
대용량 저장장치 구조의 개관
•
최신의 컴퓨터에 대량의 보조저장장치는 하드 디스크 드라이브(HDD)와 비휘발성 메모리(NVM) 장치에 의해 제공된다.
1.
하드 디스크 드라이브
•
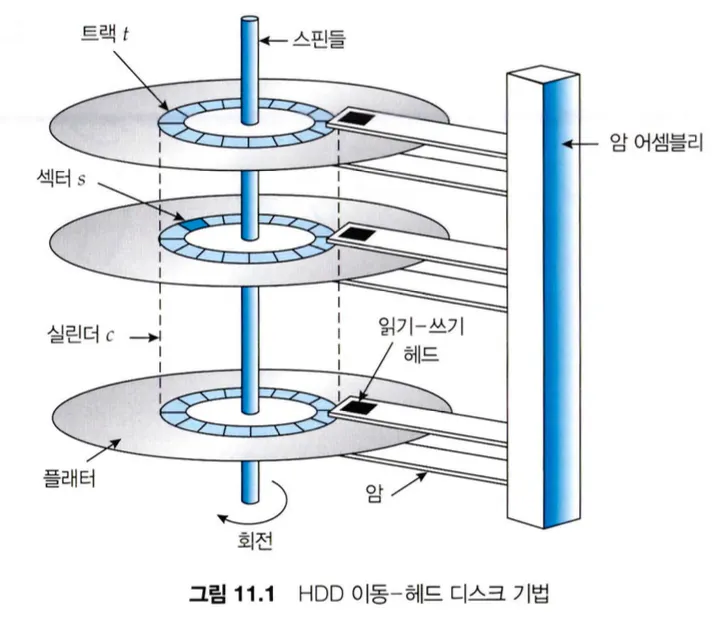
HDD의 CD처럼 생긴 원형 평판은 플래터(platter)인데, 플래터의 양쪽 표면은 자기 물질로 덮여있어 자기적으로 기록하여 저장하고 자기 패턴을 감지해 정보를 읽는다.
•
읽기-쓰기 헤드는 디스크 암(disk arm)에 부착되어 모든 플래터의 표면 위에서 움직이며 데이터를 읽고 쓴다.
•
플래터의 표면은 원형인 트랙(track)과 피자 조각 같은 모양의 섹터(sector)로 나누어지고, 동일한 암 위치에 있는 트랙의 집합으로 하나의 실린더(cylinder)를 형성한다.
•
디스크 드라이브 모터는 고속으로 회전하는데, 분당 회전수(RPM) 단위로 표현되며 초당 60~250회 정도 회전한다. 전송 속도는 드라이브와 컴퓨터 간의 데이터 흐름의 속도인데, 전송 속도는 드라이브 모터의 회전 속도와 관련이 있다.
•
위치 지정 시간 혹은 임의 액세스 시간은 디스크 암을 원하는 실린더로 이동하는 탐색 시간과 원하는 섹터가 디스크 헤드 위치까지 회전하는데 걸리는 회전 지연시간이 있다.
•
디스크 플래터는 얇은 보호 층으로 코팅되어 있지만, 간혹 디스크 헤더가 닿아 자기 표면을 손상하는 헤드 충돌이 발생한다. 헤드 충돌은 일반적으로 수리가 불가하고 디스크 전체를 교체해야 한다.
2.
비휘발성 메모리 장치
•
플래시 메모리 기반 NVM은 디스크 드라이브와 유사한 컨테이너에서 사용되며 SSD(solid-state disk)라 부른다. 다른 경우에는 USB 드라이브 또는 DRAM 스틱의 형태를 취한다.
•
NVM 장치는 움직이는 부품이 없기 때문에 HDD보다 안정성이 높고, 탐색 시간과 회전 지연시간이 없기 때문에 더 빠르고 전력 소비량이 적다.
•
플래시 NVM은 NAND 반도체를 사용하는데 NAND 반도체는 그 특성 때문에 저장과 신뢰성에 문제가 있다. 페이지 단위로 읽고 쓰는 것은 가능하지만, 데이터를 덮어쓰는게 불가능하기 때문에 먼저 지우고 저장해야한다.
•
또한 NAND 반도체는 사용할 때마다 기능이 열화되어 100,000번의 사용 후에는 해당 셀의 기능이 정지한다.
•
NAND 반도체는 덮어쓰기가 불가능하기 때문에 유효하지 않은 데이터가 포함된 페이지가 발생하는데, 유효한 데이터 페이지를 추적하기 위해 컨트롤러가 플래시 변환 계층(FTL)을 유지한다.
•
가비지 수집 하는 경우 유효한 데이터를 옮기기 위해 전체 용량의 20%정도를 따로 준비해놓는 과잉 공급(over-provisioning)을 사용한다.
•
과잉 공급 공간은 다른 블록에 비해 일부 블록이 빨리 마모되는 것을 방지하기 위한 마모 평준화(wear leveling)에도 도움이 된다.
3.
휘발성 메모리
•
운영체제에 의해 할당되는 버퍼와 캐시와는 달리, RAM 드라이브 보조저장장치는 사용자와 프로그래머가 표준 파일 연산을 사용해 데이터를 임시로 보관할 수 있다.
4.
