
입출력 하드웨어
•
장치 드라이버는 모든 하드웨어를 일관된 인터페이스로 표현해주며, 이러한 인터페이스를 그보다 상위층인 커널의 입출력 서브시스템에 제공해주는 역할을 한다. 이는 시스템 콜이 운영체제와 어플리케이션 사이에서 표준 인터페이스를 제공하는것과 유사하다.
•
하드웨어 장치는 케이블을 통하거나 무선으로 신호를 보냄으로써 컴퓨터 시스템과 통신하는데, 이러한 장치는 포트(port)라 불리는 연결점을 통해 컴퓨터와 접속된다.
•
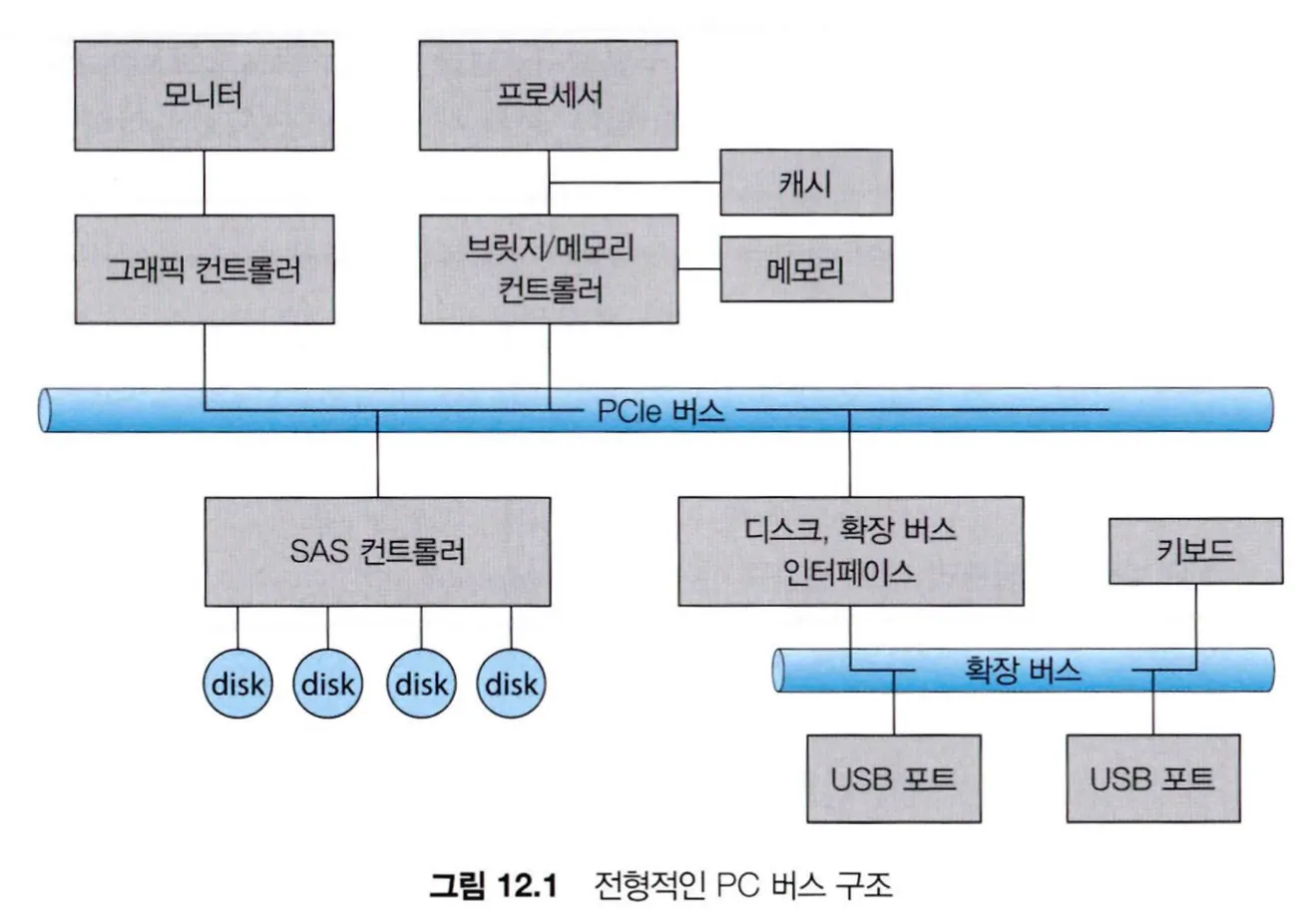
만약 하나 이상의 장치들이 공동으로 여러 선(wire)을 사용한다면, 이러한 선을 버스(bus)라 부른다. PCI 버스처럼 버스의 정의는 회선의 집합으로써 이를 통해 주고받는 메세지의 프로토콜까지를 포함한다.
•
장치 A가 B에 연결되고, B가 C, C가 컴퓨터의 포트까지 연결되어 있다면, 데이지 체인(daisy chain)이라 부른다. 데이지 체인은 통상 하나의 버스처럼 동작한다.
•
버스는 컴퓨터 다양한 종류가 있는데, PCI 버스(일반적인 PC system bus)가 프로세서-메모리 서브 시스템을 고속 장치와 느린 장치들(키보드, USB 포트 등)을 연결하는 확장 버스(expansion bus)에 연결한다.
•
또한 여러 디스크들을 SAS 컨트롤러를 통해 직렬연결 SCSI(SAS) 버스에 연결한다.
•
PCIe는 하나 이상의 레인(lane)을 통해 데이터를 전송하는 유연한 버스인데, 레인은 수신용과 전송용 두 개의 신호 쌍으로 구성된다. 따라서 각 레인은 4개의 선으로 구성되어 전이중 바이트 스트림으로 8-비트 바이트 형식의 데이터 패킷을 전송한다.
•
컨트롤러는 포트와 버스, 장치를 작동할 수 있는 전자장치의 집합체이다.
◦
직렬 포트 컨트롤러는 간단한 장치 컨트롤러로, 직렬 포트의 전선에 나타나는 전기 신호를 제어한다.
◦
광섬유 채널(FC) 버스 컨트롤러는 FC 프로토콜 메시지를 처리할 수 있는 프로세서와 전용 메모리를 가진 호스트 버스 어댑터(HBA)로 구현된다.
1.
메모리 맵드 입출력
•
프로세서에서 컨트롤러가 가지고 있는 레지스터에 비트 패턴을 쓰거나 읽어서 입출력을 수행한다.
•
프로세서에서 레지스터에 비트를 쓰는 방법 중 하나로 장치 제어 레지스터를 프로세서의 주소 공간으로 매핑하는 방법이 메모리 맵드 입출력(memory-mapped I/O) 방식이다.
•
각 주변 장치 레지스터들을 메모리 주소와 일대일 대응하여, CPU가 물리 메모리에 매핑된 장치-제어 레지스터를 읽거나 써서 표준 데이터 전송 명령을 사용하여 입출력 요청을 수행한다.

