

리팩토링을 하는 이유
현재 42PAW의 게시글 조회의 로직은 다음과 같다.
1.
Pagination의 size와 page 기준으로 DB에서 게시글(Board) + 게시글 작성한 유저(member) fetch join으로 조회
2.
유저의 로그인 여부에 따라 차단 유저 리스트 및 카테고리 리스트 조회
a.
현재 유저가 로그인 중이라면 차단한 유저 목록(block list)과 유저가 설정해둔 카테고리를 각각 조회
b.
로그인을 하지 않았다면 차단 목록은 빈 리스트로, 카테고리 리스트는 전체 카테고리를 포함한 리스트로 생성
3.
조회해온 게시글 리스트에서 차단 유저 리스트에 있는 유저가 올린 게시글 필터링 및 카테고리에 맞지 않는 게시글 필터링
4.
남은 게시글 리스트를 순회하며, 게시글 id 기준으로 연관 관계를 가지는 게시글 이미지와 좋아요(reaction), 댓글(comment), 게시글을 스크랩(scrap)한 유저들을 조회
5.
각 조회된 값들로 DTO 작성(게시글, 게시글 이미지들, 좋아요 개수, 댓글 개수, 가장 최근 댓글의 작성자와 댓글 내용, 로그인 중이라면 내가 좋아요 했는지 여부와 스크랩 했는지 여부)
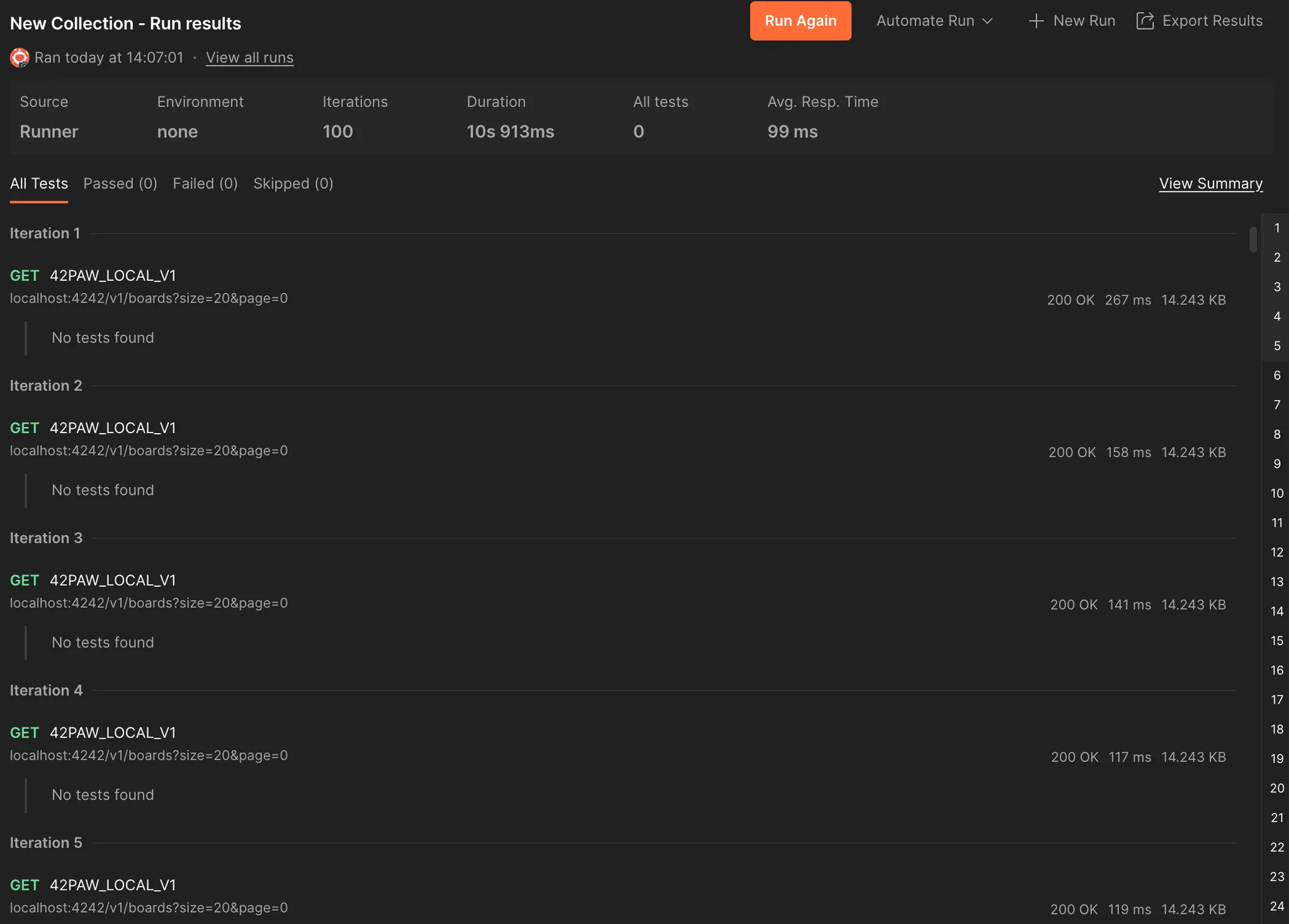
결국 구조상 1 + 3 + 4 * N 쿼리가 발생하고, 로컬에서 1만개의 더미 게시글을 생성 후 조회 로직을 수행하면 평균 99ms가 걸린다. 이는 DB에 게시글과 좋아요, 댓글, 스크랩이 늘어날수록 점점 시간이 증가할 것으로 예상된다.
•
Query DSL
•
비즈니스 로직
1차 리팩토링 - Query DSL 및 Projection으로 하나의 쿼리로 전부 조회하기
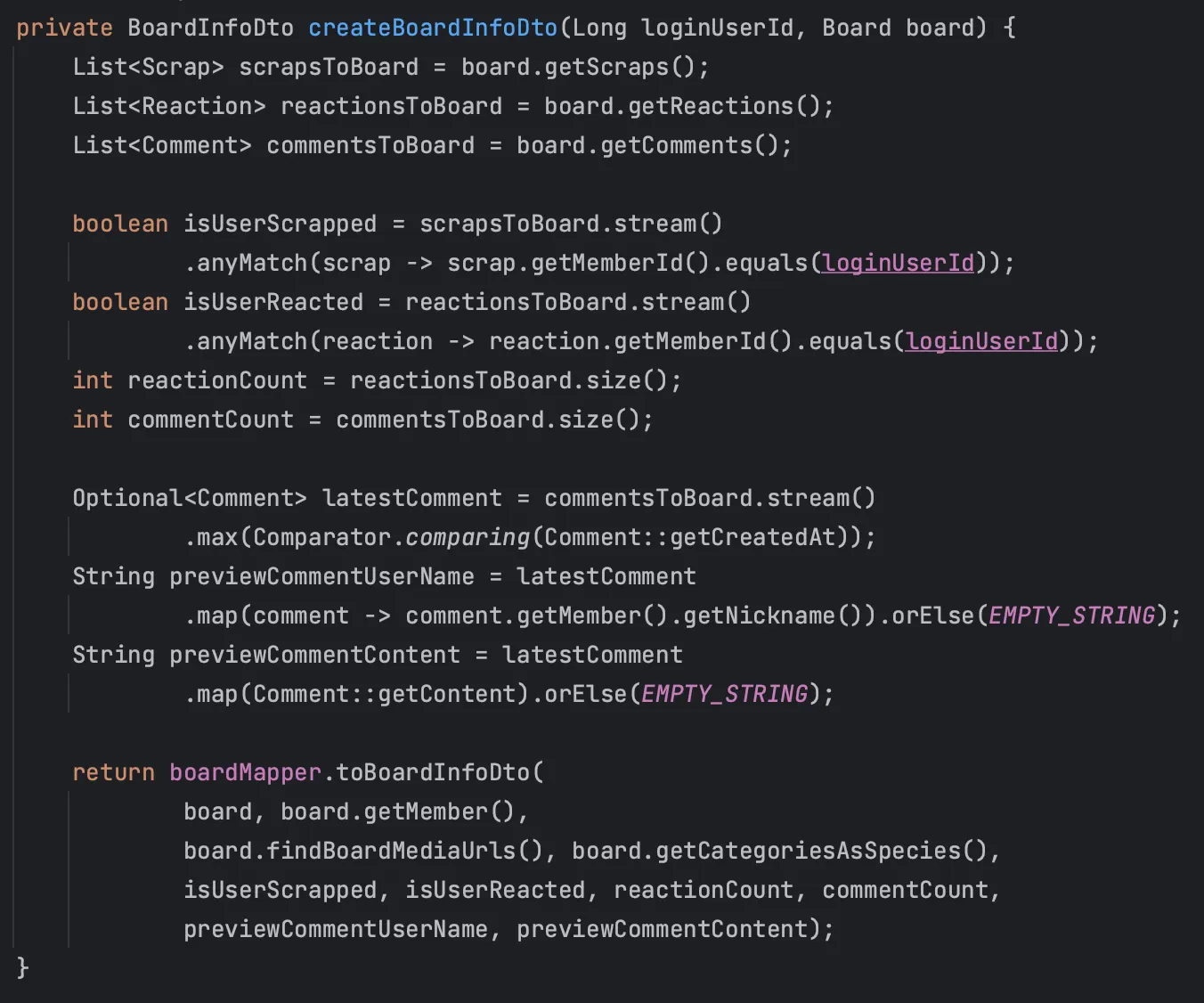
위에서 언급한 문제점에서 시작하여 1 + 3 + 4 * N만큼 쿼리가 발생하는 것을 쿼리 한 번으로 전부 조회해오도록 수정해서, 성능 개선을 시도해보았다.
지난 리팩토링의 결과를 보았을 때 fetch join으로 여러 연관관계를 한번에 들고 오면 쿼리는 한 번만 발생하지만, JPA 내부에서 각 엔티티들을 조회하고 정렬하는 과정으로 인해 오래 걸린 것으로 추측된다. 그렇다면 연관 관계를 통째로 들고 오는게 아니라, DAO와 Projection으로 필요한 필드만 뽑아서 가져오면 더 빠를까? 라는 생각이 들었다.