보조저장장치 연결 방법
•
보조저장장치는 시스템 버스 혹은 I/O 버스에 의해 컴퓨터에 연결되는데, ATA(advanced technology attachment), SATA(serial ATA), SAS(serial attached SCSI), USB(universal serial bus) 등 여러 종류의 버스를 사용할 수 있다.
•
NVM 장치는 HDD보다 훨씬 빠르기 때문에 NVMe(NVM express)라는 NVM 장치를 위한 장치를 만들었다. NVMe는 PCI 버스에 직접 연결하여 처리량을 높이고 지연시간을 줄인다.
•
버스에서 데이터 전송은 컨트롤러 혹은 호스트 버스 어댑터(HBA)라고 불리는 특수 전자 프로세서에 의해 수행된다. 호스트 컨트롤러는 버스의 컴퓨터 쪽에 있는 컨트롤러이며, 각 장치에 장치 컨트롤러가 내장되어 있다.
5.
주소 매핑
•
저장장치는 가장 작은 전송단위인 논리 블록의 커다란 1차원 배열처럼 주소가 매겨지는데, 각 논리 블록은 논리 블록 주소(LBA)를 통해 물리 섹터 또는 반도체 페이지로 매핑된다.
•
HDD에서는 논리 블록 번호를 실린더 번호, 트랙 번호, 섹터 번호로 구성된 디스크 주소로 변환할 수 있지만, 실제적으로 구현은 다음의 세 가지 이유로 어렵다.
◦
대부분 드라이버에는 결함이 있는 섹터가 존재하지만 매핑은 드라이브의 다른 곳에 있는 예비 섹터로 대체해 이를 숨긴다.
◦
고정 선형 속도(CLV, constant linear velocity)를 사용하는 장치에서는 트랙당 비트 밀도가 일정한데, 트랙이 디스크 중심에서 멀어질수록 트랙의 길이가 길어져 더 많은 섹터를 가질 수 있다. 하드디스크를 여러 구역으로 나누어 관리하는데, 트랙당 섹터 수는 한 구역 안에서는 일정하지만 구역 간에는 차이가 발생할 수 밖에 없다. 이를 해결하기 위해서는 트랙 바깥으로 갈수록 회전 속도를 높이거나, 바깥 트랙으로 갈수록 비트 밀도를 줄여 데이터 비율을 일정하게 유지하는 고정각 속도(CAV, constant anguler velocity) 방식을 사용해야한다.
◦
디스크 제조 업체는 LBA와 물리 주소 간의 매핑을 내부적으로 관리하므로 LBA와 물리적 섹터 간에 관계가 거의 없다.
디스크 스케줄링
1.
선입선처리(FCFS) 스케줄링

•
가장 간단한 형태의 방식으로, 공평해보이지만 빠른 서비스를 제공하지는 못한다.
2.
SCAN 스케줄링
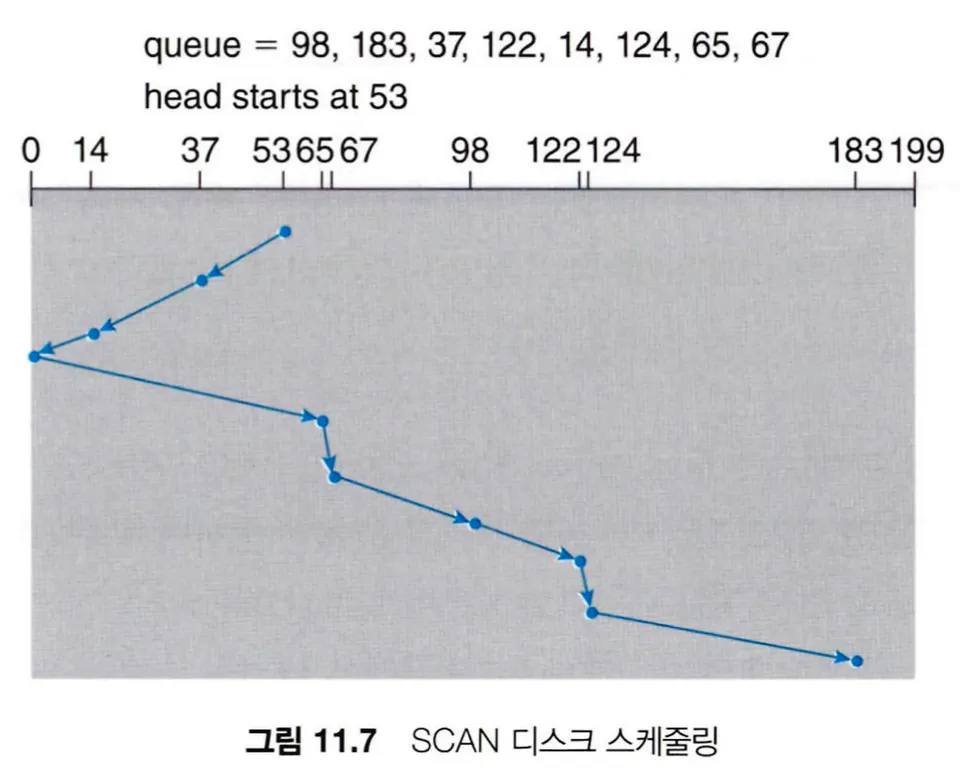
•
SCAN 알고리즘은 디스크 암이 한쪽 끝에서 다른 끝까지 이동하며 가는 길에 있는 요청을 모두 처리한다. 헤드는 디스크의 양쪽을 계속해서 가로지르며 왕복하는데, 엘리베이터의 동작과 유사하다고 하여 엘리베이터 알고리즘이라고도 부른다.
