
레코드에 순번 붙이기
순서 조작을 하기위해, 레코드에 순번을 붙이는 방법을 살펴보자.
기본 키가 한 개의 필드인 경우
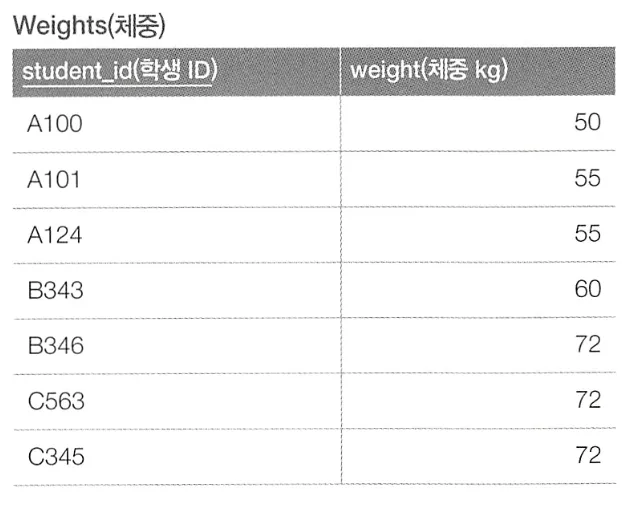
이와 같은 테이블에서 학생 ID를 오름차순으로 붙여보고자 한다.
SELECT student_id, ROW_NUMBER() OVER (ORDER BY student_id) AS seq
FROM Wegiths;
SQL
복사

MySQL처럼 ROW_NUMBER 함수를 사용할 수 없다면 아래와 같이 상관 서브쿼리를 사용해야 한다.
SELECT student_id, (SELECT COUNT(*) FROM Weights W2
WHERE W2.student_id <= W1.student_id) AS seq
FROM Weights W1;
SQL
복사

이전 장에서 언급한 것처럼, 테이블에 대해 2번 접근하기 때문에 가급적 윈도우 함수를 사용하는 것이 좋다.
기본 키가 여러 개의 필드로 구성되는 경우
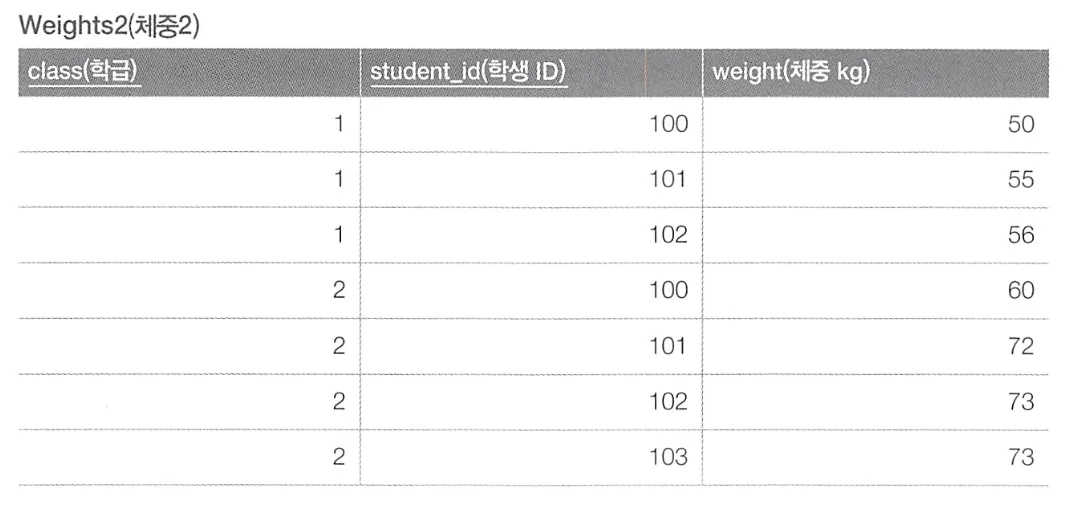
class와 student_id 두 개의 필드를 기본 키로하는 위의 테이블에서 순서를 매기는 방법은 아래와 같다.
