
집약
SQL에는 COUNT, SUM, AVG, MAX, MIN 5개의 집약 함수(aggregate function)이라 하는 함수들이 있다. 함수의 이름이 집약인 이유는 여러 개의 레코드를 중복을 제거해 한 개의 레코드로 압축하는 기능을 가지고 있기 때문이다. GROUP BY 구를 통해 이러한 집약 함수를 사용할 수 있다.
여러 개의 레코드를 하나로 집약하기
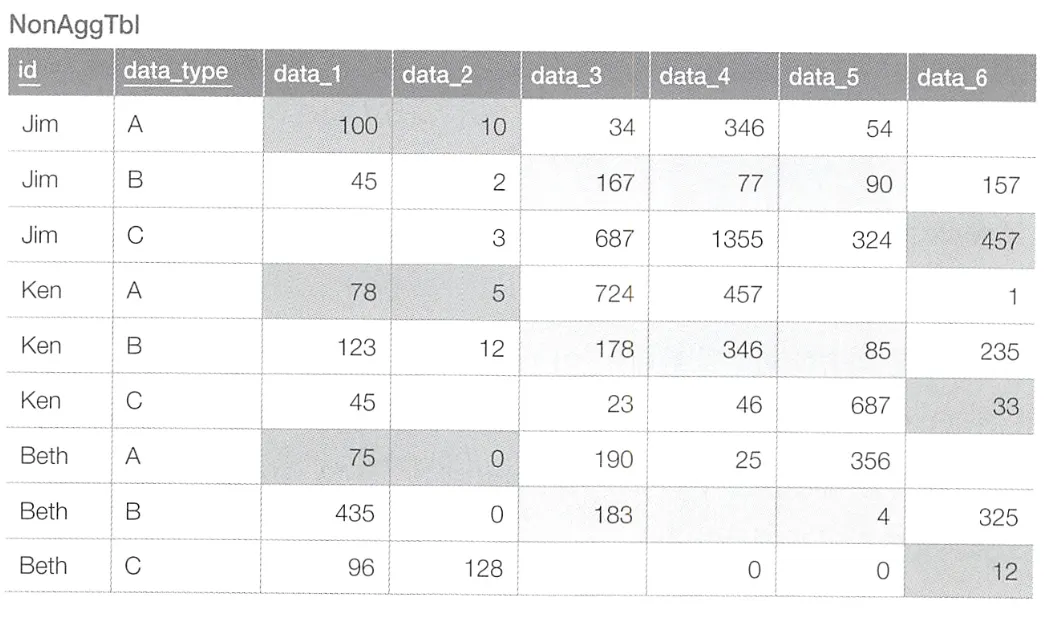
이와 같은 테이블이 있고 동일 id의 data_1과 data_2는 A 타입으로, data_3, data_4, data_5는 B 타입으로, data_6은 C 타입으로 데이터를 선택하여, id당 하나의 레코드를 집약하고자 한다.
Jim에 대한 레코드를 얻기 위해 각 타입별로 쿼리를 날려보면 다음과 같다.
SELECT id, data_1, data_2 FROM NonAggTbl
WHERE id = 'Jim' AND data_type = 'A';
SQL
복사

SELECT id, data_3, data_4, data_5 FROM NonAggTbl
WHERE id = 'Jim' AND data_type = 'B';
SQL
복사

SELECT id, data_6 FROM NonAggTbl
WHERE id = 'Jim' AND data_type = 'C';
SQL
복사

이는 쿼리 결과의 필드가 각각 달라서 UNION으로 집약하는 것이 불가능하다. 또한 UINON은 성능적으로 안티 패턴임으로 가급적 사용하지 않는 것이 좋다.
만약 이를 CASE 식을 사용해 쿼리를 만들면 아래와 같이 작성하게 될 것이다.
SELECT id,
CASE WHEN data_type = 'A' THEN data_1 ELSE NULL END AS data_1,
CASE WHEN data_type = 'A' THEN data_2 ELSE NULL END AS data_2,
CASE WHEN data_type = 'B' THEN data_3 ELSE NULL END AS data_3,
CASE WHEN data_type = 'B' THEN data_4 ELSE NULL END AS data_4,
CASE WHEN data_type = 'B' THEN data_5 ELSE NULL END AS data_5,
CASE WHEN data_type = 'C' THEN data_6 ELSE NULL END AS data_6,
FROM NonAggTbl GROUP BY id;
SQL
복사
하지만 이 쿼리는 대부분 DBMS에서 오류가 발생한다. GROUP BY 구로 집약할 때 SELECT에 올 수 있는 것은 상수, 집약 키, 집약 함수 세 가지 밖에 사용하지 못한다.
따라서 아래와 같이 내부에 있는 하나의 요소를 선택할 수 있는 MAX 함수를 사용하여 작성해야한다.
SELECT id,
MAX(CASE WHEN data_type = 'A' THEN data_1 ELSE NULL END) AS data_1,
MAX(CASE WHEN data_type = 'A' THEN data_2 ELSE NULL END) AS data_2,
MAX(CASE WHEN data_type = 'B' THEN data_3 ELSE NULL END) AS data_3,
MAX(CASE WHEN data_type = 'B' THEN data_4 ELSE NULL END) AS data_4,
MAX(CASE WHEN data_type = 'B' THEN data_5 ELSE NULL END) AS data_5,
MAX(CASE WHEN data_type = 'C' THEN data_6 ELSE NULL END) AS data_6,
FROM NonAggTbl GROUP BY id;
SQL
복사