3.
C-SCAN 스케줄링

•
Circular-SCAN 스케줄링은 SCAN 알고리즘을 변형하여, 헤드를 한쪽으로 이동해 가면서 요청을 처리하지만 끝에 다다르면 반대로 도는게 아니라 처음 시작했던 자리로 돌아가 반복한다.
NVM 스케줄링
•
NVM 장치들은 이동 디스크 헤드가 없기 때문에 일반적으로 간단한 FCFS 정책을 사용한다.
•
I/O는 순차적으로 혹은 무작위로 발생할 수 있는데, 읽거나 쓸 데이터가 읽기/쓰기 헤드 근처에 있기 때문에 하드디스크와 같은 장치에서는 순차적 액세스가 최적이지만, 초당 입출력 연산 수(IOPS)로 측정되는 무작위 액세스 I/O는 하드디스크의 헤드 이동을 유발하기 때문에 NVM에서 훨씬 빠르다.
•
NVM에서 모든 블록이 기록되었지만 사용 가능한 여유 공간이 있다면 가비지 수집을 실행하는데, 가비지 수집을 하면서 페이지 읽기 → 과잉공간에 쓰기 → 데이터 지우기 → 쓰기 순으로 진행된다. 이렇게 가비지 수집을 위해 생성되는 I/O 요청을 쓰기 증폭(write amplication)이라 하며, 장치의 쓰기 성능에 큰 영향을 줄 수 있다.
오류 감지 및 수정
•
패리티는 체크섬의 한 형태로 고정 길이 워드 값을 계산 및 저장하고 비교하여 나머지 연산을 수행하는데, 메모리 시스템은 이런 패리티 검사를 통해 오류 감지를 해왔다.
•
다른 오류 감지 방법으로는 해시 함수를 사용해 다중 비트 오류를 감지하는 순환 중복 검사(CRC, cyclic redundancy check)이 있고, 문제를 감지하고 보정까지 하는 오류 수정 코드(ECC, error-correction code)도 있다.
•
오류의 종류로는 오류가 발생했을 때 복구가 가능한 소프트 오류와 수정할 수 없는 하드 오류가 있다.
저장장치 관리
1.
드라이브 포매팅, 파티션, 볼륨
•
저장장치는 데이터를 저장하기 전에 컨트롤러가 읽고 쓸 수 있도록 섹터들로 나누어져 있어야 하고, NVM 페이지를 초기화하고 FTL이 생성되어있어야 한다. 이 과정을 저수준 포매팅(low-level formatting) 혹은 물리적 포매팅이라 부른다.
•
대부분 하드디스크는 공장에서 저수준 포매팅이 되어 나오는데, 드라이브를 사용하여 파일을 저장하려면 운영체제가 세 단계를 통해 데이터 구조를 장치에 기록한다.
◦
먼저 장치를 하나 이상의 블록이나 페이지 그룹으로 파티셔닝한다. 운영체제는 각 파티션을 별도의 장치처럼 사용할 수 있고 이 과정에서 파일 시스템을 마운트한다.
◦
두 번째 단계는 볼륨을 생성하고 관리하는 작업이다.
◦
마지막 단계는 운영체제가 가용 공간과 할당된 공간의 맵과 초기 빈 디렉터리를 초기화하는 논리적 포매팅 또는 파일 시스템 생성이다.
•
효율성을 높이기 위해 대부분의 파일 시스템은 클러스터라는 더 큰 청크로 묶어 작업을 수행한다. 클러스터를 사용하면 I/O가 순차 접근을 더 많이하고 랜덤 액세스 특성을 줄이기 때문에 더 효율적으로 사용할 수 있다.
•
일부 운영체제는 파일 시스템 자료구조 없이도 파티션을 논리 블록의 대용량 순차 배열처럼 사용할 수 있게 해준다. 이 배열을 raw 디스크라고 하며, 이 배열에 대한 I/O를 raw I/O라 한다.
2.
부트 블록
•
초기 부트스트랩 로더는 시스템 마더보드의 NVM 플래시 메모리 펌웨어에 저장되어 예약된 메모리 위치에 매핑된다. 부트로더를 통해 CPU 레지스터에서 장치 컨트롤러 및 메인 메모리까지 시스템의 모든 측면을 초기화한다.
