

이전 리팩토링 결과
이전에 층 전체 사물함 조회 Query 리팩토링하기라는 이름으로 List<Object> 형태의 Repository를 N+1 문제가 발생하는 형태로 리팩토링한 적이 있다. 사실 해당 리팩토링은 결과를 떠나서 리팩토링 하는 과정에서 정말 많은 것을 배우고 공부할 수 있었지만, 결과적으로는 속도 이슈로 인해 프로젝트에 반영되지 못했다.
추후 wchae님이 ComplexRepository라는 새로운 Repository를 파고, List<Object> 형태를 ComplexEntities 형태로 새로운 클래스를 선언하여 리팩토링 해두셨다. 기존의 구조와 로직을 그대로 가져가면서 책임의 분리와 형태만을 감싸 리팩토링 했기 때문에, 이전 글에서 언급했던 단일책임원칙과 유지보수성을 만족하면서도 속도 측면에서도 문제가 없다.
현재에 와서 해당 코드를 공부해보다가, 문득 내가 이전 리팩토링을 진행할 당시 여러 Entity를 주체로 조회해오는 저런 방식이 왜 속도가 빠른지에 대해서는 전혀 이해하지 못하고 넘어갔다는 것을 깨달았다. 그 이유를 찾아서 직접 DB에 쿼리를 날려가면서 왜 빠른지 나름의 분석해본 결과는 아래와 같다.

위의 실행계획을 살펴보면, cabinet_place 테이블을 먼저 테이블 풀 스캔으로 접근한다. 그 후 cabinet 테이블에 접근을 하는데, 이를 잘 살펴보면 type이 ref로 되어 있는 것을 볼 수 있다. 이는 인덱스 스캔이 이루어지는 것을 말하는데, Cabi에는 인덱스를 따로 만들지 않았는데 이게 왜? 라는 생각이 들어서 찾아보았다.

cabinet 테이블에 생성되어있는 인덱스를 살펴보면, cabinet_place_id로 인덱스가 생성되어 있다.
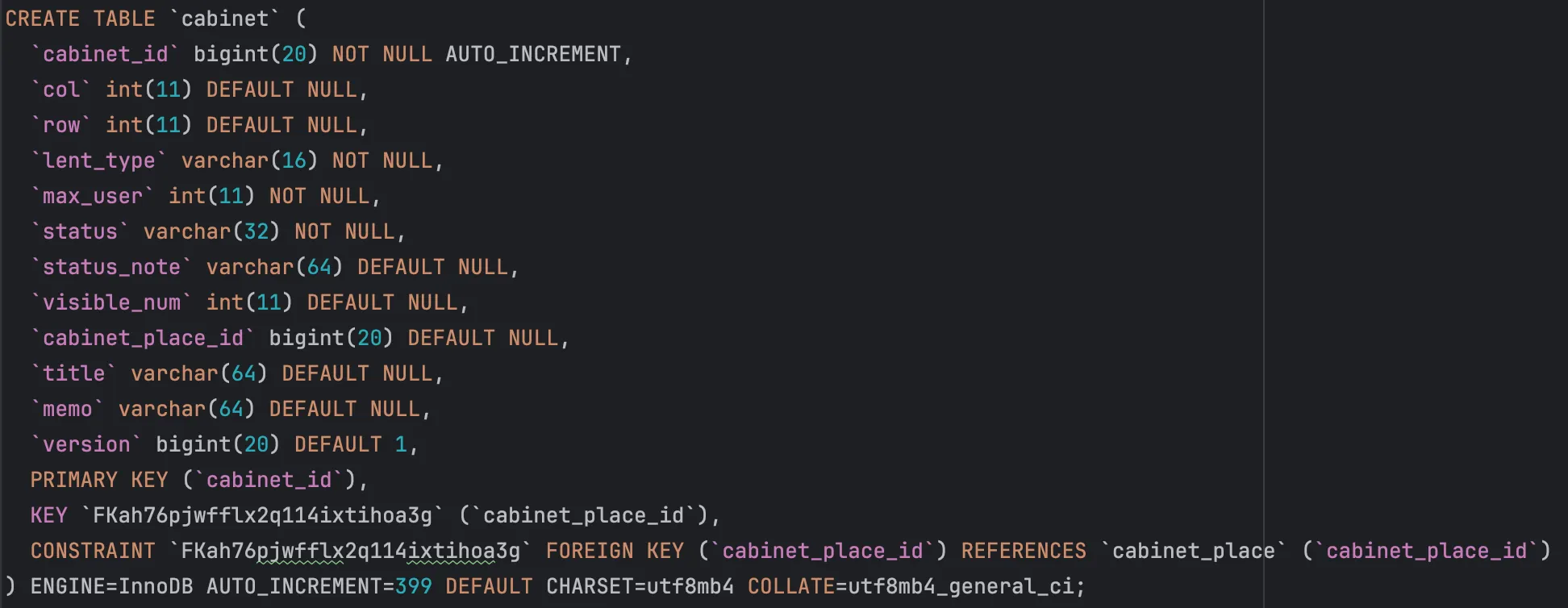
이처럼 cabinet 테이블에 cabinet_place_id로 외래 키 + 유니크 제약 조건을 걸면, 따로 인덱스를 생성하지 않더라도 자동으로 생성하기 때문이다.
동일한 이유로 cabinet → lent_history, lent_history → user 순으로 조회할 때 전부 외래 키와 유니크 제약 조건으로 인해 이미 인덱스가 생성되어있기 때문에, 각 테이블에 접근할 때 인덱스 검색을 통해 수행되어 빠른 것이다.
다시 리팩토링하기로 한 이유
리팩토링을 다시 하고자 결심한 이유는 해당 코드를 분석하는 도중에, 로직이 직관적이지 않고 가독성 측면에서 개선할 여지가 있다고 느껴 리팩토링하고자 한다.
@Override
public List<CabinetsPerSectionResponseDto> getCabinetsPerSectionDSL(String building,
Integer floor) {
log.debug("getCabinetsPerSection");
List<ActiveCabinetInfoEntities> currentLentCabinets = cabinetOptionalFetcher.findCabinetsActiveLentHistoriesByBuildingAndFloor2(
building, floor);
List<Cabinet> allCabinetsByBuildingAndFloor = cabinetOptionalFetcher.findAllCabinetsByBuildingAndFloor(
building, floor);
Map<Cabinet, List<LentHistory>> cabinetLentHistories = currentLentCabinets.stream().
