

Multiple Bag Fetch Exception을 만나게 된 계기
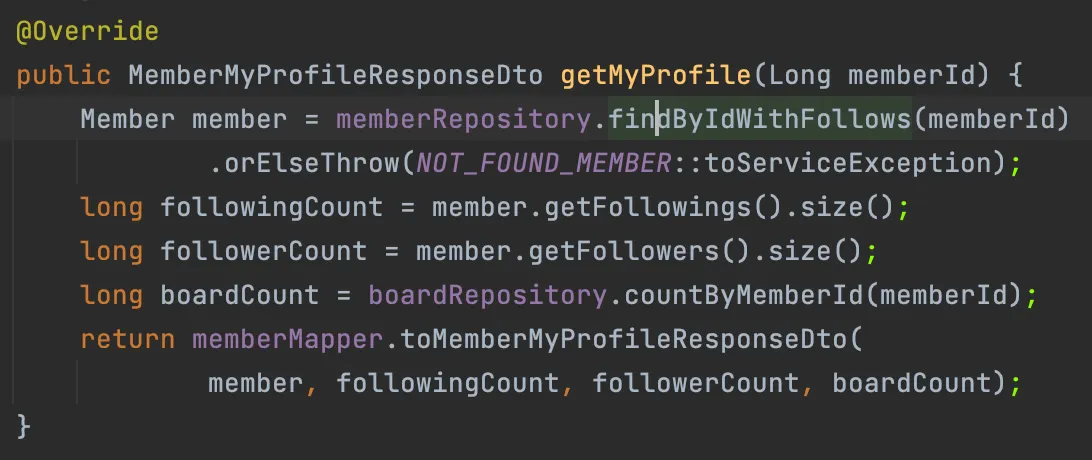
42 PAW 프로젝트 API를 구현하면서 코드를 작성하다가 아래와 같은 서비스 로직을 작성하게 되었다.
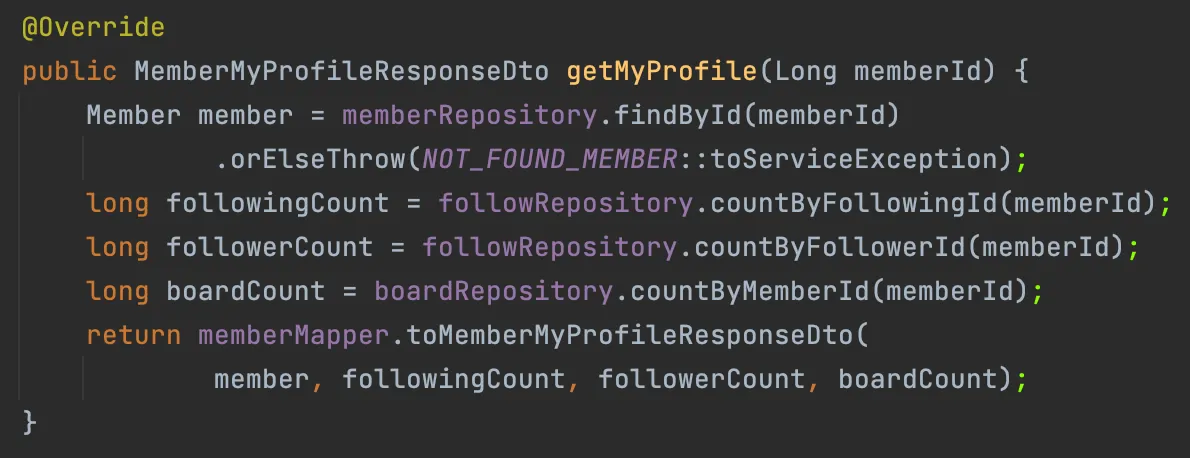
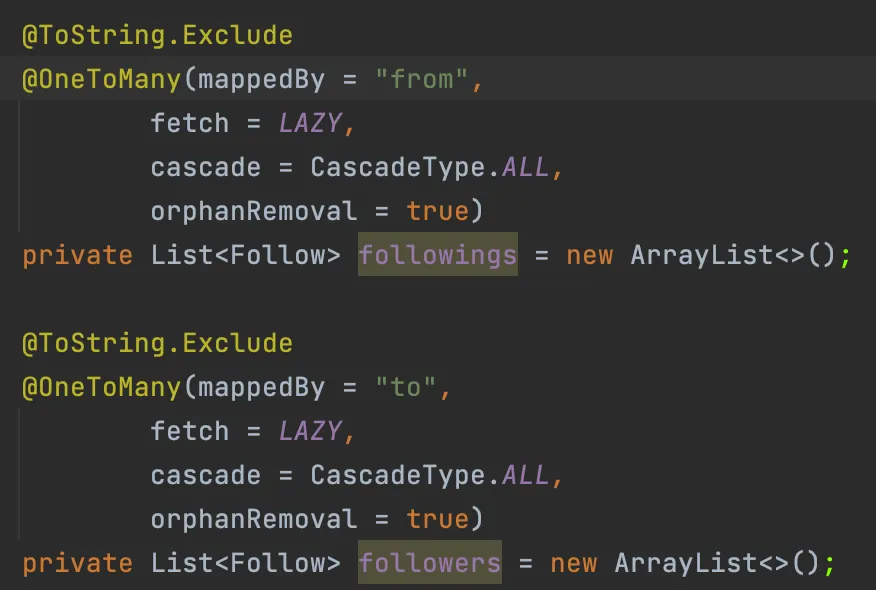
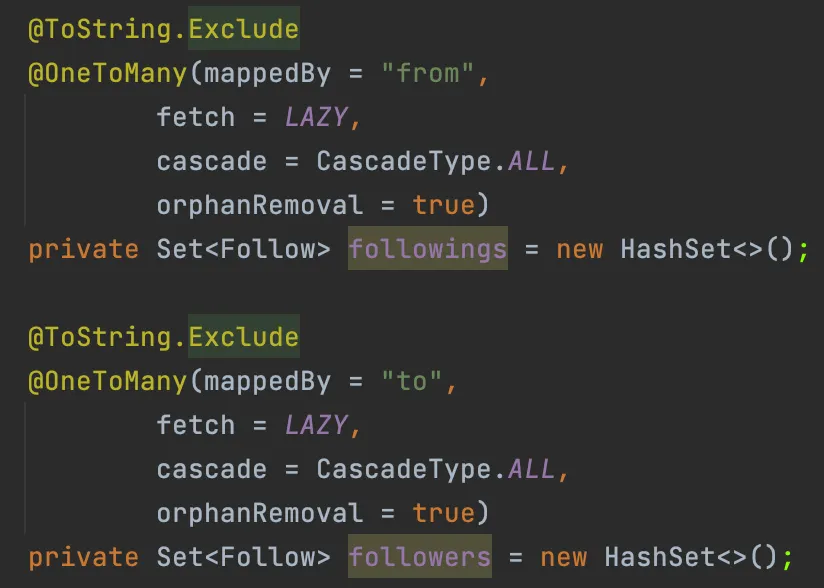
Member의 팔로우 관련 연관관계