•
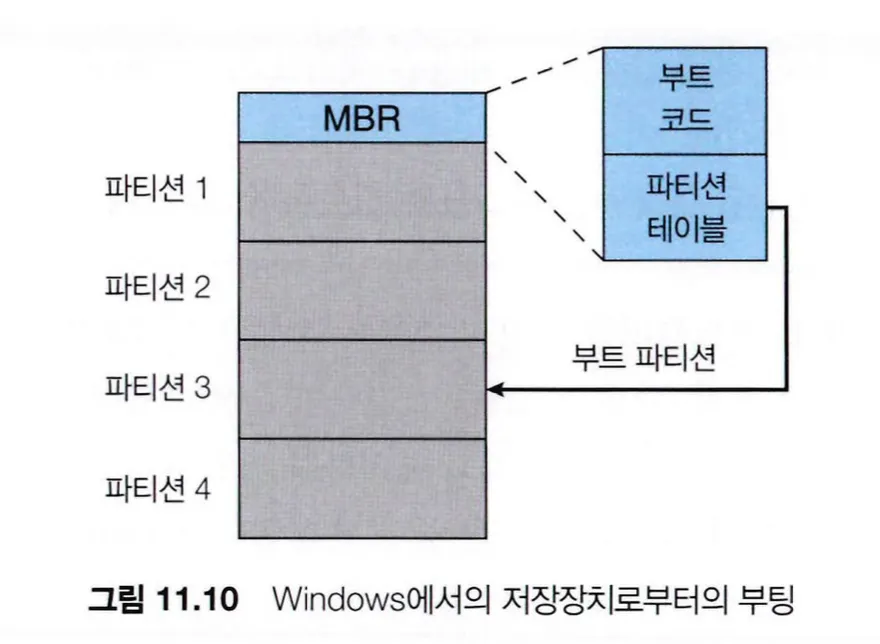
부트스트랩 로더 프로그램은 장치의 고정된 위치에 있는 부트 블록에 저장되는데, 이 부트 파티션이 있는 장치를 부트 디스크 또는 시스템 디스크라고 한다.
•
Windows 시스템은 부트 코드를 NVM 장치의 첫 번째 페이지인 마스터 부트 레코드(MBR)에 배치한다.
3.
손상된 블록(Bad Blocks)
•
디스크는 부품들이 움직이고 매우 정밀한 장치이므로 쉽게 고장이 발생하는데, 고장이 심해서 디스크 전체를 교체해야 할 때도 있으나 보통 한두 개 섹터에 결함이 발생한다.
•
디스크는 손상된 디스크 블록을 손상 블록 리스트를 만들어두고 예비 섹터 중 하나를 손상된 섹터와 교체 시켜 운영체제에서는 전혀 모르게 사용한다. 이러한 기법은 섹터 예비(sector sparing) 혹은 섹터 포워딩(sector forwarding)이라 한다.
•
이렇게 컨트롤러에 의해 재배치를 통해 손상 블록을 관리하면 디스크 스케줄링 알고리즘에 의한 최적화가 무산될 수 있는데, 일부 디스크들을 포매팅할 때 예비 섹터를 실린더마다 배치하고 예비 실린더도 배치하고 섹터가 손상되면 실린더에서 예비 섹터를 찾는 식으로 해결할 수 있다.
•
예비 섹터를 관리하는 다른 방안으로 손상 블록이 있는 섹터부터 예비 섹터까지 모든 섹터를 재매핑하여 손상 섹터를 처리하는 섹터 밀어내기(sector slipping) 방식이 있다.
•
에러의 종류로는 블록 데이터를 복사하여 스페어 또는 슬립하여 복구 가능한 소프트 에러와 데이터를 잃어버리는 하드 에러가 있다.
스왑 공간 관리
1.
스왑 공간 사용
•
시스템을 운영하다 스왑 공간이 부족하면 프로세스들을 도중에 중단 시켜야하고 최악의 경우에는 시스템 전체가 crash 될 수 있기 때문에, 스왑 공간은 예상보다 크게 잡는 것이 안전하다.
•
스왑 공간이 너무 크면 파일을 위한 공간이 부족해질 수 있기 때문에, 일부 운영체제에서는 권장하는 예약 스왑 공간 크기가 있다.
2.
스왑 공간 위치
•
스왑 공간은 일반 파일 시스템이 차지고 있는 공간에 만들 수도 있고 별도의 파티션을 만들어 사용할 수도 있다.
•
스왑 공간을 별도의 raw 파티션에 만들어 사용하면, 일반 파일이나 디렉터리는 해당 파티션에는 저장되지 않고 스왑 관리 루틴에 의해 스와핑을 하는데만 사용된다.
저장장치 연결
a.
호스트 연결 저장장치
•
•
호스트 연결 저장장치는 로컬 I/O 포트를 통해 액세스 되는 저장장치로, 이 포트들은 SATA와 같은 몇가지 기술을 사용한다.
•
고성능 워크스테이션과 서버는 더 많은 저장장치를 사용해야하거나 저장장치들을 공유해야하므로 광섬유 채널(FC, fire channel)과 같은 정교한 I/O 아키텍처를 사용한다.
b.
