

우아콘 따라잡기
다른 사람의 추천으로 우아콘 발표 영상을 보게 되었다.


위 발표를 보면, 배달의 민족에서 어떤 문제를 겪었고 어떤 고민을 했고 어떻게 해결 했는지를 논리정연하게 설명하고 있다. 이를 보면서 배달의 민족의 문제와 해결 과정을 정리해보고, 부족한 개념을 공부하고 더 나아가 내가 사용해 볼 수 있는 여지는 없는지 고민해보고자 한다.
관련 개념 정리
Scale-up vs Scale-out

CQRS

MSA

API Composition

Sharding

Transactional Outbox Pattern

영상 내용
배민의 고민사항
영상에서 나온 배달의 민족에서 5년간 고민하고 해결했던 문제들은 총 4가지를 언급한다.
1.
배민 애플리케이션은 가게, 메뉴, 주문, 결제, 배달 등 여러 시스템이 서로 통신하여 요청을 처리하는데, 이러한 여러 시스템 중 하나의 시스템에서 장애가 발생하면 다른 시스템들도 사용할 수 없게 된다. 이를 개선하기 위해 단일 장애가 다른 시스템으로 전파되지 않도록 시스템 간의 느슨한 결합을 가져가기 위해 고민한다.
2.
배달의 민족이 성장함에 따라 주문량도 꾸준하게 늘어, 일 평균 300만 건의 주문이 발생하여 방대한 데이터를 저장해야 하는 상황에서 어떻게 잘 저장하고 조회 성능도 보장할 수 있을까에 대해 고민한다.
3.
음식 배달이라는 애플리케이션 서비스 특성상 12시와 18시에 트랜잭션이 과도하게 몰리게 되는데, 이런 대규모 트랜잭션을 어떻게 잘 처리할 수 있을까에 대해 고민한다.
4.
여러 시스템 간 연계하여 통신하는 배민 애플리케이션 특성상 MSA를 적용하여 이벤트 기반 통신을 한다. 주문 시스템이 이벤트를 발행하여 여러 시스템들과 통신하는데, 이벤트 유실 시 재생 방안이나 이벤트 흐름의 가시화, 이벤트 간에 잘 통신하기 위해 고민한다. 또한 이벤트 발행에 대한 일관성 유지나 이벤트 아키텍처를 단순화하기 위해 고민한다.
이런 문제들에 대해 배달의 민족에서는 어떤 방식들을 고민했고, 어떻게 해결했는지 알아보자.
1. 단일 장애 포인트
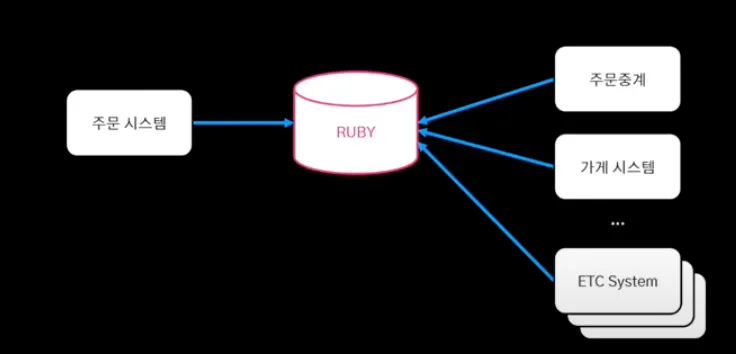
배달의 민족은 중앙 집중 DB 구조를 가지고 있는데, 이런 구조로 인해 DB의 장애가 전체 시스템의 장애로 전파된다. 이와 같이 단일 장애가 시스템 전체로 전파되는 상황으로 인해, 단일 집중 DB를 버리고 각 시스템 별로 DB를 구축하는 탈루비 프로젝트를 진행했다.
