
서브쿼리의 문제점
서브쿼리는 실체적인 데이터를 저장하고 있지 않기 때문에, 연산 비용이 추가되고 데이터 I/O 비용이 발생하며 최적화를 받을 수 없어 서브쿼리의 성능적 문제가 발생한다.
•
연산 비용 추가
서브쿼리에 접근할 때마다 SELECT 구문을 실행해서 데이터를 만들기 때문에, SELECT 구문 실행에 발생하는 비용이 추가된다. 서브쿼리의 내용이 복잡할수록 이러한 실행 비용은 더 높아진다.
•
데이터 I/O 비용 발생
서브쿼리의 결과를 일시적으로 저장해두기 위해 메모리에 저장하는데, 서브쿼리의 결과가 크다면 TEMP 탈락이 발생해 접근 속도가 급격하게 떨어질 수 있다.
•
최적화를 받을 수 없음
서브쿼리로 만들어지는 데이터는 구조적으로는 테이블과 차이가 없지만, 테이블에는 있는 명시적인 제약이나 인덱스 같은 메타 정보가 없어 옵티마이저가 최적화를 해주지 못한다.
서브쿼리는 유연한 사용이 가능해 코딩할 때는 편하지만, 이러한 문제점들 때문에 복잡한 연산을 수행하거나 연산 결과가 큰 서브쿼리를 사용할 때는 성능 리스크를 고려해야 한다.
서브쿼리의 위험성
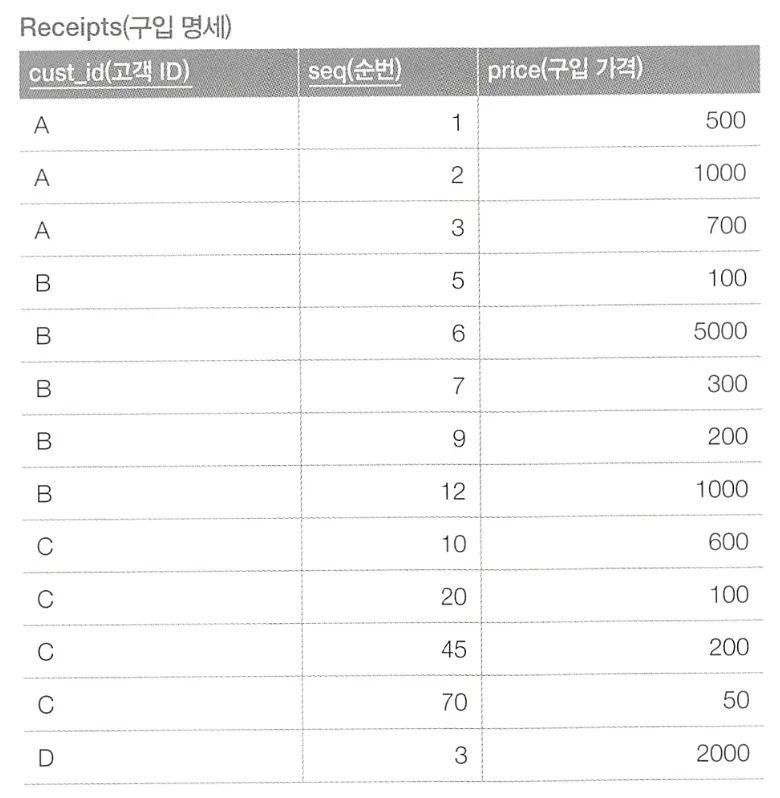
이와 같은 테이블이 있고, 여기서 쿼리를 통해 아래와 같은 결과를 얻고자 한다.
