
반목문
SQL의 반복문
SQL에는 반복문이 없다. SQL은 관계 전체를 조작의 대상으로 삼기 때문에, 일부러 반복문을 언어 설계에서 제외하였다.
일반적으로 사용자는 SQL의 반복문 부재를 자바나 C# 같은 절차 지향형 호스트 언어에서 구현하여 이를 해결한다. 하지만 이런 경우 반복적인 SELECT 구문이 발생하거나, 대량의 데이터를 레코드 하나씩 테이블에 갱신하게 된다.
SQL 문을 통해서 여러 데이터를 한 번에 처리하고자 할 때, 반복적인 호출로 처리하는 반복계와 여러 호출을 한 번에 처리하는 포장계가 있다.
반복계 단점
반복계의 가장 큰 단점은 성능이 떨어진다는 것이다. 같은 기능을 구현할 때 반복계는 포장계보다 성능이 훨씬 떨어진다. 처리 특성에 따라 다르겠지만, 간단하게 일반화하면 아래와 같다.
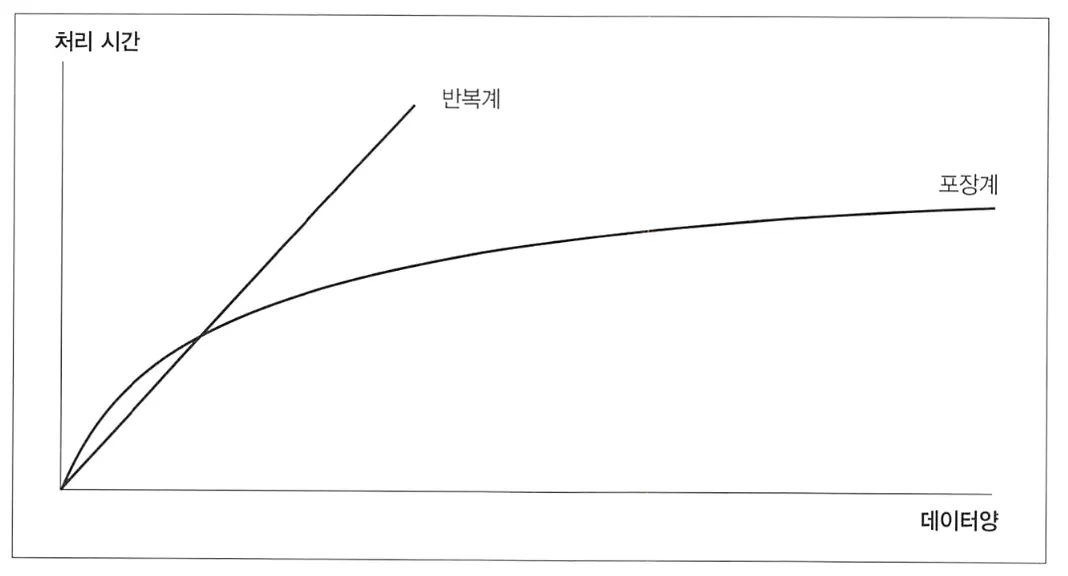
SQL을 실행할 대는 데이터를 검색하거나 연산하는 처리 외에도, 전처리로 데이터베이스 연결, SQL 구문 네트워크 전송, SQL 구문 파스, SQL 구문 실행 계획 생성 및 평가 등의 처리를 수행하고 후처리로 결과 집합을 네트워크로 전송한다.
이 중 SQL 구문을 네트워크로 전송하는 것과 실행 결과를 네트워크로 전송하는 것은 어플리케이션과 데이터베이스가 물리적으로 같은 본체에 있다면 발생하지 않는다. 분리 되어있다고 하더라도, 일반적으로 같은 데이터센터 내 동일 LAN 상에 있으므로 전송 속도가 빨라 오버헤드가 거의 없다. 또한, 데이터베이스 연결도 최근의 어플리케이션에서는 커넥션 풀 방식을 적용하기 때문에 거의 문제가 되지 않는다.
오버헤드 중 가장 영향이 큰 것은 SQL 구문 파스와 SQL 구문 실행 계획 생성 및 평가이다. 특히 SQL 구문 파스는 종류에 따라 0.1초~1초 정도 걸리고, 반복계에서는 이 시간이 반복하여 SQL을 받을 때마다 소요되므로 큰 오버헤드가 된다.