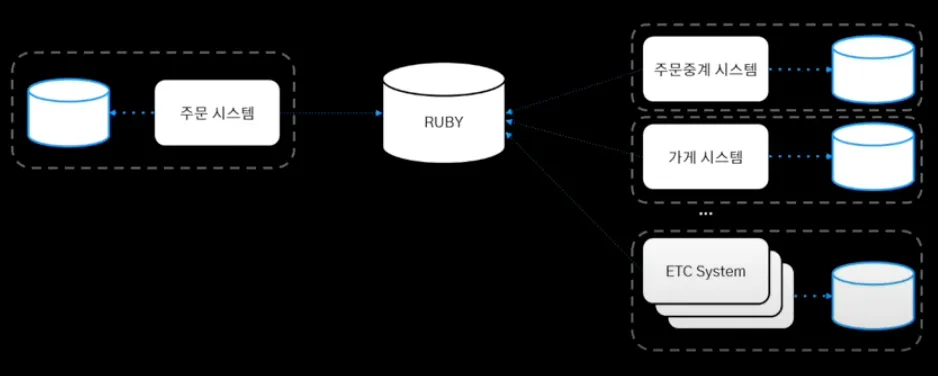
이와 같이 시스템 별 별도의 저장소 구축하고,
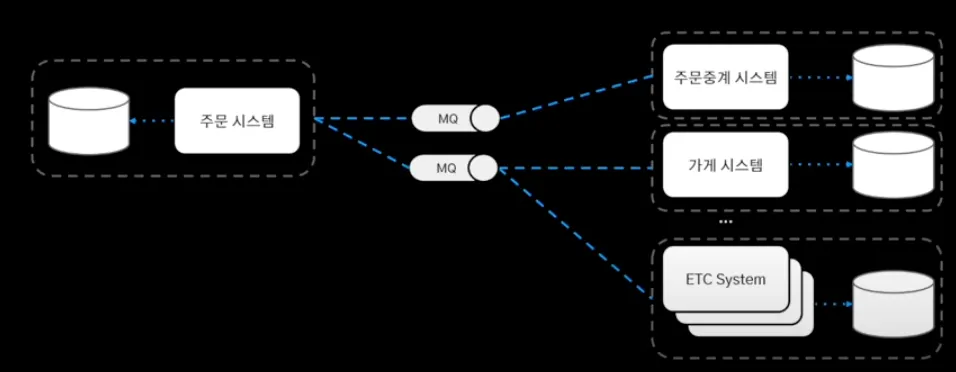
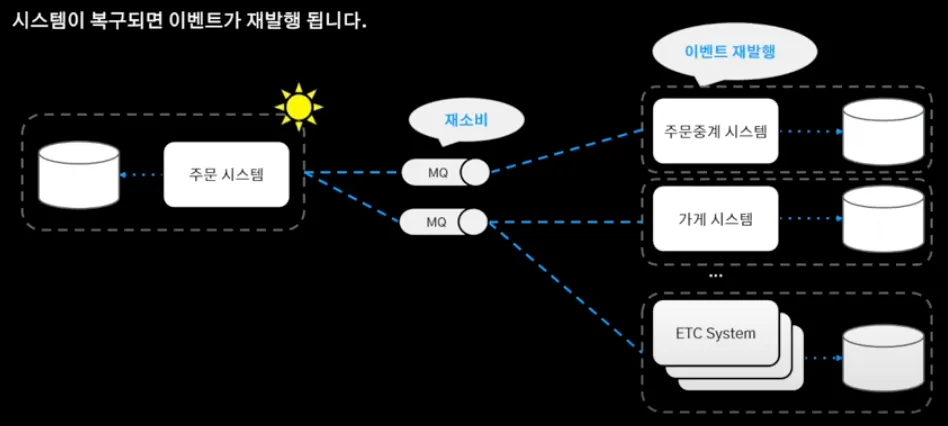
시스템 간의 결합을 느슨하게 하기 위해 메세지 큐 기반의 통신을 도입하여 MSA의 기반을 구축했다. 장애 발생하면 메세지 큐의 이벤트 재소비를 통해 이벤트 재발행하여 서비스 안정화했다.
2. 대용량 데이터
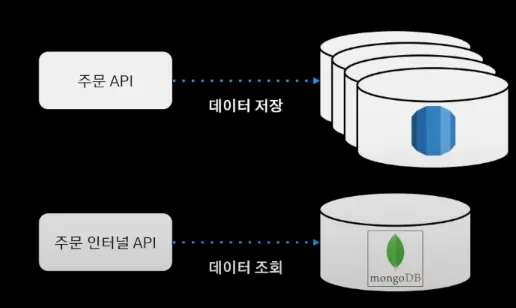
배달의 민족 주문 시스템의 구조와 흐름은 다음과 같다.
