
SELECT 구문
데이터베이스의 핵심은 데이터가 저장되어 있는 테이블에서 필요한 데이터를 가져오는 검색이다. SQL(Structed Query Language)은 이름의 Query에서 알 수 있듯 데이터 검색을 잘 수행하기 위한 언어이다. 검색은 질의(query)나 추출(retrieve)라고도 불리기도 하는데, 데이터가 아무리 많더라도 제대로 활용하지 못하면 의미가 없다. 때문에 SQL은 검색 관련해서 굉장히 많은 기능을 제공하고, 검색을 위해 사용하는 SQL 구문을 SELECT 구문이라 부른다.
name | phone_nbr | address | sex | age |
인성 | 080-3333-XXXX | 서울시 | 남 | 30 |
하진 | 090-0000-XXXX | 서울시 | 여 | 21 |
하린 | 부산시 | 여 | 55 |
이와 같은 Address 테이블이 있다고 할 때 아래와 같이 테이블 전체를 선택할 수 있다.
SELECT name, phone_nbr, address, sex, age FROM Address;
SQL
복사

SELECT 구와 FROM 구
SELECT 구문에는 테이블의 어떤 필드를 가져올 지에 대한 SELECT 구와 데이터를 선택할 대상 테이블을 지정하는 FROM 구가 있다. DBMS 마다 조금 다르지만 일반적으로 SELECT 구와 FROM 구는 반드시 입력해야하는데, SELECT 1과 같이 상수를 선택하는 경우에는 특정한 테이블에서 데이터를 꺼내 오는 것이 아니기 때문에 FROM 구를 입력하지 않아도 된다.
위의 결과를 보면 공란이 보이는데, RDB에서는 NULL로 이와 같은 불명한 데이터를 처리한다.
WHERE 절
테이블에서 레코드를 조회할 때, 항상 모든 레코드가 필요한 것은 아니다. 이런 경우에 특정 조건에 맞는 일부 레코드만 가져오도록 WHERE 구를 통해 추가적인 조건을 지정한다.
SELECT name, address FROM address WHERE address = '인천시';
SQL
복사

WHERE 구에는 =와 같은 동일 조건 외에도 다양한 조건 지정이 가능하다.
연산자 | 의미 |
= | ~와 같음 |
<> | ~와 같지 않음 |
>= | ~ 이상 |
> | ~ 초과 |
<= | ~ 이하 |
< | ~ 미만 |
AND나 OR를 통해 복합 조건을 만족하는 레코드를 가져오도록 할 수 있다.
SELECT name, address, age FROM Address
WHERE address = '서울시' AND age >= 30;
SQL
복사

SELECT name, address FROM Address
WHERE address = '서울시' OR address = '부산시' OR address = '인천시';
SQL
복사
이와 같은 여러 OR 조건들을 IN 절을 통해서 간단하게 나타내는 것도 가능하다.
SELECT name, address FROM Address
WHERE address IN ('서울시', '부산시', '인천시');
SQL
복사
위에서 언급한 공란(NULL)과 관련해 조건으로 추가하고 싶다면 아래와 같이 사용해야한다.
SELECT name, phone_nbr FROM Address
WHERE phone_nbr IS NULL;
SQL
복사
NULL과 관련된 조건을 추가할 때 phone_nbr = NULL과 같이 작성하기 쉬우나, 이는 제대로 동작하지 않는다. NULL을 조회할 때는 phone_nbr = IS NULL, NULL이 아닌 경우에는 phone_nbr = IS NOT NULL과 같이 조회해야한다. 이는 NULL이 데이터가 아니기 때문에, 데이터에 적용하는 연산자(=, <>, > 등)를 적용할 수 없기 때문이다.
SELECT 구문은 함수
SELECT 구문은 절차 지향형 언어의 함수와 기능이 비슷하다. 테이블을 입력으로 받아, 테이블을 출력한다.
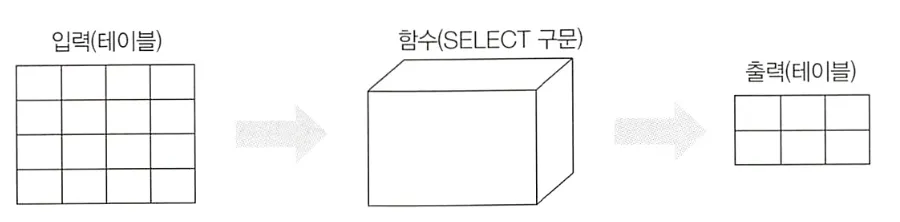
이 때문에 SELECT 구문은 관계가 닫혀있다는 의미의 폐쇄성(clsure property)을 가진다고 하고, 이는 뷰와 서브쿼리의 기본이 되는 개념이다.
GROUP BY 구
GROUP BY 구를 사용하면, 테이블에서 단순하게 데이터를 선택하는 것 뿐만 아니라 합계나 평균과 같은 집계 연산들을 SQL 구문으로 처리할 수 있다.
함수 이름 | 설명 |
COUNT | 레코드 수를 계산 |
SUM | 숫자를 더함 |
AVG | 숫자의 평균을 구함 |
MAX | 최대값을 구함 |
MIN | 최소값을 구함 |
SELECT address, COUNT(*) FROM Address
GROUP BY address;
SQL
복사