네트워크 연결 저장장치
•
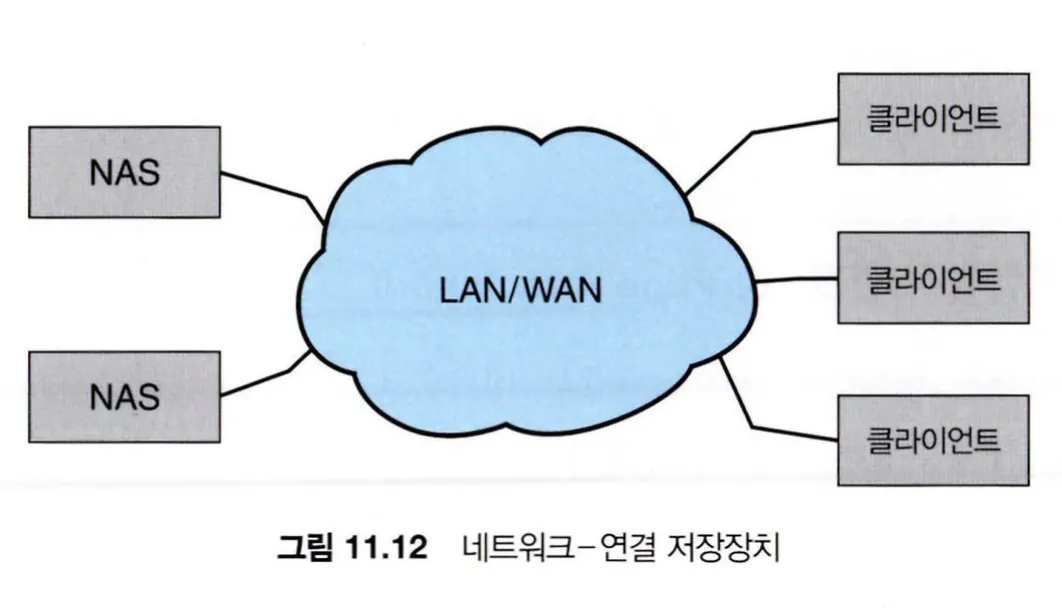
NAS(network-attached storage)는 네트워크를 통해 저장장치에 대한 액세스를 제공하고, NAS 장치는 특수 목적 저장장치 시스템이거나 네트워크의 다른 호스트에 저장장치를 제공하는 일반 컴퓨터일 수 있다.
•
클라이언트는 원격 프로시저 호출 인터페이스를 통해 NAS에 액세스하고, RPC(원격 프로시저 호출)는 IP 네트워크상에서 TCP 또는 UDP를 통해 전달된다.
•
네트워크 연결 저장장치는 일반적으로 RPC 인터페이스를 구현하는 소프트웨어를 사용하여 저장장치 배열로 구현된다.
c.
클라우드 저장장치
•
클라우드 저장장치는 네트워크 연결 저장장치와 유사하게 네트워크를 통해 저장장치에 액세스할 수 있는데, NAS와 달리 이 저장장치를 제공하는 원격 데이터 센터에 인터넷 또는 WAN을 통해 접속하여 액세스된다.
•
NAS는 CIFS나 NFS 프로토콜을 사용하면 파일 시스템처럼 접근되고, iSCSI 프로토콜을 사용하면 raw 블록 장치로 접근된다. 반면 클라우드 저장장치는 API 기반이며 프로그램은 API를 통해 저장장치에 접근한다.
d.
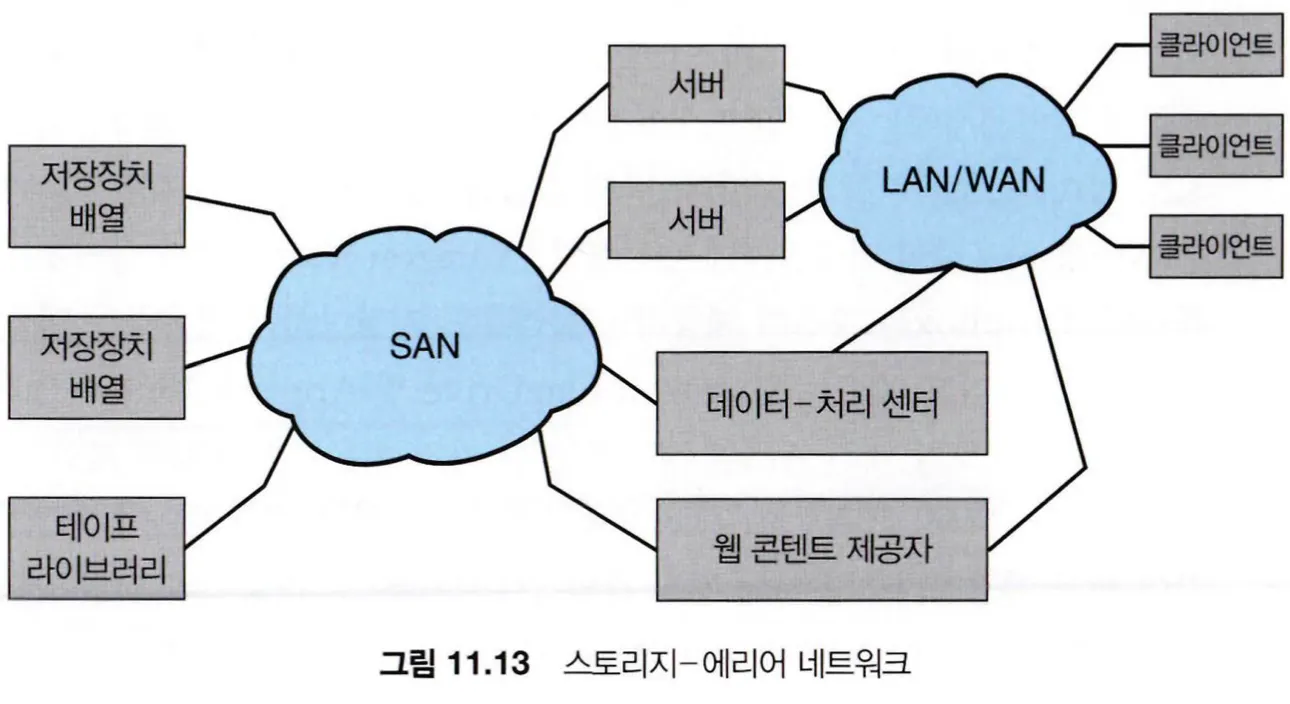
SAN과 저장장치 배열
•
SAN(storage-Area Network)은 서버들과 저장장치 유닛들을 연결하는 사유 네트워크를 말하는데, 여러 호스트와 저장장치를 SAN에 부착할 수 있고 저장장치를 동적으로 호스트 할당할 수 있기 때문에 유연하다.
