
데이터 저장 목적
데이터를 저장은 어떤 목적으로 저장하느냐에 따라, 큰 개념으로 분류했을 때 OLTP와 OLAP로 구분할 수 있다. 데이터 마트, 데이터 웨어하우스, 데이터 레이크에 저장되는 모든 데이터는 기본적으로 OLAP를 위한 데이터이다. 다시 말해, 분석(BI, Business Inteligence) 활동을 위하여 저장된다. 그렇다고 해서 데이터 레이크 = OLAP 데이터베이스는 아니다. 정확히는 OLAP를 위한 데이터를 모아 놓는 공간이라고 볼 수 있다.
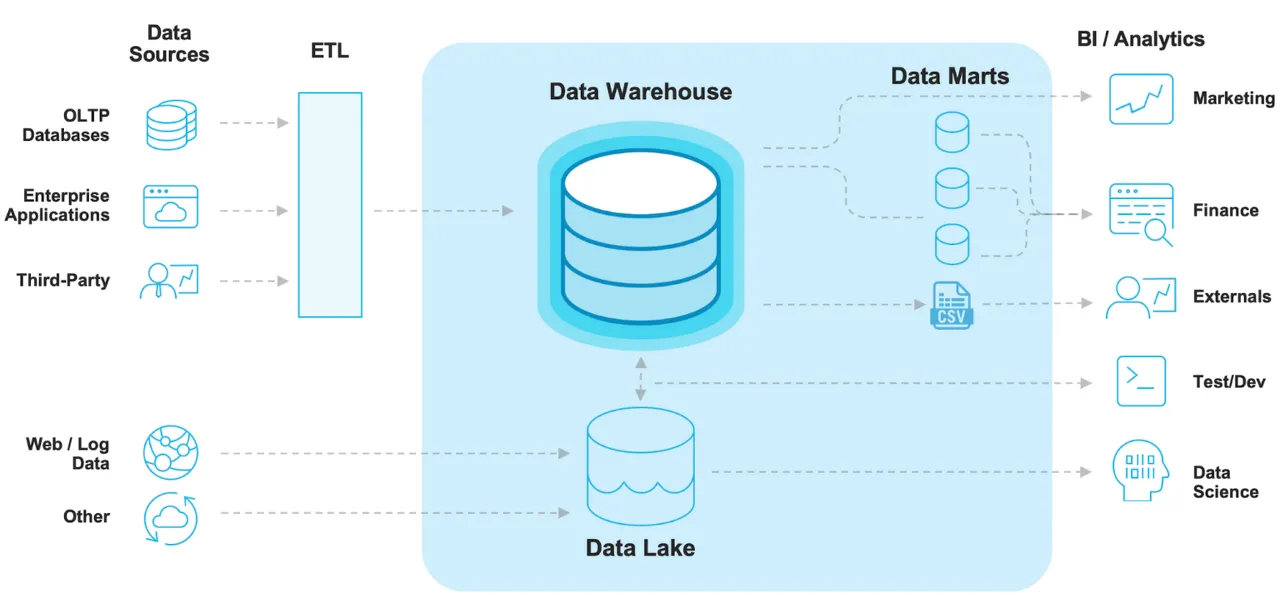
데이터 레이크, 데이터 웨어하우스, 데이터 마트 용어들은 기술적인 구분이 아닌, 사용적인 구분으로 회사마다 구축 형태나 의미가 조금씩 다르게 사용될 수 있다.
데이터 웨어하우스(Data Warehouse)
이전까지 많은 기업에서 운영과 분석에 동일한 데이터베이스를 이용했다. 하지만 인터넷 사용자가 늘어나면서, 저장되는 데이터가 많아지고 데이터 분석에 대한 수요가 증가하면서 여러가지 문제가 발생했다.
•
운영 중심의 데이터 저장(대출, 예금 등) 방식
•
분석을 위한 요청이 서버에 부하를 주고, 이로 인해 운영에도 영향을 받는다.
•
사용자가 사용하기 쉬운 데이터를 제공하지 못하거나, 데이터를 가공하는 추가적인 작업 발생한다.
•
전사적 정보에 대한 통합 분석이 어렵다.