HAVING 구
위의 GROUP BY 구를 적용하여 여러 집합으로 그룹화 이후, 그 결과 집합에 HAVING 구를 통해 추가로 조건을 걸어 선택할 수 있다.
SELECT address, COUNT(*) FROM Address
GROUP BY address HAVING COUNT(*)=1;
SQL
복사

이와 같이 WHERE 구가 레코드에 조건을 지정하는 거라면, HAVING 구는 결과 집합에 조건을 지정하는 기능이다.
ORDER BY 구
SQL의 일반적인 규칙에는 정렬과 관련된 내용이 없기 때문에, 위의 예시들처럼 SQL 구문을 통해 레코드를 조회하면 결과들의 출력 순서는 딱히 정해진 규칙 없이 순서가 아무렇게나 되어있다. 모든 DBMS에서 SELECT 구문 결과의 순서를 보장하려면, ORDER BY 구를 사용해 순서를 명시적으로 지정해야한다.
SELECT name, phone_nbr, address, sex, age FROM Address
ORDER BY age DESC;
SQL
복사

ORDER BY 구 뒤에 정렬 순서를 정해야 하는데, 오름차순은 ASC(Ascending)으로 지정하고 내림차순은 DESC(Descending)으로 지정한다.
뷰와 서브쿼리
뷰(View)는 데이터베이스 안에 SELECT 구문을 저장하는 기능으로, 복잡하거나 자주 사용되는 SELECT 구문을 텍스트 파일로 저장하여 간편하게 호출하여 사용하기 위한 기능이다. 뷰는 말그대로 SELECT 구문을 텍스트로 저장할 뿐, 그 결과 테이블을 내부에 저장하지 않는다.
•
뷰 생성하기
CREATE VIEW CountAddress (v_address, cnt) AS
SELECT address, COUNT(*) FROM Address GROUP BY address;
SQL
복사
•
뷰 사용하기
SELECT v_address, cnt FROM CountAddress;
SQL
복사
뷰는 사용 방법이 테이블과 동일하지만, 내부에는 데이터를 보유하지 않는다. 실제적으로 뷰는 추가적인 SELECT 구문을 실행하는 중첩(nested) 구조이다.
// 뷰에서 데이터를 선택
SELECT v_address, cnt FROM CountAddress;
// 뷰를 실행할 때 SELECT 구문으로 전개
SELECT v_address, cnt
FROM (SELECT ADDRESS AS v_address, COUNT(*) AS cnt
FROM Address GROUP BY address)
AS CountAddress;
SQL
복사
이와 같이 FROM 구에 SELECT 구문을 통해 어떤 레코드를 가져올지 직접 지정하는 것을 서브쿼리(subquery)라 부른다.
name | phone_nbr | address | sex | age |
인성 | 080-3333-XXXX | 서울시 | 남 | 30 |
민 | 080-3333-XXXX | 부산시 | 남 | 32 |
준서 | 부산시 | 남 | 18 |
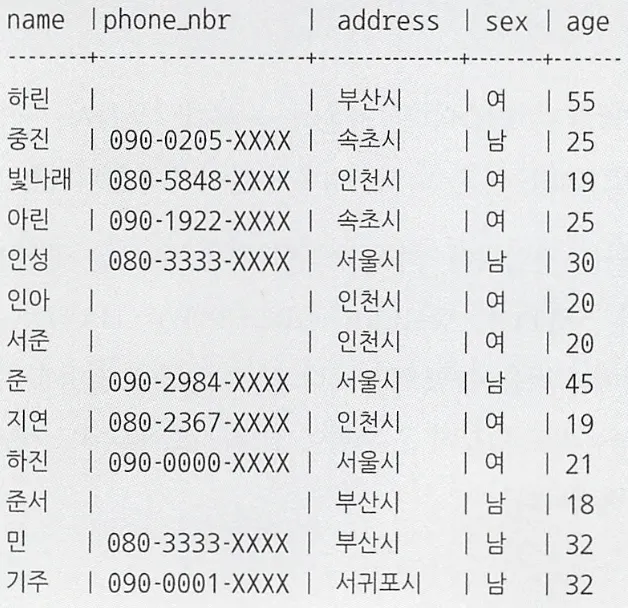
이와 같은 Address2 테이블이 있다고 할 때, ‘Address 테이블에서 Address2 테이블에 있는 사람을 선택하는 SQL 문’을 IN 절과 서브쿼리로 나타낼 수 있다.
SELECT name FROM Address
WHERE name IN (SELECT name FROM Address2);
SQL
복사
IN 절은 상수를 매개변수로 받는 것 외에도 이와 같이 서브쿼리를 매개변수로 받을 수 있다. 이런 처리를 매칭(matching)이라 부른다.