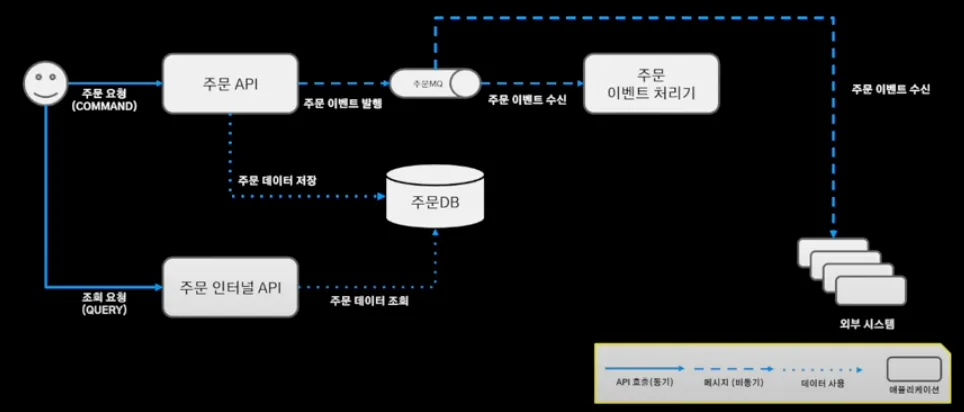
1.
주문 인터널 API가 주문 정보가 필요한 서비스에 필요한 주문 데이터를 제공
2.
주문 요청
3.
주문 API를 통해 주문 데이터 DB에 저장 + 주문 이벤트 발행(MQ)
4.
주문 이벤트 처리기는 주문 시스템과 별개로 움직이기 위해 메세지 큐의 발행된 이벤트를 바라보며 주문 이벤트 수신
5.
주문 처리기에서 필요한 외부 시스템의 이벤트를 발행
6.
해당 이벤트를 구독한 외부 시스템에서 이벤트를 처리
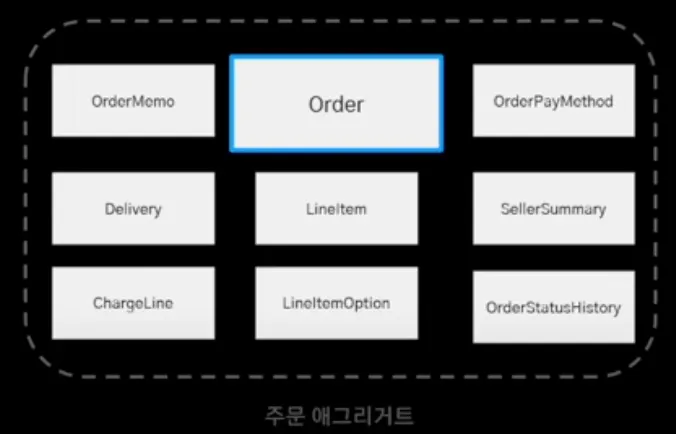
주문을 위해서는 주문 애그리거트의 주문 정보, 메뉴 정보, 결제 정보, 배달 정보 등 많은 정보가 필요한데,
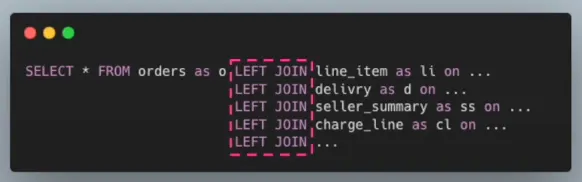
때문에 이와 같이 다수의 JOIN 연산 필요했다. 하지만 정규화된 주문 DB에서 저장과 조회과 함께 발생하기 때문에, 일 평균 300만 건의 대규모 데이터가 주문 DB에 저장되어 조회 시 JOIN 연산으로 인해 성능이 저하되었다.