collect(groupingBy(ActiveCabinetInfoEntities::getCabinet,
mapping(ActiveCabinetInfoEntities::getLentHistory,
Collectors.toList())));
Map<String, List<CabinetPreviewDto>> cabinetPreviewsBySection = new HashMap<>();
cabinetLentHistories.forEach((cabinet, lentHistories) -> {
String section = cabinet.getCabinetPlace().getLocation().getSection();
CabinetPreviewDto preview = createCabinetPreviewDto(cabinet, lentHistories);
if (cabinetPreviewsBySection.containsKey(section)) {
cabinetPreviewsBySection.get(section).add(preview);
} else {
List<CabinetPreviewDto> previews = new ArrayList<>();
previews.add(preview);
cabinetPreviewsBySection.put(section, previews);
}
});
allCabinetsByBuildingAndFloor.forEach(cabinet -> {
if (!cabinetLentHistories.containsKey(cabinet)) {
String section = cabinet.getCabinetPlace().getLocation().getSection();
CabinetPreviewDto preview = createCabinetPreviewDto(cabinet,
Collections.emptyList());
if (cabinetPreviewsBySection.containsKey(section)) {
cabinetPreviewsBySection.get(section).add(preview);
} else {
List<CabinetPreviewDto> previews = new ArrayList<>();
previews.add(preview);
cabinetPreviewsBySection.put(section, previews);
}
}
});
cabinetPreviewsBySection.values().forEach(cabinetList -> cabinetList.sort(
Comparator.comparing(CabinetPreviewDto::getVisibleNum)));
return cabinetPreviewsBySection.entrySet().stream()
.sorted(Comparator.comparing(entry -> entry.getValue().get(0).getVisibleNum()))
.map(entry -> cabinetMapper.toCabinetsPerSectionResponseDto(entry.getKey(),
entry.getValue()))
.collect(Collectors.toList());
}
Java
복사
저 ComplexEntities 구조를 그대로 가져가되 필요한 데이터만 Compact하게 가져오면, 네트워크의 부하나 메모리 상의 이점이 있다고 생각하여 직접 쿼리를 작성해보며 속도를 비교해보았다.