// 윈도우 함수 사용
SELECT class, student_id,
ROW_NUMBER() OVER (ORDER BY class, student_id) AS seq
FROM Weights2;
// 상관 서브쿼리 사용
SELECT class, student_id,
(SELECT COUNT(*) FROM Weigths2 W2
WHERE (W2.class, W2.student_id)
<= (W1.class, W1.student_id) AS seq
FROM Weights2 W1;
SQL
복사
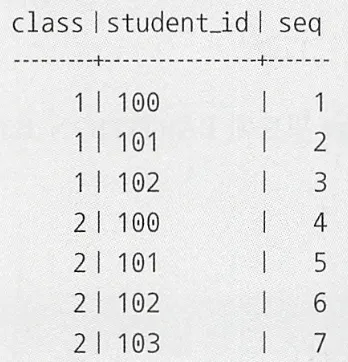
서브 상관쿼리는 다중 필드 비교를 통해 여러 복합적인 필드를 하나의 값으로 연결하여 한번에 비교하였다.
그룹마다 그룹 내 순번을 붙이는 경우
학급마다 순번을 붙이기 위해서는, 윈도우 함수 PARTITION BY를 사용하거나 테이블을 그룹으로 나누고 그룹마다 내부 레코드에 순번을 붙이는 방식을 사용해야한다.
// 윈도우 함수를 사용
SELECT class, student_id,
ROW_NUMBER() OVER (PARTITION BY class
ORDER BY student_id) AS seq
FROM Weights2;
// 상관 서브쿼리를 사용
SELECT class, student_id,
(SELECT COUNT(*) FROM Weight2 W2
WHERE W2.class = W1.class
AND W2.student_id <= W1.student_id) AS seq
FROM Weigths2 W1;
SQL
복사

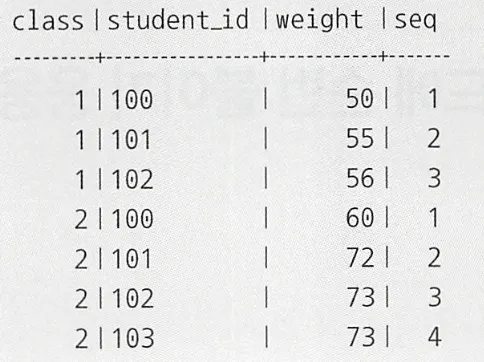
갱신으로 순번 매기기
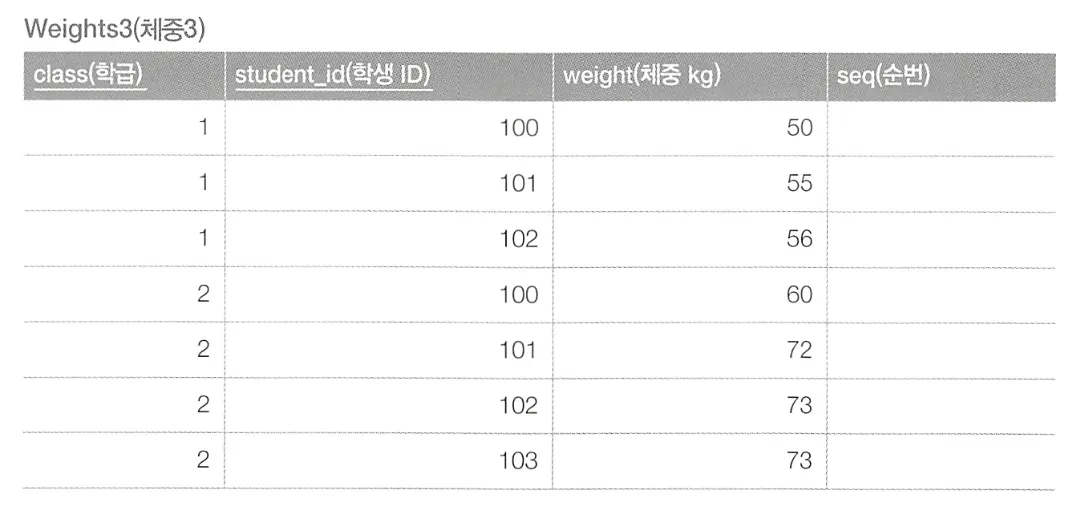
이런 seq 필드를 가지는 테이블에서, 필드에 순번을 갱신하는 UPDATE 구문을 만들고자 한다.