조회 성능을 높이기 위해 역정규화를 통한 모델링 진행하여,
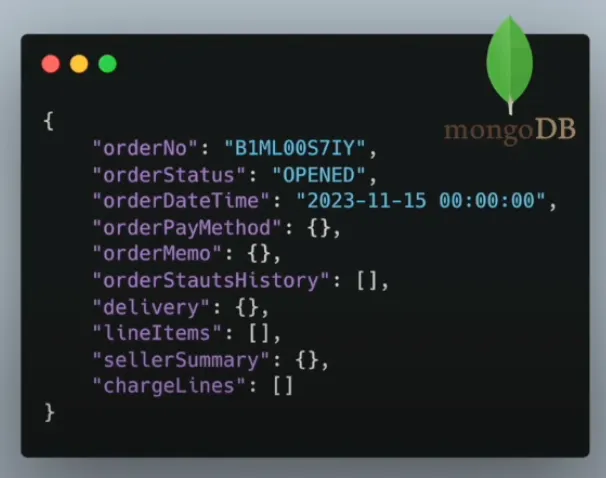
mongoDB에 싱글 도큐먼트로 구성하였다.

이를 통해 단순 id 기반의 조회 연산으로 성능을 극대화할 수 있었다.
데이터 동기화의 경우에는
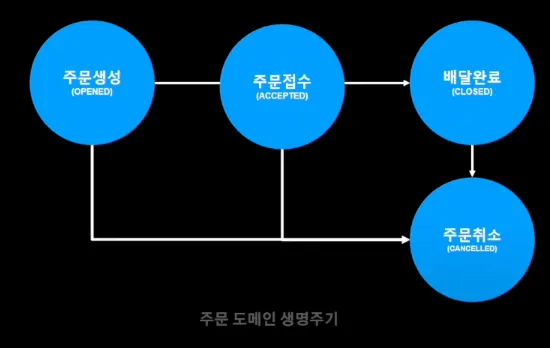
주문 도메인 데이터의 경우 주문 도메인 생명주기 내에서만 데이터의 변화가 발생한다는 점에 주목하여, 주문 이벤트 처리기에서 동기화를 진행하였다.
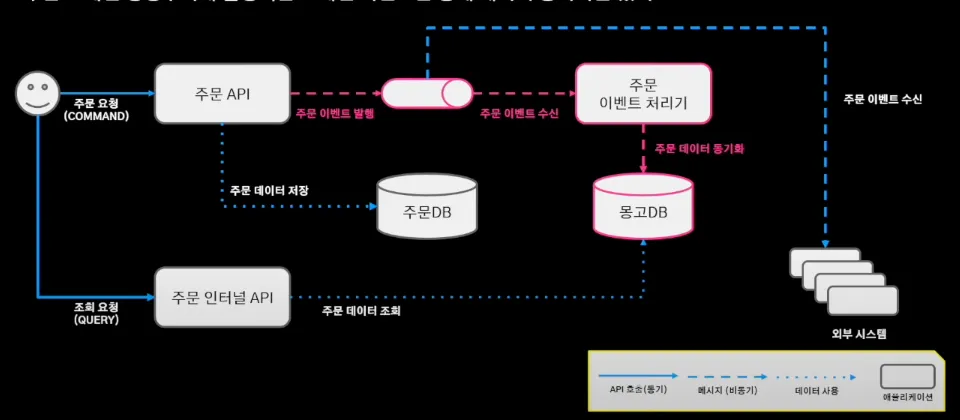
이와 같이 저장과 조회를 분리한 CQRS 패턴으로 조회 성능을 개선했다.
3. 대규모 트랜잭션
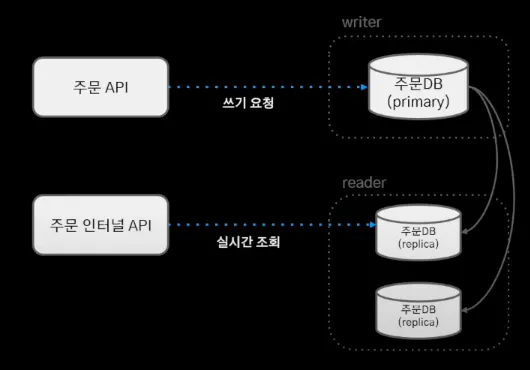
기존의 주문 시스템 DB는 위와 같이 HA 구성 되어있다.