쿼리 속도 비교
select distinct *
from cabinet c
join cabinet_place cp on c.cabinet_place_id = cp.cabinet_place_id
join lent_history lh on lh.cabinet_id = c.cabinet_id
join user u on u.user_id = lh.user_id
where cp.floor = 2 and lh.ended_at is null;
SQL
복사
기존의 로직과 동일하게 쿼리를 작성하여 쿼리의 동작 시간을 확인해보았을 때 22ms 정도 걸렸다.
select distinct *
from cabinet c
join cabinet_place cp on c.cabinet_place_id = cp.cabinet_place_id
join lent_history lh on lh.cabinet_id = c.cabinet_id
join user u on u.user_id = lh.user_id
where cp.floor = 2 and lh.ended_at is null
order by visible_num;
SQL
복사
여기에 visible_num 순으로 정렬을 시도하면 25ms 정도로 약간 늘어났다.
그렇다면 이 정도의 속도를 크게 해치지 않는 선에서 가져오는 데이터를 변형 해보자.
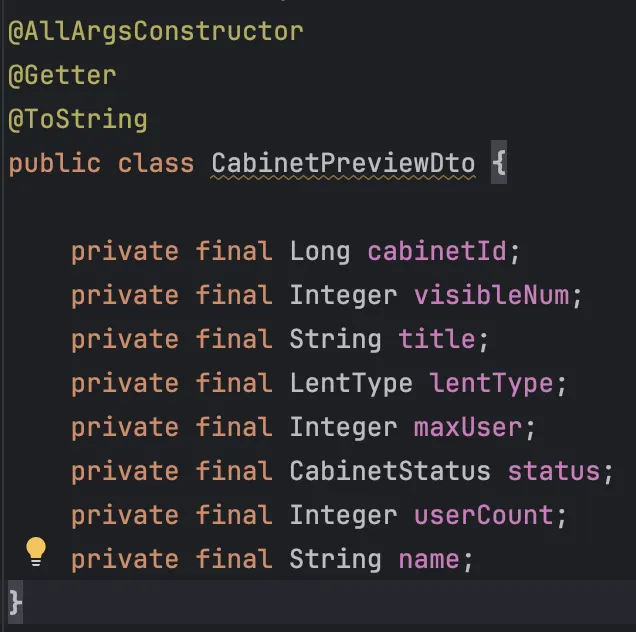
실제 응답으로 나가는 DTO를 살펴보면, 3중 Join 쿼리의 전체 데이터가 필요하지 않다. 이를 필요한 데이터만 가져오도록 선택해 쿼리를 날려보자.
select distinct cp.section, c.cabinet_id, c.visible_num, c.title,
c.lent_type, c.max_user, c.status, u.name
from cabinet c
join cabinet_place cp on c.cabinet_place_id = cp.cabinet_place_id
join lent_history lh on lh.cabinet_id = c.cabinet_id
join user u on u.user_id = lh.user_id
where cp.floor = 2 and lh.ended_at is null;
SQL
복사
이와 같이 필요한 데이터들만 선택하여 가져오면 쿼리의 속도가 19ms 정도로 약간 줄어든다.
select distinct cp.section, c.cabinet_id, c.visible_num, c.title,
c.lent_type, c.max_user, c.status, u.name
from cabinet c
join cabinet_place cp on c.cabinet_place_id = cp.cabinet_place_id
join lent_history lh on lh.cabinet_id = c.cabinet_id
join user u on u.user_id = lh.user_id
where cp.floor = 2 and lh.ended_at is null
order by visible_num;
SQL
복사
여기에 정렬 조건을 추가해도 18ms로 오차 범위 내로 무의미한 시간의 변화가 있었다.