레코드에 순번 붙이기 - 응용
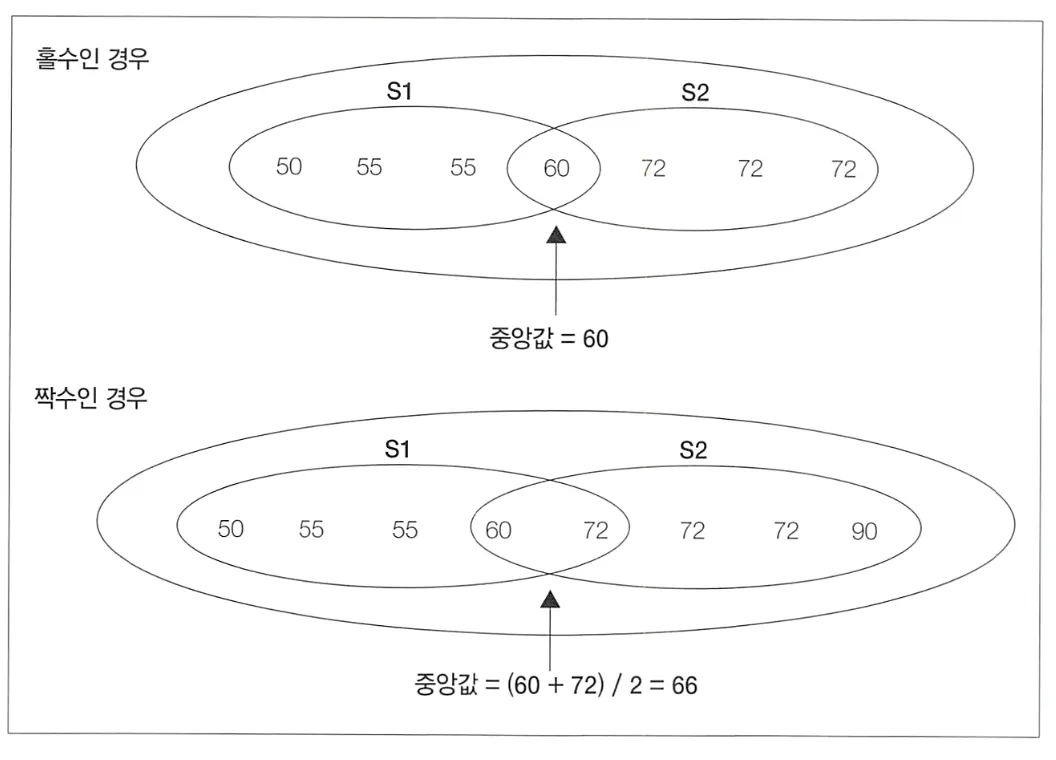
중앙값(median) 구하기
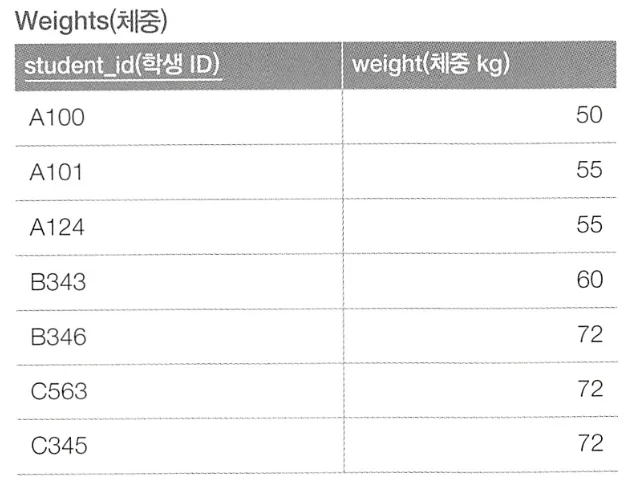
홀수개 레코드, 중앙값 = 60
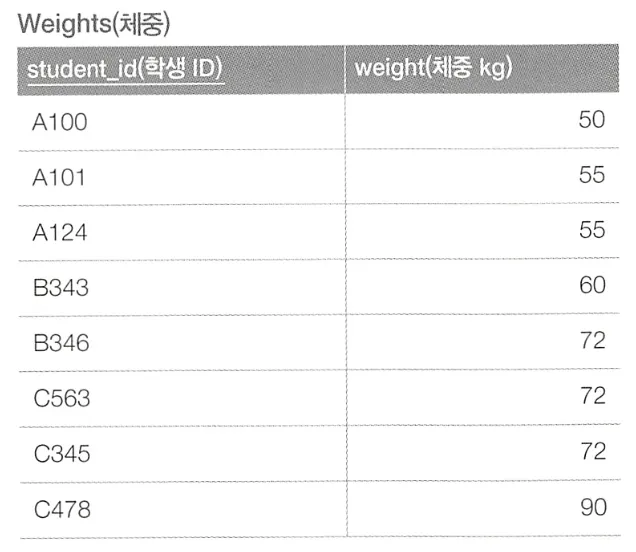
짝수개 레코드, 중앙값 = 66 (중앙값 두 개의 평균)
•
집합 지향적 방법
SELECT AVG(weight)
FROM (SELECT W1.weight FROM Weights W1, Weights W2
GROUP BY W1.weight
HAVING SUM(CASE WHEN W2.weight >= W1.weight
THEN 1 ELSE 0 END) >= COUNT(*) / 2
AND SUM(CASE WHEN W2.weight <= W1.weight
THEN 1 ELSE 0 END) >= COUNT(*) /2) TMP;
SQL
복사