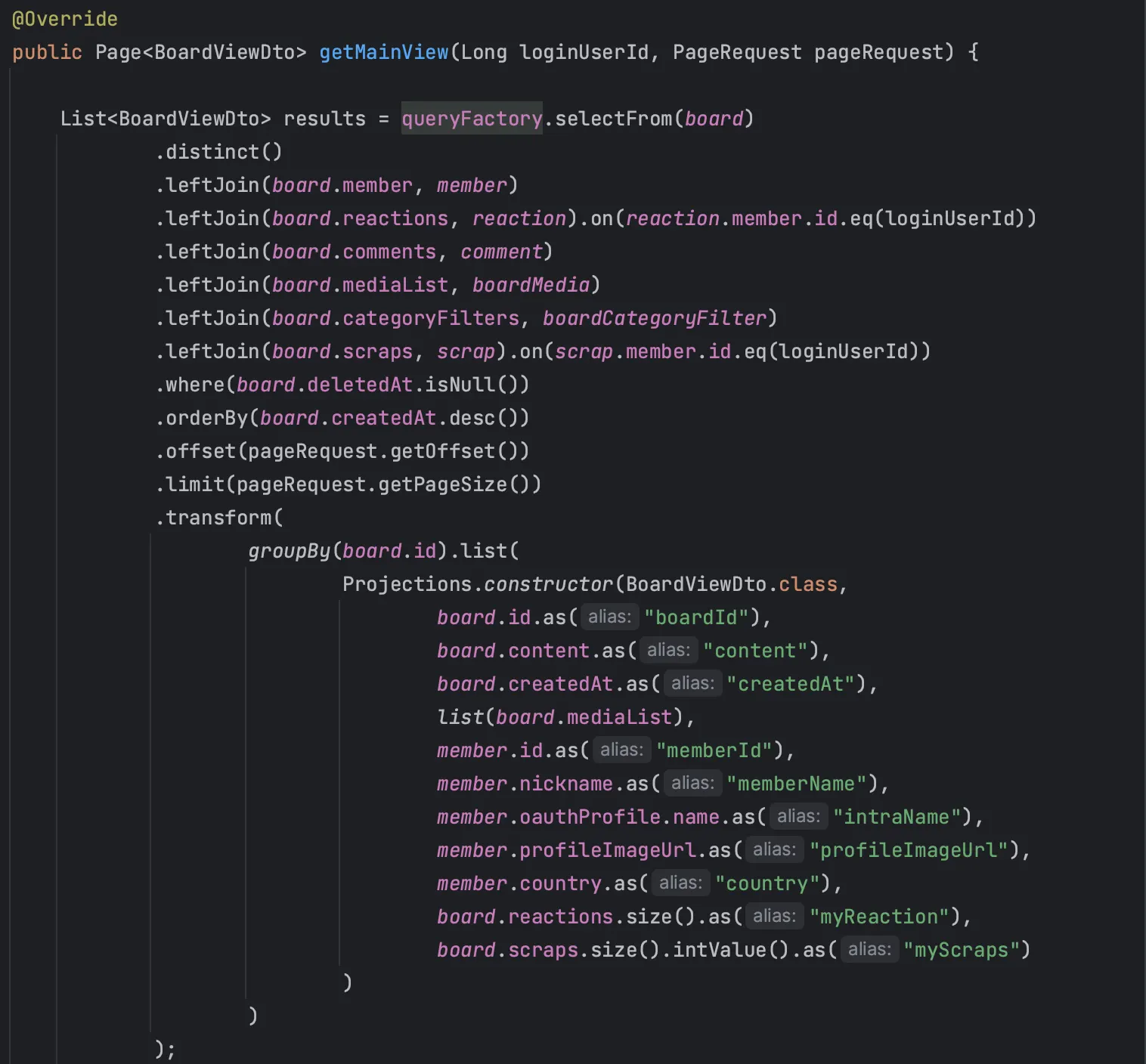

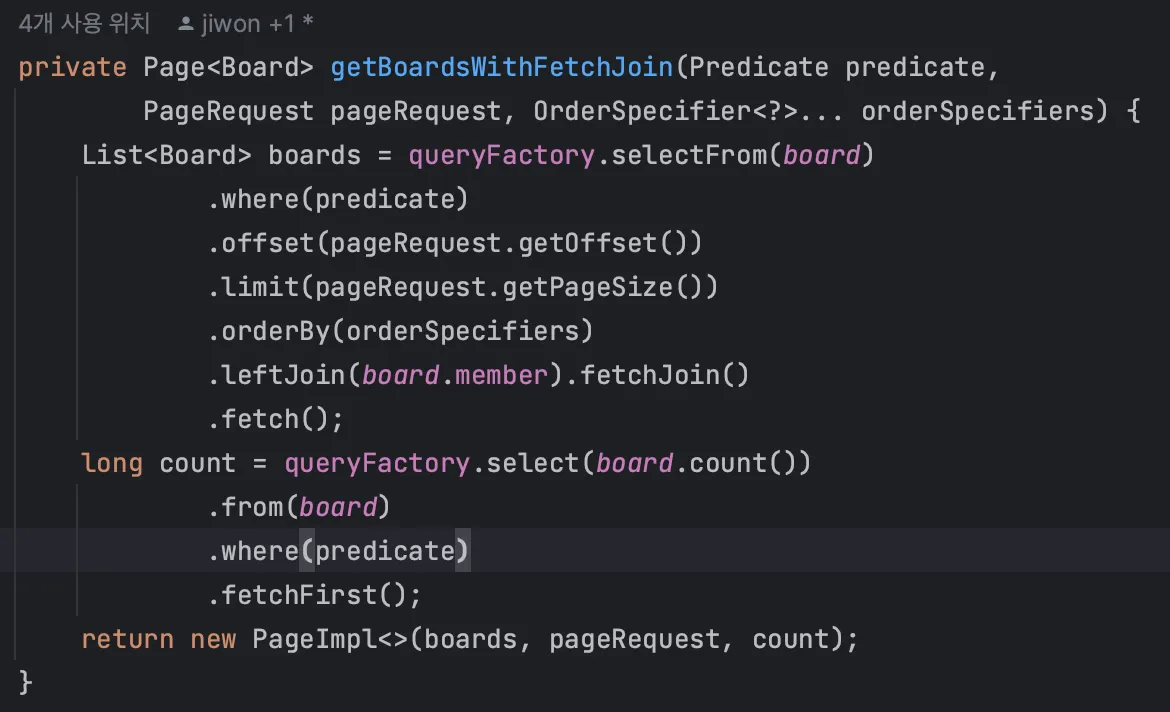
이와 같이 Query DSL로 연관 관계에서 필요 필드들만 뽑아서 한번에 조회해오는 쿼리를 만들었다.

목표했던 대로 쿼리는 이와 같이 1개만 발생하고, select 문을 살펴보면 딱 필요한 필드들만 선택하여 가져오는 것을 알 수 있다.
1차 리팩토링 결과 및 결론
테스트 결과는 말이 안되는 수준으로 성능이 저하되었다. 50개 게시글에서 조회하는 경우 2.67초, 1만개 게시글에서 조회하는 경우에는 5분을 기다려도 응답을 받지 못했다. 리팩토링 이후 항상 100개씩 테스트 돌려보고 평균 시간을 측정하는데, 이는 시간이 굉장히 오래 걸리기도 하고 의미가 없을 것 같아 하지 않았다.
left join만으로 필요한 값들을 전부 조회해오는 것은, 가져오는 방식이나 걸리는 시간, 가져온 데이터, 발생한 쿼리 모두 사실상 fetch join이랑 다를 바가 없었다. 이는 특정 필드들만 선택해서 가져온다고 하더라도 딱히 다르지 않다. 쿼리는 한 번만 발생하지만 그에 따라 여러 데이터를 join하는 것은 동일하기 때문이다. 추가적으로 조회 후 DAO에 맞춰 데이터를 정리하는 과정까지 추가되니 오히려 느려진 것으로 추측된다.
이를 통해 결국 쿼리를 한 번만 날려 쿼리 조회 수를 낮추는 방식은 별도의 저장 구조를 가지는 DB를 따로 두고 DAO 패턴을 적용하지 않는다면, 현재 구조에서 더 이상 개선이 힘들 것으로 생각된다.