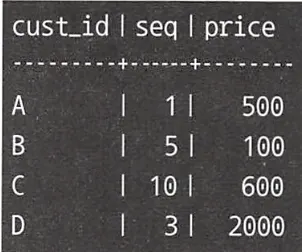
•
서브쿼리를 사용한 방법
SELECT R1.cust_id, R1.seq, R1.price FROM Receipts R1
INNER JOIN (SELECT cust_id, MIN(seq) AS min_seq
FROM Receipts GROUP BY cust_id) R2
ON R1.cust_id = R2.cust_id AND R1.seq = R2.min_seq;
SQL
복사
이를 SQL 구문으로 작성하면 위와 같이 작성할 수 있고, 동작을 그림으로 나타내면 아래와 같다.
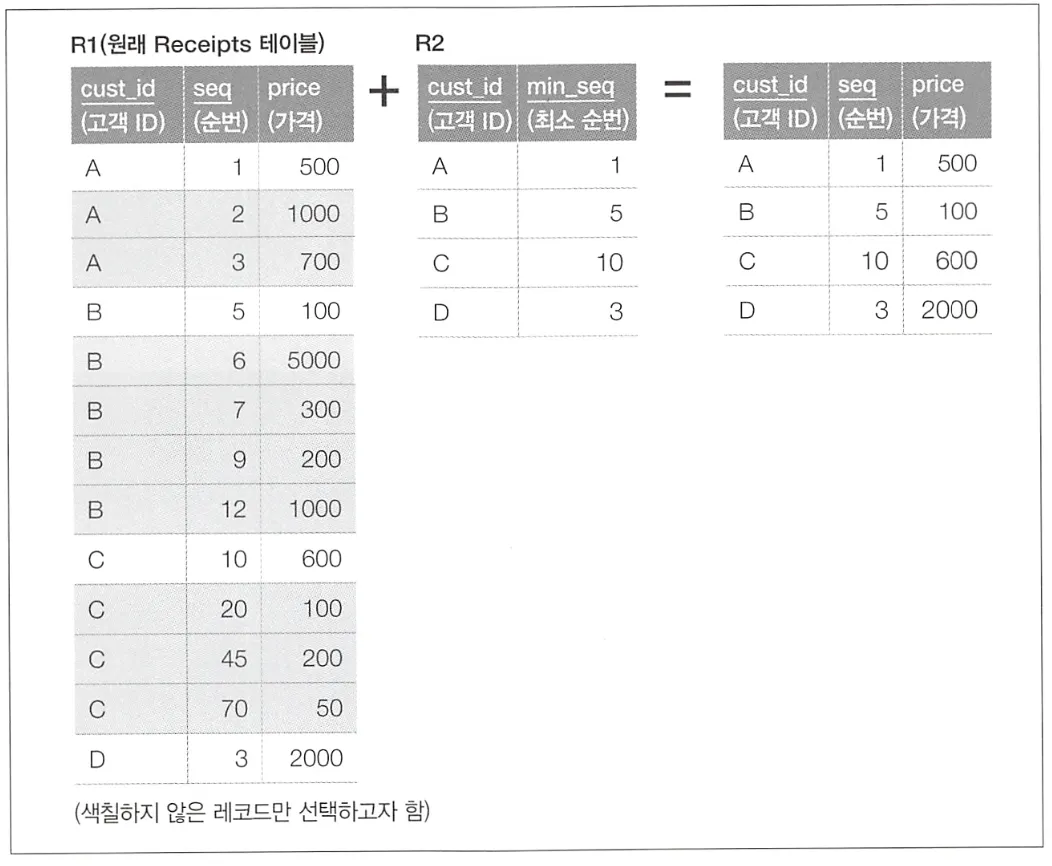
하지만 이와 같이 작성하면 코드가 여러 계층에 걸쳐 만들어져 가독성이 떨어지고, 코드의 성능이 떨어진다.
성능이 떨어지는 이유는 위에서 언급한 서브쿼리의 문제점들에 더해, 결합을 필요로 하기 때문에 비용이 높고 실행 계획 변동 리스크가 있다. 또한 Receipts 테이블에 두 번 접근하게 된다.

PostgreSQL 실행 계획

Oracle 실행 계획
실행 계획을 살펴보면 R1, R2에 각각 스캔이 이루어지고, Hash 결합이 이루어진다. Nested Loops가 사용된다 하더라도, Receipts 테이블에 2회 접근한다는 문제가 남아있다.