로직에 대해서 간략하게 설명해보자면, member를 조회해와서 해당 멤버를 팔로우 하는 사람과 팔로우 하고 있는 사람의 수, 해당 member가 올린 게시글의 수를 계산하여 DTO로 변환하는 로직이다.
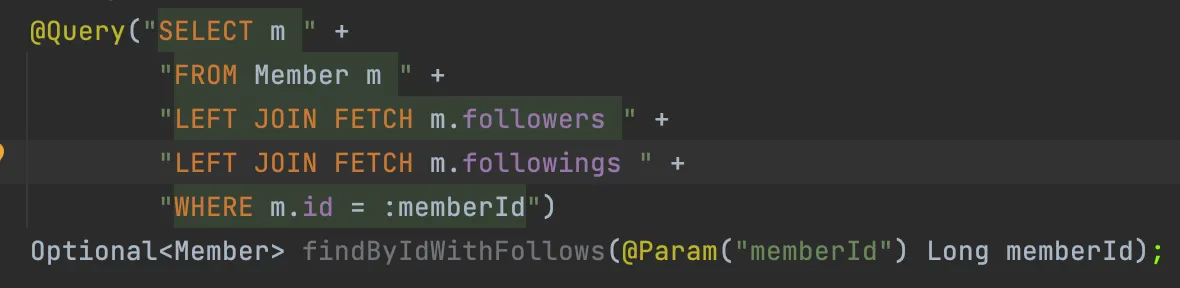
해당 로직을 작성하던 중, 이 부분에서 단순히 숫자를 세기 위해 쿼리가 4번 나간다는 사실을 깨닫고 고민에 빠졌다. Member에서 찾아올 때 Fetch Join으로 다 같이 불러오면 Collections.size()로 끝나는 로직이라 생각되어 바로 아래와 같이 JPQL을 수정해서 테스트 해보았다.
