
조건 분기에 불필요한 UNION 쓰지말기
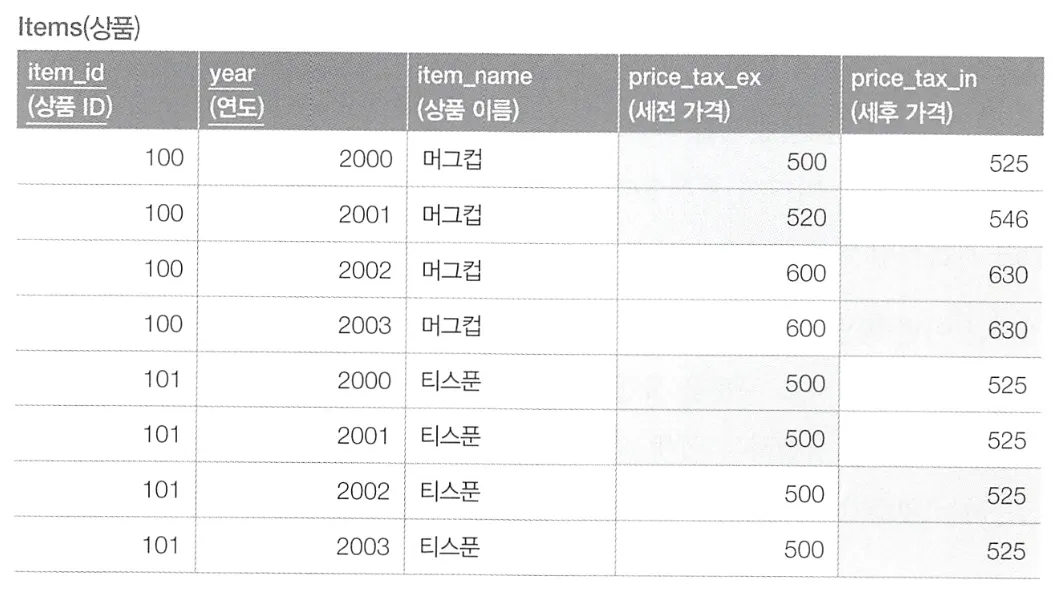
이와 같은 테이블이 있고, 이를 조회하여 넘겨줄 때 연도를 기준으로 2001년 이전은 세전 가격을 주고 2002년 이후는 세후 가격을 넘겨주어 아래와 같은 결과를 만들고자 한다.
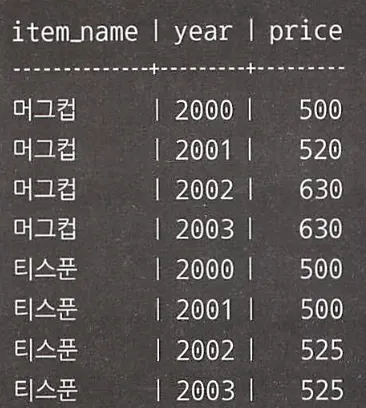
year를 조건 분기로 2001년 이전과 2002년 이후를 구분해서 가격을 선택하면 될 것이다.
SELECT item_name, year, price_tax_ex AS price FROM Items
WHERE year <= 2001
UNION ALL
SELECT item_name, year, price_tax_in AS price FROM Items
WHERE year >= 2002;
SQL
복사
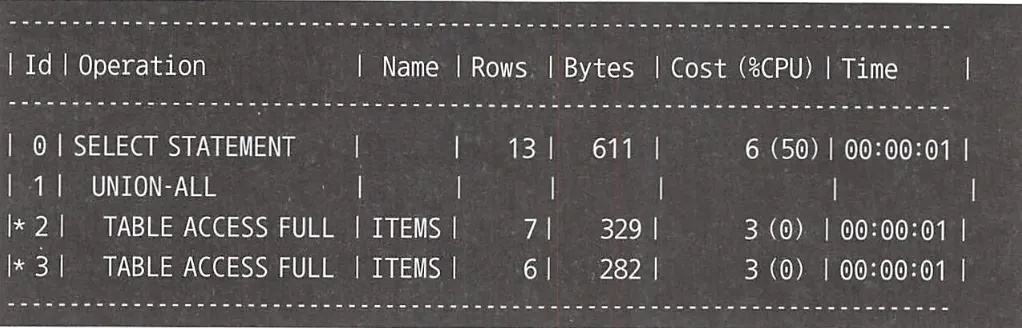
위와 같이 쿼리를 작성하기 쉽지만, 이는 길고 가독성이 좋지않은데다가 성능상 문제가 있다. 위 SQL 구문의 실행 계획을 보면 다음과 같다.