위 집약 SQL 구문의 실행 계획은 다음과 같다.

PostgreSQL 실행 계획

Oracle 실행 계획
둘 모두 테이블 풀 스캔으로 GROUP BY로 집약 수행하고, 해시 알고리즘을 사용한다. 해시가 고전적인 정렬보다 빠르므로, 최근에는 GROUP BY를 사용하는 집약에서 정렬보다 해시를 사용하는 경우가 많다. 특히 GROUP BY의 유일성이 높으면 해시의 효율이 높아진다.
문제는 정렬과 해시 모두 메모리를 많이 사용하기 때문에 워킹 메모리가 부족하면 스왑이 발생하고, TEMP 탈락이라 불리는 이 현상으로 인해 성능이 굉장히 느려지게 된다.
집약 함수 예시 문제들
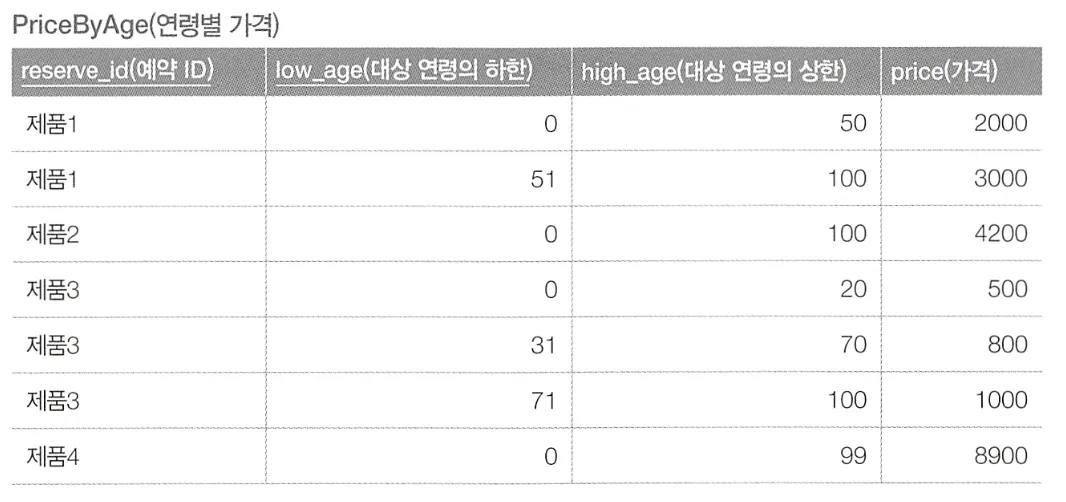
이와 같은 테이블이 있고, 0~100세까지 모든 연령이 가지고 놀 수 있는 제품을 골라서 선택하고 싶다.
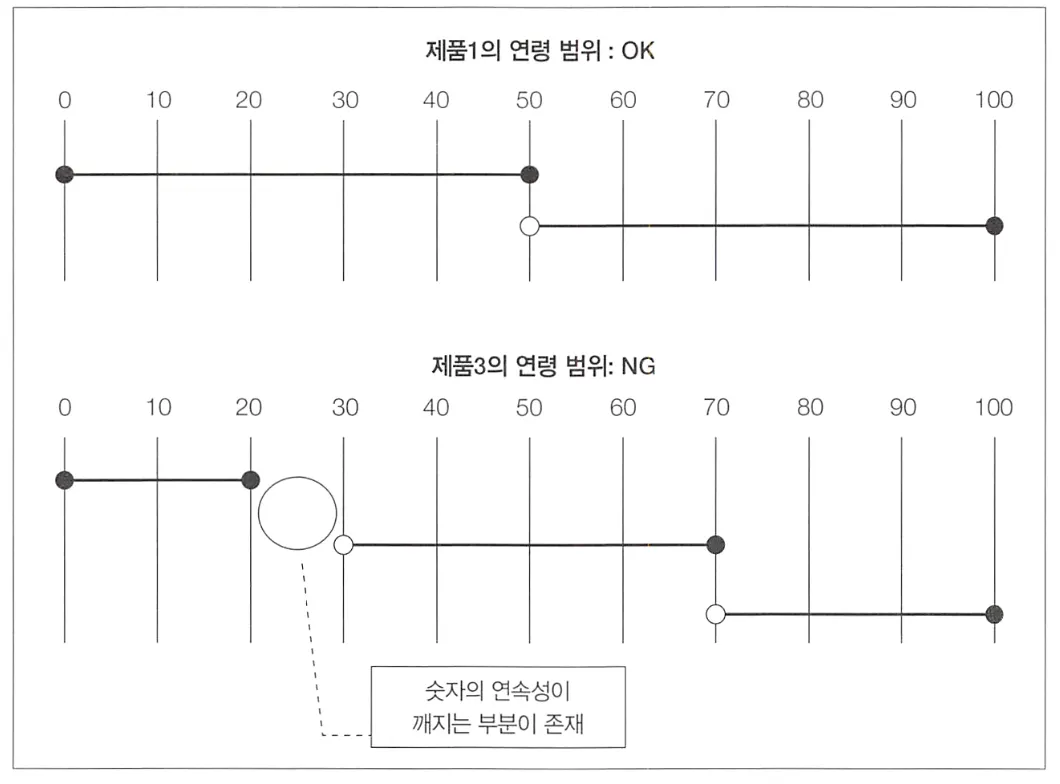
이처럼 제품 1은 두 개의 레코드로 나누어져 있지만, 0~100세까지의 모든 연령을 커버할 수 있다. 반면 제품 3은 커버하지 못하는 연령대가 있기 때문에 위 조건을 만족하지 못한다.
이 문제의 정답 SQL 구문은 다음과 같다.
SELECT product_id FROM PriceByAge
GROUP BY product_id
HAVING SUM(high_age - low_age + 1) = 101;
SQL
복사