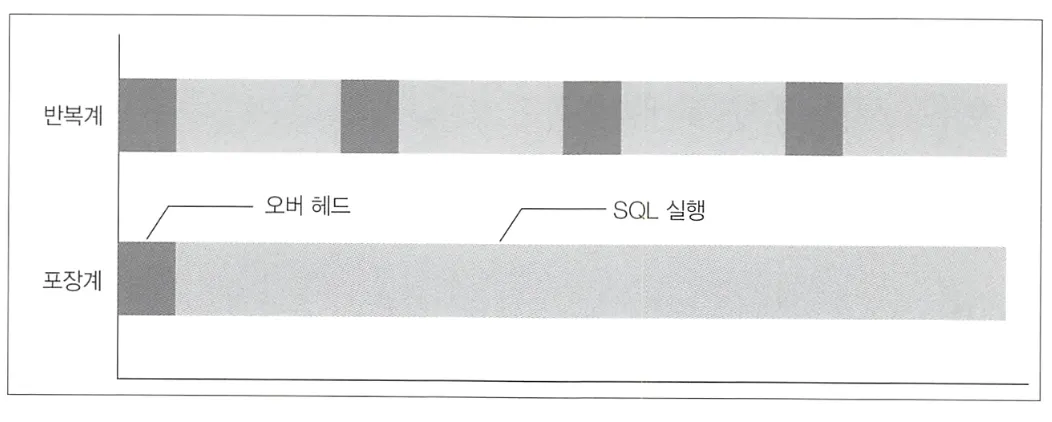
또 다른 반복계의 단점으로는 병렬 분산처리를 할 수 없다는 것이다. 반복계 SQL 구문은 처리를 굉장히 단순화하기 때문에, 리소스를 분산해서 병렬 처리하는 최적화가 안된다. 데이터베이스 서버 저장소는 대부분 RAID 디스크로 구성되어있어 I/O 부하를 분산할 수 있게 되어있지만, 반복계는 1회 SQL 구문이 접근하는 데이터양이 적기 때문에 I/O 병렬화를 하기 힘들다.
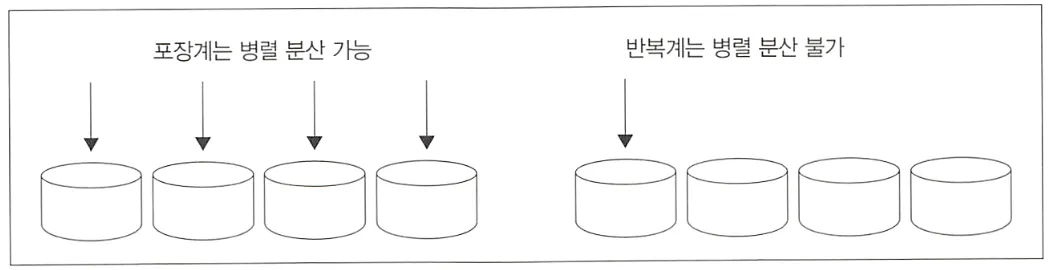
또한 반복계는 데이터베이스가 발전해도 그로 인한 혜택을 받을 수 없다. 데이터베이스가 처리해야 하는 데이터양이 점차 늘고 있어, DBMS 개발사는 SQL을 어떻게 해야 더 빠르게 할 수 있을지 연구한다. 이러한 노력 중에는 대규모 데이터를 다루는 복잡한 SQL 구문을 빠르게 만들기 위한 노력도 있다. 반면 단순한 SQL 구문을 더 빠르게 처리하기 위한 노력은 거의 하지 않는다. 반복계는 튜닝할 수 있는 가능성도 거의 없기 때문이다. 반면 포장계는 튜닝을 제대로 한다면 현격한 성능 차이를 만들어 낼 수 있다.
반복계를 빠르게 만들기
1.
반복계를 포장계로 바꾸기
어플리케이션을 수정하여 반복계를 포장계로 바꾸는 방법이다. 이미 다 만들어진 어플리케이션에서 성능 검증 시에 문제가 발견되는 경우가 많기 때문에, 실제 이런 선택지를 사용할 수 없는 경우가 많다.
2.
각각의 SQL을 더 빠르게 수정하기
각각의 SQL을 더 빠르게 수정하여, 전체적으로 성능 향상을 시키는 방법이다. 하지만 반복계에서 사용하는 SQL 구문은 너무 단순하기 때문에, 유니크 스캔 혹은 인덱스 레인지 스캔을 제외하면 더 이상 튜닝할 여지가 별로 없는 경우가 많다.
