
갱신을 효율적으로
NULL 채우기

이와 같은 테이블에서, val 필드에 NULL 값 대신 같은 keycol의 이전 seq의 val 값을 그대로 저장하여 아래와 같이 만든다고 하자.

이는 상관 서브쿼리로 해결할 수 있다.
UPDATE OmitTbl
SET val = (SELECT val FROM OmitTbl OT1
WHERE OT1.keycol = OmitTbl.keycol
AND OT1.seq = (SELECT MAX(seq)
FROM OmitTbl OT2
WHERE OT2.keycol = OmitTbl.keycol
AND OT2.seq < OmitTbl.seq
AND OT2.val IS NOT NULL))
WHERE val IS NULL;
SQL
복사

PostgreSQL 실행 계획
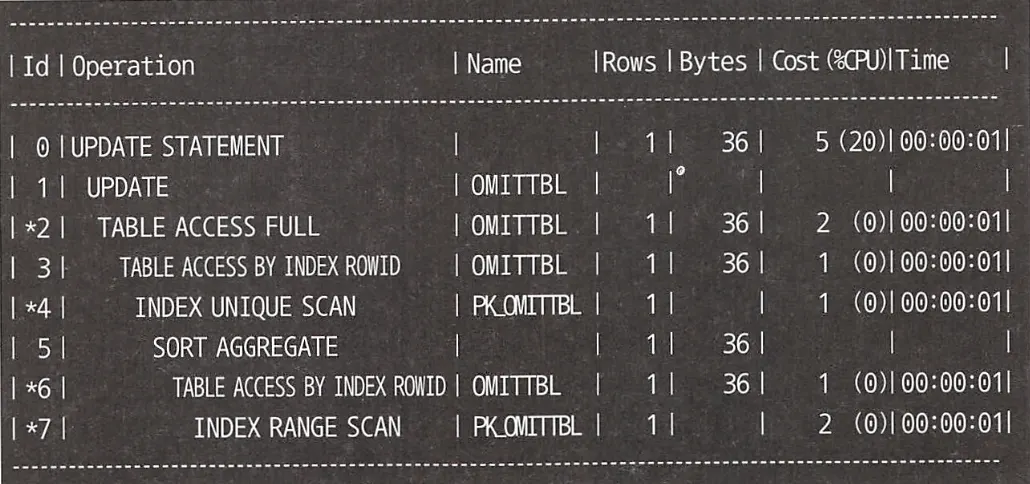
Oracle 실행 계획
Oracle에서 보면 기본적으로 테이블 풀 스캔을 사용하지만, 내부의 2개의 서브쿼리는 기본 키 인덱스를 사용하는 것을 확인할 수 있다. PostgreSQL도 데이터양이 늘어난다면 이와 같이 인덱스를 사용해 실행 계획을 만들 가능성이 크다.
NULL 되돌리기
반대로 위에서 채운 값들을 NULL로 되돌리는 작업은 다음과 같다.
UPDATE OmitTbl
SET val = CASE WHEN val
= (SELECT val FROM OmitTbl O1
WHERE O1.keycol = OmitTbl.keycol
AND O1.seq
= (SELECT MAX(seq) FROM OmitTbl O2
WHERE O2.keycol = OmitTbl.keycol
AND O2.seq < OmitTbl.seq))
THEN NULL ELSE val END;
SQL
복사
이 실행 계획은 위의 NULL을 채우는 실행 계획가 거의 동일하게 작성된다.
레코드에서 필드로의 갱신
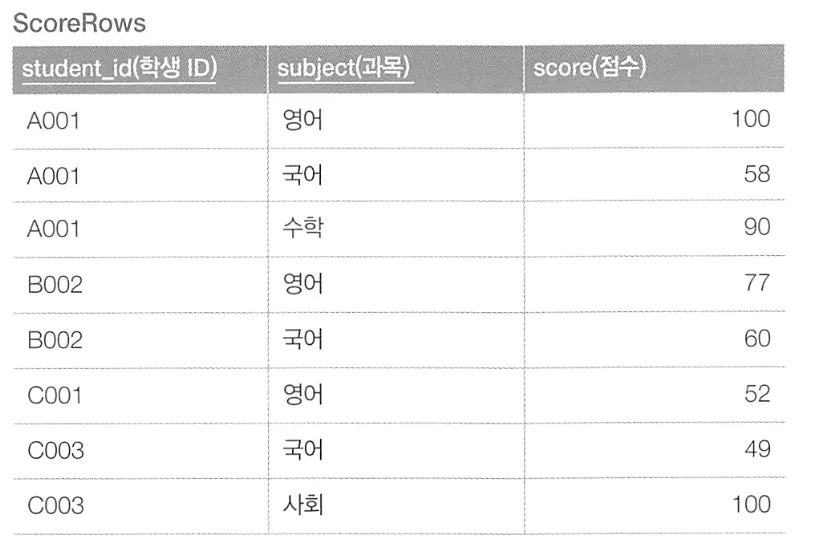
위 테이블에서 정보를 편집하여 아래와 같이 새로운 테이블에 레코드를 복사하고자 한다.

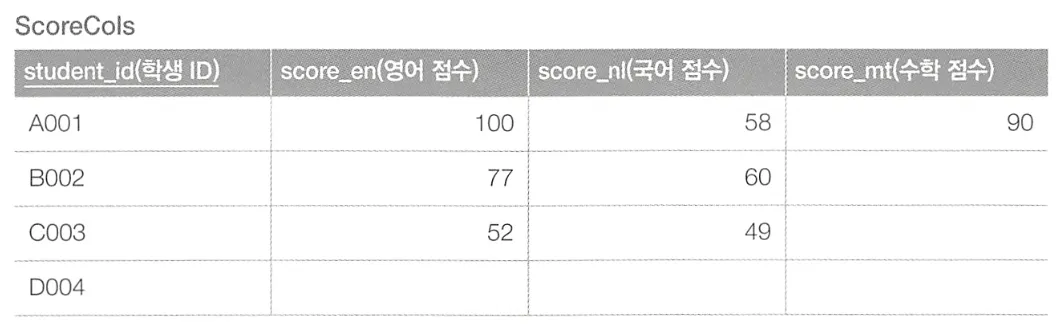
필드를 하나씩 갱신
UPDATE ScoreCols
SET score_en = (SELECT score FROM ScoreRows SR
WHERE SR.student_id = ScoreCols.student_id
AND subject = '영어'),
score_nl = (SELECT score FROM ScoreRows SR
WHERE SR.student_id = ScoreCols.student_id
AND subject = '국어'),
score_mt = (SELECT score FROM ScoreRows SR
WHERE SR.student_id = ScoreCols.student_id
AND subject = '수학');
SQL
복사
이와 같은 SQL 쿼리는 간단하고 명확하지만 3개의 상관 서브 쿼리를 실행하기 때문에 성능적으로 좋지 않다.