HAVING 구에서 집약 함수를 통해, GROUP BY가 product_id로 지정된 레코드들에서 high_age - low_age + 1을 집약 함수(SUM)를 통해 작성했다.
아래는 또 다른 예시 문제이다.
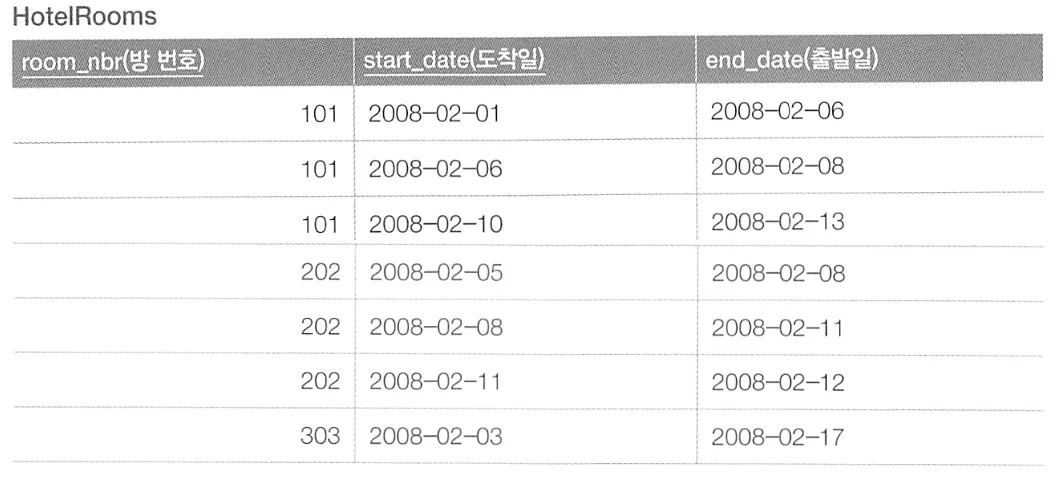
이러한 테이블이 있을 때, 사람들이 숙박한 날이 10일 이상인 방을 선택하고자 한다.
SELECT room_nbr FROM HotelRooms
GROUP BY room_nbr
HAVING SUM(end_date - start_date) >= 10;
SQL
복사