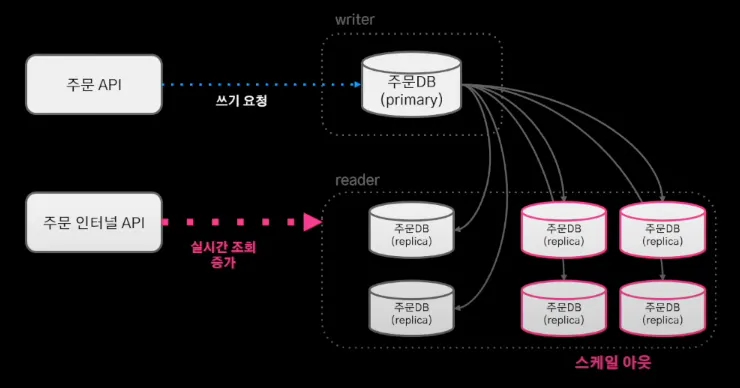
이런 구조에서는 실시간 조회가 증가하는 상황에서 replica DB를 스케일 아웃함으로써 대응하는 것이 가능하다.
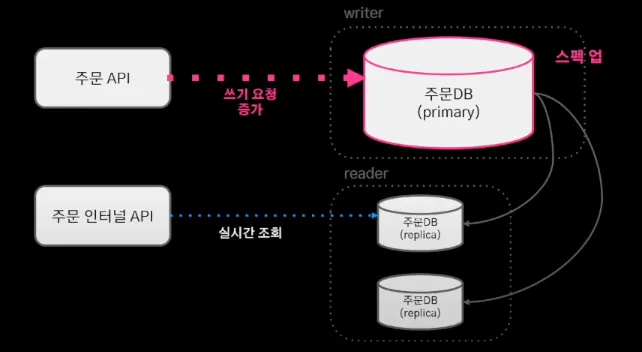
하지만 실시간 쓰기 요청의 증가하는 상황에는 스케일 업으로 밖에 대응할 수 없었다. 지속적인 스케일 업으로 AWS의 최고 스펙을 사용했지만, 요청의 누적으로 스케일 업의 한계에 도달했다.
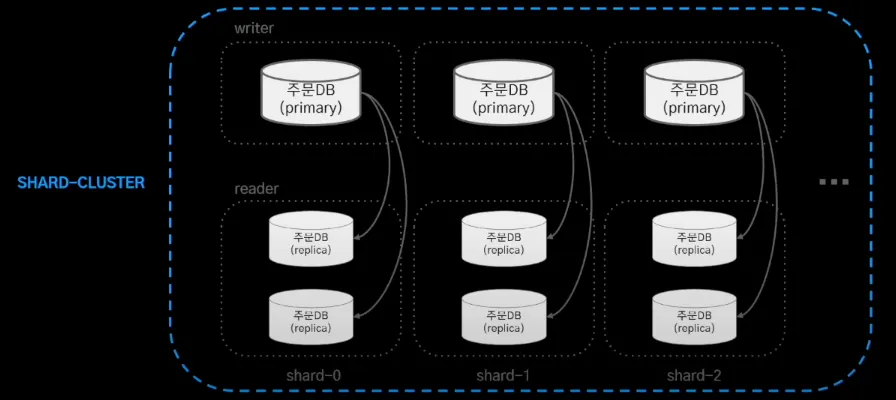
이에 대한 해결책으로 샤드 클러스터를 구성하여 쓰기 부하를 분산하고자 시도하였지만, Amazon Aurora는 샤딩을 지원 하지 않았다. 이에 코딩을 통한 애플리케이션 샤딩을 구현하기로 결정했다. 그에 따라 다음 두 가지 고민을 하게 되었다.
1.
어떤 샤딩 전략을 사용할 지에 대한 고민
2.
여러 샤드의 데이터를 애그리게이트 하는 방법에 대한 고민
먼저 샤딩 전략에는 세 가지 대표적인 전략이 있다.