•
상관 서브쿼리를 사용한 방법
SELECT cust_id, seq, price FROM Receipts R1
WHERE seq = (SELECT MIN(seq) FROM Receipts R2
WHERE R1.cust_id = R2.cust_id);
SQL
복사
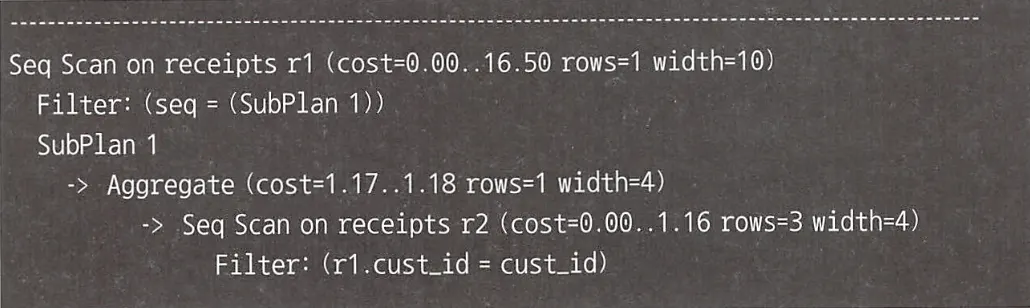
PostgreSQL 실행 계획

Oracle 실행 계획
상관 서브쿼리를 사용하면 R2 스캔에 인덱스 스캔을 사용할 가능성이 생기지만, 그렇다고해도 Receipts 테이블에 접근 1회와 기본 키 인덱스 접근 1회가 발생한다. 결국 상관 서브쿼리는 서브쿼리에 비해 성능적인 장점이 없고, 서브쿼리의 해결책이 되지 못한다.
•
윈도우 함수를 사용한 방법
Receipts 테이블에 대한 접근을 1번으로 줄이는 것이 개선의 핵심이고, 이를 윈도우 함수를 사용하여 해결할 수 있다.
SELECT cust_id, seq, price FROM
(SELECT cust_id, sq, price, ROW_NUMBER()
OVER (PARTITION BY cust_id ORDER BY seq) AS row_seq
FROM Recepits) WORK
WHERE WORK.row_seq = 1;
SQL
복사
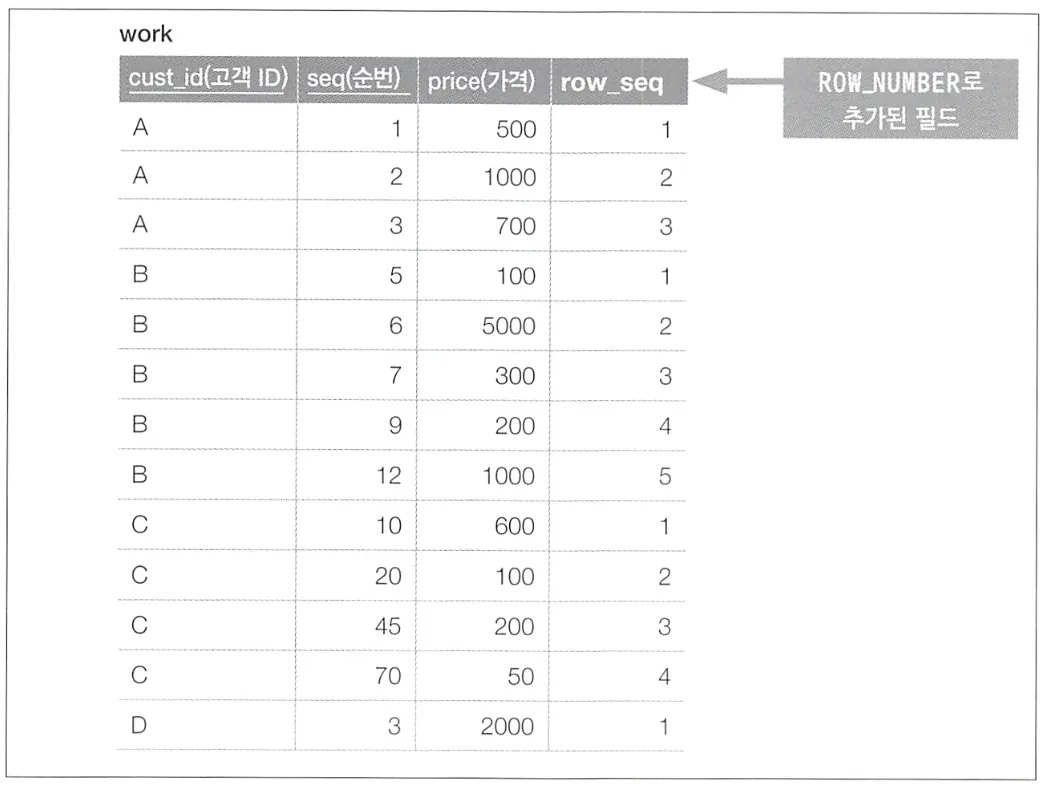
이와 같이 작성하면 쿼리도 간단해지고 가독성도 올라간다.

PostgreSQL 실행 계획

Oracle 실행 계획