•
입출력 장치 컨트롤러는 보통 네 개의 레지터로 구성되어 있는데, 상태(status)와 제어(control), 입력(data-in), 출력(data-out) 레지스터들이다.
◦
입력 레지스터 : 호스트가 입력을 얻기 위해 읽기를 수행
◦
출력 레지스터 : 호스트가 데이터를 출력하기 위해 쓰기를 수행
◦
상태 레지스터 : 호스트가 읽는 용도로, 명령 완료 여부나 입력 레지스터를 읽어도 되는지, 오류가 있었는가 같은 상태를 표현
◦
제어 레지스터 : 호스트가 주변 장치에 입출력 명령을 내리거나 장치의 모드를 변경하기 위해 쓰기를 수행하는 대상
2.
폴링
•
호스트와 입출력 하드웨어 사이의 프로토콜의 기본 핸드셰이킹(hand-shaking) 개념은, 컨트롤러가 상태 레지스터를 통해 자신의 상태를 나타내 다음 명령을 받을 준비가 되었는가를 알리고 호스트는 레지스터의 명령 준비 완료 비트(command-ready bit)를 통해 입출력이 필요하다는 상태를 알려준다. 호스트와 컨트롤러는 이 두 비트를 통해 연결 후 포트를 통해 입출력을 처리한다.
•
자세한 절차는 아래와 같다.
◦
호스트에서 반복적으로 비지 비트를 검사하여 명령을 받을 준비가 되었는지 확인한다.
◦
호스트가 명령 레지스터에 쓰기 비트를 설정하고 출력 레지스터에 출력할 바이트를 쓴다.
◦
호스트가 명령 준비 완료 비트(command-ready bit)를 설정한다.
◦
컨트롤러에서 명령 준비 완료 비트를 읽고, 자신의 비지 비트를 설정한다.
◦
컨트롤러는 명령 레지스터를 확인해 읽기인지 쓰기인지 확인하고, 출력 레지스터를 읽어 해당 바이트를 가져와 하드웨어 장치로 출력한다.
◦
명령 준비 비트를 0으로 소거하고 입출력이 성공했음을 알리기 위해 상태 레지스터의 오류 비트도 0으로 소거한다. 또한 비지 비트를 0으로 소거하여 입출력이 끝났음을 알린다.
•
위의 1 단계에서 호스트는 busy-waiting 상태로 대기하는데, 루프를 계속 돌며 비지 비트가 소거될 때까지 검사를 반복하며 폴링(polling)한다.
•
폴링은 CPU를 낭비하는 동작이지만, 만약 다른 테스크를 처리하게 넘겨버리면 직렬 포트나 키보드로부터 데이터가 계속 들어오는 상황에서 버퍼 오버플로우가 발생에 데이터 유실이 발생할 수 있다. 이를 개선하기 위한 기법이 컨트롤러가 자신의 상태가 바뀔 때 CPU에게 자신의 상태 변화를 알려주는 하드웨어 기법을 인터럽트(interrupt)라고 한다.
3.
인터럽트
•
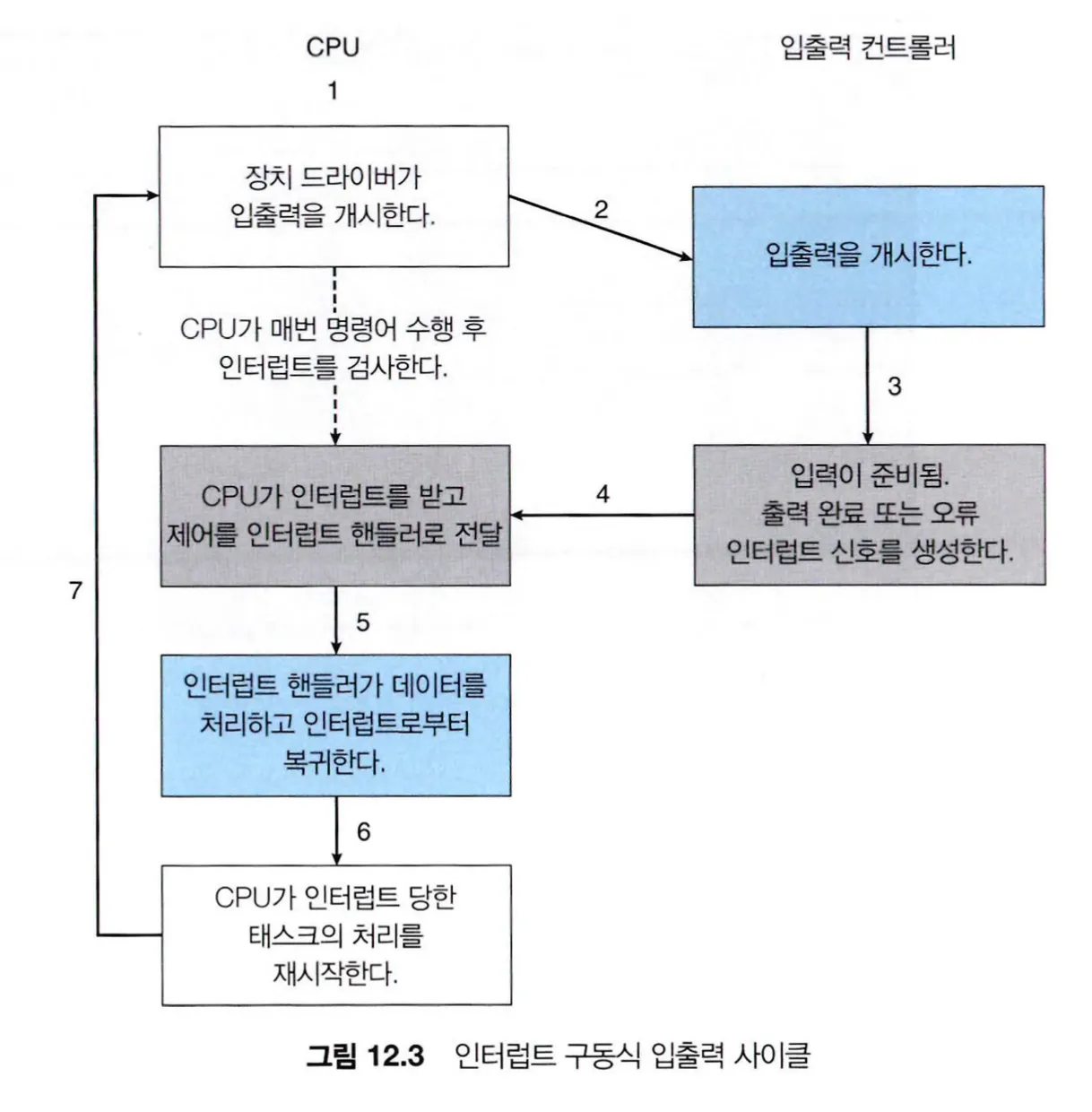
CPU 하드웨어는 인터럽트 요청 라인(interrupt request line)이라는 선을 가지고, 매 명령어를 끝내고 다음 명령어를 수행하기 전에 이 선을 검사한다.