PostgreSQL 실행 계획
Oracle 실행 계획
두 DBMS 모두 Items 테이블에 2번 접근해, 거의 동일한 로직을 TABLE ACCESS FULL로 조회해오는 것이다.
UNION은 간단하게 레코드 집합을 합칠 수 있지만, 위와 같은 실수를 하기 쉬워 정확한 판단을 통해 필요한 경우에만 사용해야한다. 위의 SQL 구문은 WHERE 절에서 조건 분기를 했는데, 이는 SQL 초보자나 사용하는 방법이다.
SELECT item_name, year,
CASE WHEN year <= 2001 THEN price_tax_ex
WHEN year >= 2002 THEN price_tax_in
FROM Items;
SQL
복사
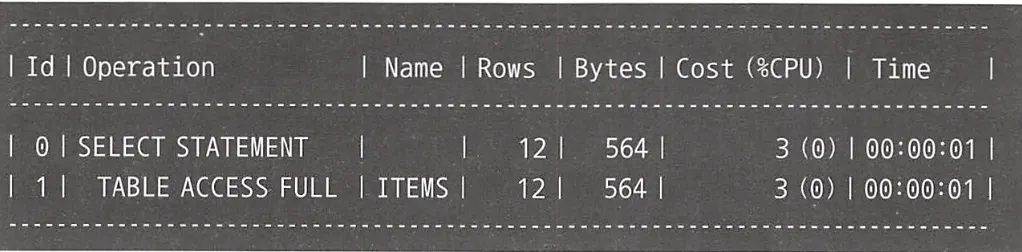
이와 같이 CASE 식을 사용해 가독성 좋으면서도 성능상 문제가 없는 SQL 구문을 작성할 수 있다.

PostgreSQL 실행 계획
Oracle 실행 계획
실제 실행 계획을 살펴보면, 테이블에 한번만 접근하고도 동일한 레코드들을 조회해오는 것을 확인할 수 있다.
UNION을 사용한 조건 분기는 ‘SELECT 구문’을 기본 단위로 하기 때문에, 이는 절차 지향형 프로그래밍의 발상을 벗어나지 못한 방법이다. CASE 식을 사용한 조건 분기는 ‘식’을 기본 단위이고, SQL에서는 구문 위주보다 식 위주의 사고를 하는 것이 더 좋다.
집계와 조건 분기
집계 대상에 UNION을 사용하는 경우
집계를 수행하는 쿼리를 작성할 때도, UNION을 불필요하게 사용하는 경우가 있다.
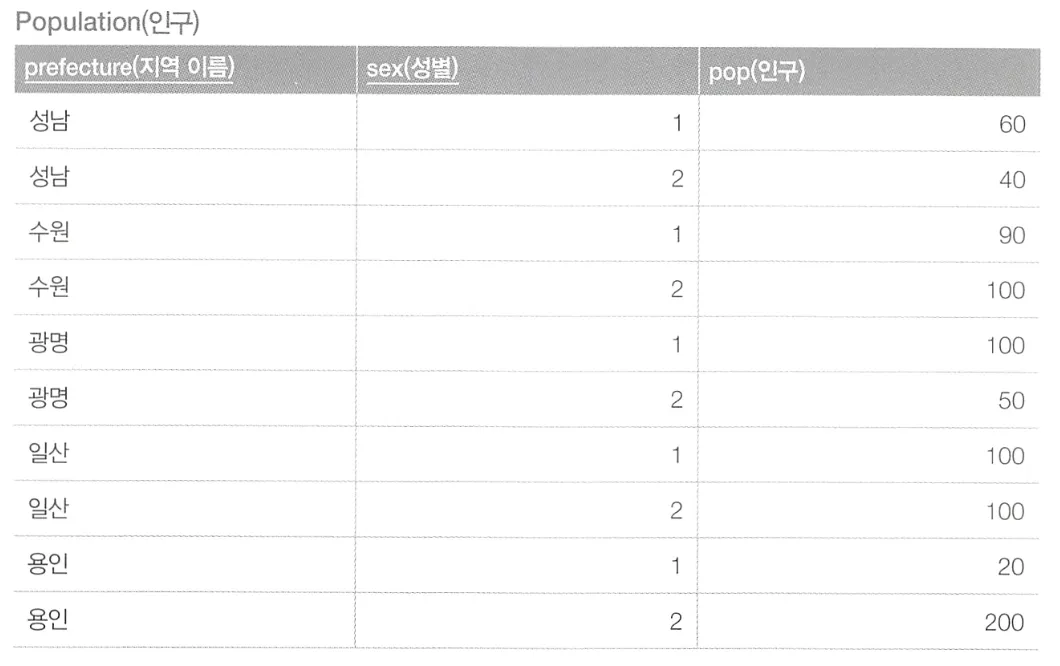
위의 테이블에서 지역별로 남자 인구, 여자 인구를 한 번에 볼 수 있게 아래처럼 출력하고자 한다.


