쿼리만 발생한다.
url: jdbc:postgresql://localhost:5432/postgres?reWriteBatchedInserts=true
YAML
복사
merge 성능 이슈
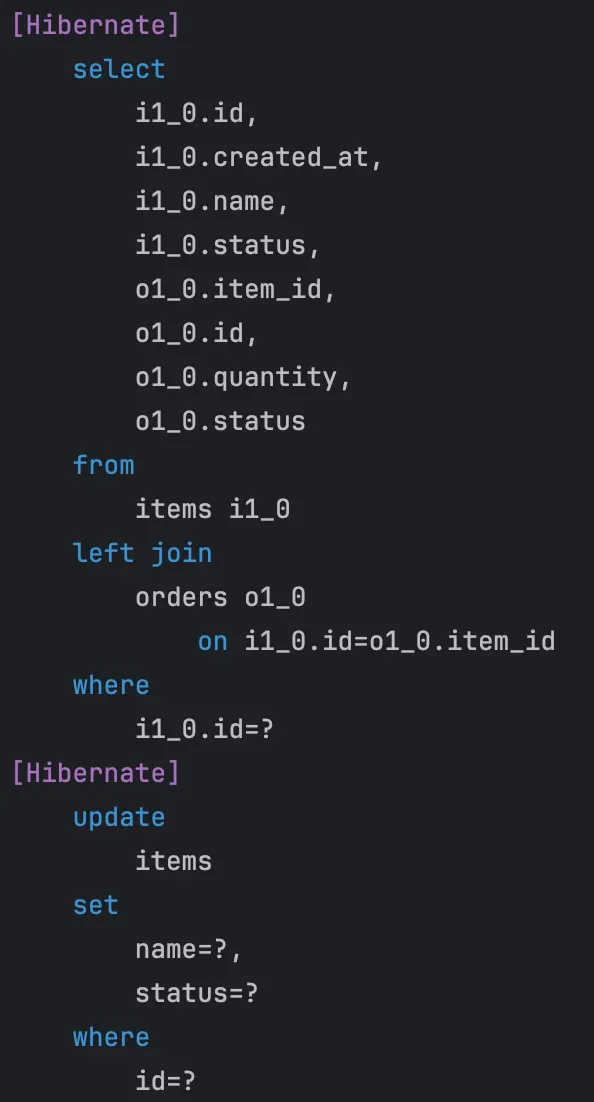
merge를 사용하는 경우 update를 수행하기 전에 데이터가 존재하는지 확인하기 위한 select 쿼리가 필연적으로 발생한다. update 자체는 batchUpdate로 처리되지만, select는 개별로 쿼리가 발생하기 때문에 피할 수 없는 성능 이슈가 발생한다.
JpaItemWriter를 사용하며 발견한 버그
Paging 기반 처리 방식은 매 청크마다 페이징으로 쿼리를 새로 조회하기 때문에, 데이터의 실시간 변경에 취약하다. 위의 예시 코드를 보면 Item을 조회 후 Item의 status를 수정해 그대로 저장하는데, 조회 조건이 status이라 페이지 0을 처리하고 나면 기존의 페이지 정보가 달라지게된다.
실제로 실행을 시켜보면, 데이터가 5개가 있지만 페이지 0에서 3개를 처리하고 그대로 배치가 종료된다. 뒤의 2개 데이터는 상태가 변경되어 누락돼 처리가 되지 않는 것이다.
이를 해결하기 위해서는 커스텀 ItemReader을 구현하거나 JpaCursorItemReader를 사용해야한다.
JpaItemWriter의 엔티티 ID 생성 전략
JpaItemWriter를 통해 새로운 엔티티를 생성하는 경우 ID 생성 전략을 선택할 때 몇 가지 주의사항이 필요하다.
•
GenerationType.SEQUENCE : DB에서 자동 생성하는 시퀀스를 사용하는 방식이다. 배치처리의 Hibernate는 성능 최적화를 위해 시퀀스 값을 미리 여러 개 받아와 메모리에 저장해두는데, 별다른 설정이 없다면 50개씩 할당받는다. 하지만 DB에서 시퀀스를 한 번에 생성하는 개수는 그와 다를 수 있기 때문에, 이를 동일하게 맞춰줄 필요가 있다.
// 애플리케이션 레벨에서 설정
@SequenceGenerator(
name = "item_id_seq",
sequenceName = "item_id_seq",
allocateSize = 100
)
Kotlin
복사
# DB 스키마 레벨에서 설정
ALTER SEQENCE item_id_seq INCREMENT BY 50;
SQL
복사
•
IDENTITY : IDENTITY 전략을 사용하는 경우에는 엔티티의 ID가 DB에서 생성되기 때문에, Hibernate가 엔티티를 영속화하기 위해서는 반드시 INSERT를 먼저 실행해야 한다. 결과적으로 모든 아이템의 INSERT가 개별적으로 처리되어야한다는 의미이기 때문에, 배치 성능이 중요하다면 SEQUENCE 전략을 사용하자.
•
TABLE : TABLE 전략은 새로운 ID를 생성할 때마다 별도의 트랜잭션이 필요하고, 이 과정에서 row 단위 잠금이 발생해 성능과 확장성 측면에 심각한 문제가 있다. ID 생성 전략으로 TABLE 전략은 사용하지 말자.