HAVING 구를 통해 상위 집합과 하위 집합으로 분할 후 두 집합의 교집합을 구해 AVG로 평균값을 구하는 방법이다. 가장 SQL스러운 방법이지만, 코드가 복잡해서 무엇을 하고 있는지 직관적으로 이해가 잘 안되고 성능이 나쁘다.

이전에 언급했듯이 자기 결합 때문에 Weights 테이블에 두 번 접근하는 것은 물론 불안정한 실행 계획 리스크를 가지고 있다.
•
절차 지향적 방법
SELECT AVG(weight) AS median
FROM (SELECT weight,
ROW_NUMBER() OVER (ORDER BY weight ASC,
student_id ASC) AS hi,
ROW_NUMBER() OVER (ORDER BY weight DESC,
student_id DESC) AS lo
FROM Weight) TMP
WHERE hi IN (lo, lo+1, lo-1);
SQL
복사
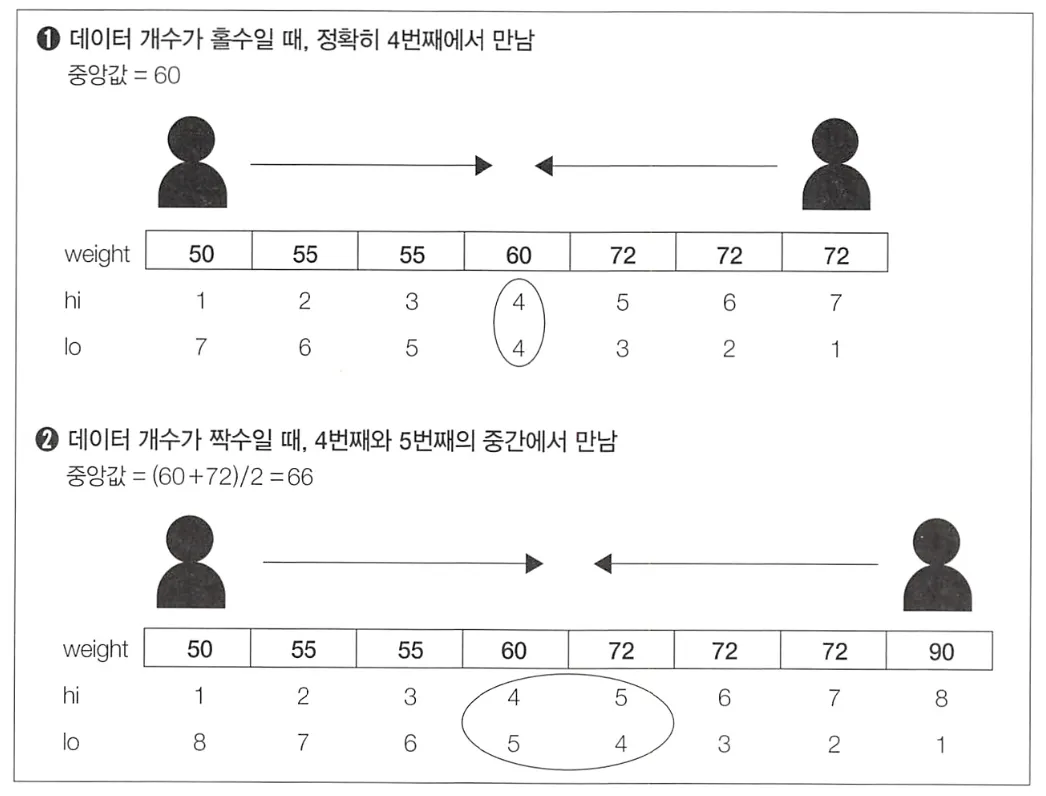