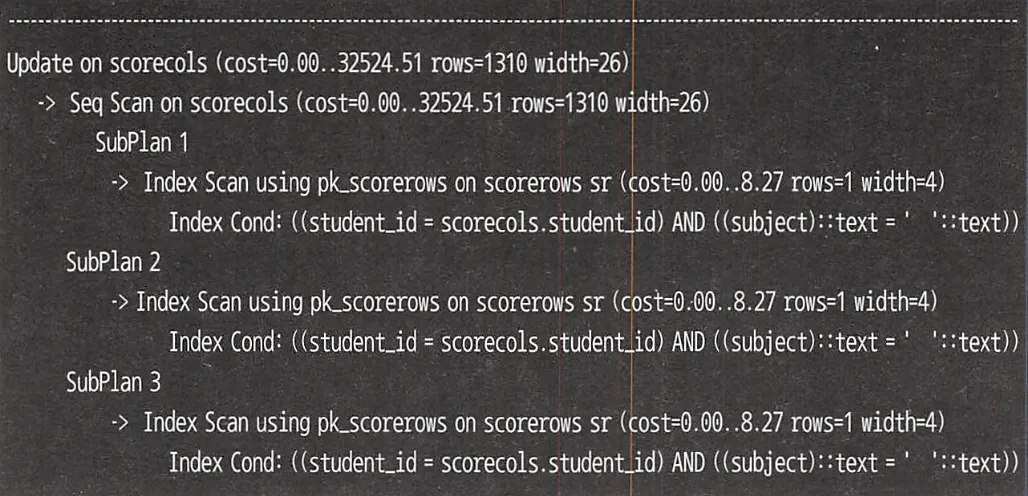
PostgreSQL 실행 계획
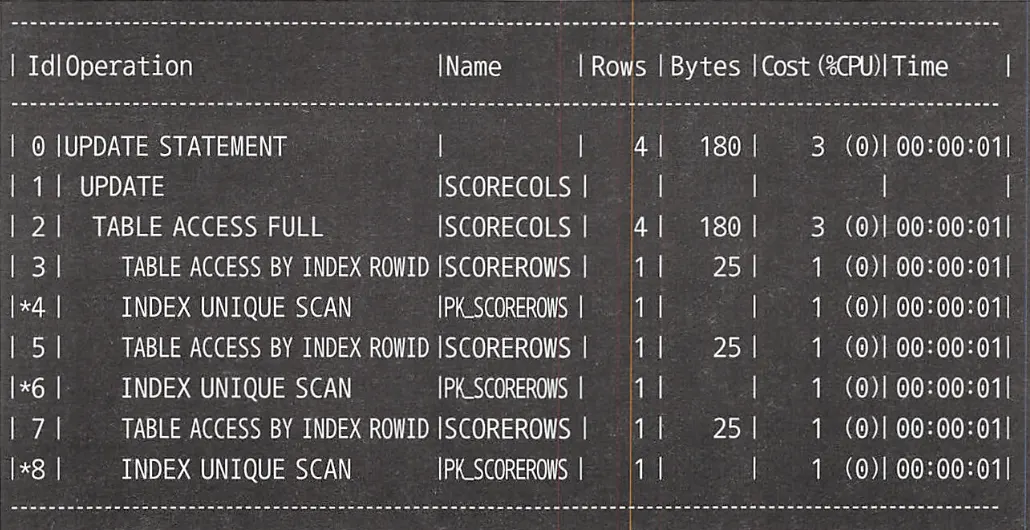
Oracle 실행 계획
실행 계획에서도 서브쿼리가 3번 실행되는 것을 확인할 수 있다.
다중 필드 할당
이럴 때 사용할 수 있는 방법으로 여러 개의 필드를 리스트화하고 한번에 갱신하는 다중 필드 할당(Multiple Fields Assignment) 방법이 있다.
UPDATE ScoreCols
SET(score_en, score_nl, score_mt)
= (SELECT MAX(CASE WHEN subject = '영어'
THEN score
ELSE NULL END) AS score_en,
MAX(CASE WHEN subject = '국어'
THEN score
ELSE NULL END) AS score_nl,
MAX(CASE WHEN subject = '수학'
THEN score
ELSE NULL END) AS score_mt
FROM ScoreRows SR
WHERE SR.studen_id = ScoreCols.student_id);
SQL
복사
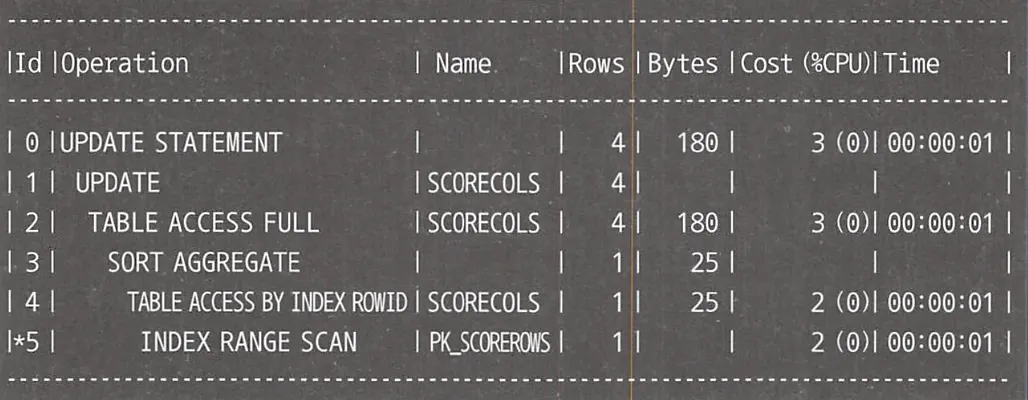
여기서 중요한 것은 국어, 영어, 수학이라는 세 개의 필드를 리스트 형식으로 지정하여 한번에 처리하는 다중 필드 할당과, 서브쿼리에서 MAX 함수를 각각 적용하여 집약한다는 것이다. 서브쿼리를 집약하지 않으면 여러 개의 레코드가 리턴되어, (100, NULL, NULL)과 같이 3개의 값이 리턴된다.
이와 같이 다중 필드 할당을 사용하면 서브 쿼리를 한번에 처리할 수 있어, 성능도 향상되고 코드도 간단해진다. 또한 갱신할 필드가 늘어나도 서브쿼리의 수가 늘어나지 않아 성능적으로 악화될 일이 없다.