3.
다중화 처리
CPU와 디스크 같은 리소스에 여유가 있고 처리를 분할할 수 있는 키가 명확하다면, 처리를 다중화해서 성능을 선형에 가깝게 스케일 할 수 있다. 반대로 데이터를 분할할 수 있는 키가 명확하지 않거나, 병렬화 했을 때 리소스가 부족하다면 사용하지 못한다.
반복계의 장점
반복계의 장점은 대부분 SQL 구문과 실행 계획이 단순하여 발생하는 장점들이다. 실행 계획이 단순하기 때문에 변동 위험이 거의 없어 실행 계획의 안정성이 높다.
또한 예상 처리 시간의 정밀도가 높다. 포장계는 실행 계획에 따라 성능이 현격한 차이를 보이는데, 반복계의 SQL 구문은 간단하기 때문에 예상 처리 시간의 차이가 그리 크지 않다.
반복계는 갱신 처리를 반복해서 하는 경우, 특정 반복 횟수마다 커밋을 수행하면 중간에 오류가 발생하더라도 해당 지점 부근부터 다시 처리하면 된다. 이처럼 반복계는 트랜잭션 제어가 편리하다.
SQL 내 반복문 표현
포장계를 사용하기 위해 SQL에서 반복을 대신하는 수단은 CASE 식과 윈도우 함수다. 윈도우 함수와 CASE 식을 함께 사용하여 표현할 수 있다.
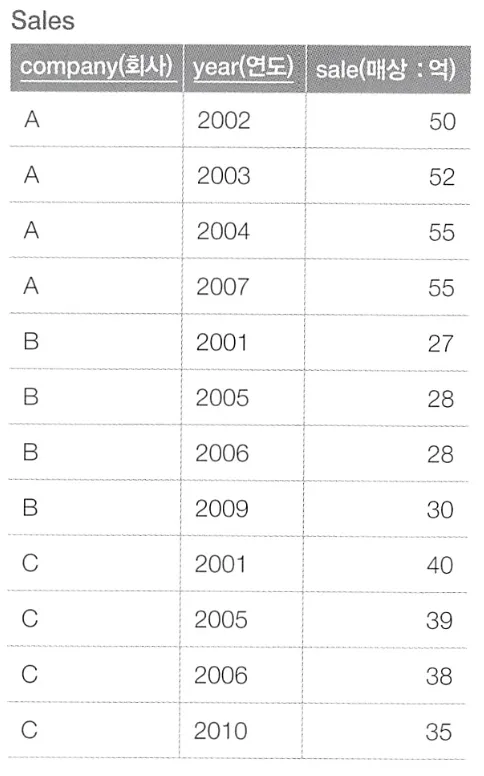
이런 테이블에서 전년도 매출의 등략을 표시하여 아래와 같은 테이블을 출력하고자 한다.
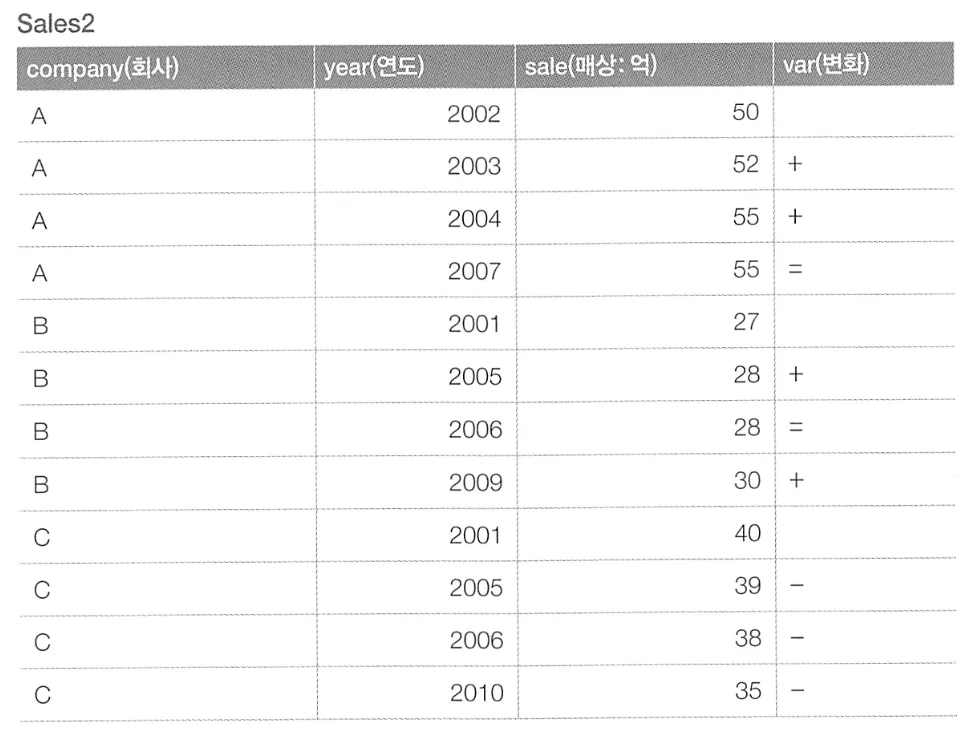
아래와 같이 SQL 구문을 작성하면 이를 얻을 수 있다.