DBMS에서는 이러한 SELECT 구문을 받으면 아래처럼 서브쿼리를 상수로 전개해서 치환한다.
SELECT name FROM Address
WHERE name IN ('인성', '민', '준서', ... , '중진');
SQL
복사
위와 동일한 SELECT 문을 직접 상수를 하나씩 입력하는 하드코딩은 Address2 테이블이 변경될 때마다 수정해야하지만, 서브쿼리를 사용하면 데이터가 바뀌더라도 수정없이 사용 가능하다.
조건 분기, 집합 연산, 윈도우 함수, 갱신
SQL 조건 분기
SQL에는 조건 분기를 문장 단위가 아닌 식 단위로 분기한다. 절차 지향형 프로그래밍 언어의 switch 조건문과 비슷하게, CASE 식과 WHEN 구의 평가식을 통해 특정 조건에 따른 동작을 지정할 수 있다.
WHEN 구의 평가식으로 평가 후 조건이 맞으면 THEN 구에 지정된 식이 리턴되며 CASE 식이 종료되고, 맞지 않으면 다음 WHEN 구로 이동해 같은 처리를 반복한다. 모든 조건에 맞지 않는다면 ELSE에서 지정한 식이 리턴된다.
SELECT name, address,
CASE WHEN address = '서울시' THEN '경기'
WHEN address = '인천시' THEN '경기'
WHEN address = '부산시' THEN '영남'
WHEN address = '속초시' THEN '관동'
WHEN address = '서귀포시' THEN '제주'
ELSE NULL END AS district
FROM Address;
SQL
복사

CASE는 식이기 때문에, 식을 적을 수 있는 어느 위치에서든 사용될 수 있다. 위처럼 SELECT 구에도 사용할 수 있고, WHERE, GROUP BY, HAVING, ORDER BY 구 어디에나 사용 가능하다.
SQL 집합 연산
SQL에는 여러 테이블 조회 결과를 UNION이나 INTERSECT 같은 집합 연산을 하는 기능이 있다. 여러 집합 연산들의 결과에서 중복되는 항목이 있다면, 자동으로 중복되는 레코드를 제거한다.
•
UNION으로 합집합 구하기
SELECT * FROM Address
UNION SELECT * FROM Address2;
SQL
복사
•
INTERSECT로 교집합 구하기
SELECT * FROM Address
INTERSECT SELECT * FROM Address2;
SQL
복사

•
EXCEPT로 차집합 구하기
SELECT * FROM Address
EXCEPT SELECT * FROM Address2;
SQL
복사

EXCEPT는 UNION이나 INTERSECT와는 다르게 어떤 테이블이 먼저 오는지 순서에 따라 결과가 달라진다. 이는 두 집합 A와 B에서 차집합 A-B와 B-A가 다른 것과 마찬가지이다.
윈도우 함수
GROUP BY 구는 데이터를 분류하는 것과 분류한 데이터들을 집약하는 기능으로 구분된다. 윈도우 함수는 GROUP BY에서 데이터들을 집약하는 기능을 빠진 것이라고 볼 수 있다.
윈도우 함수의 기본적인 구문은 COUNT나 RANK 같은 집약 함수 뒤에 OVER 구를 작성 후 내부에 PARTITION BY 혹은 ORDER BY를 입력하는 것이다.
// GROUP BY
SELECT address, COUNT(*) FROM Address GROUP BY address;
// PARTITION BY
SELECT address, COUNT(*) OVER(PARTITION BY address) FROM address;
SQL
복사