Receipts 테이블에 대한 접근도 1회로 감소한 것을 알 수 있다.
장기적 관점에서의 리스크 관리
서브쿼리의 성능적인 부분은 DBMS와 데이터베이스 서버의 성능, 매개변수나 인덱스 등의 환경 요인으로 인해 크게 바뀔 수 있다. 다만 저장소에 대한 I/O를 줄이는 것이 SQL 튜닝의 가장 기본 원칙이다.
결합을 사용한 쿼리는 두 개의 불안정 요소가 있다.
•
알고리즘 변동 리스크
세 가지 결합 알고리즘 중 어떤 것을 선택할지는 옵티마이저에 의해 테이블의 크기나 카디널리티 등을 고려하여 자동으로 결정된다. 따라서 초기에는 테이블의 레코드 개수가 적어 Nested Loops를 사용하다가도, 레코드가 늘어나 일정 역치를 넘어가면 실행 계획에 변화가 생긴다. 이로 인해 성능이 좋아지기도 하지만, Hash 나 Sort Merge를 선택 후 TEMP 탈락이 발생하는 등의 이유로 오히려 크게 악화되기도 한다. 결국 결합을 사용하면 이런 변동 리스크를 안고 사용할 수 밖에 없다.
•
환경 요인에 의한 지연 리스크
Nested Loops에서 내부 테이블에 인덱스가 있으면 성능이 크게 개선되지만, 항상 결합 키에 인덱스가 존재하지는 않을 것이다. Hash나 Sort Merge에서 TEMP 탈락이 발생하는 경우 작업 메모리를 늘려주면 성능을 개선할 수 있지만, 메모리 튜닝은 한정적 리소스 내부에서의 트레이드 오프를 발생시킨다.
결합을 사용한다는 것은 장기적인 관점에서 이와 같이 고려해야할 리스크를 늘린다는 의미이다.