대신 ScoreRows 테이블에 대한 검색이 INDEX UNIQUE SCAN이 아니라 INDEX RANGE SCAN이 사용되는 것을 볼 수 있다. 다만 학생당 과목 수가 그리 많지 않을 것이기 때문에, 서브쿼리를 줄이는 것이 훨씬 효율적인 트레이드 오프이다.
NOT NULL 제약이 걸려있는 경우
저장하는 테이블에 NOT NULL 제약이 걸려있는 경우를 살펴보자.
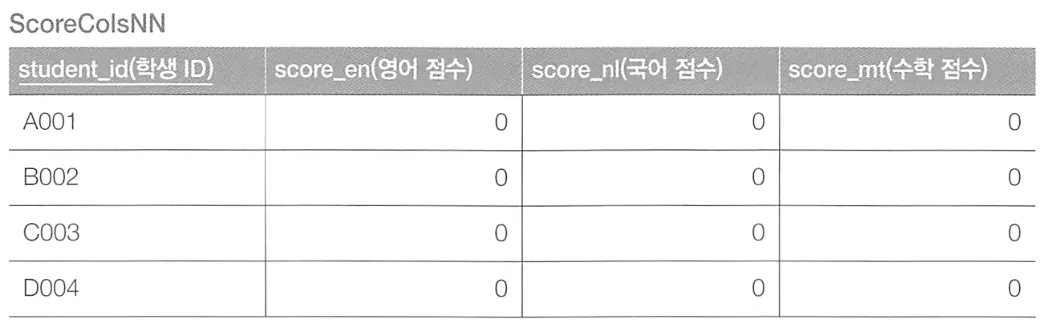
테이블의 초기 상태는 이와 같을 것이다.
상관 서브쿼리를 통해 NOT NULL 제약 조건을 해결하면 다음과 같다.
UPDATE ScoreColsNN
SET score_en = COALESCE((SELECT score FROM ScoreRows
WHERE student_id = ScoreColsNN.student_id
AND subject = '영어'), 0),
score_nl = COALESCE((SELECT score FROM ScoreRows
WHERE student_id = ScoreColsNN.student_id
AND subject = '국어'), 0),
score_mt = COALESCE((SELECT score FROM ScoreRows
WHERE student_id = ScoreColsNN.student_id
AND subject = '수학'), 0),
WHERE (SELECT * FROM ScoreRows
WHERE student_id = ScoreColsNN.student_id);
SQL
복사
다중 할당 필드로 NOT NULL 제약 조건을 해결하면 다음과 같다.
UPDATE ScoreColsNN
SET (score_en, score_nl, score_mt)
= (SELECT COALESCE(MAX(CASE WHEN subject = '영어'
THEN score
ELSE NULL END), 0) AS score_en,
COALESCE(MAX(CASE WHEN subject = '국어'
THEN score
ELSE NULL END), 0) AS score_nl,
COALESCE(MAX(CASE WHEN subject = '수학'
THEN score
ELSE NULL END), 0) AS score_mt,
FROM ScoreRows SR
WHERE SR.student_id = ScoreColsNN.student_id)
WHERE EXISTS (SELECT * FROM
WHERE student_id = ScoreColsNN.student_id);
SQL
복사
이와 같은 방법 외에도 MERGE 구문을 사용하여 NOT NULL 제약 조건을 해결할 수 있다.
MERGE INTO ScoreColsNN
USING (SELECT student_id,
COALESCE(MAX(CASE WHEN subject = '영어'
THEN score
ELSE NULL END), 0) AS score_en,
COALESCE(MAX(CASE WHEN subject = '국어'
THEN score
ELSE NULL END), 0) AS score_nl,
COALESCE(MAX(CASE WHEN subject = '수학'
THEN score
ELSE NULL END), 0) AS score_mt,
FROM ScoreRows
GROUP BY student_id) SR
ON (ScoreColsNN.student_id = SR.student_id)
WHEN MATCHED THEN
UPDATE SET ScoreColsNN.score_en = SR.score_en,
ScoreColsNN.score_nl = SR.score_nl,
ScoreColsNN.score_mt = SR.score_mt;
SQL
복사
이 방법은 UPDATE 때 두 개로 분산되어 있던 WHERE 조건을 ON 절을 통해 한번에 끝낼 수 있다는 것이다. 본래 MERGE 구문은 UPDATE와 INSERT를 한번에 시행하려고 고안된 기술이지만, 이처럼 둘 중 한 가지만 수행해도 구문 상에 문제가 없다.
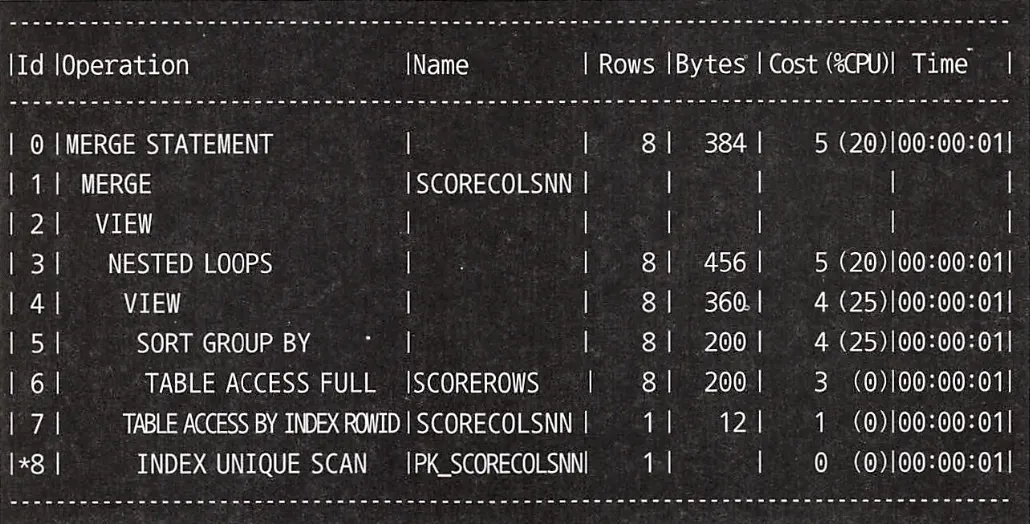
실행 계획을 보면 테이블 풀 스캔 1회와 정렬 1회가 발생한다. 이는 갱신할 필드가 많아져도 변하지 않아, 상관 서브쿼리와 달리 성능이 악화될 여지가 없다. 또한 ScorecolsNN 테이블과 ScoreRows 테이블의 결합도 1회만 발생하므로 EXISTES를 사용하는 것보다 나을 수 있다.