•
입출력 하드웨어 컨트롤러가 이 요청 라인에 신호를 보내면 CPU가 알아차리고 각종 레지스터 값과 상태 정보를 저장한 후, 메모리 상의 인터럽트 핸들러 루틴으로 점프한다.
•
인터럽트 핸들러 루틴의 작업을 수행한 후 CPU를 인터럽트 전의 실행 상태로 되돌리기 위해 복귀 명령(return from interrupt)을 실행한다.
•
대부분의 CPU는 회복 불가능한 메모리 오류와 같은 이벤트에 사용되는 마스크 불가 인터럽트와 인터럽트 기능을 잠시 중단 시켜놓을 수 있는 마스크 가능 인터럽트로 두 종류의 인터럽트 요청 라인을 가진다.
•
인터럽트 기법은 보통 주소라고 불리는 정수값을 통해 특정 인터럽트 핸들링 루틴을 선택한다. 대부분의 아키텍처 이 주소는 인터럽트 벡터라고 불리는 테이블의 오프셋으로 사용되고, 인터럽트 벡터는 인터럽트 핸들링 서비스의 메모리 주소들을 가지고 있다.
•
컴퓨터는 인터럽트 벡터 내의 주소들보다 더 많은 장치들을 가지고 있는데, 인터럽트 사슬화(chaining) 기술을 사용하여 해결한다.
•
인터럽트 기법은 CPU가 자동으로 높은 우선순위 인터럽트가 낮은 우선수위의 인터럽트를 선점할 수 있게 하여, 인터럽트 우선순위 수준(interrupt priority levels)을 구현할 수 있도록 한다.
•
운영체제 인터럽트를 사용하여 여러가지 예외(exceptions)를 처리하기도 하는데, divide-by-zero나 액세스 해서는 안되는 메모리에 액세스하거나 사용자 모드에서 특권 명령을 수행하려 했을 때와 같은 예외 상황들이 인터럽트를 통해 예외 처리된다.
•
대부분 인터럽트 처리는 시간과 자원이 제한되어있어 구현이 복잡하기 때문에, 시스템은 1차 인터럽트 처리기(FLIH)와 2차 인터럽트 처리기(SLIH)로 나누어 인터럽트를 관리한다.
•
그 외에도 페이지 폴트나 시스템 콜에서도 인터럽트가 사용된다. 시스템 콜을 호출하면 라이브러리 루틴을 호출하는데, 그 과정에서 소프트웨어 인터럽트(software interrupt) 또는 트랩(trap)이라 부르는 특수한 명령어를 수행한다.
•
인터럽트는 모든 시스템에서 비동기적(asynchronous)으로 일어나는 이벤트를 처리하고, 커널 내의 수퍼바이저 루틴(supervisor routine)을 수행하기 위한 방도로 사용된다.
4.
직접 메모리 접근
•
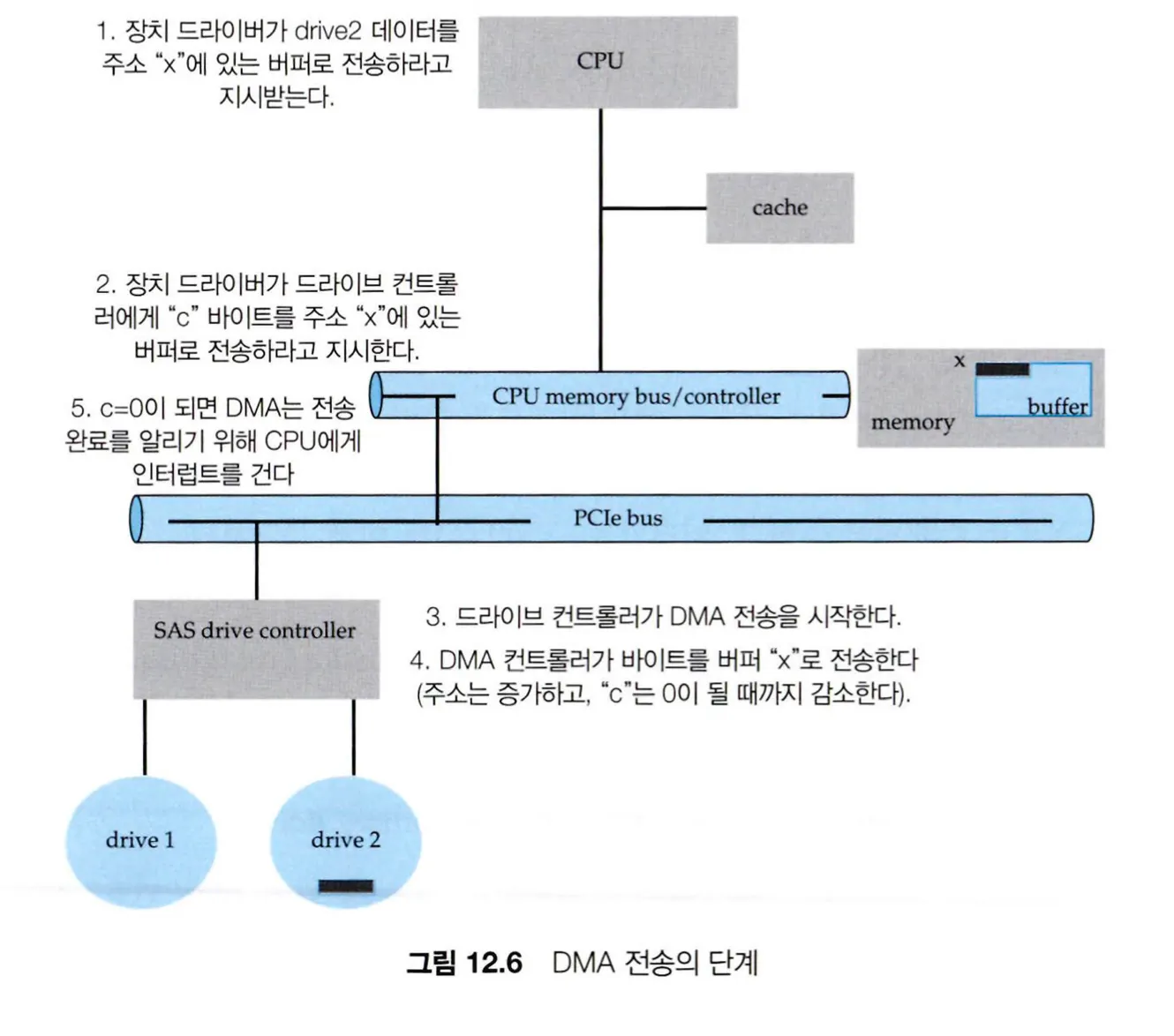
CPU가 상태 비트를 반복적으로 검사하면서 1바이트씩 옮기는 입출력 방식을 PIO(Programmed I/O)라고 부르는데, CPU는 PIO의 작업 일부를 DMA(Direct Memory Access) 컨트롤러에 위임하여 처리한다.