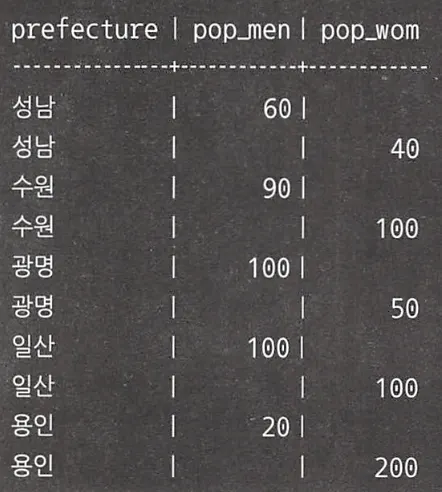
UNION을 사용하고자 한다면 이와 같이 코드가 복잡해지고, 실제 출력도 아래와 같이 NULL이 포함되어 원하는대로 나오지 않을 것이다.

실행 계획을 살펴봐도, Populations 테이블에 대해 풀 스캔이 2번 수행된다.
이 예시 또한 UNION 대신 CASE 식을 사용하여 더 간결하고 성능도 더 좋게 만들 수 있다.
SELECT prefecture,
SUM(CASE WHEN sex = '1' THEN pop ELSE 0 END) AS pop_men,
SUM(CASE WHEN sex = '2' THEN pop ELSE 0 END) AS pop_wom,
FROM Population GROUP BY prefecture;
SQL
복사

집약 결과에 UNION을 사용하는 경우
집약 결과에 불필요하게 UNION을 사용하여, 가독성과 성능을 망치는 패턴이 있다.
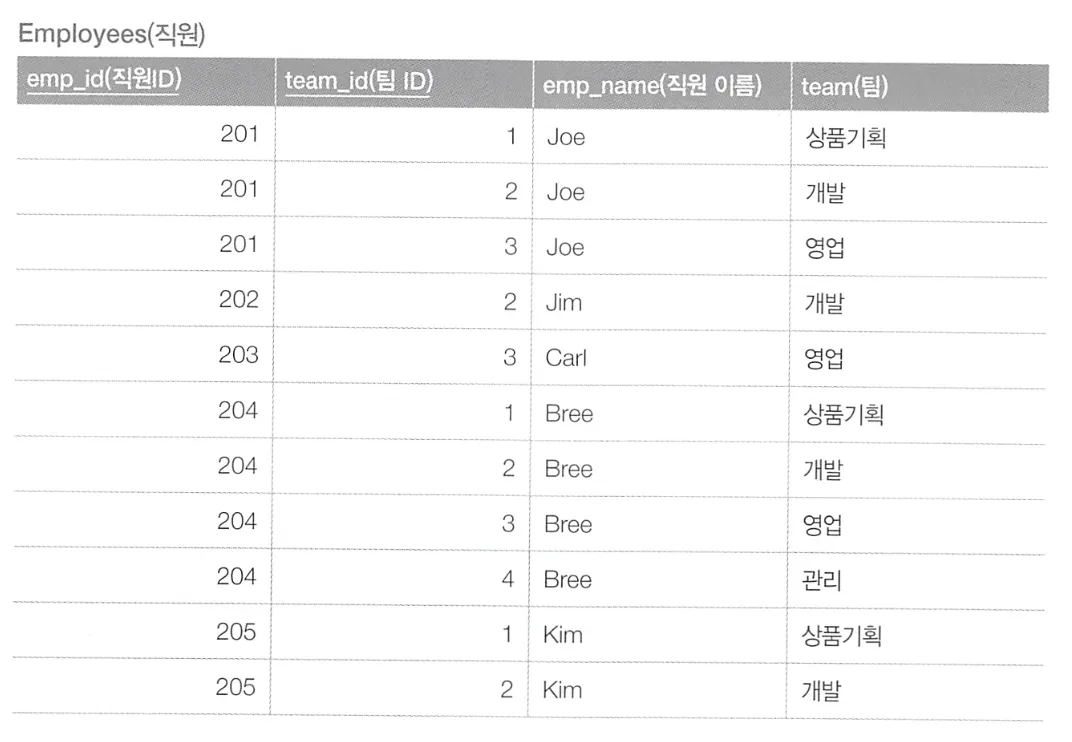
위 테이블에서 아래 출력처럼 소속된 팀의 개수에 따라 팀의 이름을 다르게 출력하려 한다.