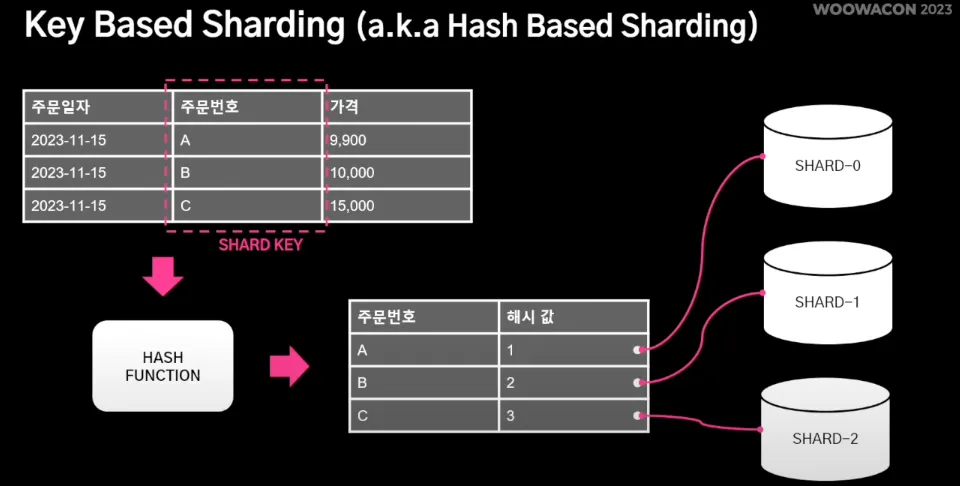
1.
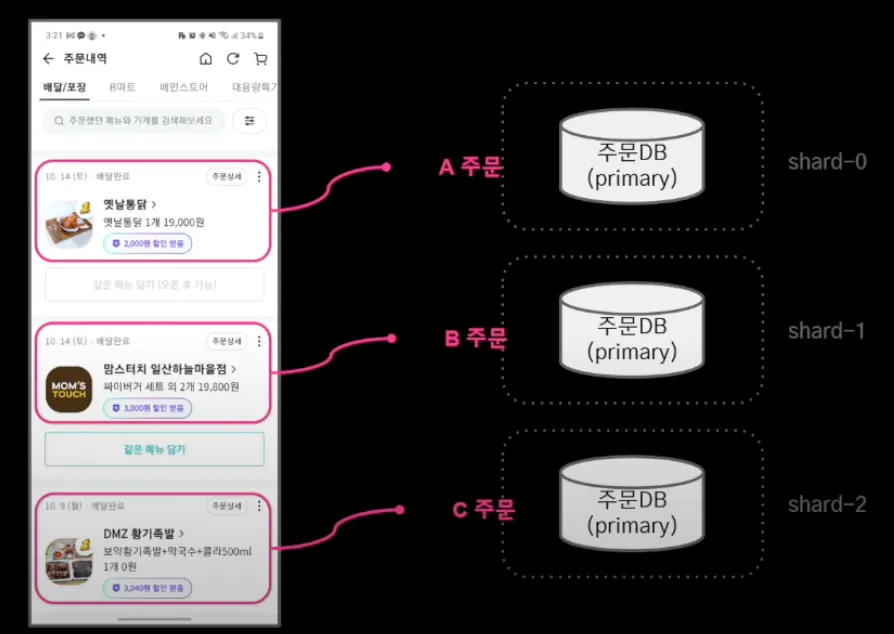
Key Based Sharding : Shard key를 이용해 데이터 소스를 결정하는 방식으로, 주문 DB의 주문번호를 해시 함수에 넣어 데이터 소스 결정한다.
이 방법의 장점으로는 구현이 간단하고, 해시 함수를 잘 구현하면 데이터를 골고루 분배할 수 있다는 것이다.
반면, 단점으로는 장비를 동적으로 추가 및 제거할 때 데이터 재배치 및 해시 함수 수정 필요하다는 것이다.
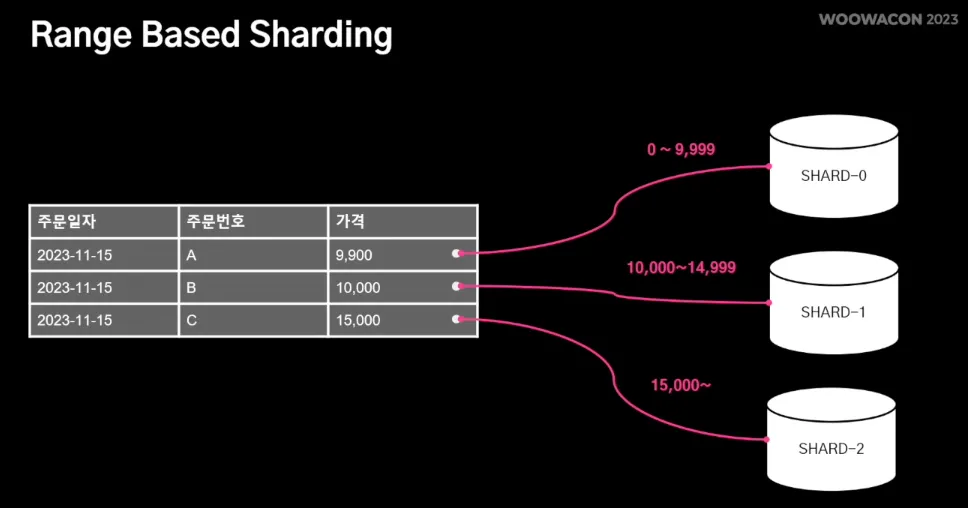
2.