필드에서 레코드로 변경
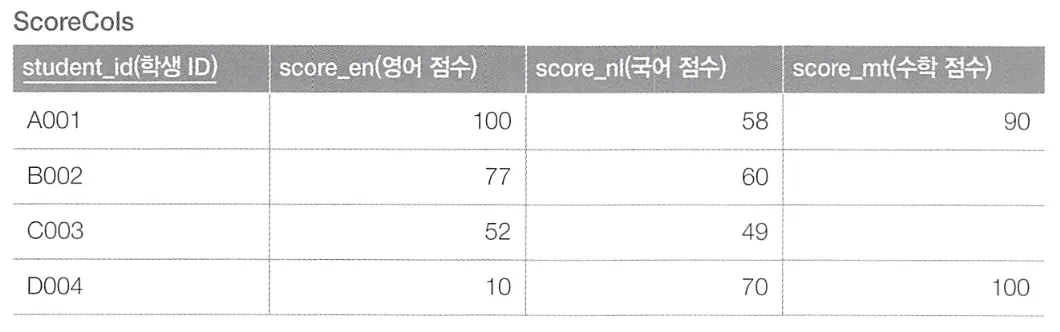
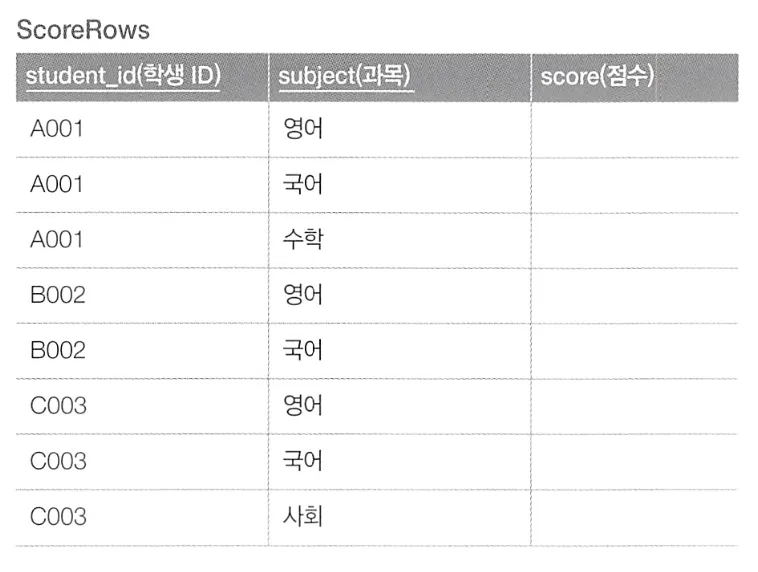
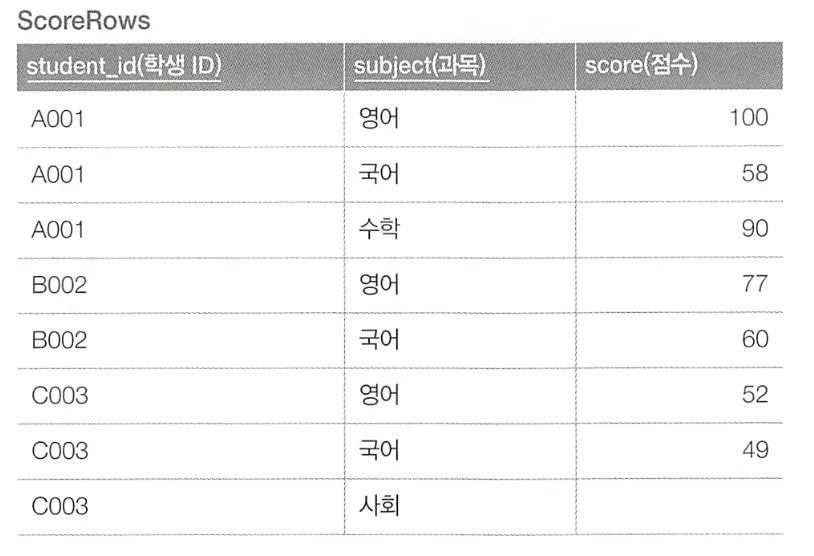
반대로 위와 같이 데이터를 필드에서 레코드로 변경하고자 한다.
UPDATE ScoreRows
SET score = (SELECT CASE ScoreRows.subject
WHEN '영어' THEN score_en
WHEN '국어' THEN score_nl
WHEN '수학' THEN score_mt
ELSE NULL END
FROM ScoreCols
WHERE student_id = ScoreRows.student_id;
SQL
복사

PostgreSQL 실행 계획
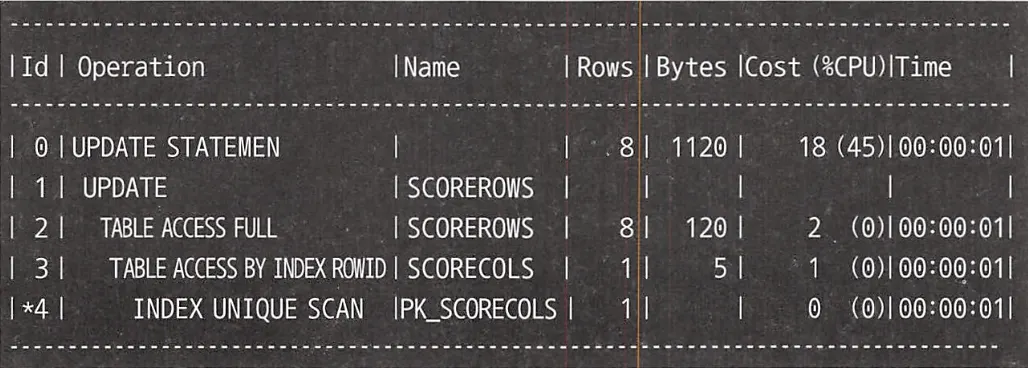
Oracle 실행 계획
테이블에 대한 접근이 한 번만 이루어지고, 기본 키 인덱스로 정렬이나 해시가 없어 성능적으로 충분히 좋은 실행 계획이다.