2차 리팩토링 - DAO 최적화와 IN절을 통해 한번에 조회하기
이걸 어떻게 개선할까를 고민하던 중, 1 + 2 + 4 * N 쿼리를 각 조회를 IN절로 묶어 한번에 조회하여 1 + 2 + 4 쿼리로 줄인다면 성능상 괜찮지 않을까라는 생각을 하게 되었다.
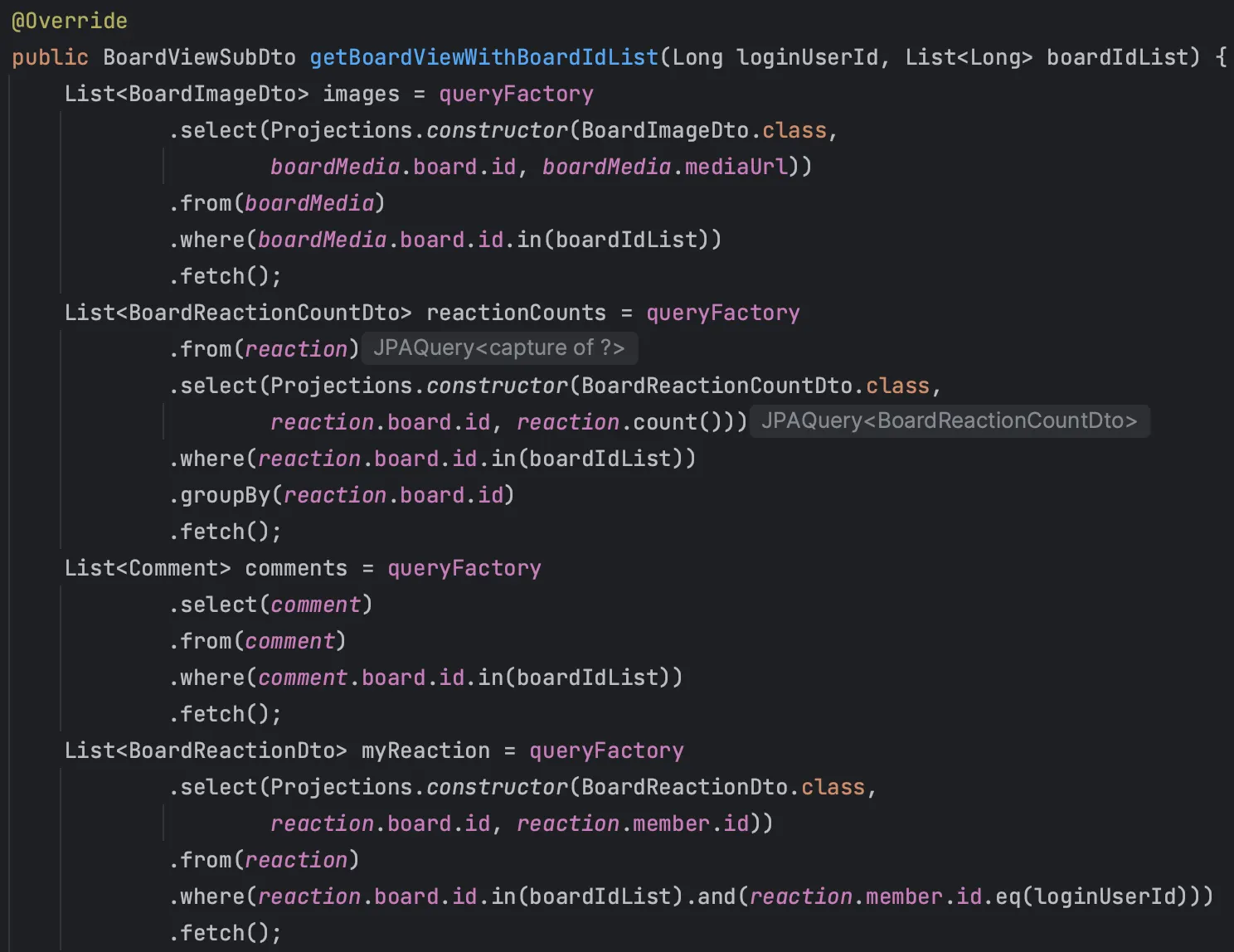
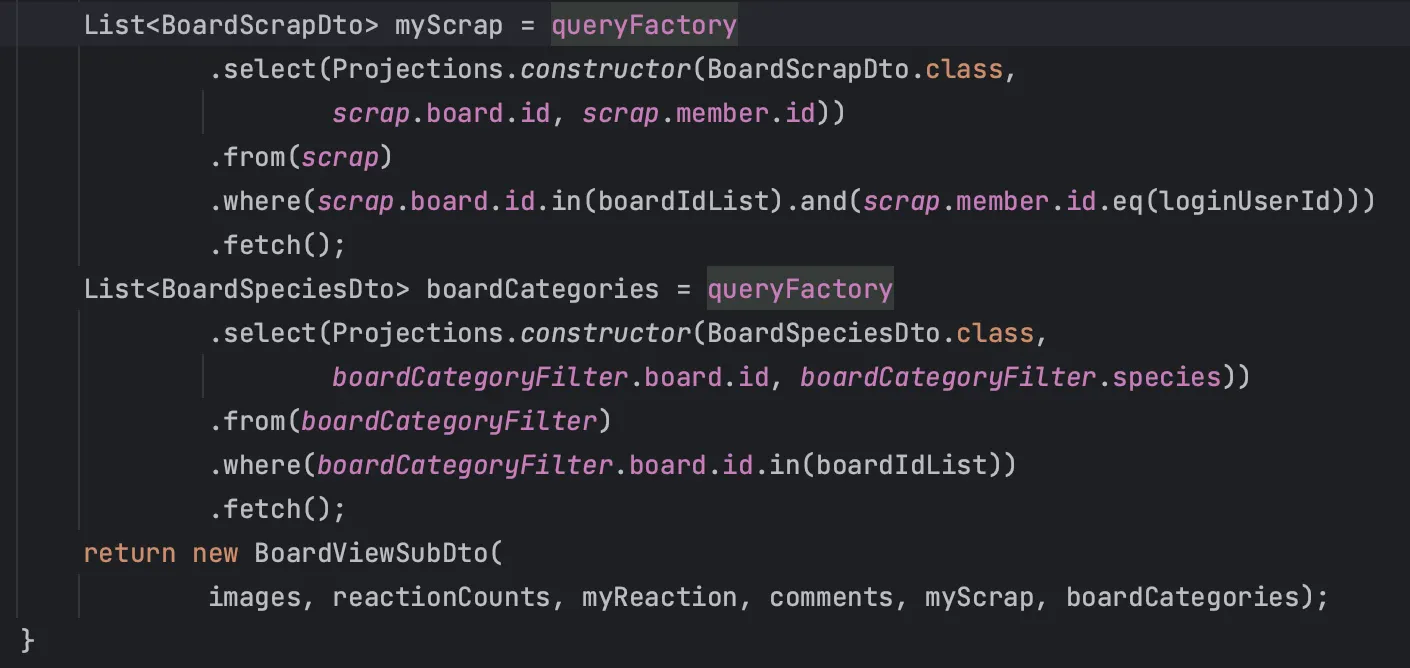
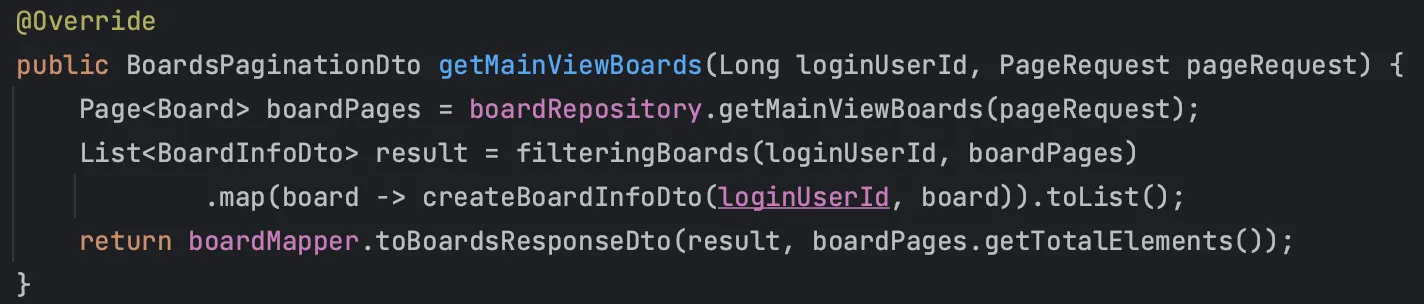
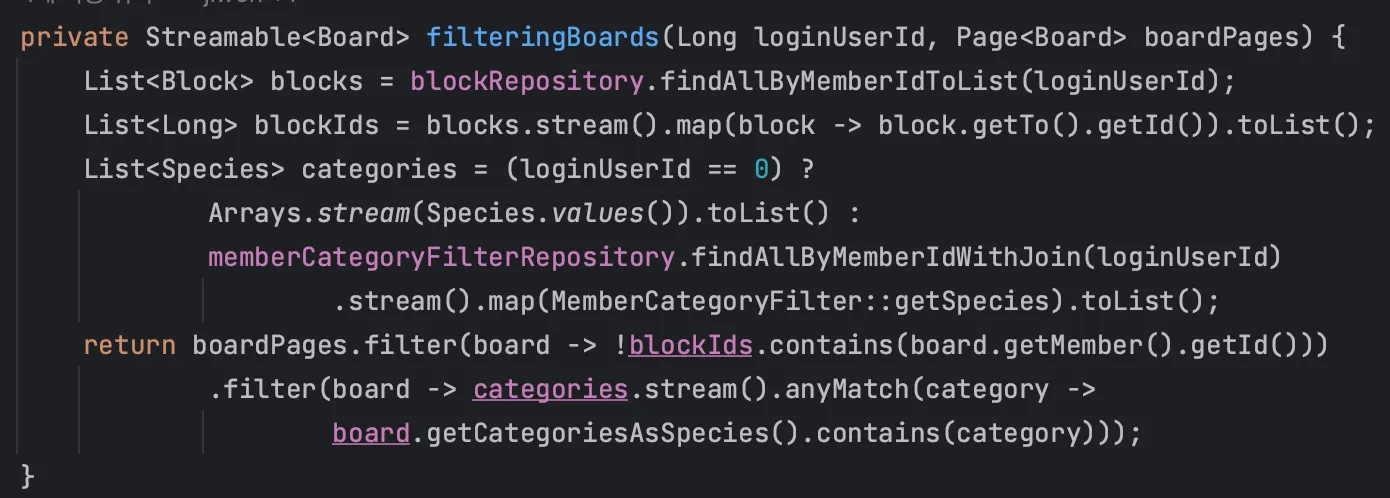
이와 같이 Pagination에 맞춰 게시글들의 id만 리스트로 받고 Query DSL의 in절에 넣어, 게시글, 게시글 이미지들, 좋아요 개수, 댓글 개수, 가장 최근 댓글의 작성자와 댓글 내용, 로그인 중이라면 내가 좋아요 했는지 여부와 스크랩 했는지 여부를 각각 일괄적으로 조회하도록 작성했다.
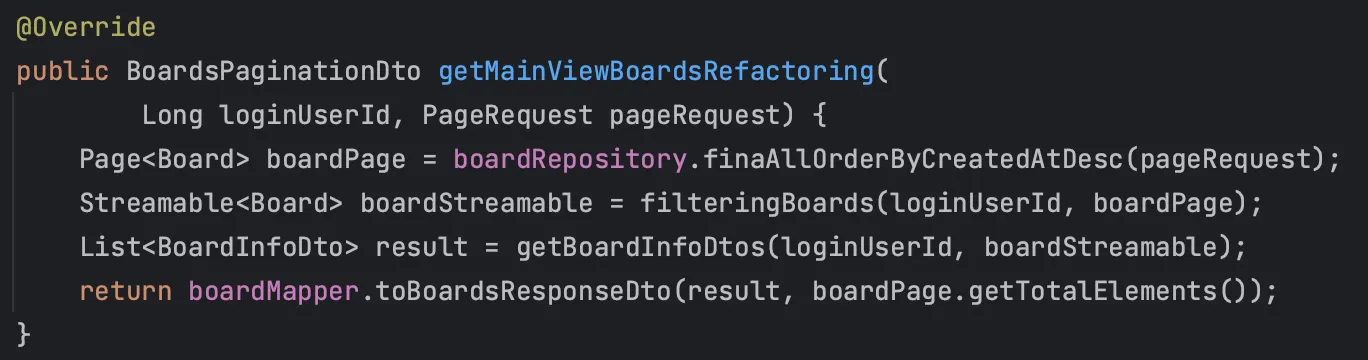

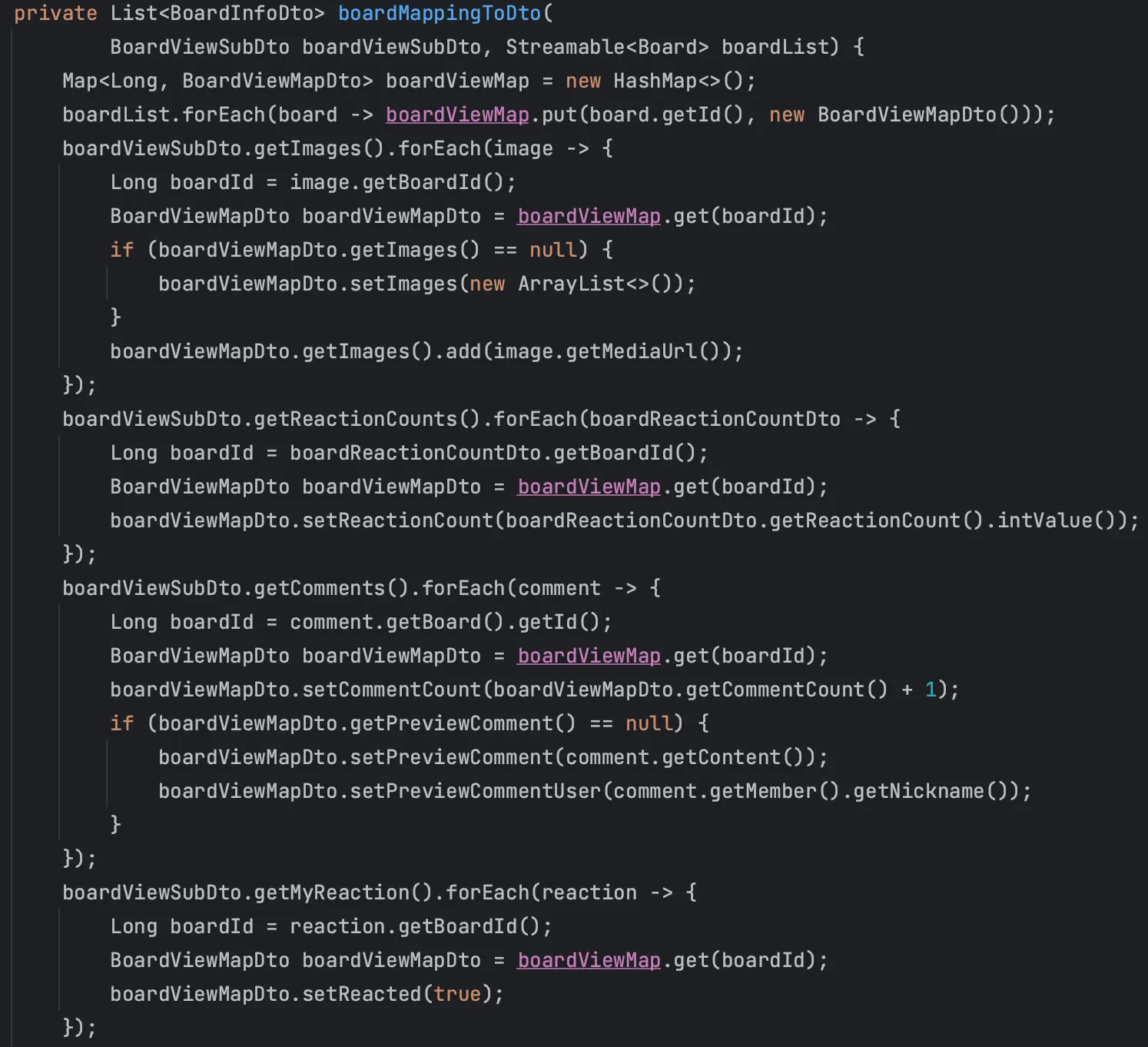
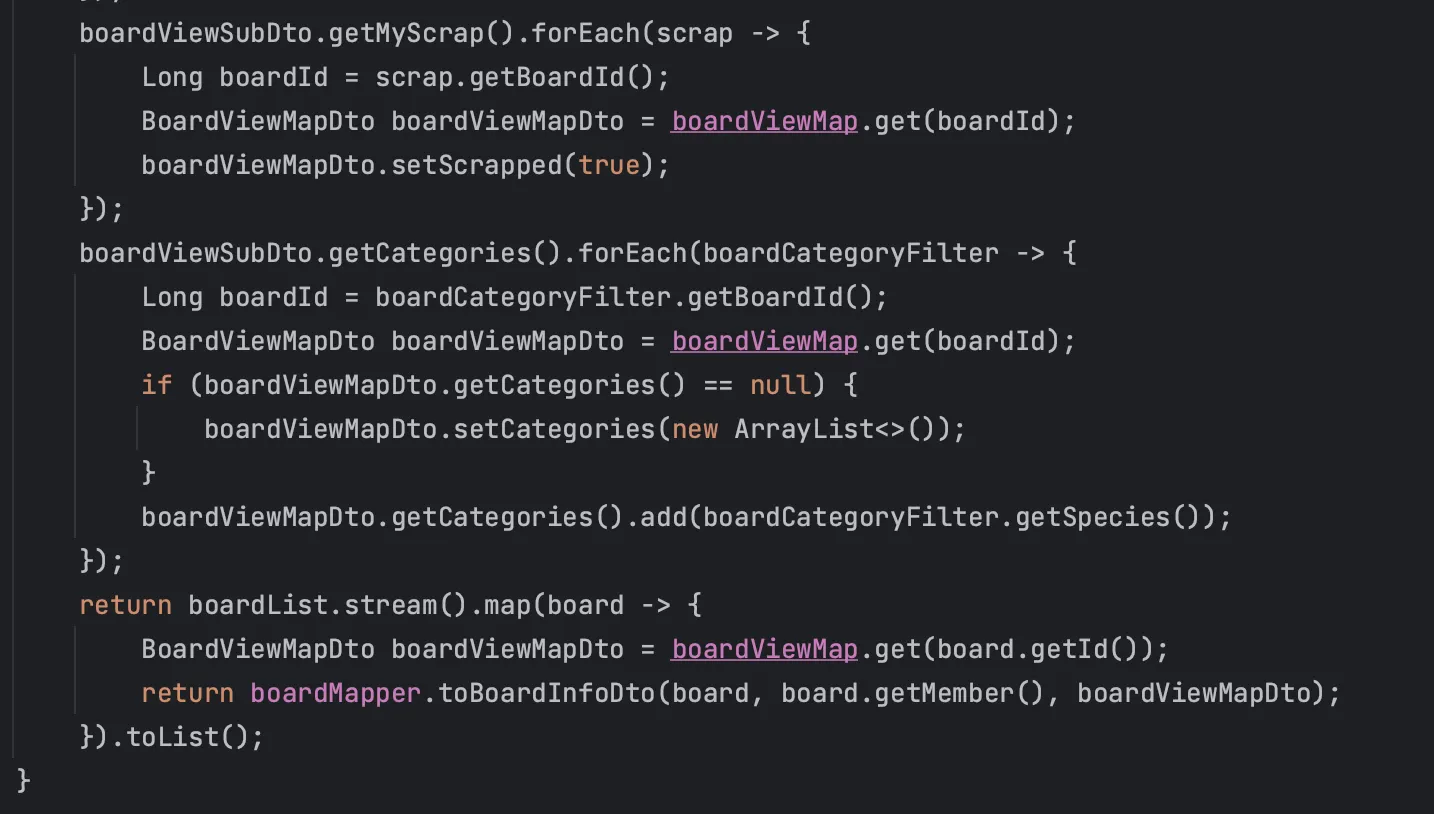
그 후 이처럼 비즈니스 로직으로 통해 데이터를 가공하여 DTO에 매핑하여 전달하도록 작성했다.