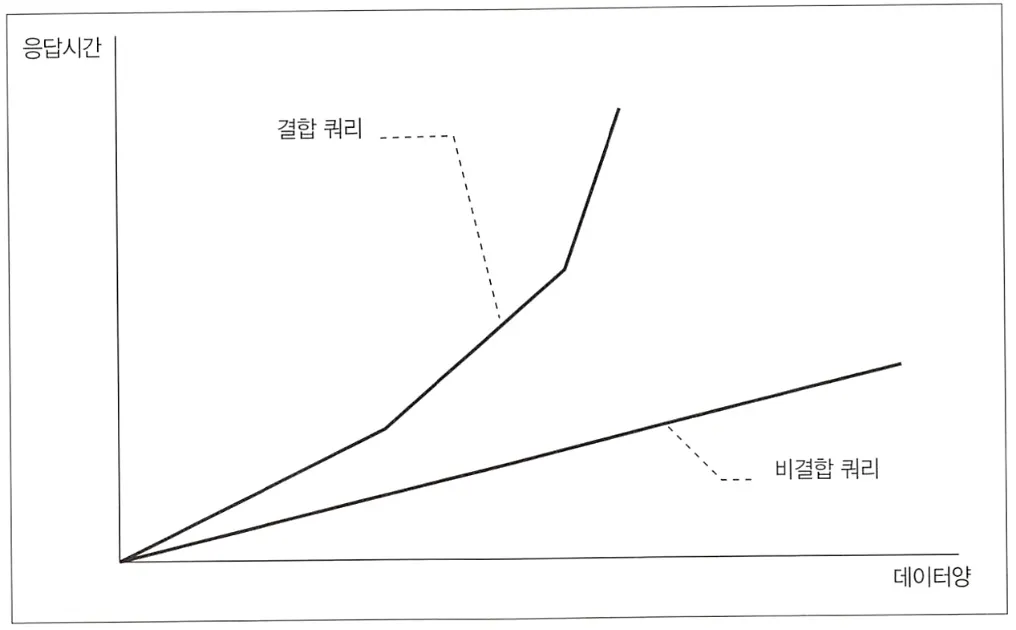
이러한 이유들로 인해서 옵티마이저가 이해하기 쉽게 쿼리를 단순하게 작성하는 것이 좋다. 실행 계획이 단순할수록 성능이 안정적이고, 기능(결과) 뿐만 아니라 비기능(성능)적인 부분도 보장할 수 있어야 한다.
서브쿼리의 위험성 - 응용편
앞선 Receipts 테이블을 사용하여, 고객마다 seq가 최대값을 가지는 레코드와 seq가 최소값을 가지는 레코드의 price 필드의 차이를 구해보자. 원하는 출력은 아래와 같다.

이 문제에 서브쿼리를 사용하면 아래와 같이 된다.

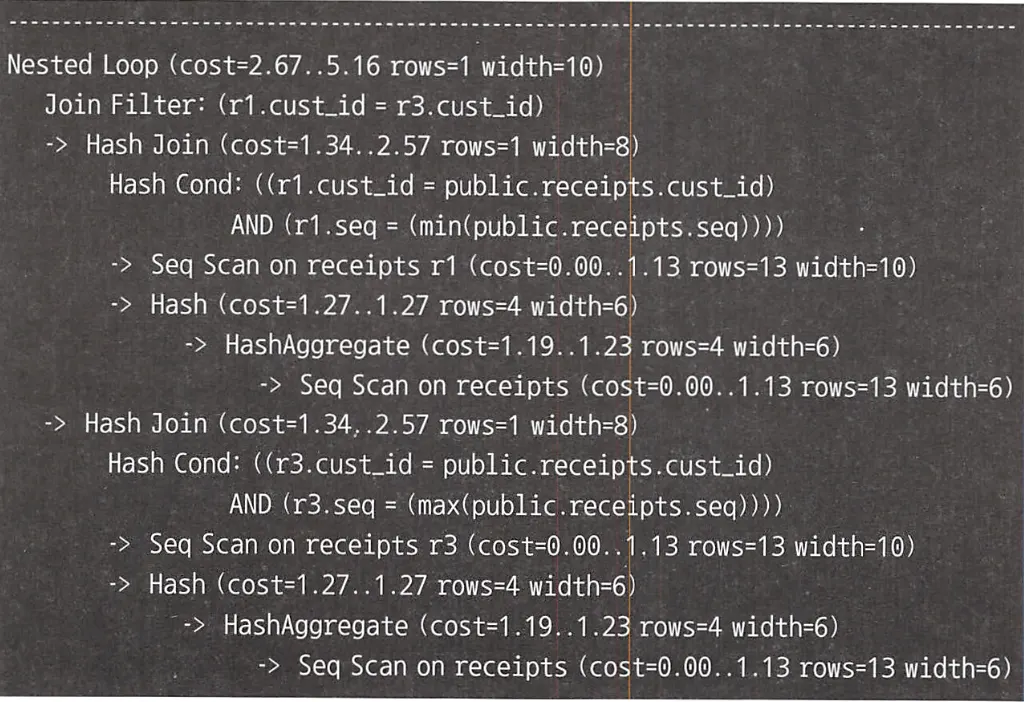
가독성이 좋지않고, 테이블에 대한 접근도 4번이나 이루어진다.