•
SAN을 사용하면 서버의 클러스터가 동일한 저장장치를 공유할 수 있게도 하고 저장장치 배열이 여러 호스트를 직접 연결할 수 있게 한다.
•
SAN은 저장장치 배열보다 많은 포트를 가지고 있기 때문에 비용이 많이 든다.
•
데이터를 저장하는 드라이브와 저장장치를 관리하고 네트워크를 통해 저장장치에 액세스 할 수 있는 컨트롤러를 포함하는데, 컨트롤러는 CPU, 메모리 및 배열의 기능을 구현하는 소프트웨어로 구성된다.
•
InfiniBand(IB)라고 하는 특수 목적의 버스 아키텍처를 통해 내부 연결 구조를 구성하고, 서버들과 스토리지 유닛을 연결하는 고속의 내부 연결망을 만든다.
RAID 구조
•
저장장치의 소형화와 가격이 저렴해지면서 다수의 드라이브를 부착하는게 보편화되고, 다수의 드라이브에서 병렬적으로 운영하여 데이터 읽기, 쓰기 비율을 향상시킬 수 있다.
•
RAID(redundant array of inexpensive disk)라 불리는 다양한 디스크 구성 기술을 통해 다수의 드라이버에 데이터의 중복 저장이나 데이터의 분실없이 성능과 신뢰성을 높인다.
1.
중복으로 신뢰성 향상
•
여러 개의 디스크로 구성된 세트에서 오류가 발생할 확률은 하나의 디스크에서 오류가 발생할 확률보다 훨씬 크다. 하나의 디스크의 고장 사이의 평균 시간(MTBF, mean time between failure)가 t이라면 n개의 디스크 일 때 MTBF는 t/n으로 훨씬 자주 발생할 것이다.
•
이러한 신뢰성 문제는 중복을 허용하여 해결할 수 있다. 오류의 경우마다 사용되는 별도의 정보를 저장해두어 디스크 오류 발생 시 데이터를 손실하지 않을 수 있다.
•
가장 간단한 방법은 미러링(mirroring)으로 모든 드라이브의 복사본을 만들어 두는 것이다. 논리 디스크를 두 개의 물리 드라이브로 구성하여 모든 쓰기 작업을 두 드라이브에서 모두 실행하여 미러드 볼륨을 생성한다.
•
미러드 볼륨의 MTBF은 단일 드라이브의 MTBF와 손상된 드라이브를 교체하고 다시 저장하는데 소요되는 평균 수리 시간에 좌우된다.
•
미러링은 물리 디스크를 두 배 사용하게 되어 비용이 많이 들고, 전원 결함이나 두 개의 드라이브에 손상을 줄 수 있는 자연재해 같은 경우에는 대비하지 못한다.
2.
병렬성을 이용한 성능 향상
•
여러 드라이브를 사용할 경우 데이터 스트라이핑(data striping)을 사용하여 전송 비율을 향상 시킬 수 있다.
•
가장 간단한 방법으로, 여러 드라이브에 각 바이트의 비트를 나누어 저장하는 데이터 스트라이핑이 있는데 이를 비트 레벨 스트라이핑(bit-level striping)이라 부른다.
•
다른 방법으로 블록 단위 스트라이핑이 있는데, 파일 블록을 여러 드라이브에 스트라이핑 하는 방법이다.
•
디스크의 병렬성을 사용하면 부하 균등화를 통해 여러 작은 액세스의 처리량을 높이고, 규모가 큰 액세스의 응답 시간을 줄일 수 있다.
3.