GROUP BY 결과

PARTITION BY 결과
실제 윈도우 함수 결과에는 위와 같이 파티션마다 구분선이 있지는 않다.
GROUP BY 구는 결과를 분류하고, 집약 작업까지 수행하여 중복되는 항목 없이 각 분류된 레코드로 출력된다. 반면,윈도우 함수는 분류까지 수행하지만, 집약 작업을 하지 않기 때문에 처음 조회된 레코드 수와 동일한 수만큼의 결과가 출력된다.
COUNT나 SUM과 같은 일반 함수 외에도, RANK나 ROW_NUMBER 등의 윈도우 함수 전용의 순서 관련 함수들도 제공된다.
SELECT name, age, RANK() OVER(ORDER BY age DESC) AS rnk FROM Address;
SQL
복사

위 결과를 보면 공동 3위로 인해 4위가 없는데, RANK 대신 DENSE_RANK를 사용하면 건너뛰지 않고 이어서 순위를 출력할 수 있다.
갱신 기능과 트랜잭션
기본적으로 SQL의 갱신 작업은 삽입(insert)과 제거(delete), 갱신(update) 세 종류로 분류된다.
•
삽입(INSERT)
RDB에서 데이터를 등록하는 단위는 레코드(행)이라 한다. INSERT는 레코드를 삽입하는 기능이다.
INSERT INTO Address (name, phone_nbr, address, sex, age)
VALUES ('인성', '080-3333-XXXX', '서울시', '남', 30);
SQL
복사
위처럼 삽입 기능 사용 시 필드에 문자열을 넣으려면 작은따옴표(싱글쿼트)로 문자열을 감싸야 하고, 숫자나 NULL을 넣으려면 감싸지말고 그대로 넣으면 된다.
INSERT INTO Address (name, phone_nbr, address, sex, age)
VALUES ('인성', '080-3333-XXXX', '서울시', '남',30),
('하진', '090-0000-XXXX', '서울시', '여', 21),
('준', '090-2984-XXXX', '서울시', '남', 45),
('만', '080-3333-XXXX', '부산시', '남', 32),
('하란', NULL, '부산시', '여', 55),
('빛나래', '080-5848-XXXX', '인천시', '여', 19),
('인아', NULL, '인천시', '여', 20),
('아린', '090-1922-XXXX', '속초시', '여', 25),
('기주', '090-0001-XXXX', '서귀포시', '남', 32);
SQL
복사
만약 여러 개의 레코드를 넣고 싶다면, 이와 같이 사용하여 한 개의 INSERT 구문으로 반복해서 삽입하는 기능을 지원하는 DBMS들이 있다.
•
제거(DELETE)
데이터를 삭제하는 방법은 레코드를 삭제하는 것과 테이블을 삭제하는 방법이 있다.
// 테이블 삭제
DELETE FROM Address;
// 특정 레코드 삭제
DELETE FROM Address WHERE address = '인천시';
SQL
복사
데이터 삭제는 테이블 혹은 레코드(행) 단위로 이루어지기 때문에 DELETE name FROM Address;와 같이 DELETE 뒤에 필드를 넣으면 오류가 발생한다.
•
갱신(UPDATE)
등록된 데이터를 UPDATE 구문을 통해 변경할 수 있다.
UPDATE Address SET phone_nbr = '080-5849-XXXX'
WHERE name = '빛나래';
SQL
복사
WHERE 구를 생략하면 해당 테이블의 모든 레코드가 값이 변경된다. SET 구에 여러 필드들을 입력해, 한 번에 해당 레코드 내의 여러 값을 변경할 수 있다.
// 여러 필드 수정하기 방법1
UPDATE Address SET phone_nbr = '080-5849-XXXX', age = 20
WHERE name = '빛나래';
// 여러 필드 수정하기 방법2
UPDATE Address SET (phone_nbr, age) = ('080-5849-XXXX', 20)
WHERE name = '빛나래';
SQL
복사
두 번째 방법은 DBMS에 따라 지원하지 않을수도 있다.