마찬가지로 윈도우 함수를 통해 결합을 제거하고 테이블 접근을 줄일 수 있다.
SELECT cust_id,
SUM(CASE WHEN min_seq = 1 THEN price ELSE 0 END)
- SUM(CASE WHEN max_seq = 1 THEN price ELSE 0 END)
FROM (SELECT cust_id, price,
ROW_NUMBER() OVER (PARTITION BY cust_id
ORDER BY seq) AS min_seq,
ROW_NUMBER() OVER (PARTITION BY cust_id
ORDER BY seq DESC) AS max_seq
FROM Receipts) WORK
WHERE WORK.min_seq = 1 OR WORK.max_seq = 1
GROUP BY cust_id;
SQL
복사
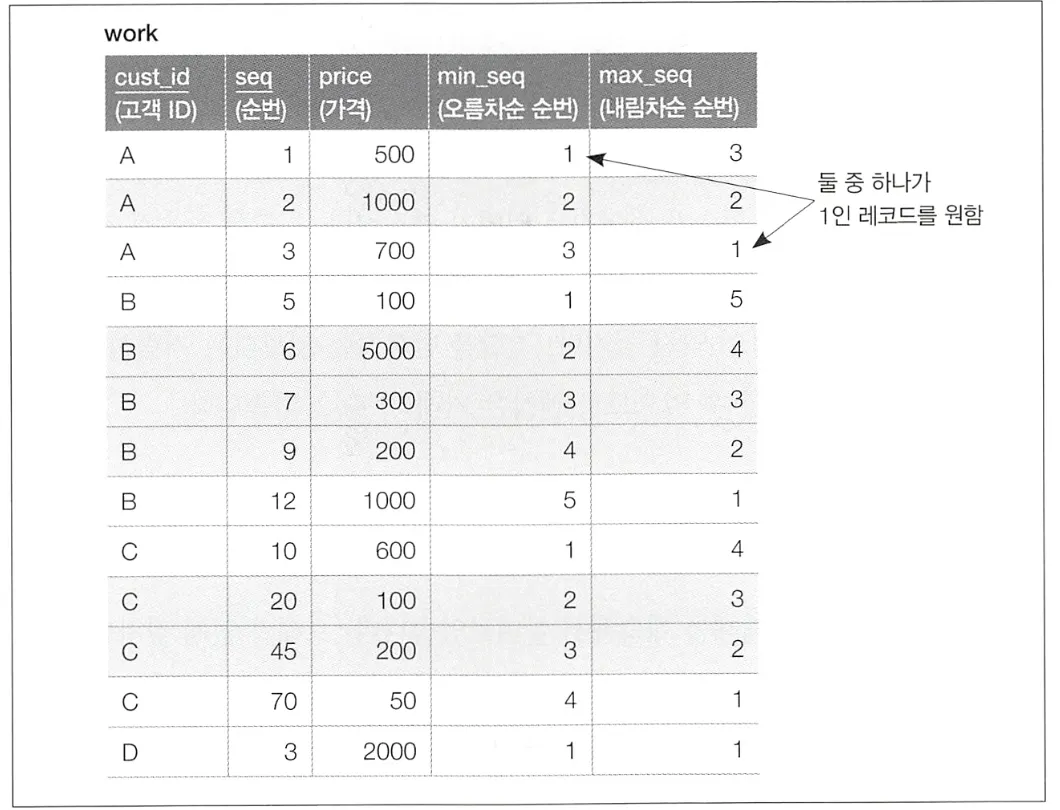
원래 다른 레코드에 있는 값은 뺄셈할 수 없는데, 이를 cust_id로 한 개의 레코드에 집약 후 윈도우 함수와 CASE 식으로 뺄셈을 수행했다.