RAID 레벨
•
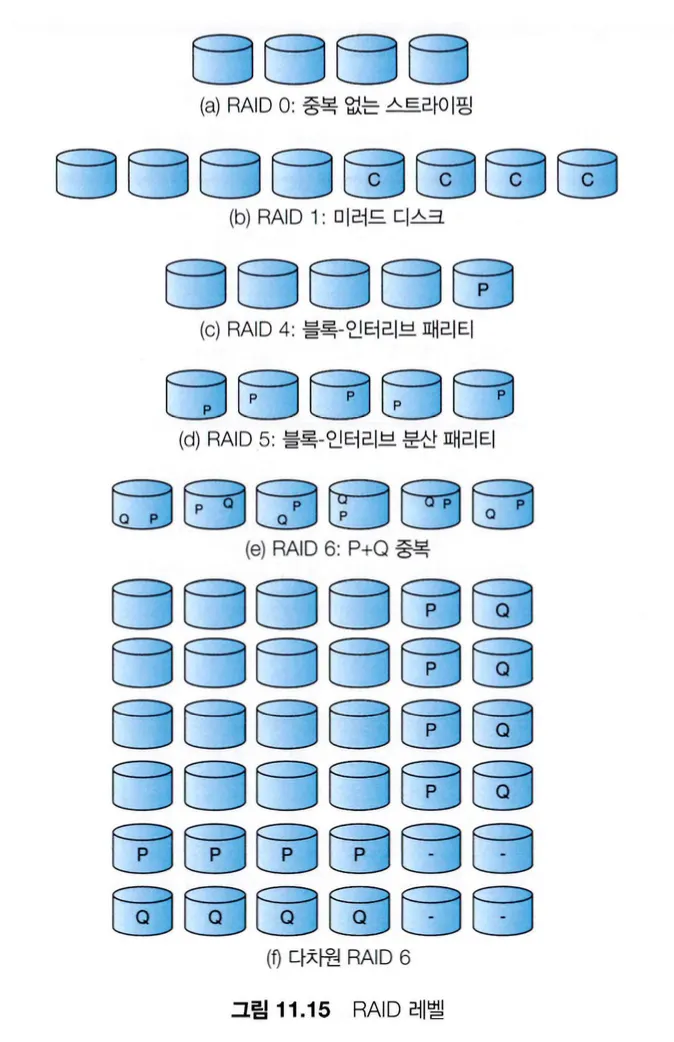
스트라이핑은 높은 전송률을 제공해주지만 신뢰성을 높일 수는 없는데, 패리티 비트와 디스크 스트라이핑을 결합하여 적은 비용으로 중복을 허용하여 신뢰성을 높이는 여러 기법들이 있다. 각 기법마다 가격 대비 성능비가 다른데, 이를 RAID 레벨을 통해 분류한다.
•
RAID level 0
◦
RAID 레벨 0은 블록 레벨로 스트라이핑 하는 드라이브 구성을 말하며, 미러링이나 패리티 비트 같은 어떤 중복 정보도 가지고 있지 않는다.
•
RAID level 1
◦
RAID 레벨 1은 드라이브 미러링을 사용하는 드라이브 구성이다.
•
RAID level 4
◦
RAID 레벨 4는 데이터 블록을 각각의 드라이브에 저장하고 해당 블록들의 오류 수정 계산 결과를 별도의 드라이브에 저장하는 오류 수정 코드(ECC) 방식을 사용하는 드라이브 구성이다. 메모리-스타일 오류 수정 코드(ECC) 구성이라고도 한다.
◦
드라이브 중 하나에 오류가 발생하면 오류 수정 코드를 다시 계산하여 이를 감지하고 오류를 발생시킨다. ECC 블록이 하나만 있어도 RAID 4에서는 오류를 수정할 수 있다.
◦
운영체제가 블록보다 작은 데이터를 쓰려면, 블록을 읽고 새 데이터로 수정한 후 다시 써야하는데 이를 읽기-수정-쓰기 주기라고 부른다. 이렇게 한 번 쓰려면 드라이브에 4번 액세스해야한다.
◦
XOR 패리티 계산과 기록을 하기 때문에 오버헤드로 발생한다.
•
RAID level 5
◦
RAID 레벨 5는 block-interleaved distributed parity라고 불리기도 하는데, N개의 드라이브에 데이터를 저장하고 하나의 드라이브에 패리티를 저장하는 RAID 4와 달리 패리티를 N+1 개의 드라이브 모두에 분산시켜 저장한다.
◦
하나의 드라이브 오류가 데이터 및 패리티의 분실을 동시에 야기하기 대문에 한 블록과 그 블록의 패리티 블록을 같이 저장할 수 없다.
◦
RAID 5는 RAID 4에서의 과도한 패리티 집중을 막을 수 있다.
•
RAID level 6
◦
RAID 레벨 6은 P+Q 중복 기법이라고도 불리는데, RAID 5와 유사하지만 여러 디스크 오류를 대비하여 추가의 중복 정보를 저장한다.
◦
패리티 비트를 사용하는 대신에 Galois field 수학과 같은 에러 교정 코드가 Q를 계산하는데 사용된다.
•
다차원 RAID level 6
◦
다차원 RAID 레벨 6은 드라이브를 행과 열(차원 이상의 배열)로 논리적으로 정렬하고 행을 따라 수평으로 열을 따라 수직으로 RAID 6을 구현한다.