그림과 같이 ROW_NUMBER 윈도우 함수를 통해 얻은 오름차순과 내림차순 행 번호가 1만큼 차이가 나는 경우에 대해서 선택하는 방법이다. 중요한 것은 RANK나 DENSE_RANK 함수는 2위 다음에 4위가 오거나 5위가 두 명이 되는 경우가 있어 꼭 ROW_NUMBER 함수를 사용해야한다는 것이다. 또한 student_id를 같이 정렬해주어야지 NULL이 되는 것을 방지할 수 있다.

Weights 테이블에 대한 접근이 1회로 줄고, 결합이 사용되지 않는 것을 볼 수 있다. 대신 정렬이 2번 발생한다.
•
절차 지향적 방법 - 개선하기
SELECT AVG(weight)
FROM (SELECT weight,
2 * ROW_NUMBER() OVER(ORDER BY weight)
- COUNT(*) OVER() AS diff
FROM Weights) TMP
WHERE diff BETWEEN 0 AND 2;
SQL
복사
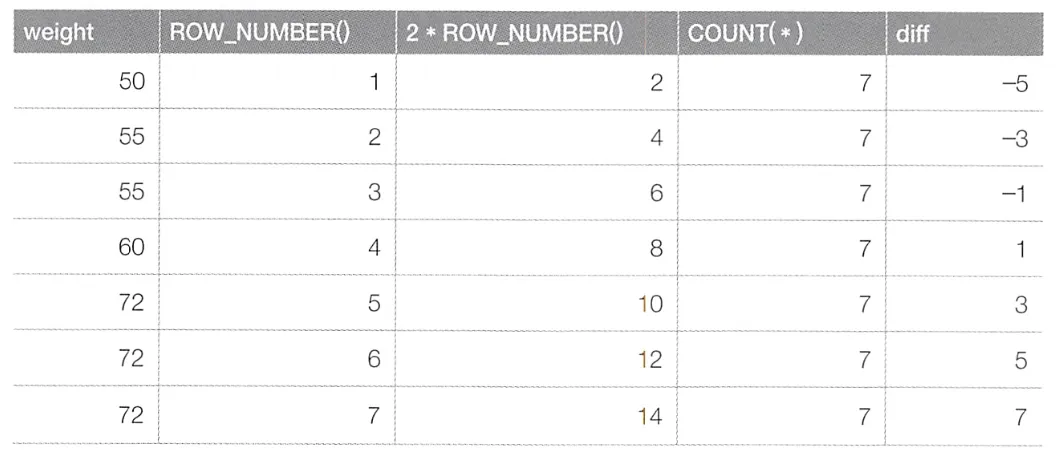
COUNT 함수의 OVER에 ORDER BY 구가 없으므로 정렬을 1번만 한다.