이 쿼리의 결과는 정확히 위 DTO와 매칭 되지 않기 때문에, 순회를 하며 cabinet마다 대여하고 있는 name의 수를 세어 userCount와 대표 name을 설정해주는 별도의 비즈니스 로직이 필요하다.
그러던 중 SQL 레벨업 책에서 공부했던 윈도우 함수를 사용하면, 위 DTO에 딱 맞는 데이터를 가져올 수 있겠다 싶어 쿼리를 날려보았다.
select distinct cp.section, c.cabinet_id, c.visible_num, c.title,
c.lent_type, c.max_user, c.status,
count(lh.lent_history_id) over (partition by c.cabinet_id) as user_count,
max(u.name) over (partition by c.cabinet_id) as name
from cabinet c
join cabinet_place cp on c.cabinet_place_id = cp.cabinet_place_id
join lent_history lh on lh.cabinet_id = c.cabinet_id
join user u on u.user_id = lh.user_id
where cp.floor = 2 and lh.ended_at is null
order by visible_num;
SQL
복사
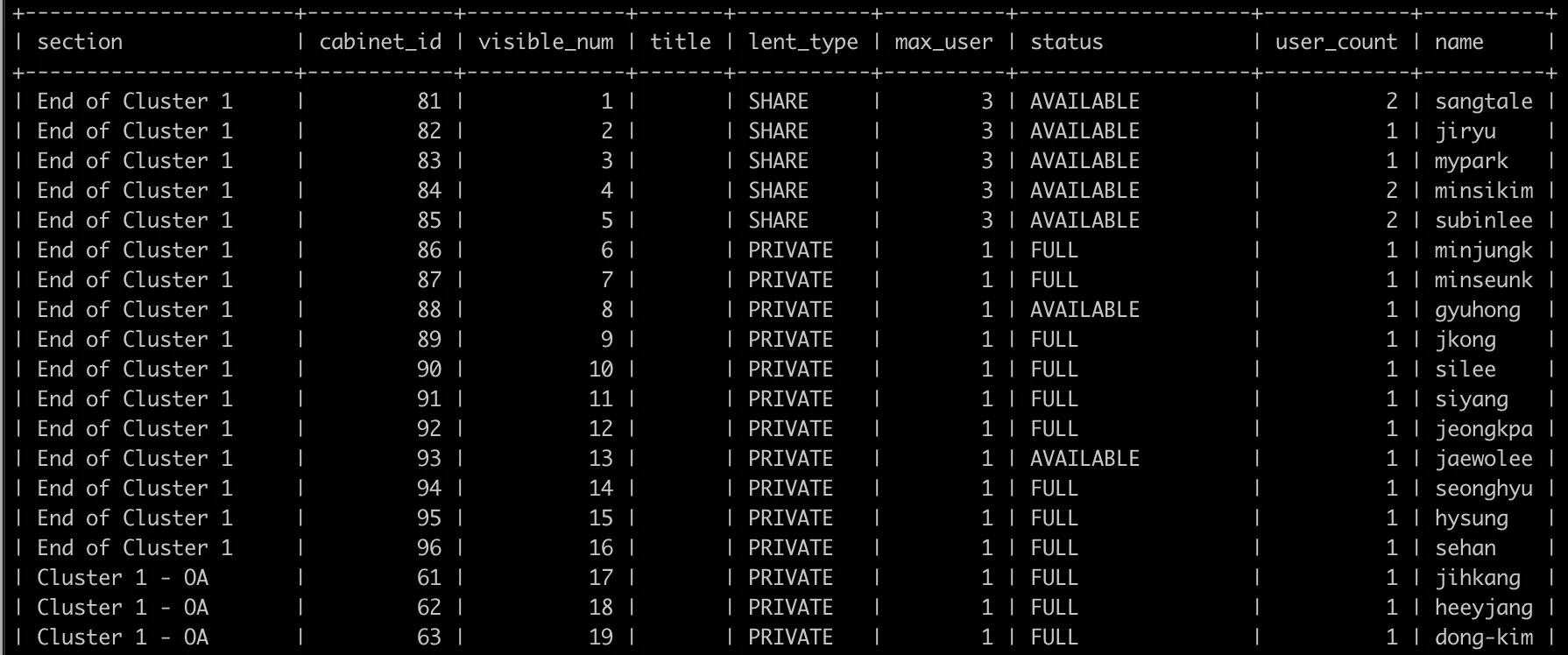
이처럼 원하는대로 데이터를 잘 조회해오고, 조회 속도도 17ms로 큰 변화가 없다.