SELECT company, year, sale,
CASE SIGN(sale - MAX(sale) OVER
PARTITION BY company ORDER BY year
ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING))
WHEN 0 THEN '='
WHEN 1 THEN '+'
WHEN -1 THEN '-'
ELSE NULL END AS var
FROM Sales;
SQL
복사
위 SQL 구문의 핵심은 ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING이다.
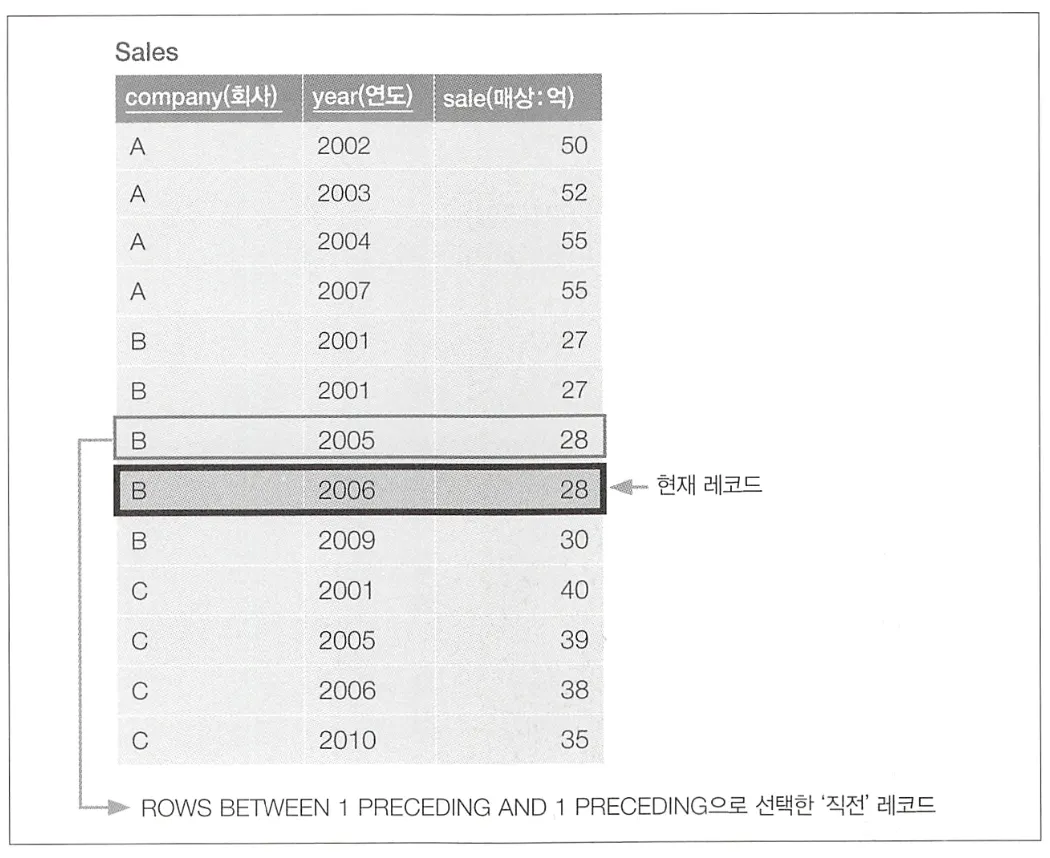
ROWS BETWEEN … AND … 식
위 SQL 구문의 실행 계획은 다음과 같다.