•
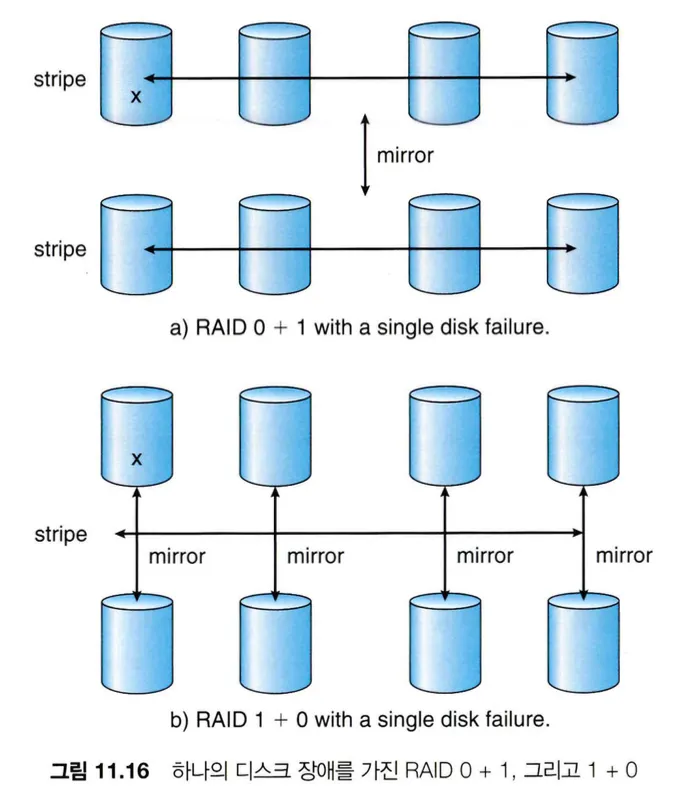
RAID level 0 + 1 / 1 + 0
◦
RAID 0과 RAID 1을 조합하여 사용하는 방법으로, RAID 1이 높은 신뢰성을 제공한다면 RAID 0이 높은 성능을 제공하기 때문에 이를 결합하여 사용한다.
◦
일반적으로 RAID 5보다 높은 성능을 제공하여 성능과 신뢰성 둘 다 중요한 환경에서 사용된다.
◦
드라이브 수가 2배가 필요하기 때문에 구축 비용이 많이 든다.
◦
RAID level 0 + 1
▪
드라이브 세트를 스트라이프하고, 그 스트라이프를 미러링한다.
◦
RAID level 1 + 0
▪
드라이브를 쌍으로 미러링 후 스트라이프 되는 방식이다.
•
마지막 갱신이 일어나기 전 파일 시스템의 모습을 저장한 스냅숏(snapshot)이나 중복성과 복구를 위해 분리된 지역에 같은 내용을 자동으로 쓰는 복제(replication) 역시 이 계층에서 구현될 수 있다.
•
복제는 주기적으로 써야할 묶음을 만들어 복제하는 비동기적 복제와 쓰기가 완료되었다고 판단되기 전에 로컬과 원격 영역에 복제하는 동기적 복제가 있다.
•
스냅숏이나 복제 같은 구현은 RAID가 구현된 계층에 의해 달라지는데, RAID가 소프트웨어적으로 구현되었다면 각 호스트가 자신의 복제본을 만들고 관리해야하고 SAN에 구현되었다면 호스트의 운영체제나 특성에 관계없이 호스트의 데이터가 복제될 수 있다.
•
RAID는 데이터를 저장하지 않고 다른 드라이브의 오류 시 교체하는 역할을 하는 여분 드라이브(hot spare drives)로 구현된다.
4.
RAID 레벨 선택
•
RAID 레벨 선택을 위한 고려사항 중 하나는 복구 능력이다. RAID 1의 복구는 간단하지만 RAID 5의 복구는 몇 시간이 소요된다.
•
RAID 0은 데이터 손실이 중요하지 않은 고성능 응용 프로그램에 사용된다.
•
RAID 1은 빠른 복구를 통한 높은 안정성이 필요한 응용 프로그램에 사용된다.
•
RAID 0+1과 1+0은 소규모 데이터베이스와 같이 성능과 안정성 모두 중요한 경우에 사용한다.
•
RAID 5의 경우에는 보통의 양의 데이터를 저장되는데 선호된다.
•
RAID 6 및 다차원 RAID 6은 저장장치 배열에서 가장 일반적인 형태로, 큰 공간적 오버헤드 없이 우수한 성능과 보호 기능을 제공한다.
5.
RAID의 문제점들
•
RAID는 파일에 대한 포인터나 파일 구조 내에 있는 포인터들이 잘못 되는 경우처럼, 운영체제나 사용자를 위해 데이터의 사용을 보장하지 않는 문제가 있다.
•
물리적 매체의 오류는 보호할 수 있지만, 다른 하드웨어나 소프트웨어 오류는 보호하지 못한다.
6.
객체 저장소
•
데이터 저장장치에 접근하는 또 다른 방법으로는, 저장장치 풀에 객체를 배치하는 방법이 있다. 저장장치 풀에 객체를 생성하고 객체 ID를 받아, 필요할 때 객체 ID를 통해 객체에 접근하거나 삭제한다.
•
객체 저장소는 일반적으로 고속 랜덤 액세스가 아니라 대량 저장장치에 사용되고, 고정된 최대 용량이 있지만 용량을 추가하기 위해 컴퓨터에 디스크를 연결하고 풀에 추가하기만 되기 때문에 수평 확장성의 이점이 있다.
•
객체 저장소는 각 객체가 내용에 대한 설명을 포함하기 때문에, 콘텐츠 기반으로 검색 가능하고 그로 인해 주소지정가능 저장소(content-addressable storage)라고도 부른다. 이 때 저장되는 콘텐츠 형식이 설정되지 않았기 때문에 구조화되지 않은 데이터를 저장한다.