이를 통해 비즈니스 로직부분을 해소할 수 있고 그로 인해 가독성이 좋아질 것임을 알지만, 윈도우 함수는 JPA나 JPQL에서 지원하지 않기 때문에 Native Query를 사용해야 한다는 단점이 있다. QueryDSL을 사용한 쿼리에서 Native Query로 변경되면서 성능이나 가독성, 유지보수성 측면에서 괜찮은가에 대해 고민하게 되었다.

이런 근거를 기반으로 Native Query를 작성해보았다.
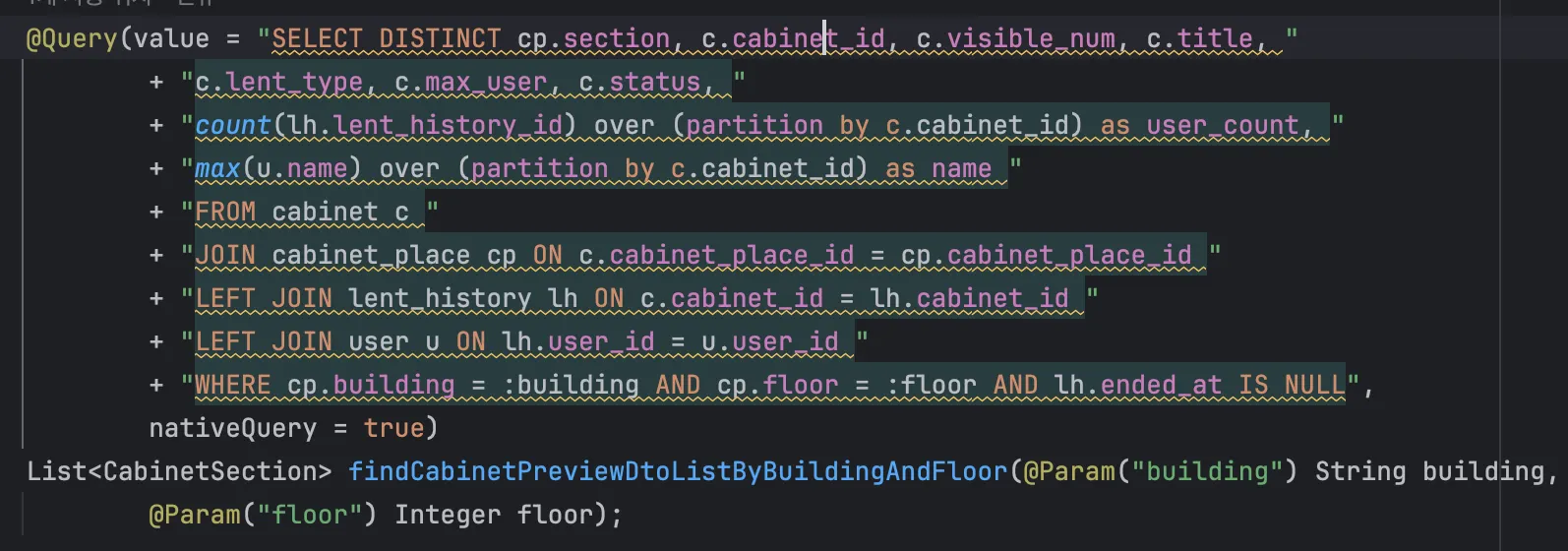
일단 쿼리 가독성이 상당히 좋지 못하다. 또한 해당 쿼리를 실행시켰을 때, 일부 값을 제대로 받아오지 못하고 윈도우 함수 부분도 잘 동작하지 않는다.