•
DMA 전송을 위해 호스트가 메모리에 전송할 데이터의 위치, 전송할 위치, 전송할 바이트 수 등의 정보를 DMA 명령 블록에 쓴다. DMA 명령 블록의 주소를 DMA에게 알려주어, DMA가 CPU 도움 없이 직접 버스를 통해 DMA 명령 블록에 액세스하여 입출력을 수행한다. 이 기법을 분산-수집(scatter-gather) 방법이라 한다.
•
대상 주소가 커널 주소 공간에 있는 경우에는 간단하지만, 사용자 주소 공간에 있다면 내용이 수정되거나 내용의 일부를 잃어버릴 수 있다. 하지만 DMA로 전송된 데이터를 스레드가 액세스할 수 있게 하려면 커널 메모리에서 사용자 메모리로 복사를 한 번 더 거치는 불필요한 이중 버퍼링 작업이 필요하다. 이를 해결하기 위해 메모리 매핑 방법을 사용한다.
•
DMA 컨트롤러와 장치 컨트롤러의 핸드셰이킹은 DMA-request와 DMA-acknowledge라고 불리는 두 개의 선을 통해 수행된다. 장치 컨트롤러가 DMA-request를 통해 전송할 자료가 있음을 알리고, DMA 컨트롤러가 DMA-acknowledge 선을 통해 응답하여 데이터를 메모리로 전송해도 됨을 알린다.
•
전송이 완전히 끝나면 DMA 컨트롤러가 CPU에 인터럽트를 거는데, DMA가 메모리 버스를 점유 중이면 CPU는 캐시에 있는 데이터는 접근할 수 있지만 메모리에 있는 데이터는 접근할 수 없다. 이런 사이클 스틸링(cycle stealing)은 CPU의 속도를 저하하지만 전체적으로는 성능이 향상된다.
•
어떠한 컴퓨터들은 DMA를 할 때 물리 주소가 아닌 직접 가상 주소 접근(DVMA, direct virtual-memory access)을 사용하기도 한다.
어플리케이션 입출력 인터페이스
•
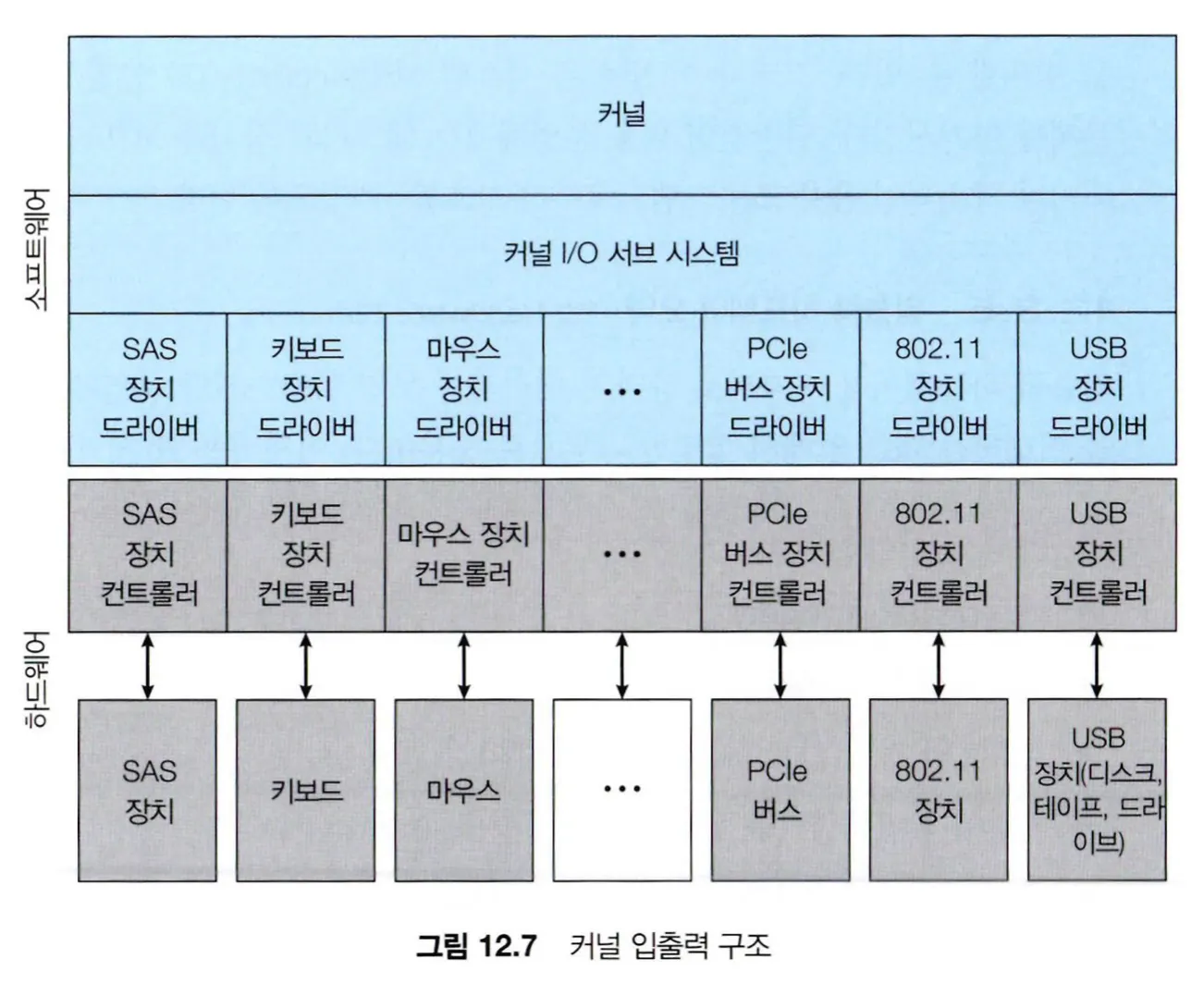
모든 입출력 장치들이 일관된 방법으로 운영체제에서 다뤄질 수 있도록, 추상화와 캡슐화, 소프트웨어 계층화(layering)을 사용하여 인터페이스를 구성한 것이 어플리케이션 입출력 인터페이스이다.
•
장치 드라이버라 불리는 커널 내의 모듈들은 각 입출력 장치들을 추상화하여 인터페이스의 표준 함수들을 내부적으로 수행한다. 이 장치 드라이버 계층(layer)은 여러 입출력 하드웨어 간의 차이를 숨기고 간단한 표준 인터페이스로 보이도록 포장해서 상위의 커널 입출력 서브 시스템에 제공하는 역할을 한다.
•
문제는 운영체제마다 장치 드라이버 인터페이스에 대한 규격이 다르기 때문에, 새로운 장치가 Windows나 Linux, macOS에 대한 드라이버와 같은 여러 장치 드라이버와 함께 제공되어야 한다는 것이다.