위의 1차 테스트에서는 결국 쿼리의 개수를 1개로 줄이는 것이 목적이였고, 그 때문에 리팩토링 이전 쿼리의 개수가 몇 개 발생하는지 신경쓰지 않았었다. 문제는 위의 리팩토링 전 로직 중 조회된 게시글들을 스트림으로 순회하며 필요한 정보들을 가져오기 위해서 repository에서 별도의 쿼리를 날리는 것이 아닌 getScraps()나 getReactions()와 같이 접근자(getter)로 값을 불러왔다는 것이다. 실제 발생되는 쿼리들을 확인을 해보니 아래처럼 JPA에서 IN 절을 통해 자체적으로 최적화를 진행하여 쿼리를 발생시켰다. 각 엔티티들도 지연 로딩 설정이 되어있고, 종단 연산을 만나기까지 지연 처리하는 스트림의 특성이 합쳐져 생긴 현상으로 추측된다. 거기에 batch size를 100개로 설정을 미리 적용해두었기 때문에 이를 IN절로 묶어서 가져온 것이다.
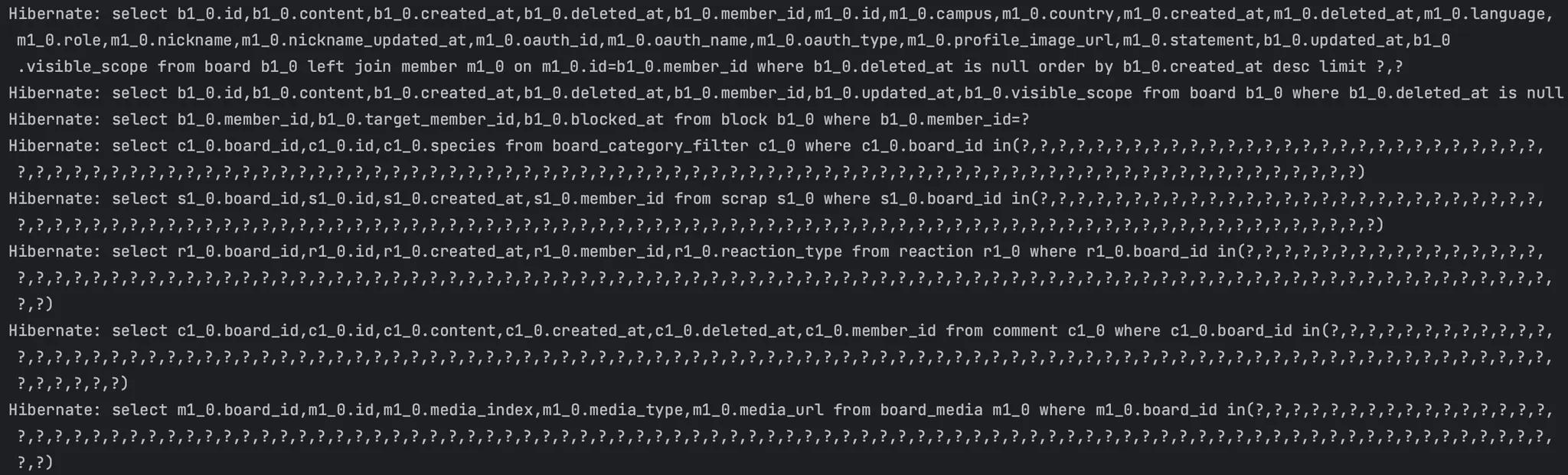
이처럼 in절로 최적화 처리되어 총 8개의 쿼리가 발생하게 된다.
2차 리팩토링 테스트 결과
그래도 이미 작성한 코드가 있으니 테스트나 해보자는 생각으로, 동일하게 1만개의 더미 게시글이 있는 로컬 환경에서 테스트를 진행해 보았다. 리팩토링 전과 후를 비교했을 때, 예상치 못한 개선 결과가 있었다.
리팩토링 전
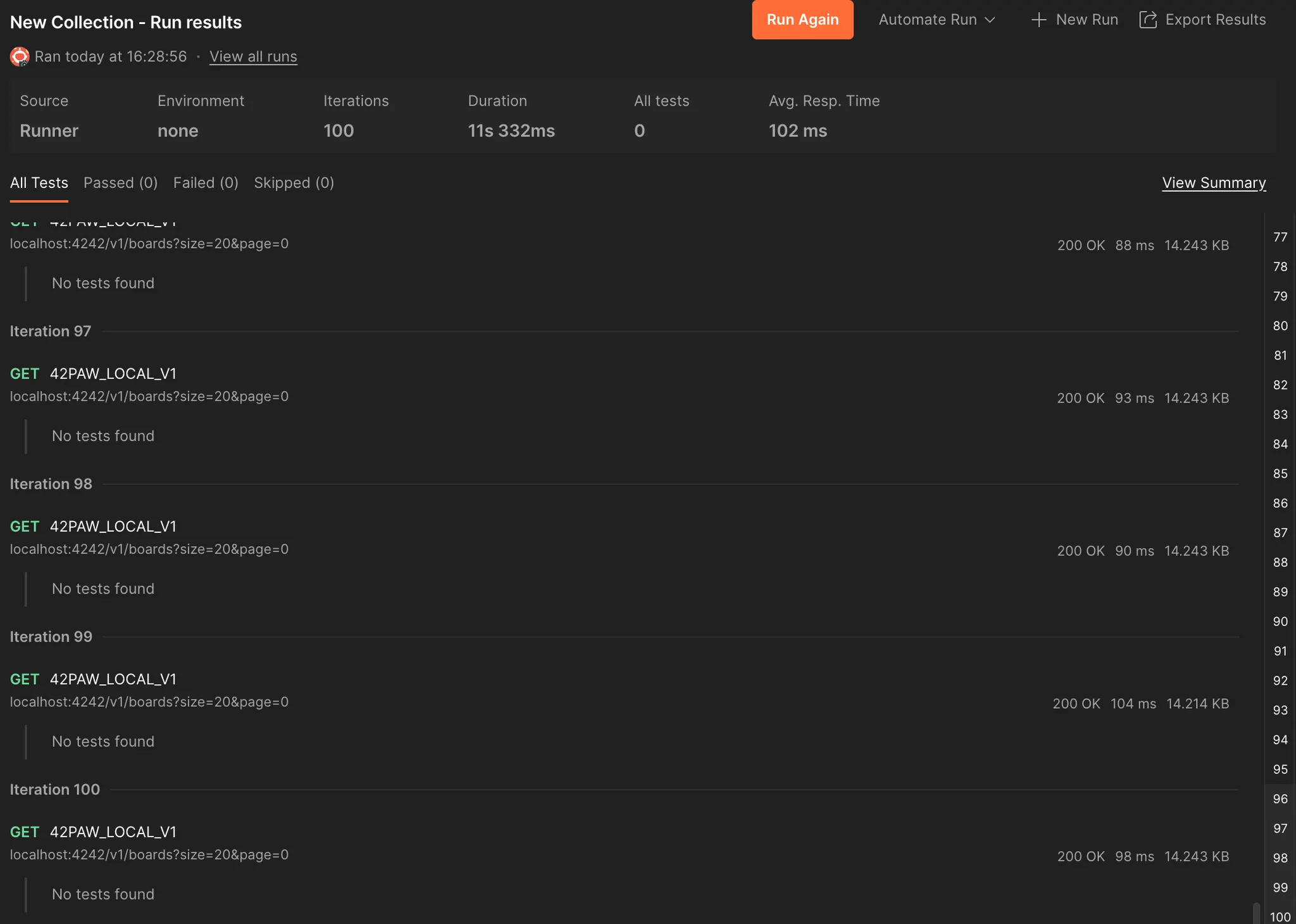
리팩토링 전에는 이와 같이 평균 응답 102 ms 정도 걸렸고, System.currentTimeMillis()를 통해 조금 더 구체적으로 걸린 시간을 측정해보면 게시글 조회 : 86 ms - 추가 쿼리 및 매핑 : 113 ms가 걸렸다.