이와 같이 UNION을 사용하면 쿼리가 길고 복잡하여 가독성이 떨어진다.

이 역시 예상할 수 있듯이 아래 실행 계획처럼 Employees 테이블에 3번 접근하게 된다.
마찬가지로 CASE 식을 사용하여 조건 분기를 나누면 훨씬 깔끔하고 성능도 좋은 쿼리를 만들 수 있다.
SELECT emp_name,
CASE WHEN COUNT(*) = 1 THEN MAX(team)
WHEN COUNT(*) = 1 THEN '2개를 겸무'
WHEN COUNT(*) = 1 THEN '3개 이상을 겸무'
END AS team
FROM Employees GROUP BY emp_name;
SQL
복사

앞서 말했던 WHERE 구에 조건 분기를 적용하는 것은 초보자나 사용하는 방법이라 했는데, HAVING 구에 조건 분기를 사용하는 것도 마찬가지로 초보자나 사용하는 방법이다.
UNION을 사용해야 하는 경우
UNION을 사용해야만 하는 경우
SELECT col_1 FROM Table_A
WHERE col_2 = 'A'
UNION ALL
SELECT col_3 FROM Table_B
WHERE col_4 = 'B';
SQL
복사
이와 같이 서로 다른 테이블에서 검색한 결과를 머지(MERGE)하는 경우에는 UNION을 사용해야만 한다.
FROM 구에 테이블을 결합하여 CASE 식으로 원하는 결과를 구할 수 있지만, 그렇게하면 필요 없는 결합이 발생해 성능이 저하된다(UNION은 저하 없음).
UNION을 사용하는 것이 성능적으로 더 좋은 경우
UNION을 사용하면 인덱스를 사용하여 빠르게 가져오지만, UNION을 사용하지 않으면 테이블 풀 스캔이 발생하는 상황에서 UNION을 사용하는 방법이 성능적으로 더 좋을 수 있다.
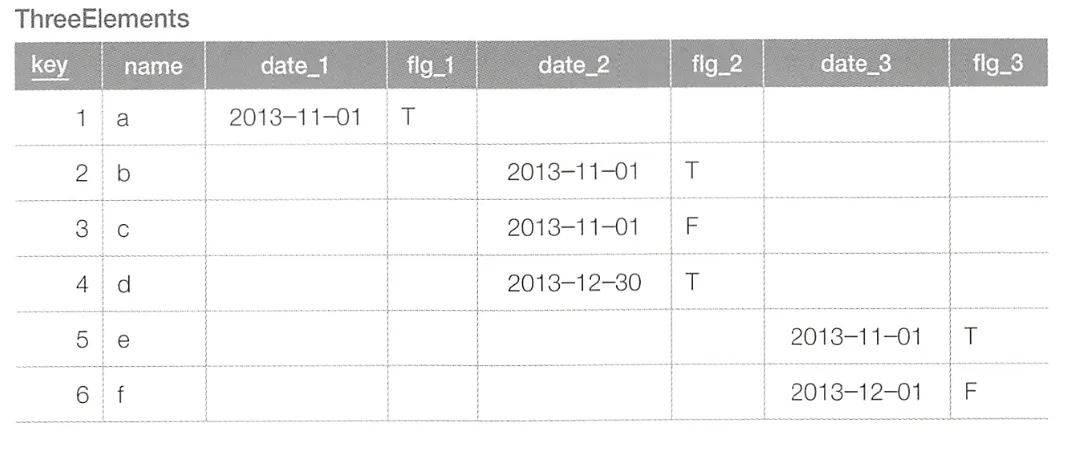
위와 같은 테이블이 있고, 그 중 3개의 레코드를 뽑아 아래와 같이 출력하고자 한다.