•
대부분 운영체제는 응용 프로그램이 입출력 장치로 임의의 명령을 전달하는 ioctl()과 같은 escape(혹은 back-door) 시스템 콜을 가지고 있다.
1.
블록 장치와 문자 장치
•
블록 장치 인터페이스는 디스크나 유사한 블록 지향(block-oriented) 장치를 사용하기 위해 읽기(read)와 쓰기(write), 탐색(seek) 명령을 제공한다.
•
운영체제나 데이터베이스는 블록 지향 장치를 마치 선형 배열로 접근하려 하는데, 이런 접근 모드를 비가공 입출력(raw I/O)이라 불린다.
•
비가공 입출력에서 어플리케이션이 자체 버퍼링을 수행하면 파일 시스템은 불필요하고 중복된 버퍼링을 하게 되고, 파일 블록이나 일부에 대한 자체 잠금(locking) 기능을 제공한다면 중복된 기능에 최악의 경우 모순이 발생할 수 있다.
•
이런 충돌을 막기 위해 비가공 장치(raw device)의 접근을 장치 제어권을 어플리케이션에게 일임하고 운영체제는 빠져있어야 한다. UNIX에서는 이런 방식을 직접 입출력(direct I/O)라고 부른다.
•
메모리 맵드(memory mapped) 파일 접근은 디바이스를 읽거나 쓰는 명령 대신 메모리의 특정 번지를 읽거나 쓰는 명령으로 파일 입출력을 대신하는 방식이다.
•
메모리 맵드 파일 접근은 파일을 가상 메모리로 매핑하고 가상 메모리의 주소를 받아, 파일에 대응되는 메모리가 참조되어야 실제 메모리에 올라온다. 이렇게 메모리 맵 방식을 사용하면 파일 입출력 인터페이스를 사용하지 않고 요구 페이징을 사용하기 때문에 효율적이다.
•
키보드는 문자 스트림(character stream) 인터페이스를 통해 접근되는 장치 중 하나로, 문자 스트림 인터페이스의 시스템 콜은 응용 프로그램에 한 글자씩을 보내거나(put) 받아오는(get) 명령을 제공한다. 라이브러리를 통해 한 줄(line)씩 읽게도 하고, 버퍼링과 편집 기능을 제공할 수도 있다.
2.
네트워크 장치
•
네트워크 입출력을 위해 많은 운영체제에서 사용하는 인터페이스는 네트워크 소켓(socket) 인터페이스로, 소켓 인터페이스에서 시스템 콜은 소켓을 생성하고 원격지 주소와 연결해주고 원격지에서 소켓으로 접속을 완료했는지 확인하고 연결되었다면 패킷을 주고 받을 수 있게 해준다.
3.
클록과 타이머
•
대부분의 컴퓨터는 하드웨어 클록과 타이머를 통해 현재 시간, 지난 시간, T 시각이 되면 X 오퍼레이션을 실행하는 기본적인 기능을 제공한다.
•
지나간 시간을 측정하고 특정 오퍼레이션을 실행시키는 하드웨어를 프로그램 가능 인터벌 타이머(programmable interval timer)라고 부르고, 일정 시간만큼 지나면 인터럽트를 발생 시킬 수 있고 이 과정을 한 번이나 주기적으로 반복해서 발생하도록 설정할 수도 있다.
•
인터벌 타이머 기법은 스케줄러가 타임 슬라이스가 종료되면 현재 실행 중인 프로세스에게서 CPU를 빼앗기 위해 사용되며, 디스크 입출력 서브시스템이 변경된 캐시 버퍼(dirty cache buffer)를 비워내는(flushing)데 사용되고, 네트워크 서브시스템이 네트워크 혼잡(congestion)이나 오류로 인해 특정 작업을 취소하는데에도 사용된다.
•
최신 PC에는 클럭 하드웨어에서 10MHz의 속도로 실행되는 고성능 이벤트 타이머(HPET)가 포함되어 있고, 저장하고 있는 값이 HPET의 값과 같으면 트리거 하도록 설정할 수 있는 비교기가 있다.
•
타이머 틱이 시스템의 time-of-day 클록에 사용되면, 시스템 클록이 부정확해질 수 있는데, 네트워크 시간 프로토콜(NTP)과 같은 프로토콜을 사용하여 부정확성을 보정할 수 있다.
4.
봉쇄형과 비봉쇄형 입출력
•
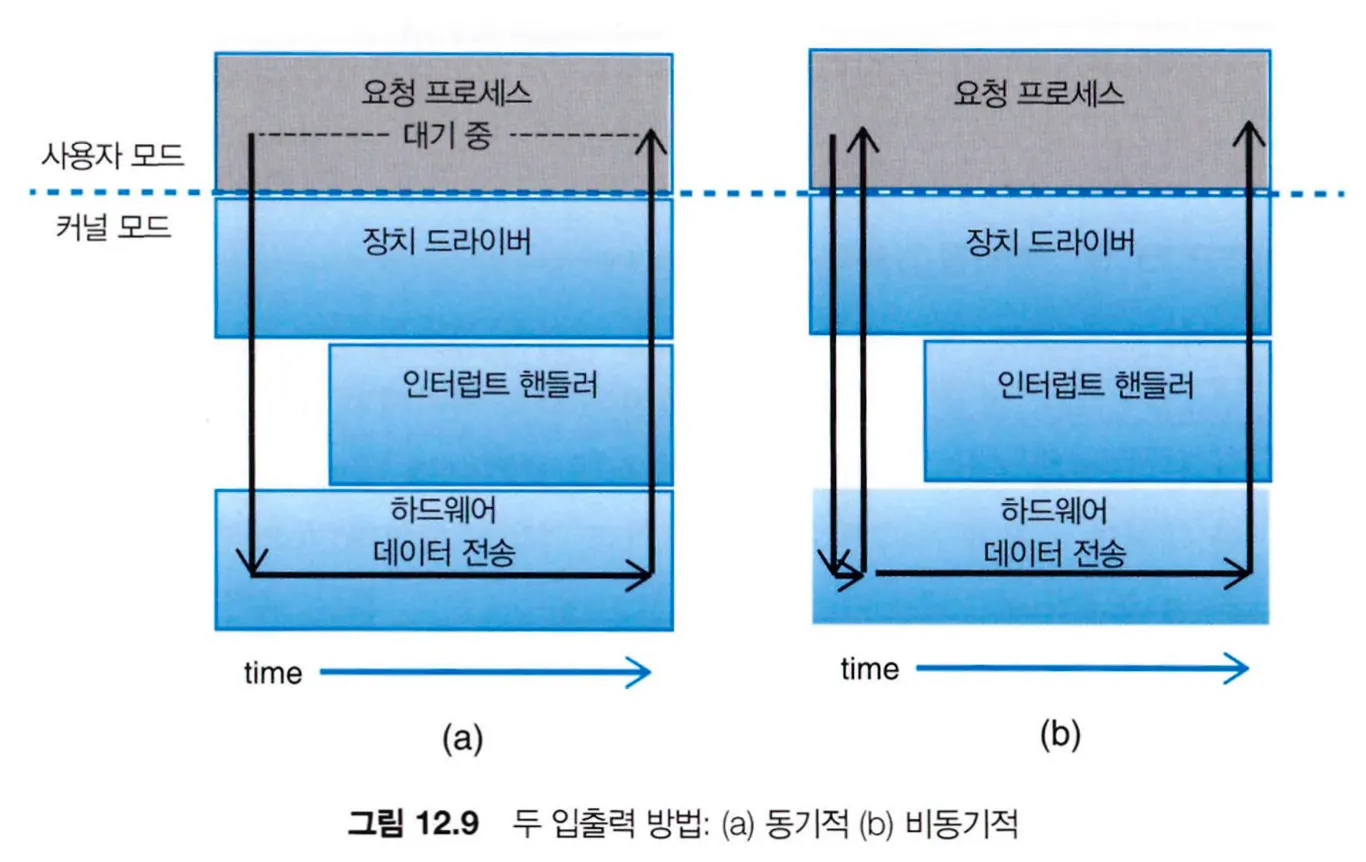
응용 프로그램이 봉쇄형(blocking) 시스템 콜을 하면 호출한 스레드는 block 상태로 들어가 대기 큐로 옮겨진다. 추후 입출력이 끝나면 다시 실행 큐로 돌아와 실행이 재개되고, 프로그램은 입출력 시스템 콜이 되돌려 준 값을 받게 된다.