Range Based Sharding : 값의 범위(Range) 기반으로 데이터를 분산하여 데이터 소스를 결정하는 방식으로, 주문의 가격 기반으로 데이터 소스 결정한다.
이 방식은 구현이 간단하지만, 데이터가 균등하게 분배되지 않음으로 인해 Hotspot이 되어 성능 저하 발생할 수 있다.
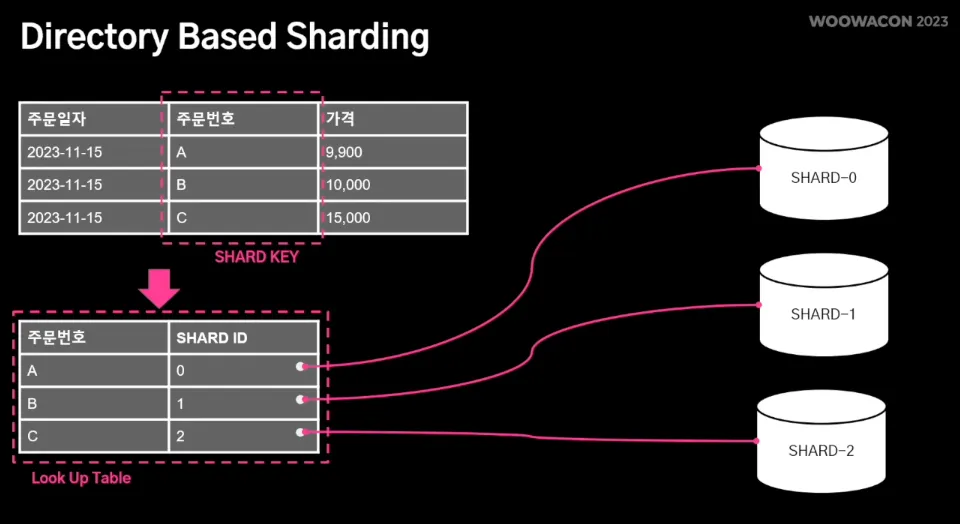
3.
Diretory Based Sharding : lookup table을 통해 매핑으로 데이터 소스를 확인하는 방식으로, look up table을 유지하여 데이터 소스 결정한다.
이 방식은 샤드 결정 로직이 look up table로 분리되어 있어 동적으로 샤드를 추가하는데 유리하다. 하지만 look up table을 통해서만 샤드를 결정하므로 look up table 자체가 단일 장애 포인트가 될 수 있다.
배달의 민족 주문 시스템 특징은 주문이 정상 동작하지 않으면, 서비스 전체의 좋지 않은 경험으로 이어진다. 또한 주문 변경은 주문 이후 최대 30일 동안만 가능하기 때문에, 동적 주문 데이터는 최대 30일만 저장한다는 것이다. 거기에 더해 음식 배달이라는 애플리케이션 특성상 주문 하루 내에 데이터 저장이 완료된다.