•
최신의 데이터 뿐만 아니라 시간에 따른 데이터 변경사항도 저장 필요
이러한 한계점들을 극복하고자 데이터베이스를 분리하고, 분석을 위한 통합적인 정보를 중심으로 데이터를 저장하는 데이터 웨어하우스를 구축하게 되었다.
여러 저장소에서 데이터를 가져와 통합하여 저장하고, 주로 정형 데이터를 기반으로 하기 때문에 관계형 데이터베이스를 엮어서 사용한다. 전사적 정보를 제공하기 때문에 일반적으로 회사마다 하나씩 데이터 웨어하우스가 구축된다.
대표적인 데이터 웨어하우스 툴로 Redshift, Bigquery, Snowflake가 있다.
데이터 레이크(Data Lake)
AI로 인해 빅데이터의 수요가 급증하면서, 사물인터넷이나 소셜미디어, 클릭 스트림 등 다양한 소스에서 예상할 수 없는 데이터들이 발생하고 이런 데이터들도 분석 대상이 되면서 데이터 형태에 관계없이 빠르게 한 곳에 저장해둘 필요가 생겼다. 기존의 관계형 데이터베이스는 속도가 느리고 데이터베이스 스키마에 맞추기 위한 추가 가공이 필요하기 때문에, 파일 저장소나 NoSQL을 사용하여 형태를 가공하지 않는 데이터를 빠르게 저장해두는 데이터 레이크가 구축되었다.
데이터 웨어하우스가 데이터를 잘 저장하여 분석하는 것이 목적이라면, 데이터 레이크는 발생하는 모든 데이터를 일단 한 곳에 저장해두는 것이 목적이다. 데이터 레이크에 저장되는 가공되지 않은 이러한 형태의 데이터를 원시 데이터(raw data)라고 부른다. 이렇게 원시 데이터를 쌓아두고, 필요할 때 가공하여 데이터 웨어하우스나 다른 데이터베이스로 옮겨서 사용된다.
데이터 레이크는 데이터가 어느 정도만큼 발생할지 모르기 때문에, 저장 공간을 미리 확보해야하고 큰 공간을 확보했지만 실제 데이터가 그만큼 쌓이지 않으면 그 비용만큼 손해가 발생하게 된다. 때문에 이렇게 예측하기 힘든 상황에서는 사용한만큼 돈을 지불하는 클라우드 서비스를 이용하기도 한다.
또한 데이터 레이크에 저장된 데이터는 주기적으로 청소하여, dark data(사용하지 않는 불필요한 데이터)가 비용을 발생시키는 것을 피해야한다.
대표적인 데이터 레이크는 AWS의 S3나 HDFS가 있다.
데이터 마트(Data Mart)
데이터 웨어하우스에서 우리가 필요한 데이터만 골라서 선택하는 과정은 필요한 데이터에 비해 조회 비용이 너무 커질 수 있다. 이러한 이유로 데이터 웨어하우스에서 각 목적에 맞는 데이터들을 따로 빼놓은 저장소인 데이터 마트를 구축하여 사용한다.
데이터 마트를 통해 필요한 데이터만 정리해두어 조회 시간과 비용을 아낄 수 있고 데이터 마트마다 권한을 부여하여 관리할 수 있지만, 데이터 웨어하우스에 저장된 데이터와 일치시키기 위해 별도의 동기화 방안이 필요하다.
데이터 마트 또한 목적에 맞춰 데이터가 정형화 되어있기 때문에, 주로 관계형 데이터베이스가 사용된다.
ETL
추출(Extract), 변환(Transform), 적재(Load)을 의미하는 ETL은 여러 데이터 소스의 데이터를 추출하여 일관성 있는 스키마에 맞춰 데이터 웨어하우스나 기타 시스템에 적재하는 통합 프로세스를 말한다. 이와 같은 과정을 거쳐 데이터를 옮기는 전체 과정을 ETL 파이프라인이라 하고, 주로 데이터 엔지니어들이 ETL 작업이 주기적이고 자동으로 수행되도록 툴을 구축하고 모니터링하는 작업을 수행한다.
ETL은 일련의 비즈니스 규칙을 적용하여, 데이터를 정리하고 체계화하여 구체적인 비즈니스 인텔리전스 요구사항을 해결할 수 있게 도와준다.