그리고 일단 Native Query의 경우 위처럼 반환값을 인터페이스로 받아야한다는 단점이 있다.
인터페이스를 Mapper를 통해 DTO로 변경하고 그 값을 section 기준으로 재구성하려다 보니, 생각보다 로직이 복잡해졌다. 사실 리팩토링 목적이 가독성 증가와 비즈니스 로직의 간편화였기 때문에, 이럴거면 차라리 쉽게 조회하던 이전 방법에서 비즈니스 로직만 조금 정리하는게 낫겠다는 생각이 들었다.
결과
@Override
public List<CabinetsPerSectionResponseDto> getCabinetsPerSection(String building,
Integer floor) {
log.debug("getCabinetsPerSection");
List<ActiveCabinetInfoEntities> currentLentCabinets = cabinetOptionalFetcher
.findCabinetsActiveLentHistoriesByBuildingAndFloor(building, floor);
Map<Cabinet, List<LentHistory>> cabinetLentHistories = currentLentCabinets.stream().
collect(groupingBy(ActiveCabinetInfoEntities::getCabinet,
mapping(ActiveCabinetInfoEntities::getLentHistory,
Collectors.toList())));
List<Cabinet> allCabinetsOnSection =
cabinetOptionalFetcher.findAllCabinetsByBuildingAndFloor(building, floor);
Map<String, List<CabinetPreviewDto>> cabinetPreviewsBySection = new LinkedHashMap<>();
allCabinetsOnSection.forEach(cabinet -> {
String section = cabinet.getCabinetPlace().getLocation().getSection();
List<LentHistory> lentHistories =
cabinetLentHistories.getOrDefault(cabinet, Collections.emptyList());
CabinetPreviewDto preview = createCabinetPreviewDto(cabinet, lentHistories);
cabinetPreviewsBySection.computeIfAbsent(section, k -> new ArrayList<>()).add(preview);
});
return cabinetPreviewsBySection.entrySet().stream()
.map(entry -> cabinetMapper.toCabinetsPerSectionResponseDto(entry.getKey(), entry.getValue()))
.collect(Collectors.toList());
}
Java
복사
결국 기존과 동일하게 ActiveCabinetInfoEntities 객체로 1번, 층 전체에 대해 Cabinet 1번으로 총 2번의 쿼리가 발생한다.
가져온 층 전체 사물함을 visibleNum을 기준으로 오름차순으로 순서대로 Map에 넣는다. 그 와중에 아까 가져온 ActiveCabinetInfoEntities를 Map으로 정리해둔 곳에서 lentHistory를 꺼내 Dto로 변환한다.
사실 비즈니스 로직은 조금 더 개선 되었지만, 가독성이 좋다는 느낌은 잘 모르겠다. 그리고 결국 Cabinet 한 층 전체를 조회하기 때문에, 이를 개선할 여지가 없는지를 많이 고민했다. 하지만 결국 데이터가 전부 채워져야 하는 부분이기도 하고, 사물함은 더 이상 증가되지 않는다는 점과 만약 Cabinet의 데이터가 너무 많아지는 경우가 있다면 그 때는 층이 아닌 Section별 조회와 같이 새로운 로직으로 작성하는 것이 맞다고 생각했다.