PostgreSQL 실행 계획

Oracle 실행 계획
테이블을 풀 스캔 후 윈도우 함수를 정렬로 실행한다. 윈도우 함수가 같은 회사의 직전 매상을 리턴하고 이를 SELECT 구문에서 출력한다.
최대 반복 횟수가 정해져있는 경우
일본의 우편번호는 413-0033처럼 7자리의 숫자로 되어 있는데, 하위 자리수까지 일치 할수록 가까운 지역을 의미한다. 이런 일본의 우편 번호를 관리하는 테이블에서, 입력 받은 우편번호가 가장 가까운 우편번호를 검색하고자 한다.

이 상황에서 4130033을 검색하고자 한다면, 일치하는게 없기 때문에 413003* → 41300** → … 순으로 검색하여 가장 낮은 자리까지 일치하는 우편번호를 출력한다.
이 문제의 해결 방법은 각 검색별로 순위를 매겨 그 결과를 그룹화해서 선택하여 출력하는 것이다.
SELECT pcode, district_name FROM PostalCode
WHERE CASE WHEN pcode = '4130033' THEN 0
WHEN pcode LIKE '413003%' THEN 1
WHEN pcode LIKE '41300%' THEN 2
WHEN pcode LIKE '4130%' THEN 3
WHEN pcode LIKE '413%' THEN 4
WHEN pcode LIKE '41%' THEN 5
WHEN pcode LIKE '4%' THEN 6
ELSE NULL END =
(SELECT MIN(CASE WHEN pcode = '4130033' THEN 0
WHEN pcode = '413003%' THEN 1
WHEN pcode = '41300%' THEN 2
WHEN pcode = '4130%' THEN 3
WHEN pcode = '413%' THEN 4
WHEN pcode = '41%' THEN 5
WHEN pcode = '4%' THEN 6
ELSE NULL END)
FROM PostalCode);
SQL
복사
이와 같이 서브 쿼리와 CASE 식을 통해 순위를 매겨 그룹을 나누고, 나눈 그룹을 WHERE 구에서 선택하는 것이다.
위 SQL 구문의 실행 계획은 다음과 같다.
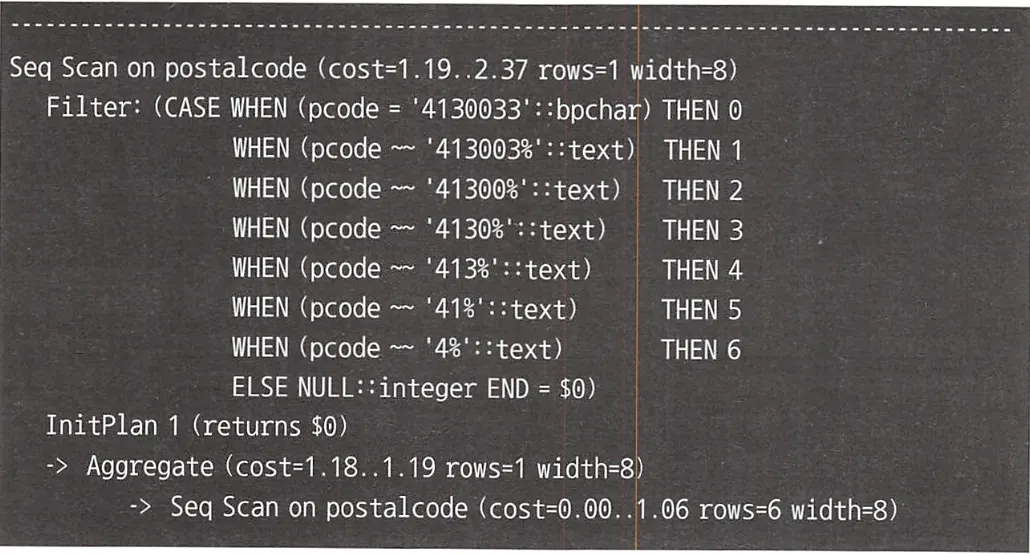
PostgreSQL 실행 계획

Oracle 실행 계획
위 실행 계획들을 보면 테이블 풀 스캔이 2번 발생하는 것을 알 수 있다. 이는 순위의 최소값을 서브 쿼리에서 찾은 후 그에 따라 다시 테이블에서 값을 가져오기 때문이다. 윈도우 함수를 사용하여 스캔 횟수를 줄일 수 있다.