리팩토링 후
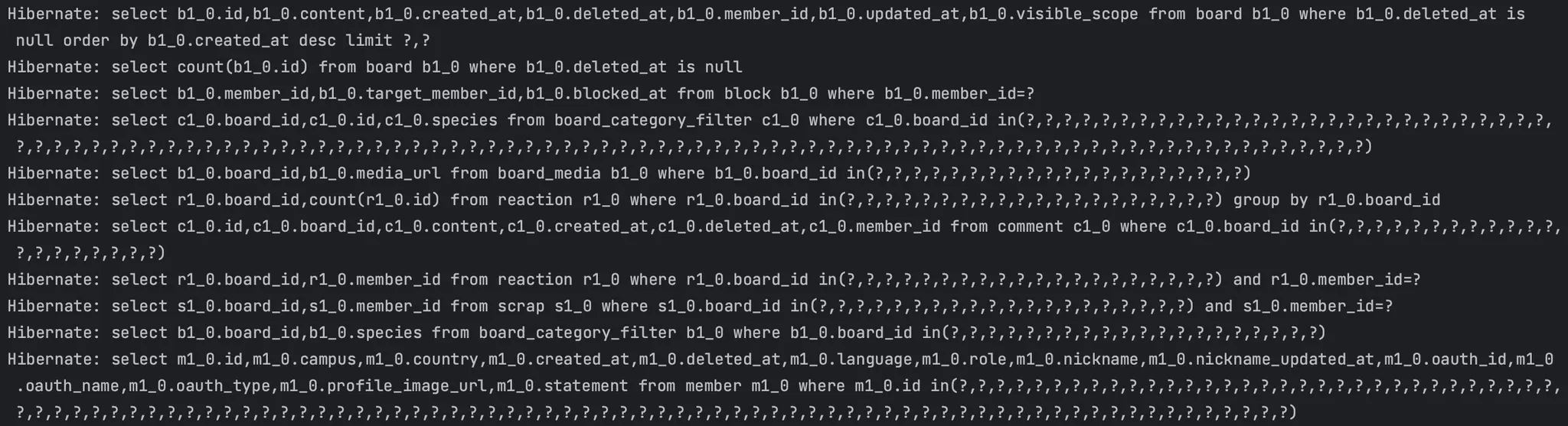
리팩토링 후에는 이처럼 쿼리가 11개로 오히려 늘어났다.
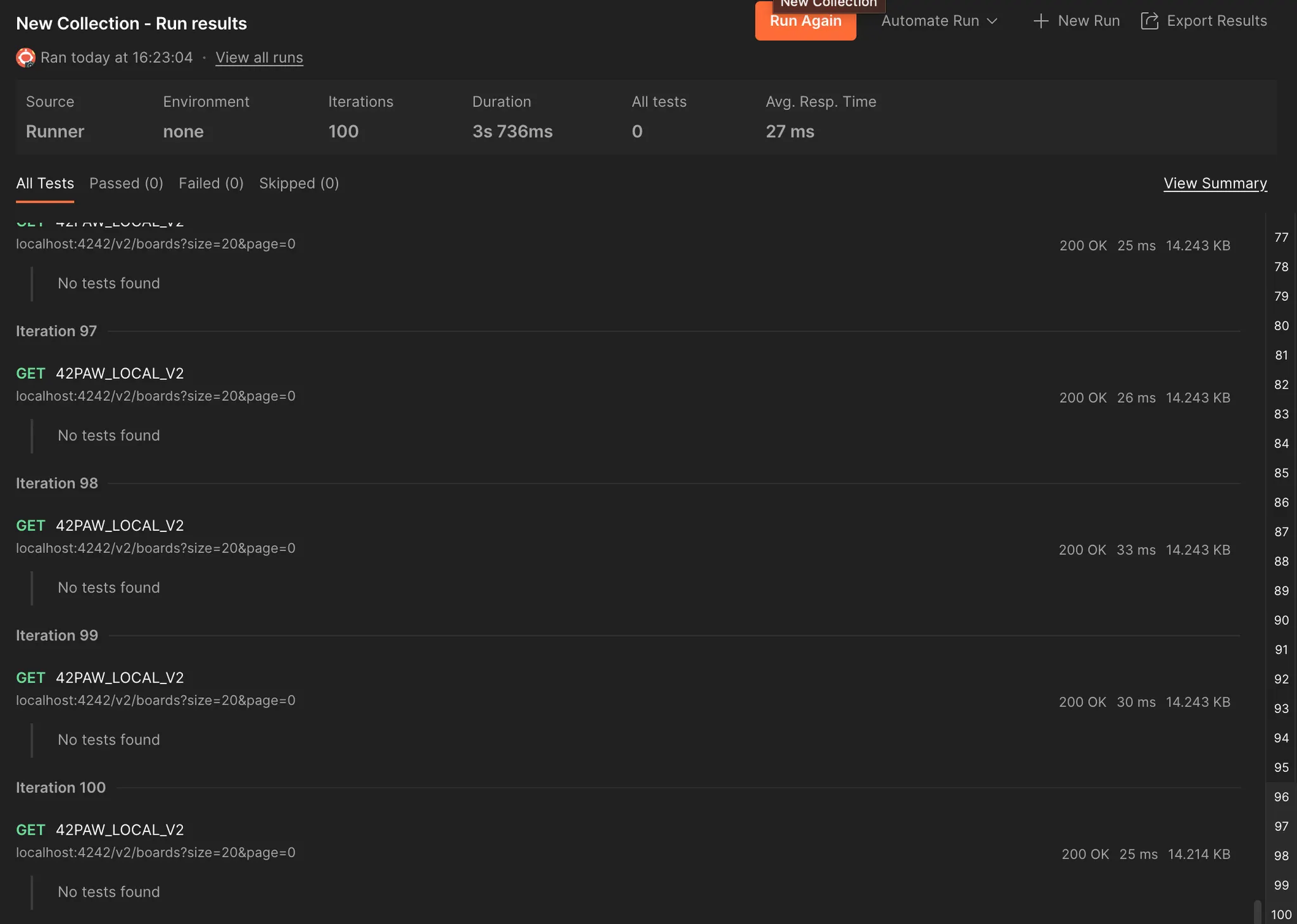
시간은 이처럼 평균 27ms, 구체적으로는 게시글 조회 : 8ms - 추가 쿼리 및 매핑 : 39ms가 걸렸고, 의외로 성능이 개선되었다.
추가적으로 배포 환경에 올려 게시글 50개인 상태에서 테스트를 진행했을 때는 다음과 같이 결과가 나왔다. 테스트는 300명의 유저가 요청을 보내는 상황을 1분 ramp-up으로 4분동안 테스트하였다.
•
리팩토링 전
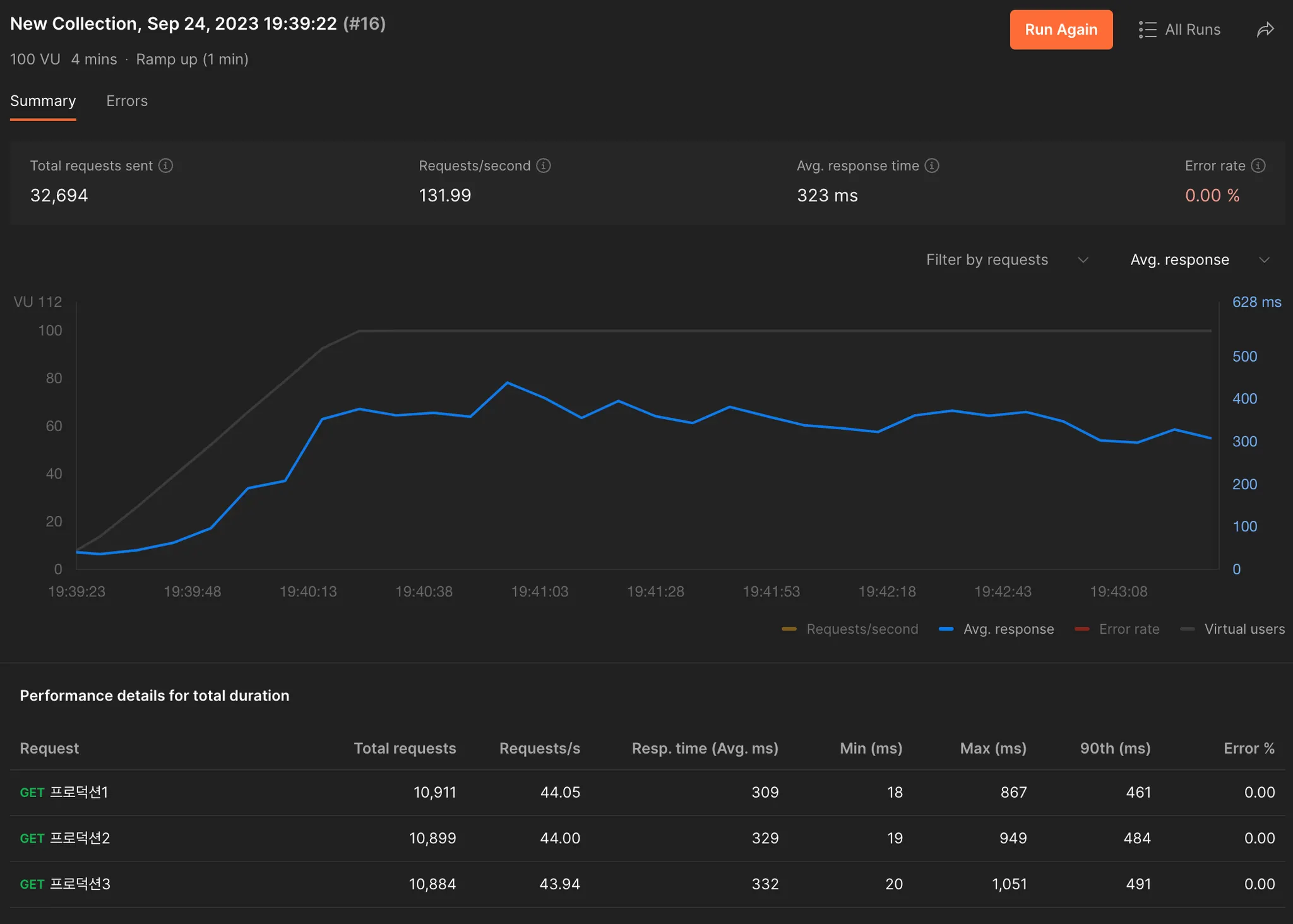
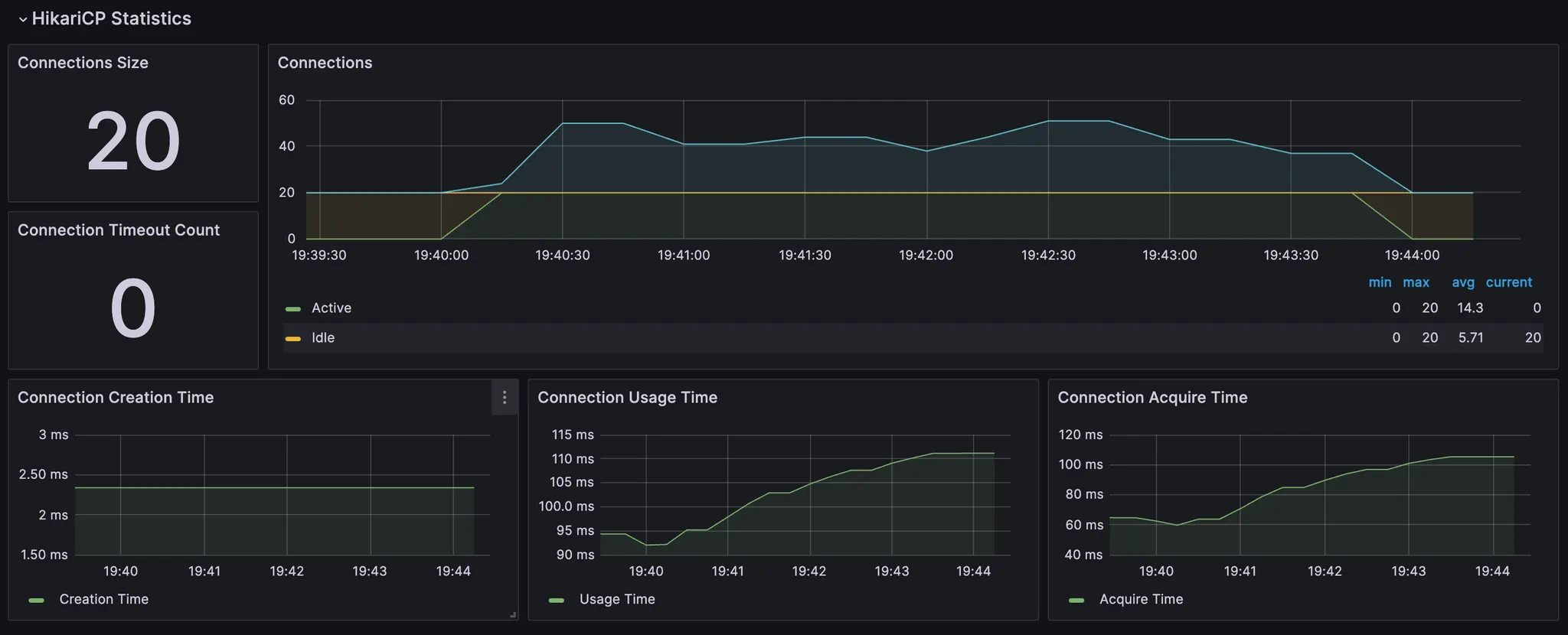
•
리팩토링 후
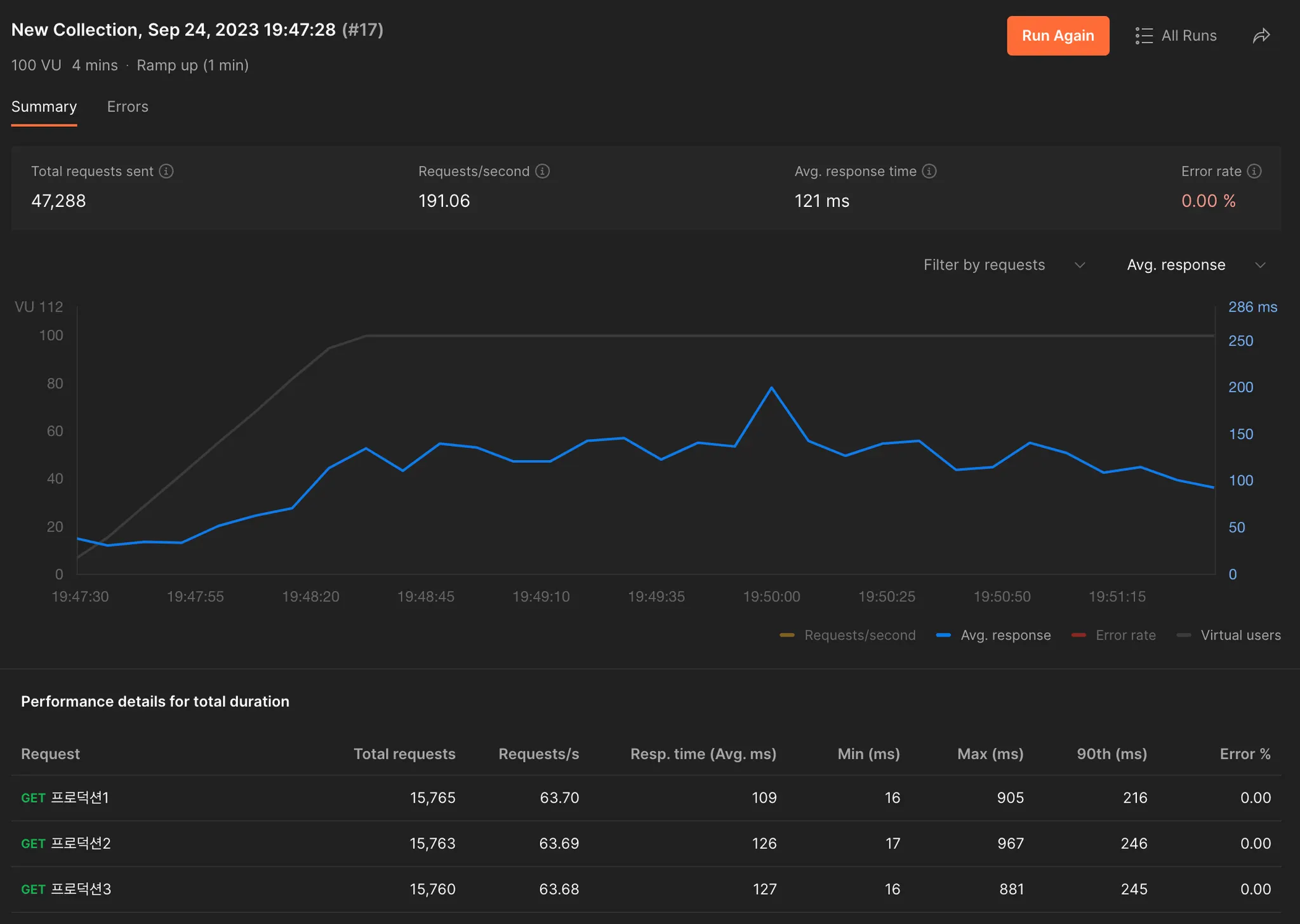
실제 배포 환경인만큼 사용자의 수에 따라 영향이 있을 것으로 생각되긴 하지만, 그것을 감안하더라도 2배 이상 빨라져 유의미한 개선 결과가 나왔다.
개선 원인 찾기