•
비봉쇄형(nonblocking) 입출력을 시스템 콜을 호출하고 즉각 복귀하여 다른 일을 처리할 수 있도록 한다. 연산하는 도중에 키보드와 마우스 입력을 받거나, 디스크에서 비디오 파일을 읽어오면서 다른 쪽에서는 비디오 파일의 내용을 스크린에 출력하는 일을 하는 것과 같이 구현될 수 있다.
•
비봉쇄형 시스템 콜의 대안으로 비동기식 시스템 콜이 있다. 비동기식 호출도 호출 후 즉각 복귀하여 자신의 코드를 계속 수행하지만, 입출력이 완료되면 운영체제가 입출력이 완료되었다는 사실을 스레드에 변수를 셋팅하거나 시그널을 보내거나 소프트웨어 인터럽트나 별도의 콜백 루틴을 수행하여 끝났음을 알려준다.
5.
벡터형 입출력
•
벡터형 입출력은 하나의 시스템 콜을 호출하여 여러 위치에 있는 입출력 연산을 수행할 수 있게 한다. 동일한 전송은 시스템 콜을 여러 번 호출하여 수행할 수 있지만, 문맥 교환과 시스템 콜 오버헤드를 줄일 수 있고 스레드 간 버퍼 공유로 인한 데이터 오염을 피할 수 있어 이러한 분산-수집 방식이 유용하다.
커널 입출력 서브시스템
1.
I/O 스케줄링
•
운영체제에서 장치마다 대기 큐를 유지하여 스케줄링을 구현하는데, 응용 프로그램이 봉쇄형 입출력 시스템 콜을 하면 그 입출력 요청은 해당 장치의 대기 큐에 들어간다. 입출력 스케줄러는 큐 안의 순서를 재배치하여 시스템 성능과 응용 프로그램의 평균 응답 시간을 개선한다.
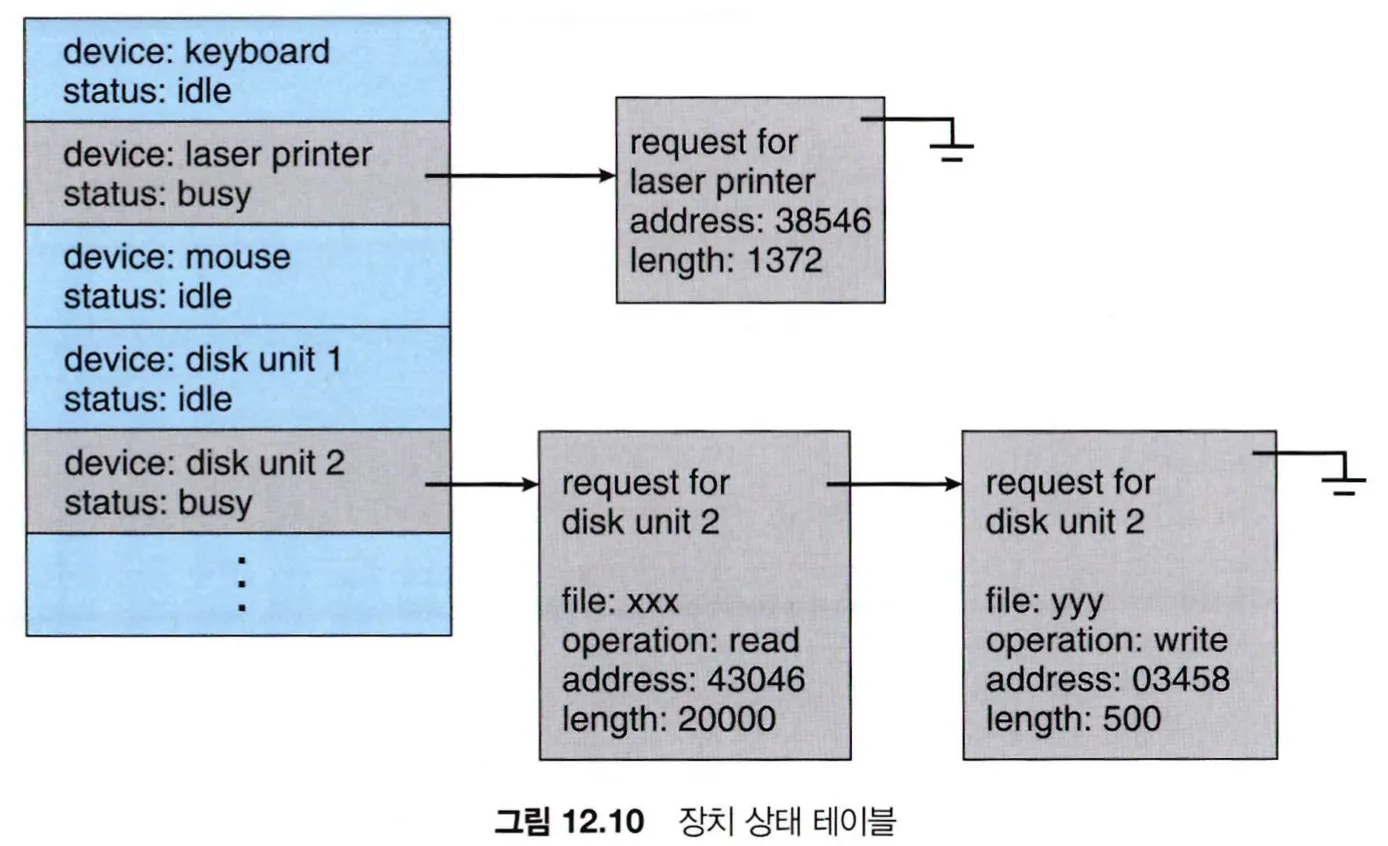
•
커널이 비동기적 입출력을 제공한다면 커널은 동시에 많은 입출력 요청을 추적해야하고, 이를 위해 운영체제는 각 장치 상태 테이블(device-status table)에 대기 큐를 연동한다. 각 테이블 항목은 장치의 종류, 주소, 상태 등을 가리킨다.