SELECT pcode, district_name
FROM (SELECT pcode, district_name,
CASE WHEN pcode = '4130033' THEN 0
WHEN pcode = '413003%' THEN 1
WHEN pcode = '41300%' THEN 2
WHEN pcode = '4130%' THEN 3
WHEN pcode = '413%' THEN 4
WHEN pcode = '41%' THEN 5
WHEN pcode = '4%' THEN 6
ELSE NULL END AS hit_code,
MIN(CASE WHEN pcode = '4130033' THEN 0
WHEN pcode = '413003%' THEN 1
WHEN pcode = '41300%' THEN 2
WHEN pcode = '4130%' THEN 3
WHEN pcode = '413%' THEN 4
WHEN pcode = '41%' THEN 5
WHEN pcode = '4%' THEN 6
ELSE NULL END)
OVER(ORDER BY CASE WHEN pcode = '413003' THEN 0
WHEN pcode = '413003%' THEN 1
WHEN pcode = '41300%' THEN 2
WHEN pcode = '4130%' THEN 3
WHEN pcode = '413%' THEN 4
WHEN pcode = '41%' THEN 5
WHEN pcode = '4%' THEN 6
ELSE NULL END) AS min_code
FROM PostalCode) Foo
WHERE hit_code = min_code;
SQL
복사

PostgreSQL 실행 계획

Oracle 실행 계획
실행 계획을 보면 테이블 풀 스캔이 1번으로 줄고, 정렬이 추가로 사용된다. 정렬에 따른 비용이 있지만, 테이블의 크기가 커질수록 테이블 풀 스캔을 줄이는 것의 효과가 더 크다.
반복 횟수가 정해지지 않은 경우
위의 우편 번호처럼 최대 분기(반복) 횟수가 정해져있는 경우에는 SQL 구문에 코드를 하나씩 입력하여 반복을 분기로 변경하는 것이 가능하다.
반복 횟수가 정해지지 않은 경우에는 계층 구조를 통해 이를 표현할 수 있다. SQL에서 계층 구조를 나타내는 방법은 인접 리스트 모델과 중첩 집합 모델, 경로 열거 모델이 있다.
•
인접 리스트 모델
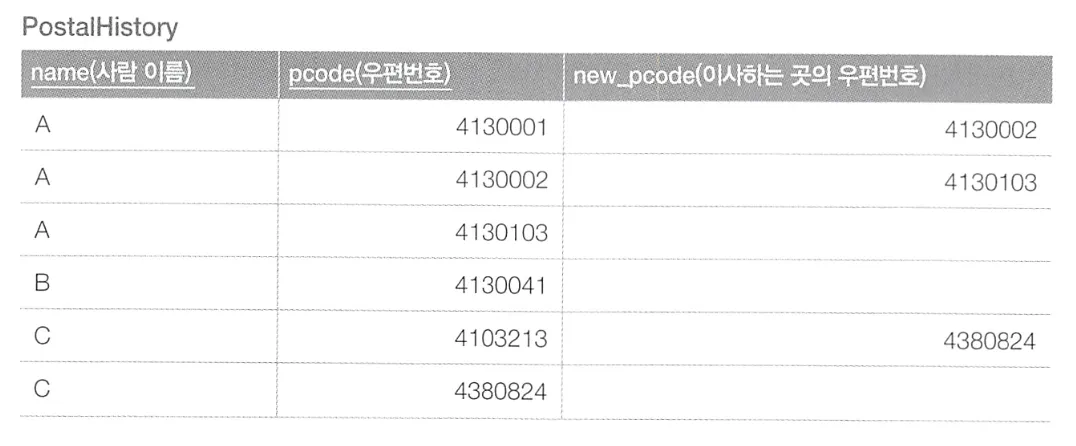
이와 같이 이사할 때마다 레코드가 추가되는 테이블이 있고, 이를 통해 이사 횟수나 가장 오래 전에 살았던 주소 등을 알 수 있다. 이처럼 키를 기준으로 데이터를 연결한 것을 포인터 체인이라 부르고, 포인터 체인을 사용하는 테이블 형식을 인접 리스트 모델이라 부른다.

가장 오래전 주소를 찾기 위해서는 현재 주소부터 반복해서 이전 주소를 찾아가야하고, 몇 번을 반복해야 가장 오래된 주소를 찾을 수 있는지 알 수 없다. SQL에서 이런 계층 구조를 찾는 방법 중 하나인 재귀 공통 테이블 식(recursion common table expression)을 사용하면 된다.