소 뒷 걸음질에 쥐 잡는 격으로 개선하긴 했지만, 원인을 분석하여 앞으로의 코드 구현 및 개선에 참고하기 위해 왜 성능이 줄어들었을까 고민해보았다.
리팩토링 전과 2차 리팩토링 후의 차이는 다음과 같다.
1.
멤버, 이미지파일, 스크랩 등 DAO 객체와 Projection을 통해 필요한 부분만 조회
2.
게시글 조회 시, 단 1개의 join도 하지 않고 게시글만 불러오기
3.
pagination을 만들기 위한 count 쿼리
4.
리팩토링 후 더 복잡해진 비즈니스 로직
이 중 3번은 개선에 도움이 되지 않으니 제외하고, 1번과 2번을 중점적으로 살펴보았다.
멤버, 이미지파일, 스크랩 등 DAO 객체와 Projection을 통해 필요한 부분만 조회
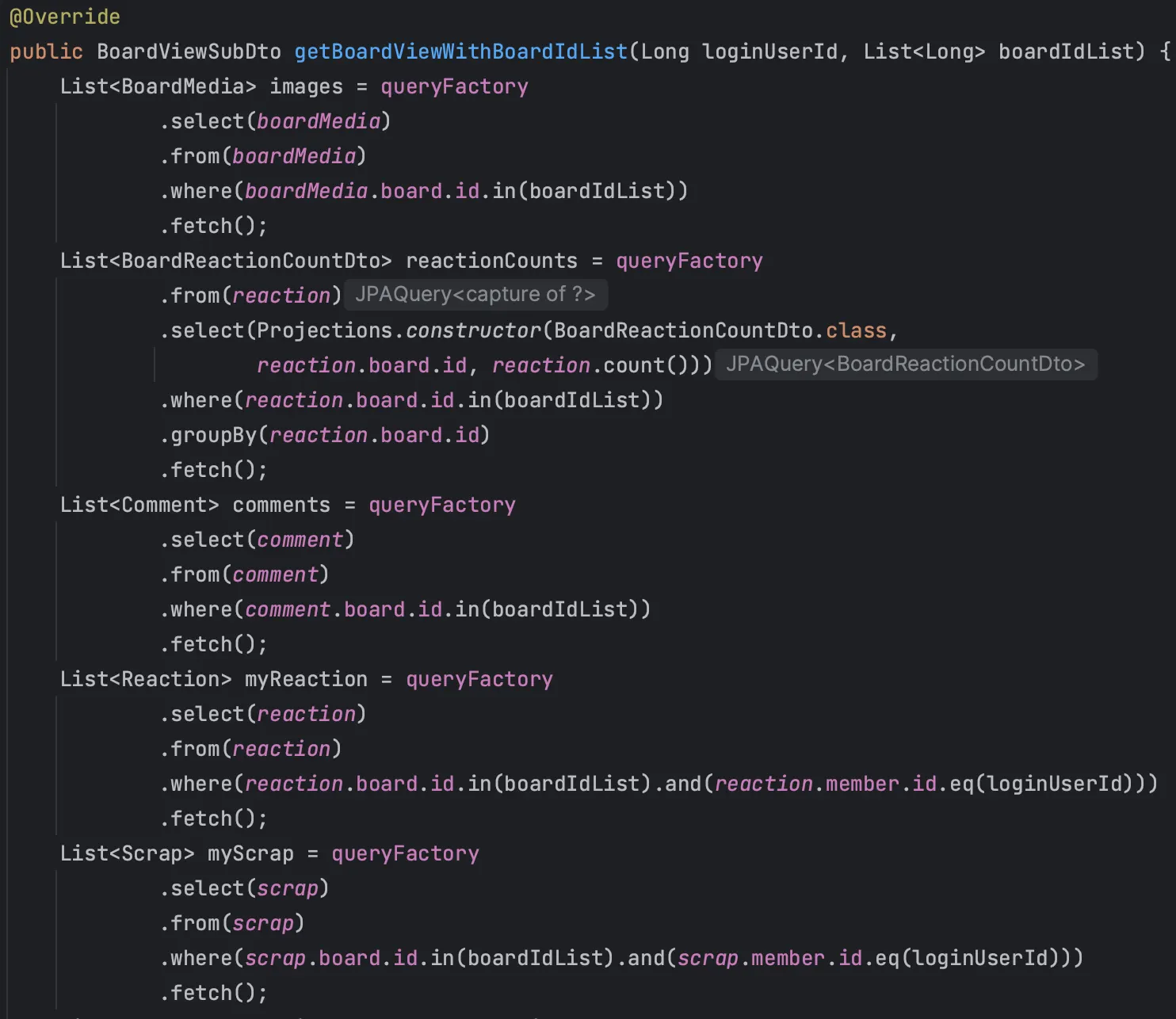
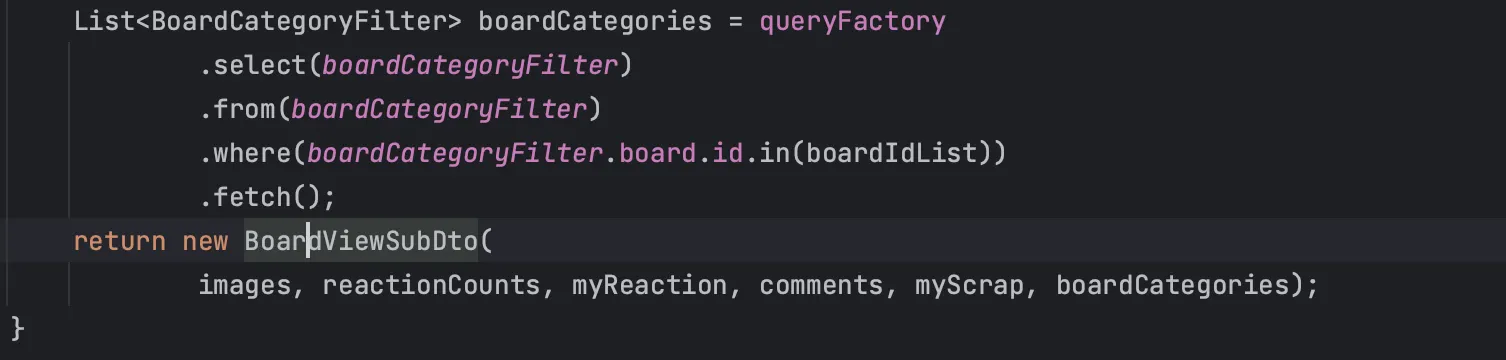
먼저 DAO 객체와 Projection의 영향을 확인하기위해, 이와 같이 count 쿼리를 제외한 나머지를 기존의 Projection을 각 엔티티를 직접 조회해오는 것으로 바꾼 후 로컬에서 테스트 해보았다.