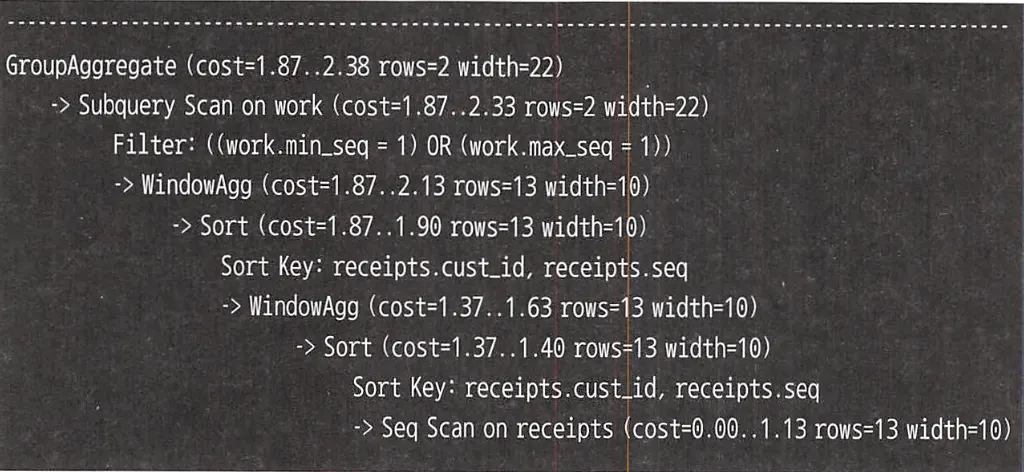
윈도우 함수로 정렬이 2번 발생하고 테이블에 대한 접근이 1번 이루어진다. 정렬 2번으로 인해 비용이 약간 발생하지만, 이는 결합으로 인해 테이블 스캔 2번 발생하는 것보다 저렴하고 실행 계획의 안정성도 확보할 수 있다.
서브쿼리 정말 나쁠까?
서브쿼리는 위에 언급한 내용들처럼 많은 단점들을 가지고 있다. 하지만 서브쿼리 자체가 나쁜 것은 아니고, 서브쿼리를 사용하지 않으면 해결할 수 없는 상황들도 있다.
또한 처음 쿼리를 고민하는 경우에는 서브쿼리를 사용해 문제를 분할하여 생각해보며 쿼리를 보다 쉽게 작성할 수 있다. 다만 SQL에서는 코드 레벨에서 볼 때, 이런 방식은 효율적이지 않을 뿐이다.
서브쿼리 사용이 더 나은 경우
결합과 집약 순서 정해주기
결합을 사용해야만 하는 경우에는 결합 시 집약을 통해 최대한 결합 대상 레코드 수를 줄이는 것이 좋다. 옵티마이저에서 이를 잘 판별하지 못하는 경우가 있어, 이런 경우에는 서브쿼리를 통해 사람이 명시해주면 성능적으로 더 좋은 결과를 얻을 수 있다.