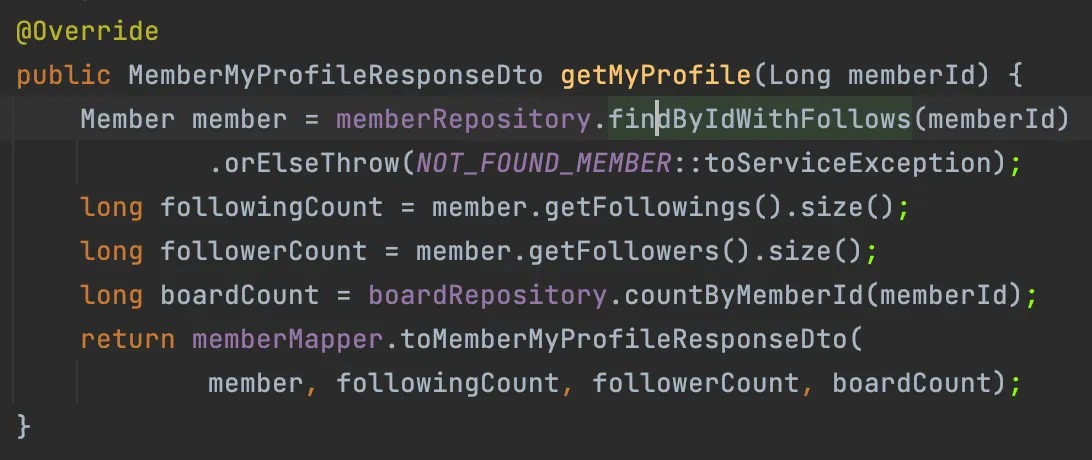
그 결과로 만난 것이 MultipleBagFetchException이다.
MultipleBagFetchException
MultipleBagFecthException은 주로 Fetch Join을 사용할 때, 여러 BagType fetch 해올 때 발생하는 예외다.
여기서의 Bag(MultiSet)은 Set과 같이 순서가 없고, List와 같이 중복을 허용하는 Hibernate의 자료구조를 말한다. 하지만 자바에서는 Bag이 없기 때문에 List를 Bag으로써 사용하고 있다. 이를 통해서 여러 Bag을 Fetch join하려 할 때 MultipleBagFetchException이 발생하는 것을 알 수 있었다. 다시말해, OneToMany나 ManyToMany와 같이 ToMany를 Fetch Join으로 가져오는 경우가 2개 이상이면 발생한다.
위 상황에서는 OneToMany인 followers와 followings가 둘 다 List로 받기 때문에, 두 필드를 모두 fetch join하려 시도했더니 MultipleBagFecthException이 발생한 것이다.
해결방법 및 적용하기
MultipleBagFecthException의 해결 방법들을 확인하기 전에 해당 방법들을 수정했을 때 각각 성능이 얼마나 나오는지 확인해보려 한다. 이를 위해서 Member 100명, Follow 데이터 9900개를 넣어두고 위의 Query 4번을 호출하는 코드 기준으로 100회 평균 API 호출 시간을 측정했다.
Query 4번 호출 코드 테스트 결과
MultipleBagFecthException이 발생하는 상황에 다음과 같은 몇 가지 해결 방법이 있다.
1.
ToMany 필드 요소를 List를 Set으로 바꾸기
List에는 중복이 있을 수 있지만 순서가 있고, Set에는 중복이 없는 대신 순서가 없다. 이에 맞춰 해당 필드의 요소가 순서가 중요하다면 List를, 중복이 없는 게 중요하다면 Set을 사용하는 것이 좋다.
위의 코드에서는 follower의 순서가 중요하지 않다는 가정 하에 Set으로 바꾸고 Fetch Join으로 쿼리 한 번에 다 조회해오는 로직을 작성했다.
테스트 결과
2.
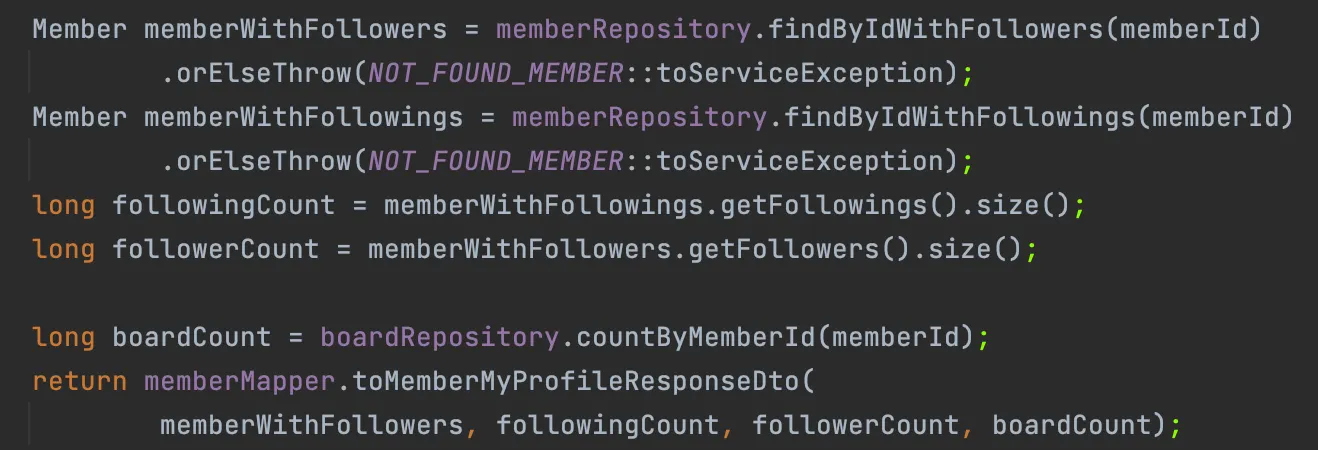
Fetch Join을 두 번에 나누어 호출하기
이 방법은 작성을 하면서도 굳이 Member를 두 번이나 조회를 하는게 정말 별로구나 싶었다. 하지만 의외로 결과가 그렇게 나쁘지 않았다.