순번을 사용한 테이블 분할
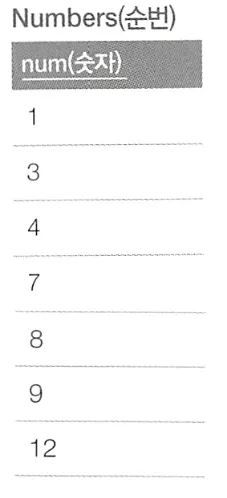
위와 같은 테이블에서 아래처럼 비어있는 구간들을 출력하고자 한다.

•
집합 지향적 방법
SELECT (N1, num + 1) AS gap_start, '~',
(MIN(N2.num) - 1) AS gap_end
FROM Numbers N1 INNER JOIN Numbers N2 ON N2.num > N1.num
GROUP BY N1.num HAVING (N1.num + 1) < MIN(N2.num);
SQL
복사

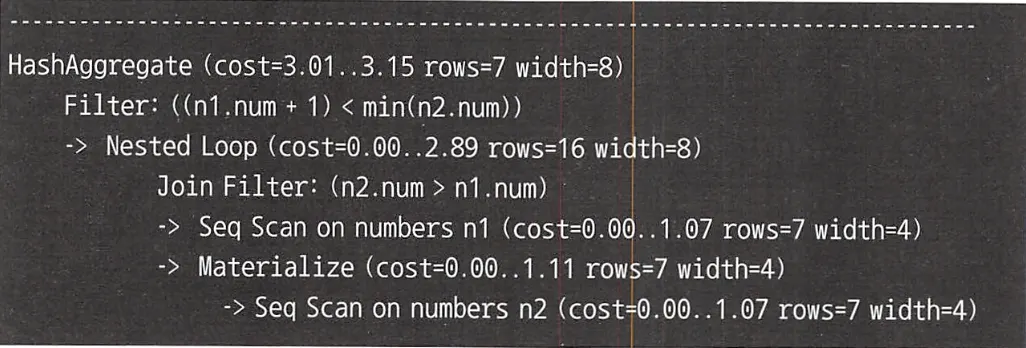
코드도 간단하고 집합 지향적이지만, 실행 계획을 보면 이 역시 자기 결합을 사용하기 때문에 Numbers 테이블에 2번 접근하고 Nested Loops로 결합이 발생해 비용이 높다.
•
절차 지향적 방법
SELECT num + 1, AS gap_start, '~', (num + diff + 1) AS gap_end
FROM (SELECT num,
MAX(num) OVER (ORDER BY num
ROWS BETWEEN 1 FOLLOWING
AND 1 FOLLOWING) - num
FROM Numbers) TMP(num,diff)
WHERE diff <> 1;
SQL
복사

자기 결합을 사용하지 않기 때문에 테이블 접근도 한 번만 이루어지고, 윈도우 함수에서 정렬이 실행돼 성능히 굉장히 안정적이다.
테이블에 존재하는 시퀀스 찾기
위의 Numbers 테이블에서 아래와 같은 시퀀스를 구해보자.

•
집합 지향적 방법
SELECT MIN(num) AS low, '~', MAX(num) AS high
FROM (SELECT N1.num, COUNT(N2.num) - N1.num
FROM Numbers N1
INNER JOIN Numbers N2 ON N2.num <= N1.num
GROUP BY N1.num) N(num,go)
GROUP BY gp;
SQL
복사

환경에 따라 인덱스 스캔이 될 수 도 있지만 결국 테이블에 2번 접근하고, 정렬이 아닌 해시 알고리즘이 사용되었다.
•
절차 지향적 방법


TMP1과 TMP2에서 정렬이 2회 발생하지만, 테이블에 대한 접근이 한 번만 이루어진다. 다만 TMP1과 TMP2에 대해 서브쿼리 스캔이 발생하는데, 서브 쿼리 결과를 일시 테이블에 전개하고 이 일시 테이블이 크다면 비용이 높아질 가능성이 있다.