PostgreSQL

Oracle
재귀 공통 테이블 식 Explosion은 현재 주소(new_pcode 필드가 NULL인 레코드의 pcode)부터 포인터 체인을 타고 올라가 모든 과거의 주소를 찾는다. depth가 가장 큰 것이 가장 오래된 주소이므로, MAX(depth)를 통해 가장 오래된 주소를 선택한다.

PostgreSQL 실행 계획
Recursive Union이 재귀 연산을 의미하고, 위 SQL 쿼리는 이사를 여러 번 반복하더라도 대응할 수 있다는 점에서 유연하다. 중간의 WorkTable은 Explosion 뷰에 여러 번 접근하므로 일시 테이블로 만들었다는 것을 나타낸다. 인덱스 idx_new_pcode를 Nested Loops로 검색했다는 것을 알 수 있다.

Oracle 실행 계획
이처럼 Oracle에서도 PostgreSQL과 비슷한 실행 계획을 볼 수 있다.
재귀 공통 테이블 식을 통한 방법은 표준 SQL에 포함되어 있는 내용이라서 구현에 의존적이지 않다. 하지만 비교적 최근에 만들어진 기능으로 일부 DBMS에서는 만들지지 않거나 최적화 되어있지 않았을 수 있다.
•
중첩 집합 모델
중첩 집합 모델은 각 레코드의 데이터를 집합(원)으로 보고, 계층 구조를 집합의 중첩 관계로 나타낸다.
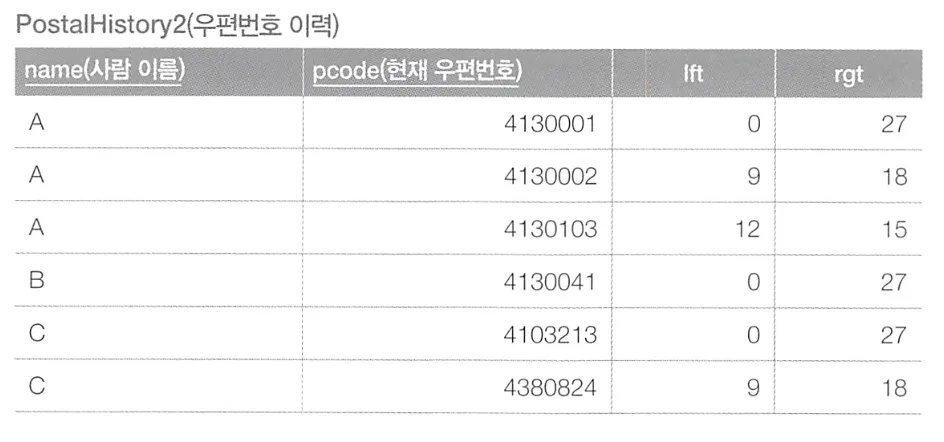
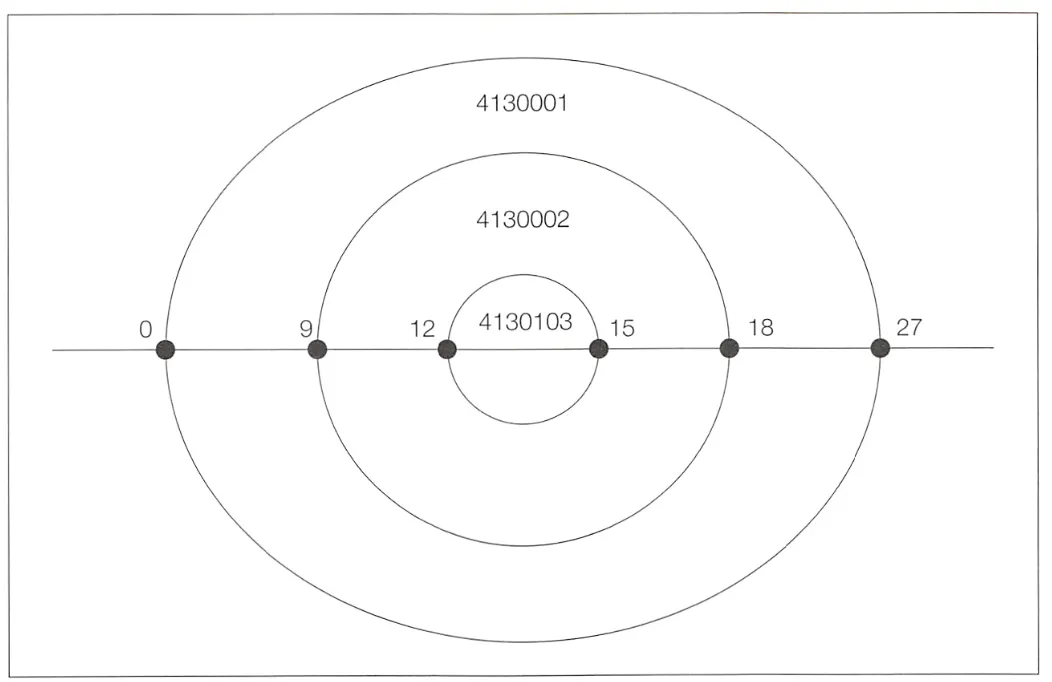
중첩 집합 모델에서는 lft와 rgt로 원의 좌측 좌표와 우측 좌표를 나타낸다. 좌표값은 대소 관계만 적절하다면 어떤 값이든 사용할 수 있다. 이를 통해 새로운 우편번호가 이전의 우편번호 원 내부에 존재하는 형태로 추가된다. 위는 A 사람의 주소들을 계층 구조로 표현한 것이다.