같은 테이블의 다른 레코드로 갱신
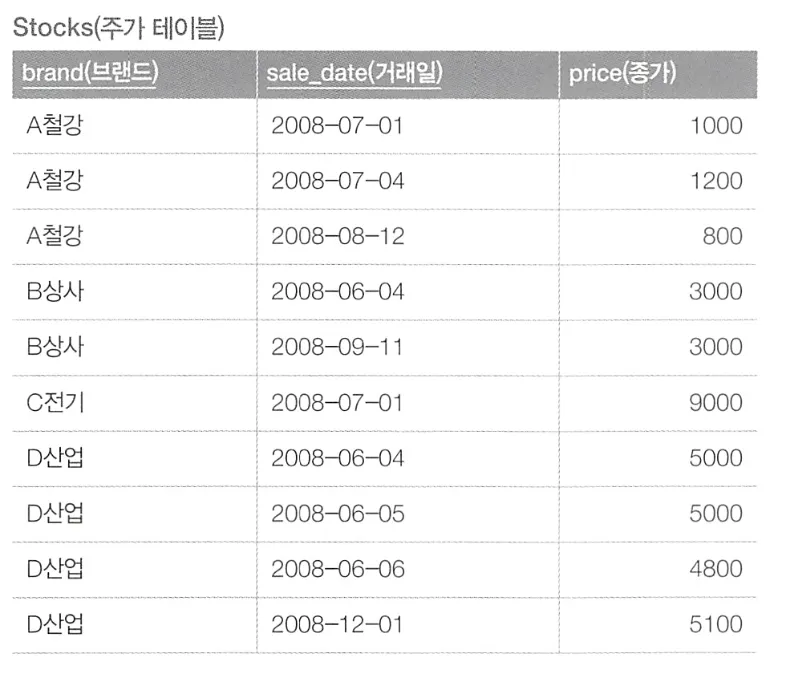
이와 같은 테이블에서, 같은 브랜드의 거래일에 따른 변화 trend(트렌드) 필드를 추가하여 아래와 같이 작성하고자 한다.
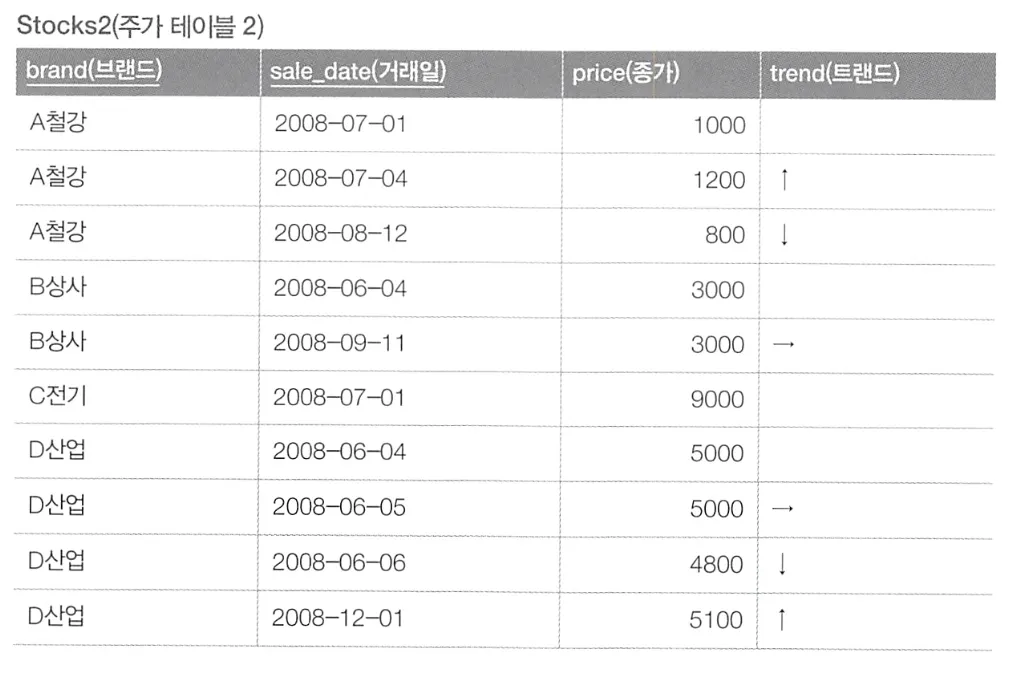
서브 상관 쿼리 사용하기
INSERT INTO Stocks2
SELECT brand, sale_date, price,
CASE SIGN(price -
(SELECT price
FROM Stocks S1
WHERE brand = Stocks.brank
AND sale_date =
(SELECT MAX(sale_date)
FROM Stocks S2
WHERE brand = Stocks.brand
AND sale_date < Stocks.sale_date)))
WHEN -1 THEN '↓'
WHEN 0 THEN '→'
WHEN 1 THEN '↑'
ELSE NULL END
FROM Stocks;
SQL
복사
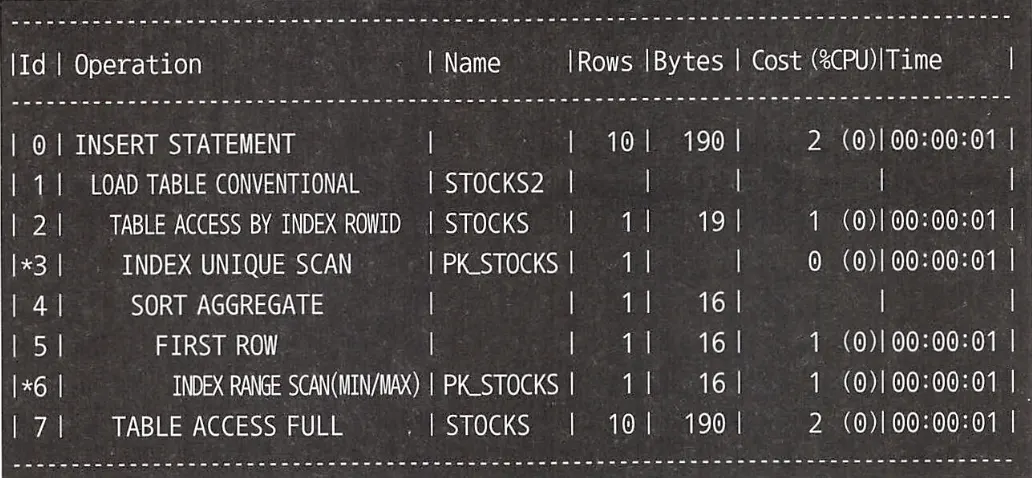
상관 서브쿼리로 인해 Stocks 테이블에 여러 번 접근이 발생하는 것을 알 수 있다.