2.
버퍼링
•
버퍼는 두 장치 사이나 장치와 응용 프로그램 사이에 데이터가 전송되는 동안 전송할 데이터를 임시로 저장하는 메모리 영역을 말한다.
•
버퍼링은 아래의 세 가지 이유 때문에 필요하다.
◦
네트워크는 드라이브보다 천배 정도 느린데, 이렇게 데이터의 생산자와 소비자 사이의 속도 차이에 대처하기 위함이다. 네트워크에서는 버퍼를 두 개 두어서 하나의 버퍼를 읽는 동안 다른 버퍼에 쓰는 식의 이중 버퍼링을 이용하여 데이터 간의 타이밍 요구 사항을 완화한다.
◦
데이터 전송 크기가 다른 장치들 사이에 완충이 필요한 경우에 사용된다. 이런 경우는 네트워크에서 자주 발생하는데, 송신측의 큰 메세지를 작은 네트워크 패킷으로 나누어 전송하면 수신측에서 패킷들을 버퍼에서 결합하여 자료를 복원한다.
◦
버퍼링은 응용 프로그램의 입출력 복제 시맨틱(copy semantics)을 지원하기 위해 사용된다. 복제 시맨틱은 운영체제에서 프로세스나 스레드에 대한 입출력 동작을 어떻게 처리하는지를 나타내는 개념이다. 입출력 작업을 수행할 때 데이터는 프로세스나 스레드에서 운영체제로 복사되어 전달되고, 입출력 작업이 완료되면 운영체제에서 다시 복사되어 프로세스나 스레드로 전달된다. 이러한 방식은 데이터의 안전성을 보장하지만 오버헤드가 발생한다.
3.
캐싱
•
캐시는 자주 사용될 자료의 복사본을 저장하는 빠른 메모리 영역으로, 캐시된 복사본을 사용하면 원래의 자료를 사용하는 것보다 효율적이다.
•
캐싱과 버퍼링은 서로 다른 기능이지만 메모리 영역을 두 가지 용도로 모두 사용할 수 있다.
4.
스풀링 및 예약 장치
•
스풀(spool)은 프린터처럼 한번에 하나의 작업만 처리해야하고 여러 응용 프로그램을 번갈아 가며 출력할 수 없는 인터리브(interleave)한 장치를 위해 출력 데이터를 보관하는 버퍼이다.
•
응용 프로그램의 출력은 각각 대응되는 보조저장장치 파일에 스풀되어, 응용 프로그램이 출력 데이터를 다 만들면 스풀링 시스템에서 모아둔 출력 데이터를 출력용 대기 열에 삽입한다.
5.
오류 처리
•
일반적으로 입출력 시스템 콜은 성공/실패를 나타내는 하나의 비트 정보를 반환하는데, UNIX 운영체제에서는 반환 값 외에도 errno라 부르는 변수를 사용하여 여러 가지 종류의 오류를 구분해준다.
•
일부 하드웨어는 훨씬 자세한 오류 정보를 제공해주는데, SCSI 장치와 같은 경우에 장치에 문제가 생기면 SCSI 프로토콜에 의해 sense key 형태로 보고하고 오류의 유형을 알려준다. 이외에도 추가적인 sense code가 있어 명령어 인자의 문제점이나 하드웨어 자가 진단 실패와 같은 자세한 정보를 알려주고, sense-code qualifier를 통해 그보다 더 자세한 정보를 알 수 있다.
6.
입출력 보호
•
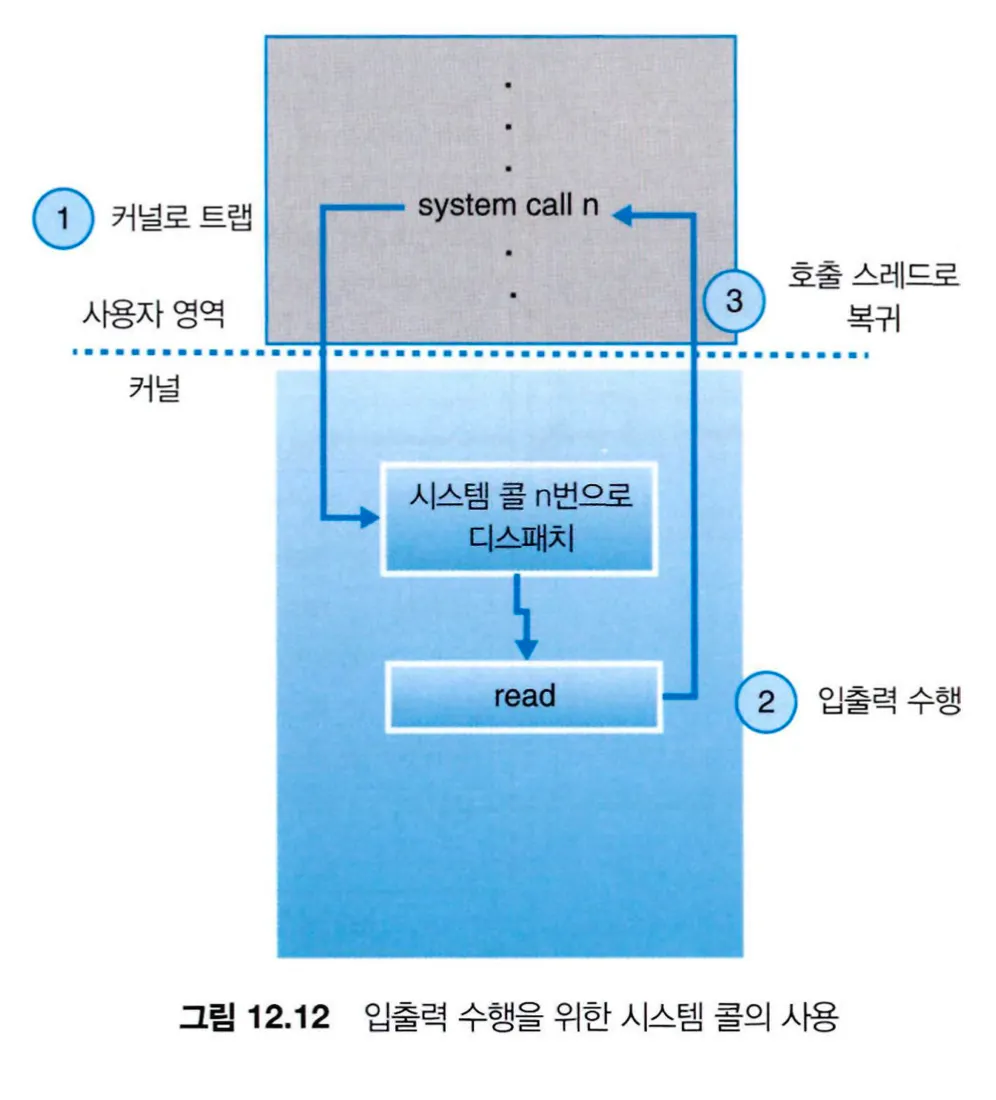
사용자가 불법적인 입출력을 못 하게 하기 위해, 모든 입출력 명령은 특권 명령(privileged instruction)으로 정의되어 사용자는 직접 입출력 명령을 수행할 수 없고 운영체제가 대신 수행하도록 시스템 콜을 수행한다.