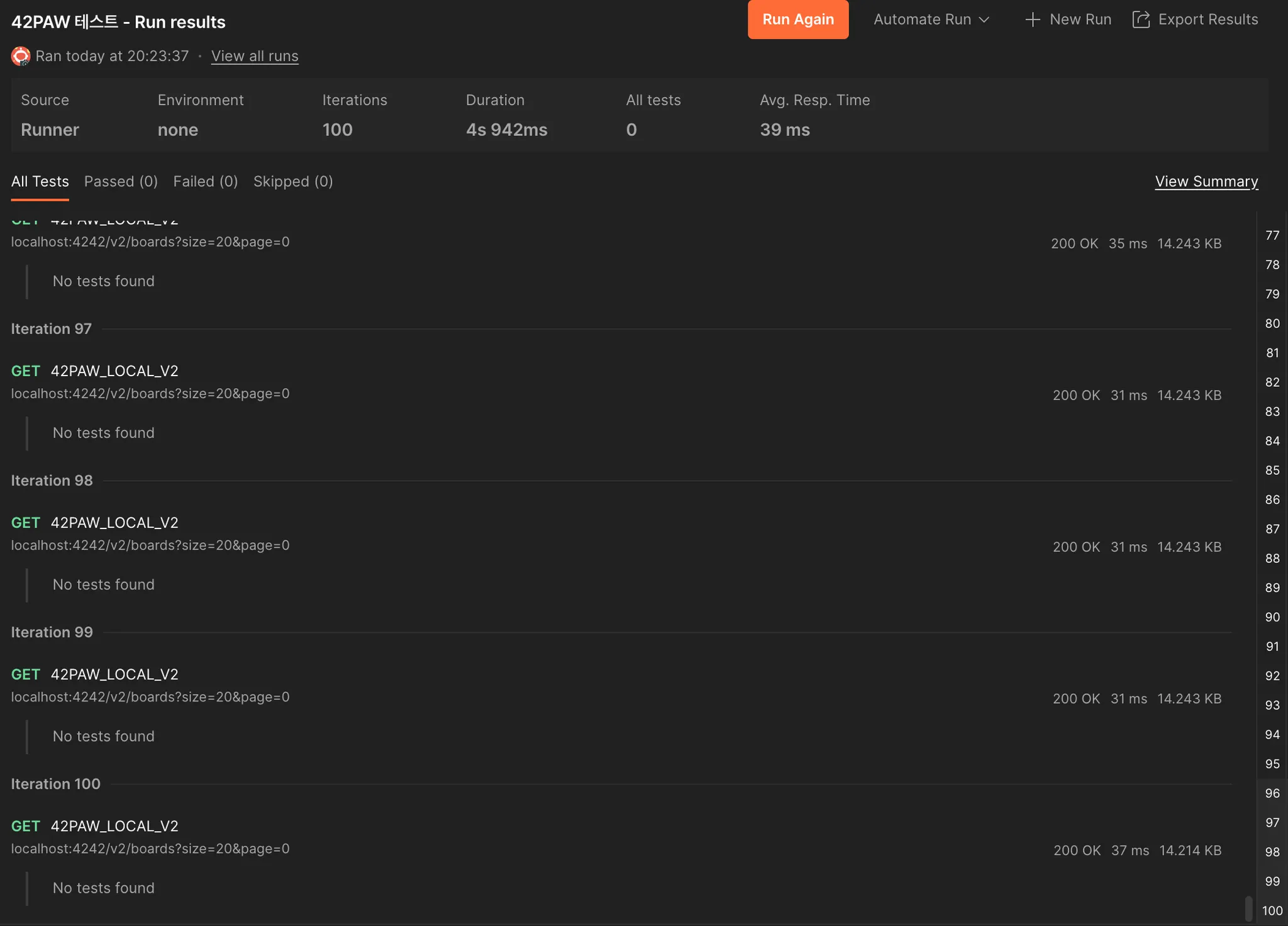
이처럼 바꾸기 전에는 39ms였고,
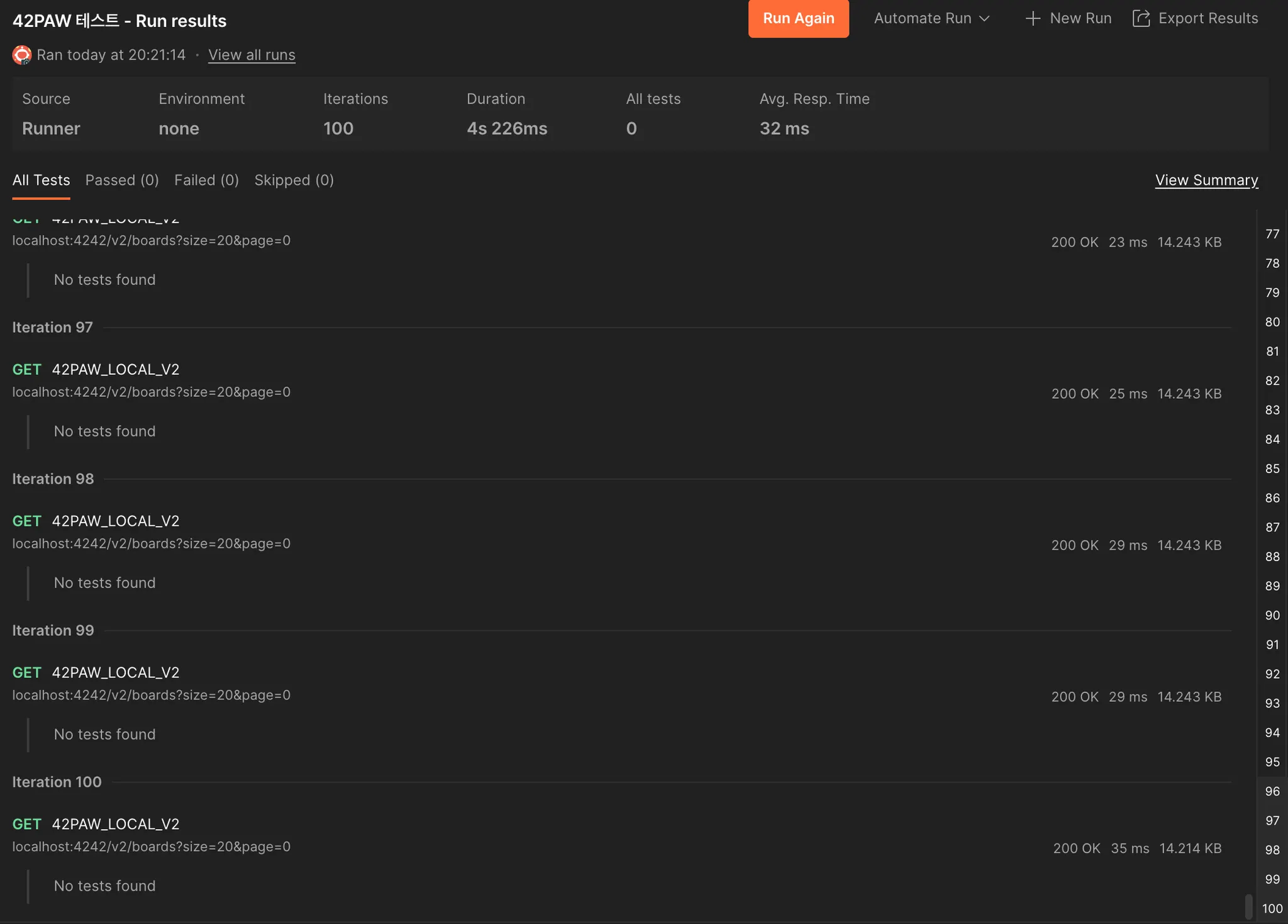
바꾼 후에는 32ms였다. 이처럼 사실상 DAO에 맞춰 Projection으로 조회를 하든 객체로 조회를 하든, 사실상 성능 차이는 무의미하다는 것을 확인했다.
게시글 조회 시, 단 1개의 join도 하지 않고 게시글만 불러오기
기존의 코드에서 Member를 fetch join하는 부분을 빼고 뒤에서 getMember()를 통해 in절로 최적화된 쿼리로 조회하도록 테스트해보았다.