이 역시 위와 유사한 문제로 HAVING 구에 집약 함수로 조건을 걸어 해결한다.
자르기
파티션
GROUP BY에는 집약 기능 말고도 자르기 기능이 있다.
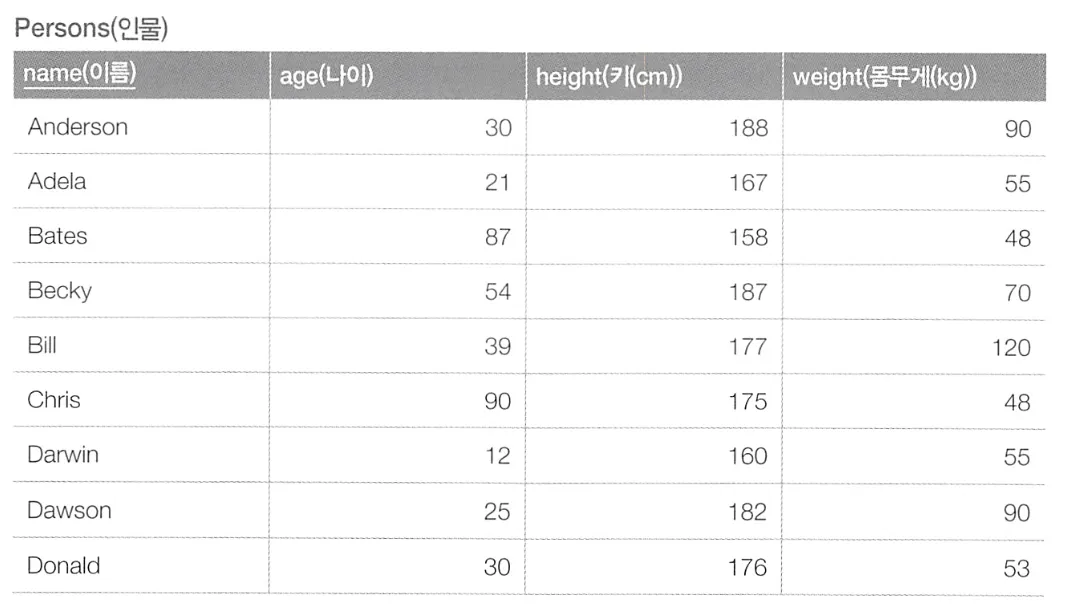
이와 같은 테이블이 있고, 아래와 같이 이름의 첫 글자 기준으로 해당 글자로 시작하는 사람의 수를 구하고자 한다.
이를 구하는 SQL 구문은 다음과 같다.
SELECT SUBSTRING(name, 1, 1) AS label,
COUNT(*)
FROM Persons GROUP BY SUBSTRING(name, 1, 1);
SQL
복사