시퀀스 객체, IDENTITY 필드, 채번 테이블
표준 SQL에는 시퀀스 객체와 IDENTITY 필드가 존재하지만, 이 두 가지 기능은 최대한 사용하지 않는 것이 좋다.
시퀀스 객체
시퀀스 객체는 테이블이나 뷰처럼 스키마 내부에 존재하는 객체 중 하나로, 아래처럼 테이블이나 뷰를 생성할 때 사용하는 CREATE 구문으로 정의할 수 있다.
CREATE SEQUENCE testseq
START WITH 1
INCREMENT BY 1
MAXVALUE 100000
MINVALUE 1
CYCLE;
SQL
복사
구현환경에 따라 차이가 있지만, START(초기값), INCREMENT(증가값), MAXVALUE(최대값), MINVALUE(최소값), CYCLE(최대값에 도달했을 때 순환 유무) 등의 옵션이 있다.
시퀀스 객체는 주로 INSERT 구문에서 자주 사용된다.
INSERT INTO HogeTbl VALUES(NEXT VALUE FOR nextval, 'a', 'b', ...);
SQL
복사
시퀀스 객체로 만들어진 순번을 기본 키로 사용해 레코드를 삽입한다.
•
시퀀스 객체의 문제점
시퀀스 객체는 세 가지 측면에서 문제가 있다.
1.
표준화가 늦어서, 구현에 따라 구문 이식성이 없고 사용할 수 없는 구현도 있다.
2.
시스템에서 자동으로 생성되는 값이므로 실제 엔티티 속성이 아니다.
3.
성능적인 문제
사실 1번은 구현 간 이식성을 신경쓰지 않으면 되고, 2번은 무시하고 그냥 사용하면 된다. 하지만 성능적인 문제는 무시할 수 없다.
시퀀스 객체가 생성하는 순번은 기본적으로 유일성, 연속성, 순서성을 가진다.
유일성은 중복값이 생성되지 않는다는 것이고 연속성은 생성된 값에 비어있는 부분이 없다는 것이다. 순서성은 순번의 대소 관계가 역전되지 않는다는 의미이다. 연속성과 순서성은 옵션 설정에 따라 배제 할 수 있다.
시퀀스 객체는 이런 세 가지 성질을 모두 만족하는 순번을 생성하는데, 동시 실행 제어를 위해 락(lock) 메커니즘이 필요하다. 동시에 여러 사용자가 시퀀스 객체에 접근하는 경우 락 충돌로 인해 성능 저하 문제가 발생하고, 한 명의 사용자가 사용하는 경우에도 락으로 인한 오버헤드가 발생한다.
시퀀스 객체로 인한 이러한 성능 저하는 CACHE와 NOORDER 객체를 통해 완화할 수 있다.
CACHE를 통해 메모리에 값을 저장해두어 접근 비용을 줄 일 수 있다. 하지만 부작용으로 시스템 장애가 발생할 때 연속성을 담보할 수 없다.
NOORDER는 순서성을 담보하지 않아 오버 헤드를 줄이지만, 반대로 순서성을 보장하고 싶다면 사용할 수 없다.
시퀀스 객체가 성능 문제를 일으키는 두 번째 경우는 핫 스팟(Hot Spot)과 관련된 문제이다. 순번처럼 비슷한 데이터를 연속적으로 INSERT하면 물리적으로 같은 영역에 저장되는데, 저장소의 특정 물리적 블록에만 I/O 부하가 커져 성능 악화가 발생하고 이를 핫 스팟(Hot Spot) 혹은 핫 블록(Hot Block)이라 부른다.