새로운 우편번호를 추가한다고 하면, 원의 좌측과 우측을 이어주는 선분을 3등분하여 새로 생긴 두 점을 새로운 좌측 좌표와 우측 좌표로 삼는다.
추가되는 좌측 좌표 = (lft * 2 + rgt) / 3
추가되는 우측 좌표 = (lft + rgt * 2) / 3
이 좌표들을 통해 굉장히 간단한 SQL 구문으로 가장 오래된 주소를 찾을 수 있다.
SELECT name, pcode, FROM PostalHistory2 PH1
WHERE name = 'A' AND NOT EXISTS
(SELECT * FROM PostalHistory2 PH2
WHERE PH2.name = 'A' AND PH1.lft > PH2.lft);
SQL
복사
가장 바깥 쪽의 원만 찾으면 되기 때문에 NOT EXISTS를 사용하여 이처럼 쉽게 구할 수 있다.

PostgreSQL 실행 계획
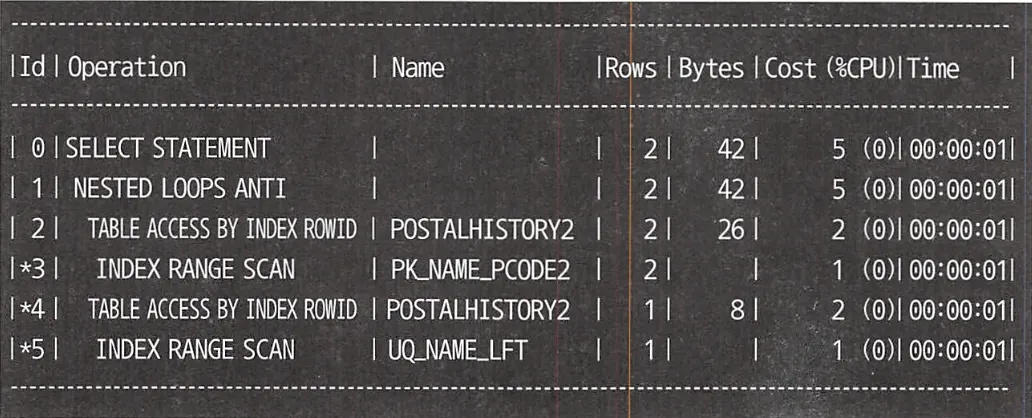
Oracle 실행 계획
두 실행 계획 모두 외측 테이블(PH1)과 내측 테이블(PH1)을 한 번만 Nested Loops로 결합한다. 위의 PostgreSQL 실행 계획은 테이블 풀 스캔이 수행되었지만, 레코드 수가 많아지면 인덱스 사용한 계획을 세우게 된다.
중첩 집합의 SQL 구문이 재귀 공통 테이블보다 빠를지는 쉽게 판단할 수 없지만, 중첩 집합은 엔티티 구조의 관점에서 문제를 해결할 수 있다.
•
경로 열거 모델
경로 열거 모델은 갱신이 거의 발생하지 않는 경우에 유효한 방식이다. 책에서는 예시와 맞지 않는다는 이유로 생략했다.