윈도우 함수 사용하기
INSERT INTO Stocks2
SELECT brand, sale_date, price
CASE SIGN(price -
MAX(price) OVER (PARTITION BY brand
ORDER BY sale_date
ROWS BETWEEN 1 PRECEDING
AND 1 PRECEDING))
WHEN -1 THEN '↓'
WHEN 0 THEN '→'
WHEN 1 THEN '↑'
ELSE NULL END
FROM Stocks S2;
SQL
복사
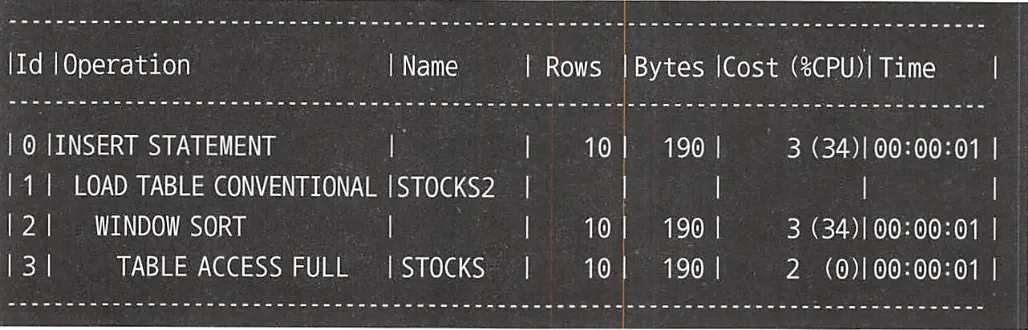
테이블에 대한 접근도 한 번으로 감소했고, 실행 계획 자체도 매우 간단해진 것을 볼 수 있다.
INSERT와 UPDATE 중 선택하기
INSERT SELECT는 일반적으로 UPDATE에 비해 성능적으로 더 좋고, MySQL처럼 갱신 SQL에서의 자기 참조를 허락하지 않는 데이터베이스에서도 사용할 수 있다는 장점이 있다.
반면, 같은 크기와 같은 구조를 가진 데이터를 두 개 만들어야 해서 저장소 용량을 2배 이상 소비한다는 단점이 있다. 기술의 발달로 저장소 가격이 점점 낮아지는 것을 고려하면 그리 큰 단점이라 볼 수 없다.
또 다른 방법으로 Stocks2 테이블을 뷰로 만드는 방법이 있는데, 저장소 용량을 절약할 수 있다는 점과 정보를 항상 최신으로 유지한다는 장점이 있다. 반면 Stocks2 뷰에 접근할 때마다 복잡한 연산이 수행되어 쿼리의 성능이 낮아진다. 성능과 동기성의 트레이드 오프라고 볼 수 있다.
갱신이 초래하는 트레이드 오프
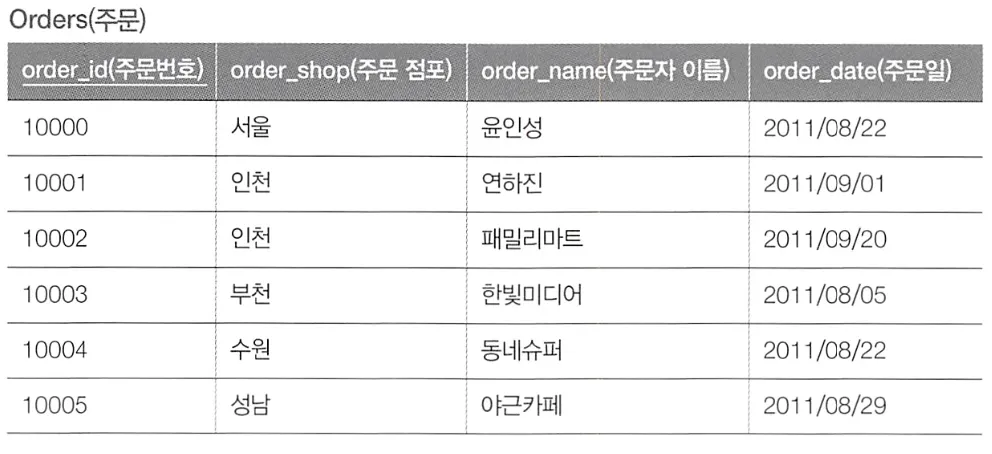
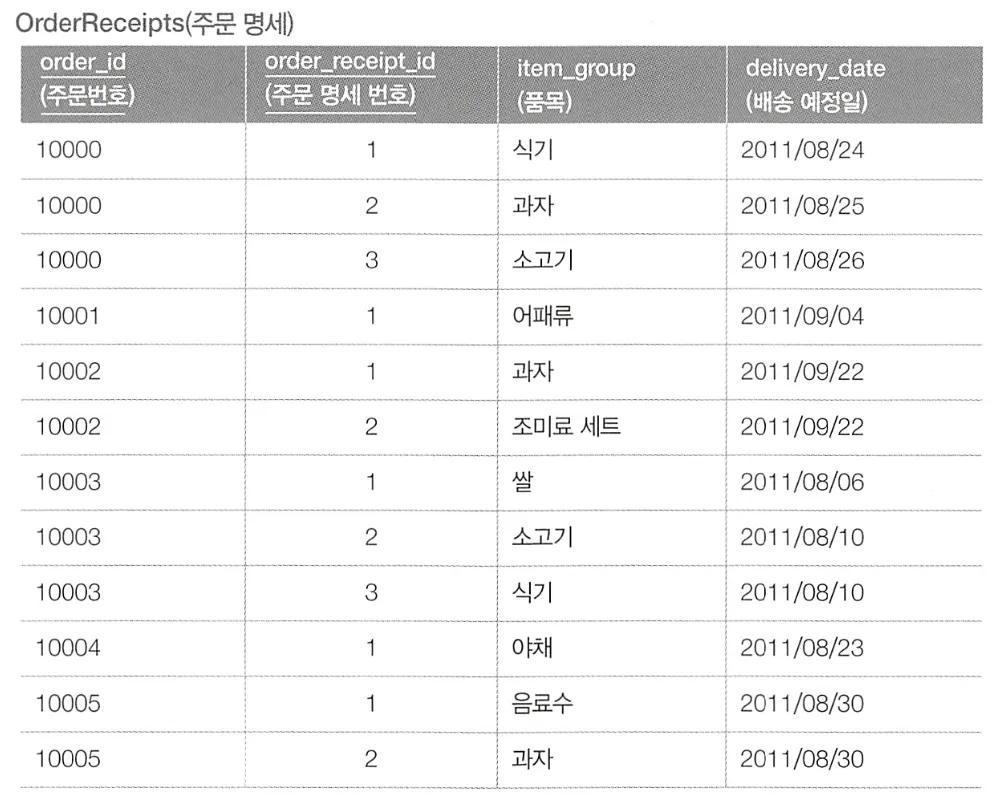
이와 같은 두 개의 테이블에서 주문일(order_date)과 상품의 배송 예정일(delivery_date)의 차이를 구해 3일 이상이라면 주문자에게 배송 주문이 늦어지고 있다고 연락하고자 한다.
SQL을 사용하는 방법
SELECT O.order_id, O.order_name,
ORC.deliver_date - O.order_date AS diff_days
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id
WHERE ORC.delivery_date - O.order_date >= 3;
SQL
복사

각 필드가 서로 다른 테이블에 존재하기 때문에, 이와 같이 결합을 사용해 날짜 차이를 구할 수 있다.