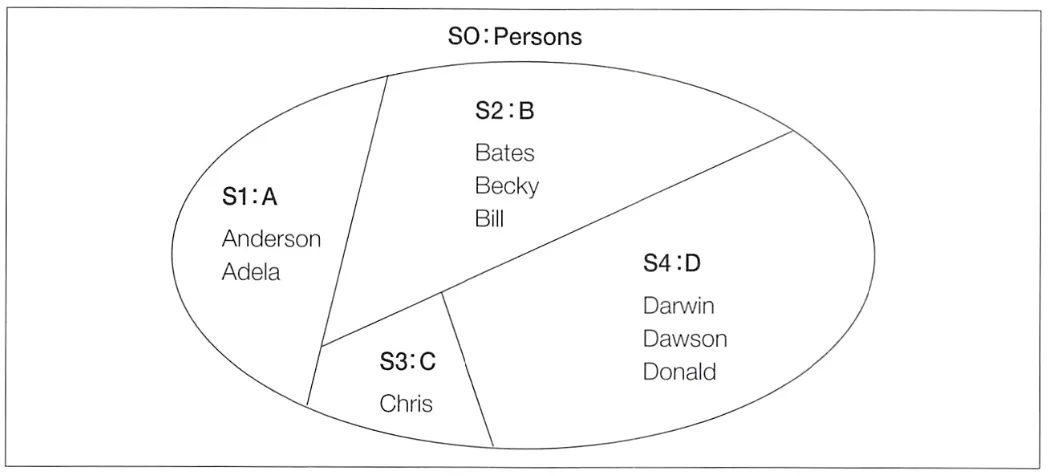
이렇게 GROUP BY 구로 잘라 만든 부분 집합 하나하나를 파티션(partition)이라 부른다. 파티션은 서로 중복되는 요소를 가지지 않는 부분 집합이다.
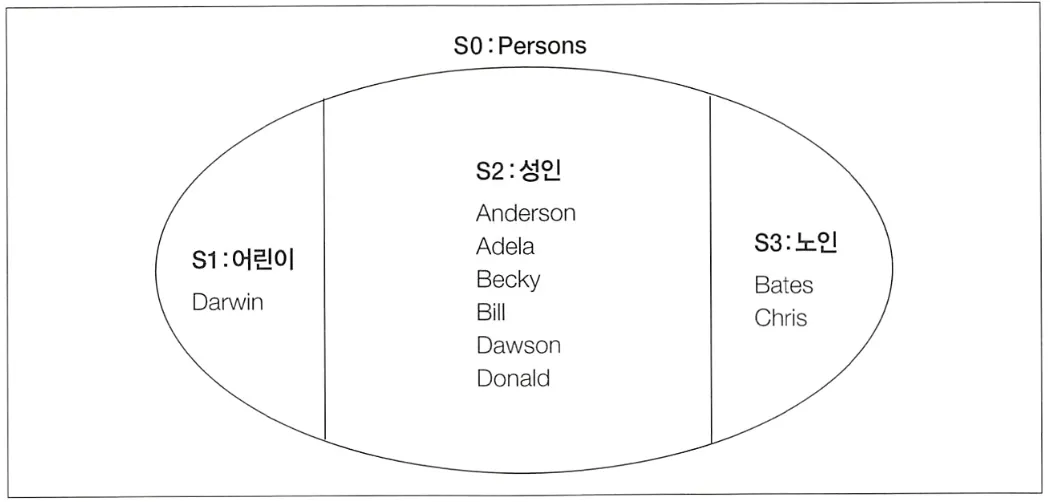
위의 테이블에서 이와 같이 나이를 기준으로 파티션을 다시 나누는 SQL 구문은 다음과 같다.
SELECT CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >= 70 THEN '노인'
ELSE NULL END AS age_class,
COUNT(*)
FROM Persons
GROUP BY CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >= 70 THEN '노인'
ELSE NULL END;
SQL
복사

자르기의 기준이 되는 키를 GROUP BY 구와 SELECET 구 모두에 입력하는 것이 핵심이다. 위의 CASE 식 대신 SELECT 구에 AS로 라벨링한 age_class라는 별칭을 사용해 아래처럼 간단하게 작성할 수도 있다.
SELECT CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >= 70 THEN '노인'
ELSE NULL END AS age_class,
COUNT(*)
FROM Persons
GROUP BY age_class;
SQL
복사

실행 계획을 살펴보면, GROUP BY 구에서 CASE 식이나 함수를 사용해도 실행 계획에는 딱히 영향이 없다는 것을 확인할 수 있다.
PARTITION BY 구
이전 장에서 GROUP BY 구에서 집약 기능을 제외하고 자르기 기능만 남긴 것이 PARTITION BY 구라고 언급했었다. 다시 말해, PARTITON BY 구를 사용해도 필드 이름 뿐만 아니라 CASE 식이나 계산 식에 적용할 수 있다.
SELECT name, age,
CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >= 70 THEN '노인'
ELSE NULL END AS age_class,
RANK() OVER(PARTITION BY CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >= 70 THEN '노인'
ELSE NULL END
ORDER BY age) AS age_rank_in_class;
SQL
복사
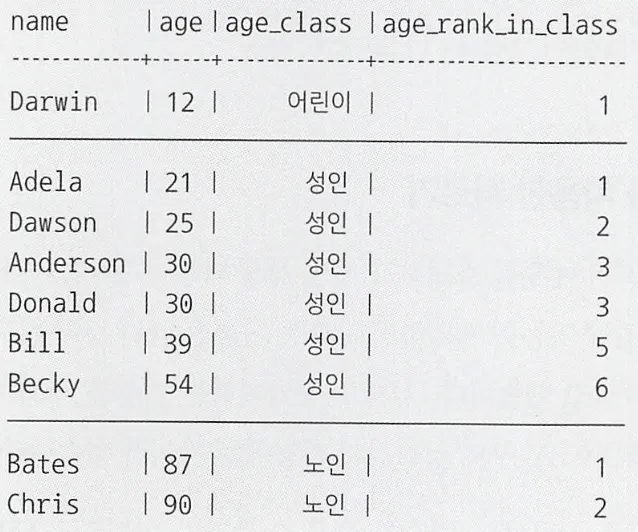
이와 같이 PARTITION BY 구를 적용해 각 그룹마다 RANK를 구하는 것도 가능하다. GROUP BY 구는 집약 기능이 없기 때문에 테이블의 레코드가 위와 같이 원본 테이블 정보를 유지하며 출력된다.