이를 UNION으로 쿼리를 작성하면 아래와 같다.


이와 같이 인덱스를 설정하고, UNION을 통해 쿼리를 작성하면 실행 계획은 아래와 같이 ThreeElements 테이블에 3번 접근하게 된다.
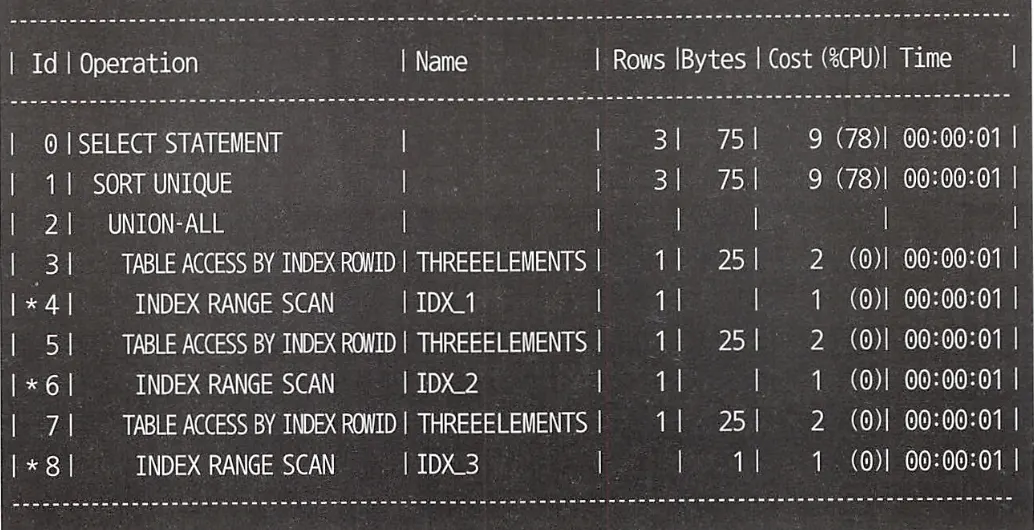
하지만 여기서 테이블에 접근을 INDEX SCAN을 통해서 했다는 점이 중요하다.
위를 UNION 없이 쿼리를 작성하려면, WHERE에 OR 조건을 넣거나 IN 절을 통해 해결할 수 있다.
SELECT key, name,
date_1, fig_1,
date_2, fig_2,
date_3, fig_3
FROM ThreeElements
WHERE (date_1 = '2013-11-01' AND flag_1 = 'T')
OR (date_2 = '2013-11-01' AND flag_2 = 'T')
OR (date_3 = '2013-11-01' AND flag_3 = 'T');
SQL
복사

테이블에 대한 접근은 1번만 수행되지만 FULL SCAN이 수행되었다.
SELECT key, name
date_1, fig_1,
date_2, fig_2,
date_3, fig_3
FROM ThreeElements
WHERE ('2013-11-01', 'T')
IN ((date_1, fig_1),(date_2, fig_2),(date_3, fig_3))
SQL
복사
IN절을 사용해도 OR을 사용한 것과 실행 계획은 동일하다.
위 경우에는 어떤 쿼리를 사용하는 것이 권장되는지는, 3회의 인덱스 스캔과 1회의 테이블 풀 스캔 중 어떤 것이 더 빠른지에 따라 결정된다. 테이블의 크기와 검색 조건에 따른 레코드 히트율에 따라 달라질 수 있다.
절차 지향형과 선언형
위의 내용들을 살펴보면 UNION을 사용한 조건 분기는 예외적인 상황을 제외하면 가급적 사용하지 않는 것이 성능적으로나 가독성으로나 더 좋다.
대부분의 프로그래밍 언어는 절차 지향형 언어이고, 절차 지향형 프로그래밍 언어에서의 기본 단위는 구문(statement)이다. 그렇기 때문에 SQL에 익숙하지 않을수록 구문 중심의 사고를 하게 된다. 하지만 SQL은 식(expression)이 기본단위인 선언형 언어이다. 가급적 구문 중심의 사고가 아닌 식 중심의 사고를 통해 좋은 SQL을 작성하자.