만약 주문 번호별 최대 지연일을 알고 싶다면 아래처럼 주문번호를 집약하면 된다.
SELECT O.order_id, MAX(O.order_name),
MAX(ORC.delivery_date - O.order_date) AS max_diff_days
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id
WHERE ORC.delivery_date - O.order_date >= 3
GROUP BY O.order_id;
SQL
복사

여기서 order_name의 MAX 함수는 날짜 차이의 최대값을 구하기 위한 집약 함수이고, delivery_date - order_date의 MAX 함수는 최대값이 아닌 값을 선택하기 위한 함수로 MIN을 사용해도 무방하다.
모델 갱신을 사용하는 방법
위의 방법은 결합 및 집약을 통한 SQL 구문이기 때문에 실행 계획의 변동 리스크가 크다. 사실 이 문제는 SQL을 사용하지 않고도 해결할 가능성이 있다. 테이블 구성(ER 모델)을 변경할 수 있다면, 배송이 늦어질 가능성이 있는 주문의 레코드에 플래그 필드를 Orders 테이블에 추가하여 간단하게 해결할 수 있다.
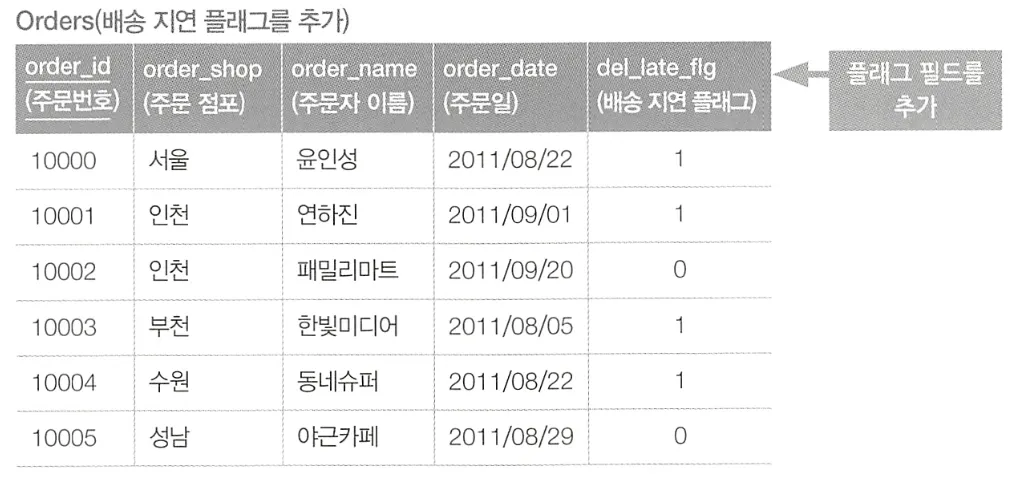
이처럼 더 나은 개선 방법이 있을 수 있으니, 반사적으로 SQL 구문으로만 해결하려 하지말자.
모델 갱신의 주의점
모델 갱신을 사용하면 복잡한 쿼리를 사용하지 않아도 되지만, 여기에도 세 가지 트레이드 오프가 있다.
1.
높아지는 갱신 비용
모델 갱신을 사용하면 추가적으로 Orders 테이블에 배송 지연 플래그 필드에 값을 넣는 갱신 처리가 필요하다. 테이블에 등록할 때 값이 정해져있다면 상관없지만, 등록 할 때 배송 예정일이 정해져 있지 않다면 갱신 비용이 많이 올라가게 된다.
2.
갱신까지의 시간 랙(Time Rag) 발생
모델 갱신은 배송 예정일이 주문 등록 후에 갱신되는 경우, Orders 테이블과 OrderReceipts 테이블 간의 동기화로 인해 실시간으로 값을 가져올 수 없다는 문제가 발생할 수 있다.
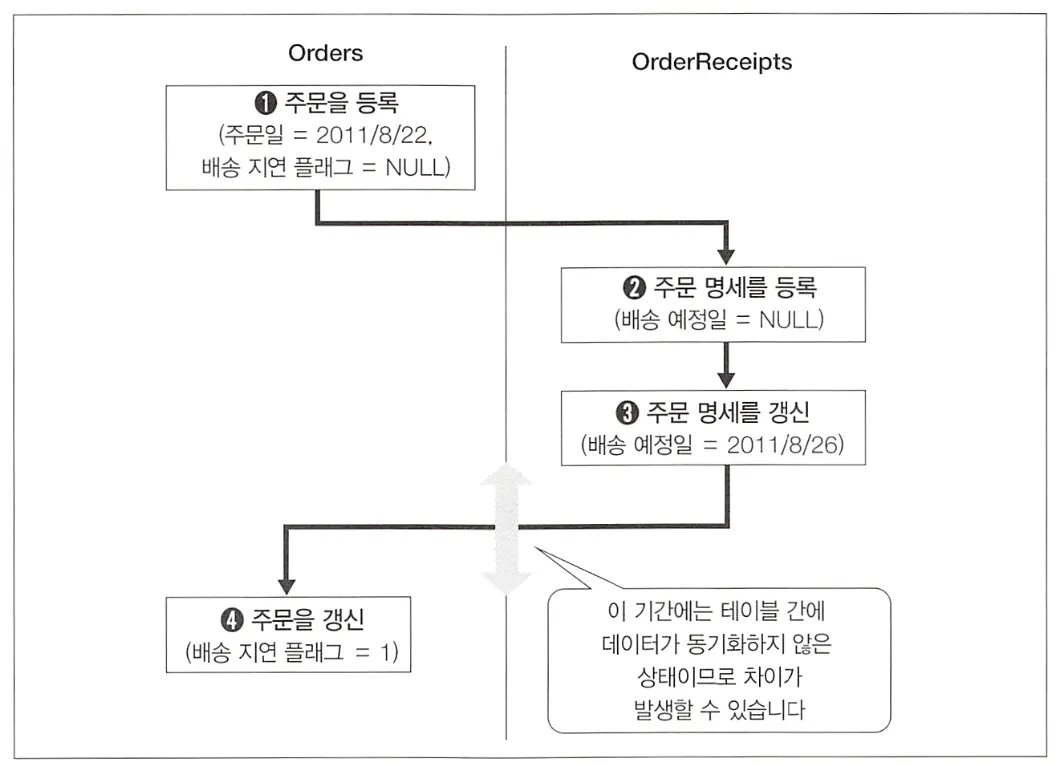
특히 이런 작업은 일반적으로 야간에 배치 갱신으로 수행되는데, 그로 인해 시간 랙 기간이 더 길어질 수 있다. 실시간성이 중요한 업무일수록 갱신 간격이 짧아져야하고, 이로 인해 성능이 저하되는 트레이드오프가 발생한다.