테스트 결과
3.
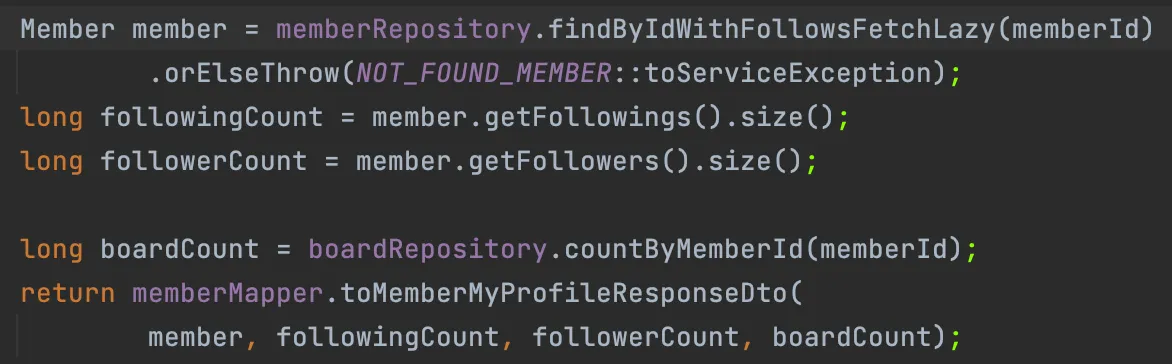
데이터가 가장 많은 요소를 Fetch join하고, 나머지 요소들을 Lazy loading 설정 후 batch size 설정으로 최적화 하기
BatchSize 어노테이션으로 in 절을 통해 N+1의 여러 쿼리를 묶어서 호출하도록 구현하는 방법으로, batch size를 1000으로 설정했으나 의외로 성능이 별로 좋지 않았다.
테스트 결과
4.
각각 별도의 Query로 조회 후 key를 기준으로 조립하기
이 해결 방법은 얻어 걸린거지만 내가 초기에 fetch join에 대한 고민을 시작하게 된, 작성한 각자의 쿼리로 4번 조회해오는 코드이다.
테스트 결과
실제 테스트 결과는 count를 별도의 쿼리로 사용하기(19ms) → 각각 fetch join으로 불러와 사용하기(31ms) → Fetch Join + Lazy loading으로 조회하기(153ms) → List 대신 Set 사용하기(161ms)순 이었다.
사실 테스트를 작성하면서 고민해봤을 때, SQL 질의문과 다르게 COUNT는 조건이 걸린 특정 컬럼만 순회하며 비교하기 때문에 fetch join보다 빠를거라 예상은 했다. 이러한 count 쿼리 특성상 필요한 값들만 확인하기 때문에 쿼리는 4번 발생하지만 성능은 압도적으로 빨랐다.
다음은 의외로 fetch join을 두 번 사용하여 각각 호출하는 방법이 빨랐는데, 이는 전체 follow는 9900개지만 하나의 멤버가 들고 있는 follow의 수가 100개로 제한되도록 데이터를 저장해서 이런 결과가 나온 것 같다.
Join을 두 번 타는 두 방법은 결과가 비슷하게 나왔는데, 결국 데이터를 조회해오고 Set을 통하든 JPA 내부적으로든 정렬하고 중복 제거를 하는 과정에서 속도가 느려지는 것 같다. 같은 이유에서 위의 두 번째 방법도 만약 데이터가 더 방대해지고 한 멤버의 팔로우가 많아진다면, 속도가 느려지는 폭이 count에 비해 훨씬 크지 않을까 생각된다.
결론
Fetch Join은 분명 쿼리 호출 횟수를 줄여주는 좋은 방안이지만, Fetch Join을 사용함으로써 DBMS 내부적으로 정렬하고 중복을 제거하는 등의 오버헤드가 분명히 존재한다. 그러니 여러 번 쿼리를 호출한다고 무작정 Fetch Join을 사용하지말고, 많은 고민을 해보고 여러 성능 테스트를 걸쳐 최적화하자.