7.
커널 자료구조
•
커널은 입출력 구성요소에 대한 상태 정보를 유지하여 네트워크 연결, 문자 장치 통신 등 입출력 활동을 관리한다.
•
UNIX는 파일 시스템 인터페이스를 통해 사용자 파일, raw 장치, 프로세스의 주소 공간 등 다양한 개체들을 파일 시스템 처럼 액세스할 수 있게 제공한다. 모든 객체가 read()를 지원해도 각 객체마다 행해지는 read()의 의미가 다를 수 있다. UNIX는 이런 다양성을 객체지향 기법을 이용하여 하나의 구조로 묶는다.
•
일부 운영체제에서는 객체지향 기법을 한 단계 더 확대하여, 커널과 장치 사이에 입출력 manager라는 프로그램을 두어 입출력 시스템 구조와 설계를 단순화하고 운영체제 커널의 크기를 줄이고 융통성을 늘린다.
STREAMS
•
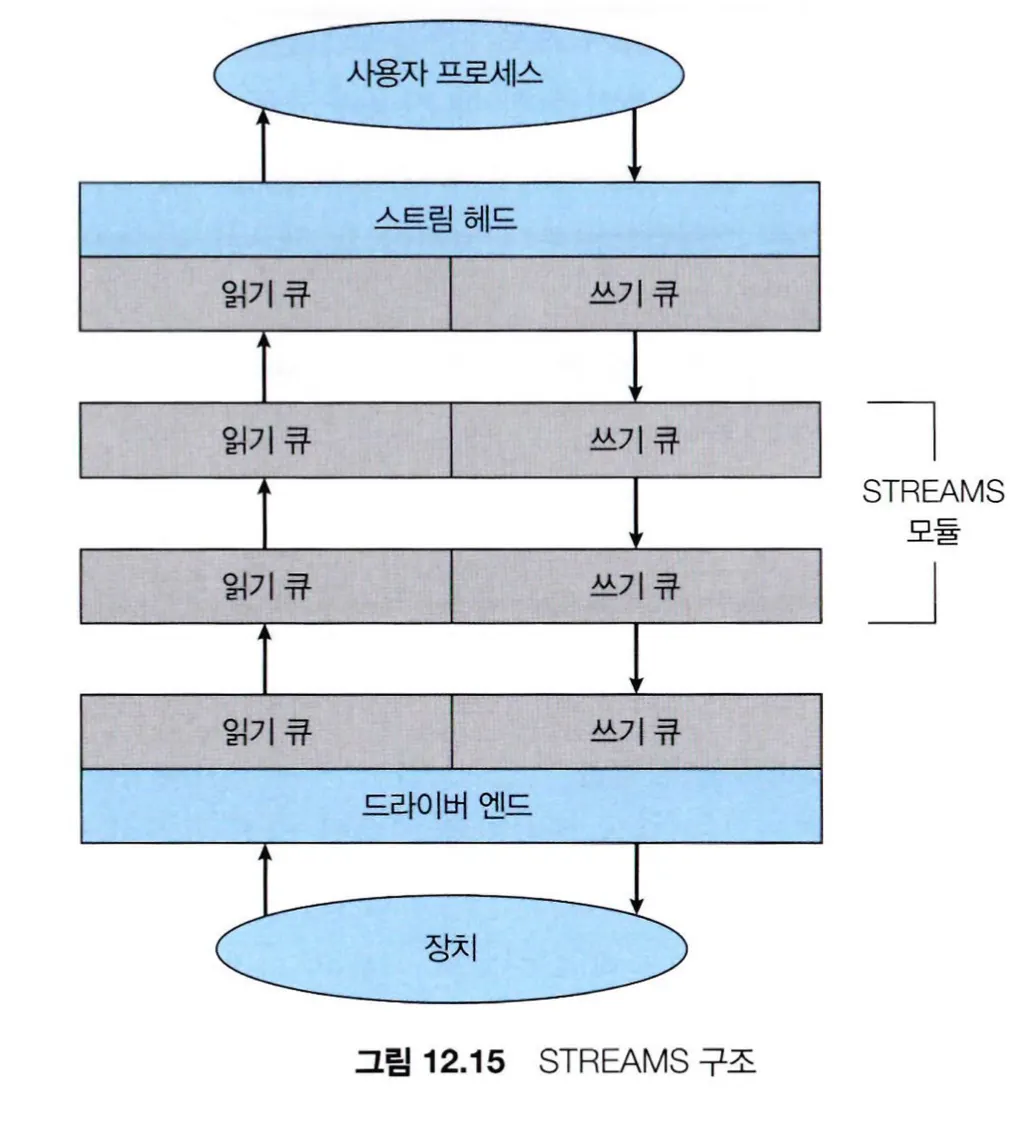
STREAMS는 UNIX에서 사용되는 기법인데, 응용 프로그램이 동적으로 드라이버 코드의 파이프 라인을 조립할 수 있도록 한다. 스트림은 디바이스 드라이버와 사용자 레벨 프로세스 사이의 완전한 양방향 연결을 말한다.
•
스트림은 사용자 프로세스와 상호 연동하는 스트림 헤드와 디바이스를 제어하는 드라이버 엔드, 그 둘 사이에 존재하는 0개 이상의 스트림 모듈로 구성되어 있다.
•
프로세스는 스트림을 통해 키보드 같은 장치들을 오픈하고 입력 편집을 다루는 모듈을 삽입할 수 있다. 인접한 모듈의 큐 사이에서 메세지가 교환되기 때문에 오버플로우가 발생할 수 있어 이러한 오버플로우를 방지하기 위해 큐가 흐름 제어(flow control)을 지원할 수 있다.
•
STREAMS 입출력은 사용자 프로세스가 스트림 헤드와 통신할 때를 제외하고 비동기(비봉쇄적)이다. 흐름 제어를 사용하는 경우 메세지를 복사할 공간이 없다면 block 된다.
•
스트림을 사용하면 디바이스 드라이버와 네트워크 프로토콜을 작성할 때 모듈식으로 점진적 접근을 위한 프레임워크를 사용할 수 있다는 장점이 있다.