3.
모델 갱신비용 발생
RDB 데이터 모델 갱신은 코드 기반의 수정에 비해 대대적인 수정이 요구된다. 갱신 대상 테이블을 사용하는 다른 처리에 문제가 발생할 가능성도 있기 때문에, 프로젝트의 단계에 따라 시스템의 품질과 개발 일정에 큰 리스크가 될 수 있다.
이처럼 모델 갱신에 따른 트레이드오프 요인들을 모두 생각해두지 않으면, 이후 큰 문제를 일으키는 핫 스팟(Hot spot)이 될 수 있다.
시야 협착: 관련 문제
시야 협착에 빠지기 쉬운 한 가지 예시를 더 살펴보자.
결과 필드에 주문 번호, 주문자 이름, 주문일, 상품 수를 포함하는 결과를 구하고자 한다.
SQL을 사용하는 방법
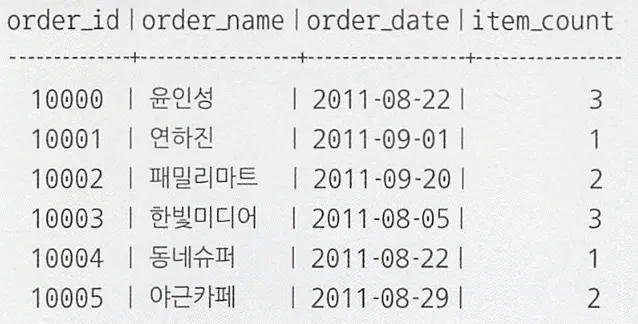
SELECT O.order_id,
MAX(O.order_name) AS order_name,
MAX(O.order_date) AS order_date,
COUNT(*) AS item_count
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id
GROUP BY O.order_id;
SQL
복사

윈도우 함수를 사용하는 방법
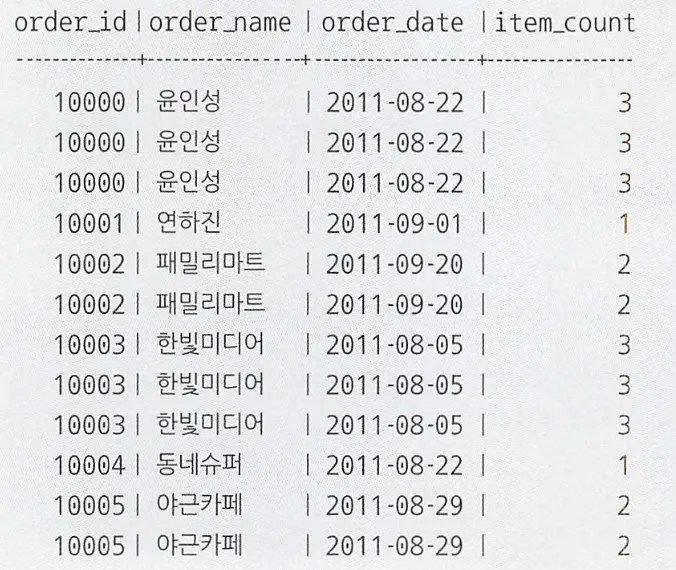
SELECT O.order_id, O.order_name, O.order_date,
COUNT(*) OVER (PARTITION BY O.order_id) AS item_count
FROM Orders O
INNER JOIN OrderReceipts ORC
ON O.order_id = ORC.order_id;
SQL
복사

모델 갱신 사용하는 방법
Orders 테이블에 상품 수라는 정보를 추가해 모델을 갱신하는 방법도 있다.
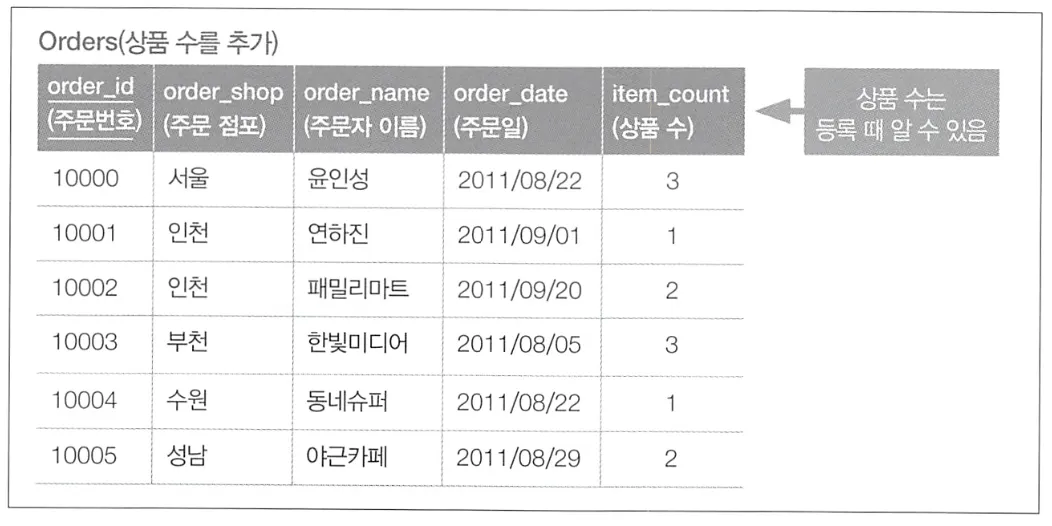
이 방법을 적용하면, 한 번 등록한 주문을 변경할 때 상품 수도 함께 변경해야할 가능성이 있다. 따라서 동기/비동기 문제도 생각해야 한다.
시야 협착 경계하기
이러한 시야 협착은 SQL 뿐만 아니라 프로그래밍 전반에 걸쳐 발생한다. 어려운 문제를 그냥 어려운 상태인 채로 풀려하면 복잡한 코드를 만들게 돼 시스템 전체 관점에서 비효율을 야기할 수 있다.
데이터 모델과 시스템
안 좋은 데이터 구조와 좋은 코드의 조합보다 좋은 데이터 구조와 안 좋은 코드의 조합이 더 좋다는 말이 있다. 이는 모든 프로그래밍 언어와 데이터에 일반화 할 수 있다.
데이터 모델이 코드를 결정하고, 코드는 데이터 모델을 결정하지 않는다. 잘못된 데이터 모델에서 출발하면 잘못된 코드를 바로 잡을 수가 없다. 엔지니어는 전략적 실패를 만회하는 것이 아니라, 올바른 전략을 고려해야한다. 진짜 좋은 프로젝트는 좋은 분위기로 시작해 좋은 분위기로 끝나는 것이다.
그만큼 데이터 구조는 중요하기 때문에, 초기에 테이블에 대한 기능적인 설계를 할 때 신중하고 잘 해야한다.