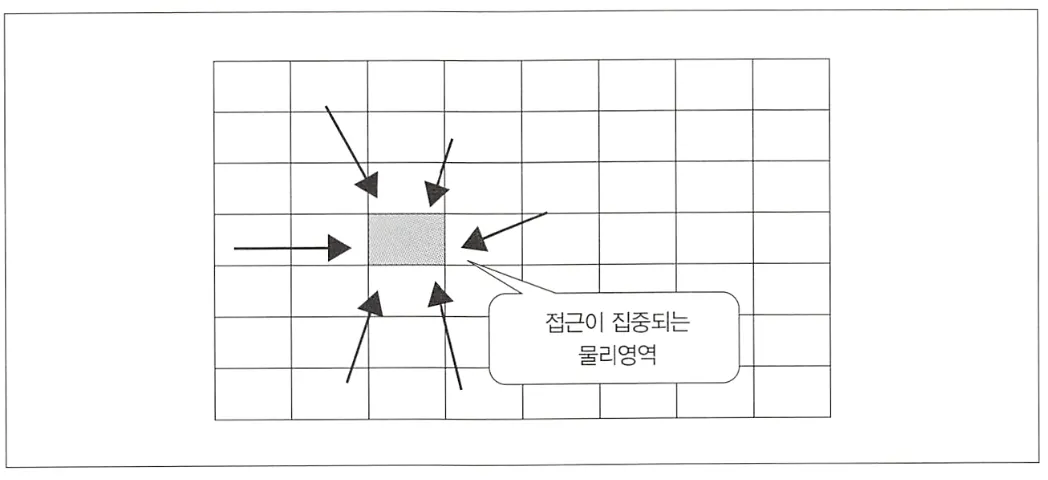
이는 시퀀스 객체 특유의 문제는 아니지만, 시퀀스 객체를 사용할 때는 거의 확실하게 나타나는 문제이다. 물리 계층의 접근 패턴을 사용자가 명시적으로 바꾸는게 불가능하기 때문에, 이런 문제는 대처하기가 거의 불가능하다.
핫 스팟 관련 문제는 Oracle의 역 키 인덱스처럼, 연속된 값을 도입하더라도 DBMS 내부에서 변화를 주어 분산할 수 있는 구조를 사용하여 완화할 수 있다. 또는 인덱스에 일부러 복잡한 필드를 추가해, 데이터의 분산도를 높이는 방법도 있다.
하지만 이런 방법들에는 트레이드 오프가 있다. 역 키 인덱스 구조를 사용하면 INSERT 구문 자체는 빨라지지만 범위 검색 등에서 I/O 양이 늘어 SELECT 구문의 성능이 나빠질 위험이 있고, 인덱스에 복잡한 필드를 추가하는 것은 구현 의존적인 방법이라 좋은 설계가 아니다.
그러니 시퀀스 객체는 최대한 사용하지 말자.
IDENTITY 필드
IDENTITY 필드는 테이블의 필드로 정의하고 테이블에 INSERT가 발생할 대마다 자동으로 순번을 붙여주는 기능으로, 자동 순번 필드라고도 불린다.
IDENTITY 필드는 기능적 측면과 성능적 측면에서 시퀀스 객체보다 심각한 문제를 가진다.
기능적 측면으로는 시퀀스 객체는 테이블과 독립적이므로 여러 테이블에서 사용할 수 있지만, IDENTITY 필드는 특정한 테이블과 연결된다.
성능적 측면으로는 시퀀스 객체는 CACHE나 NOORDER를 지정할 수 있지만, IDENTITY 필드는 구현에 따라 사용할 수 없거나 제한적으로만 사용할 수 있다.
이러한 이유로 IDENTITY 필드를 사용하는 이점은 거의 없다.
채번 테이블
최근에는 거의 찾아볼 수 없지만, 옛날에 만들어진 어플리케이션에서는 시퀀스 객체와 IDENTITY 필드를 모두 지원하지 않던 시기여서 순번을 생성하는 전용 테이블인 채번 테이블을 사용하는 경우가 꽤 있었다.
이러한 채번 테이블 역시 성능이 제대로 나오지 않으며, 시퀀스 객체의 CACHE나 NOORDER 같은 개선 방법도 없다. 그런 이유로 채번 테이블 역시 사용할 이유가 전혀 없다.