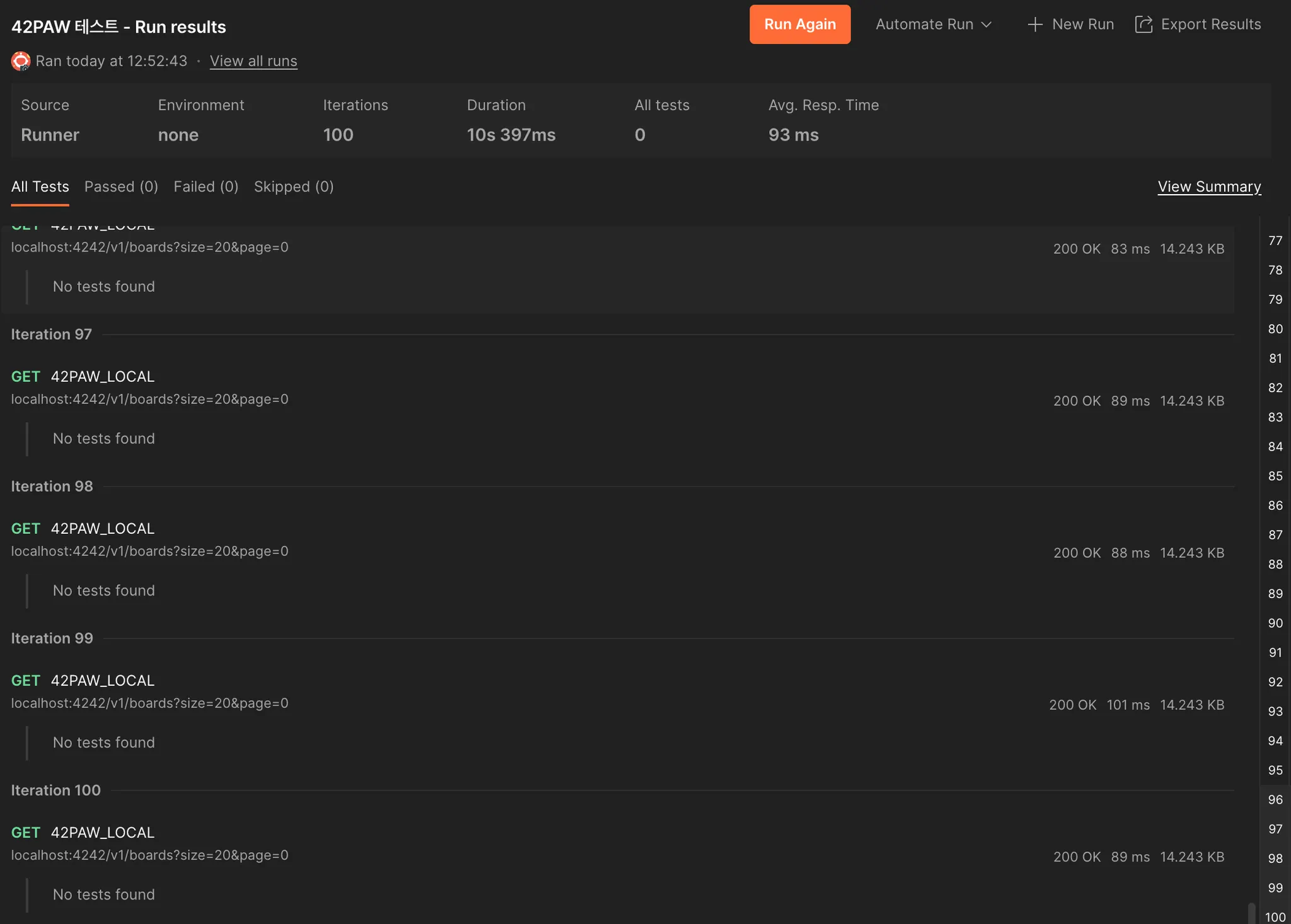
결과는 93ms로, 리팩토링 이후만큼의 성능 개선은 아니지만 join을 사용하지 않는 것으로도 아주 약간의 성능 개선이 있었다.
pagination을 만들기 위한 count 쿼리
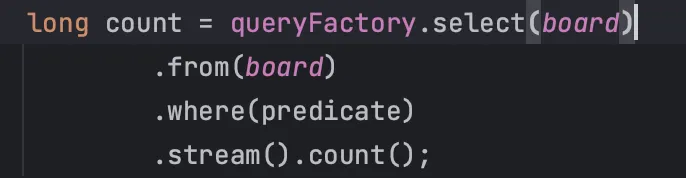
기존의 코드는 Query DSL에서 Pagination을 지원하지 않기 때문에 count 측정을 위와 같이 했다.
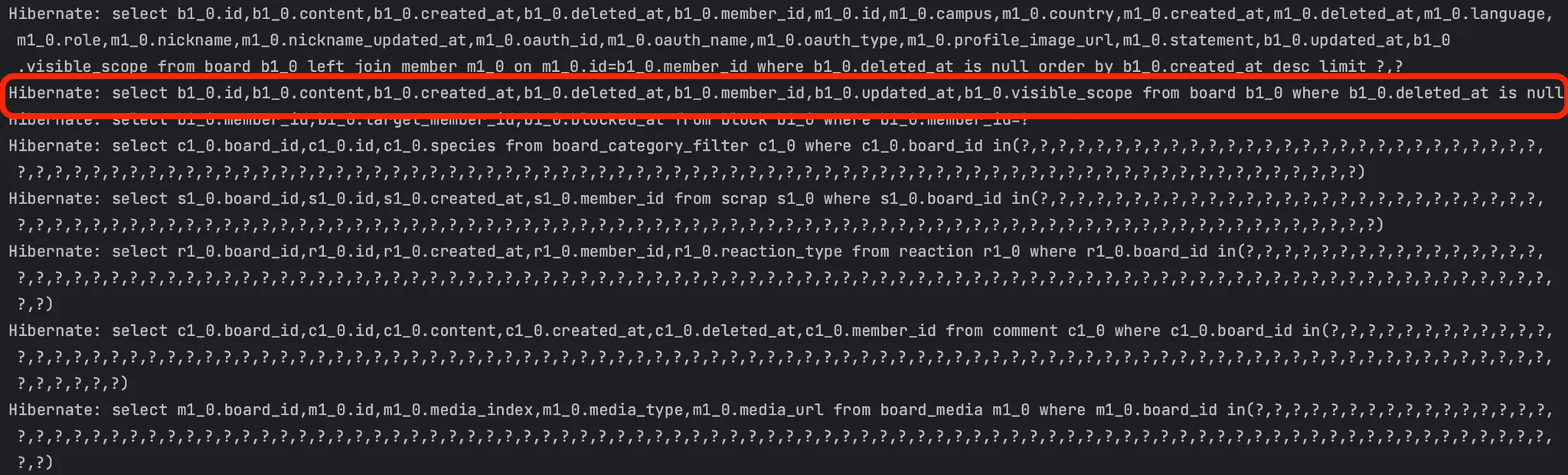
발생하는 쿼리를 살펴보면 이와 같이 count가 아닌 그냥 엔티티 조회 쿼리가 발생한다.
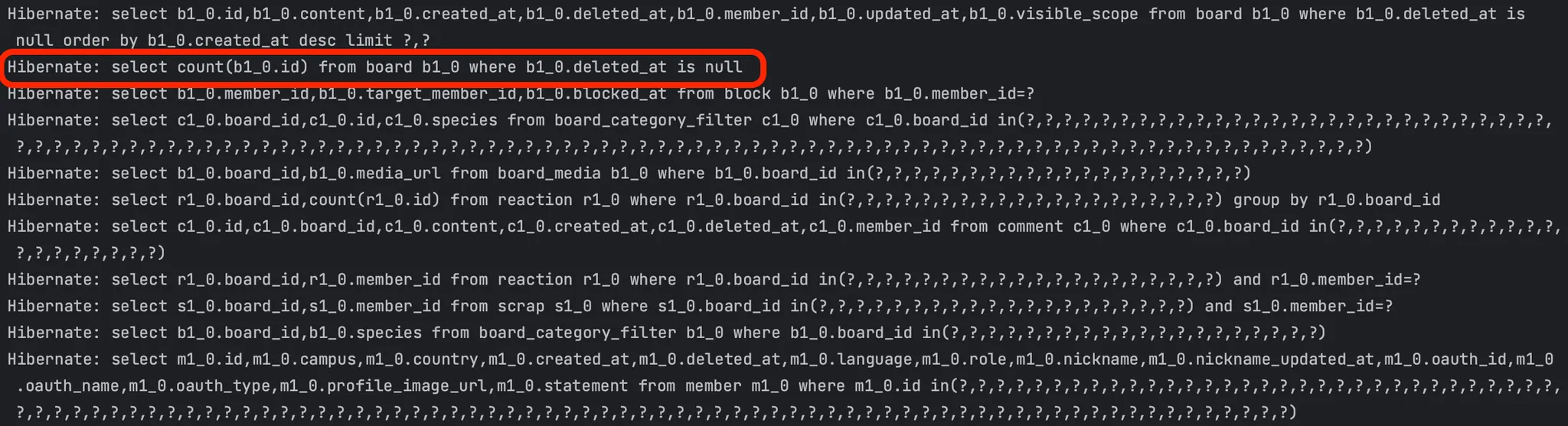
반면 리팩토링 이후에는 JPA에서 지원하는 Pagination을 사용하기 때문에 JPA 내부에서 별도의 count 쿼리를 날린다.
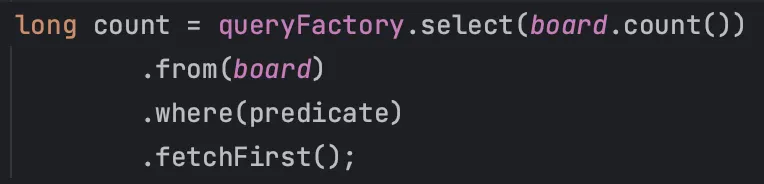
이 또한 차이가 많이 발생할 것으로 생각되어, 이를 위와 같이 수정해보았다.

그 결과 32ms로 리팩토링을 통해 개선된 것과 거의 비슷한 수준의 성능이 나왔다. 이를 통해 count가 아닌 엔티티로 값을 조회하는 것이 문제가 되었던 것을 알 수 있다.
count 쿼리 + join 사용하지 않기
그렇다면 count 쿼리를 사용하면서 join을 사용하지 않으면 성능 개선이 더 이루어질까?
테스트 결과는 25ms로, 이 또한 약간의 성능 개선이 있었다.
그럼 반대로 리팩토링 된 코드에 join을 부르면 속도가 느려질까 궁금해져 테스트 해보았다. 결과는 따로 첨부하지 않지만 어떤 값을 붙이든 join을 사용하면 속도가 조금이라도 느려지는 것을 확인했고, 특히 댓글의 경우 5만개의 더미 데이터를 넣어두었는데 댓글을 join 하면 리팩토링 전만큼 속도가 느려진다.
테스트 결과 고찰
count 쿼리의 경우 엔티티 조회 쿼리보다 빠르다는 것을 인지하고는 있었지만, 이 정도로 속도 차이가 많이 난다는 것은 처음 알게 되었다. 또한 Query DSL에서 올바른 count 사용 방법에 대해서도 새롭게 알게 되었다.
그렇다면 왜 join을 하는 순간 성능이 느려질까? 심지어 게시글 50개, 댓글 10개인 배포 환경에서도 join 안하는게 더 빠르다.

DB에서 join으로 쿼리를 날려보면, 이와 같이 결합 되는 테이블의 레코드에 따라 여러 개의 결과를 조회해온다. 이렇게 조회해온 데이터들을 DBMS 내에서 이중 반복문인 BNL(Block Nested Loop)을 사용하여 정렬하는 과정이 추가되고, 또한 JPA 내부에서도 Entity에 맞춰 여러 데이터 중 해당 컬럼만 뽑아 List로 만드는 과정을 수행하기 때문에 오래 걸리는 것으로 추측된다. 해당 SQL 구문의 mariadb 실행 계획은 다음과 같다.

당연히 인덱스 관련 설정을 하나도 하지 않았기 때문에 where를 통해 1개의 데이터만 검색하더라도 ALL type을 사용하고, 다루는 레코드 수는 각 전체를 탐색하여 100 + 167로 267이다.

이를 join 없이 in 절을 통해 조회하면 이처럼 동일하게 전체 탐색을 각각 수행하여 167개의 레코드를 다룬다. 결과적으로 동일한 수의 레코드를 다루니, 위에서 언급한 부가 과정들이 없는 join 없이 사용하는 쪽이 조금 더 빠른 것으로 생각된다.
결과가 이렇다보니 join은 인덱스를 적용하거나, 동시에 가져와야하는 연관관계가 1개여서 실질적으로 1 + N 문제가 발생하는 경우에만 최적화를 위해서 사용해야겠다는 생각이 들었다. 이번 리팩토링과 같이 여러 연관 관계들이 복잡하게 얽혀있는 경우에는 이처럼 IN 절을 통한 최적화로 구성하는 방법이 더 좋을 것 같다.