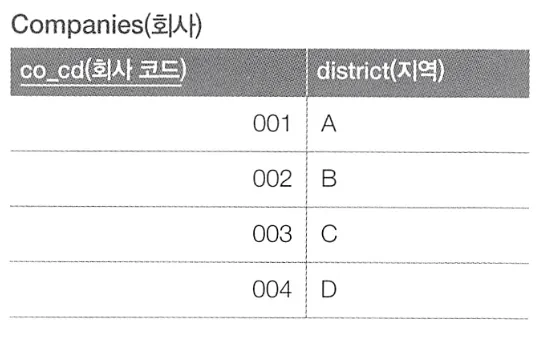
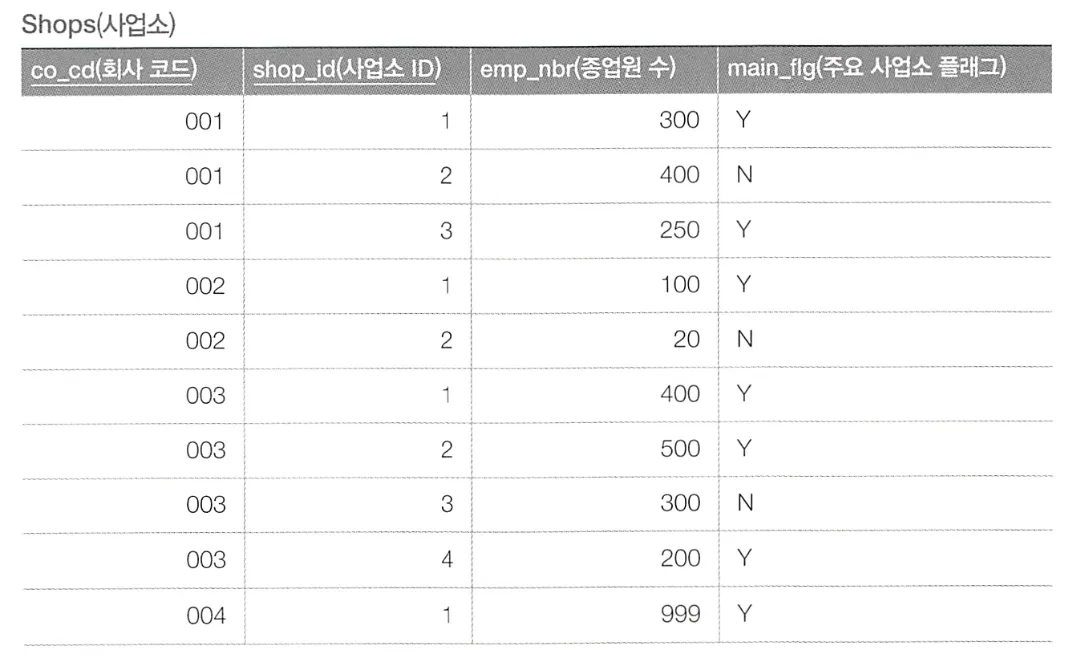
이러한 두 테이블이 있고, 두 테이블을 사용해 회사마다 주요 사업소의 지역과 직원 수를 구하고자 한다.

이를 구할 수 있는 방법은 두 가지가 있다.
1.
결합 → 집약
SELECT C.co_cd, MAX(C.district), SUM(emp_nbr) AS sum_emp
FROM Companies C
INNER JOIN Shops S ON C.co_cd = S.co_cd
WHERE main_flg = 'Y' GROUP BY C.co_cd;
SQL
복사

2.
집약 → 결합
SELECT C.co_cd, C.district, sum_emp
FROM Companies C
INNER JOIN (SELECT co_cd, SUM(emp_nbr) AS sum_emp
FROM Shops
WHERE main_flg = 'Y' GROUP BY co_cd) CSUM
ON C.co_cd = CSUM.co_cd;
SQL
복사

두 방법 모두 같은 결과를 만들어내고 비슷한 가독성을 가지지만, 성능상에서 차이를 보인다.
•
결합 → 집약 방식 : 회사 레코드 4개 / 사업소 레코드 10개
•
집약 → 결합 방식 : 회사 레코드 4개 / 사업소 레코드(CSUM) 4개
만약 각 테이블의 레코드 수가 1000개, 500만개로 회사 테이블에 비해 사업소 테이블의 데이터가 훨씬 많다면, 이는 엄청난 차이를 만들어 낸다.
다만 집약을 먼저하게 되면 집약 비용이 커지지만, TEMP 탈락이 발생하지만 않는다면 괜찮은 트레이드 오프로 볼 수 있다.