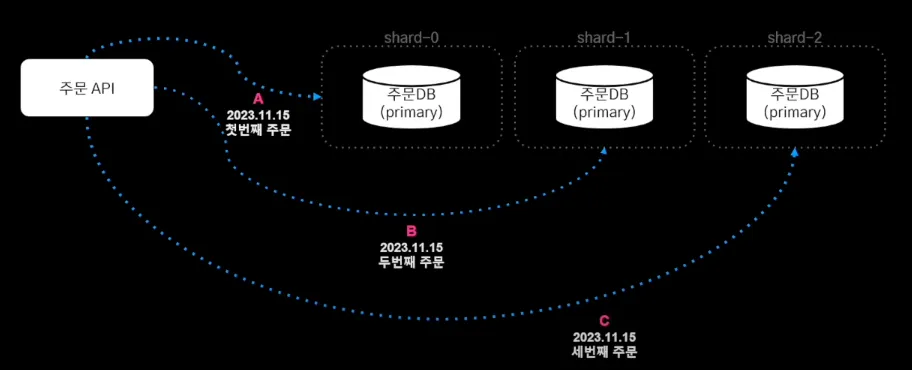
이러한 주문 시스템의 특성을 고려하여, 단일 장애 포인트 피하고 샤드 추가 이후 30일이 지나면 데이터는 다시 균등하게 분배될 것을 예상하여 Key Bash Sharding 전략을 사용하기로 결정했다. 샤드를 결정하는 공식은 주문 번호 % 사드 수 = 샤드 번호이다.
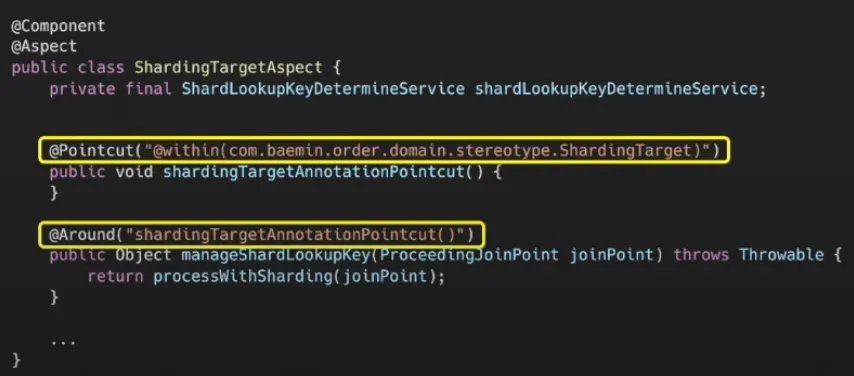
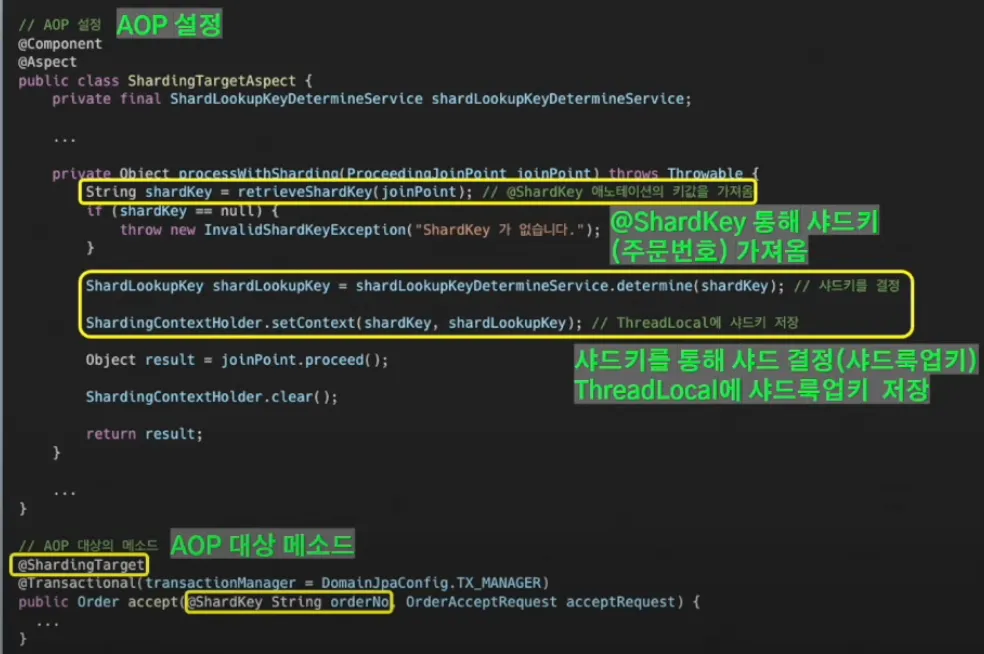
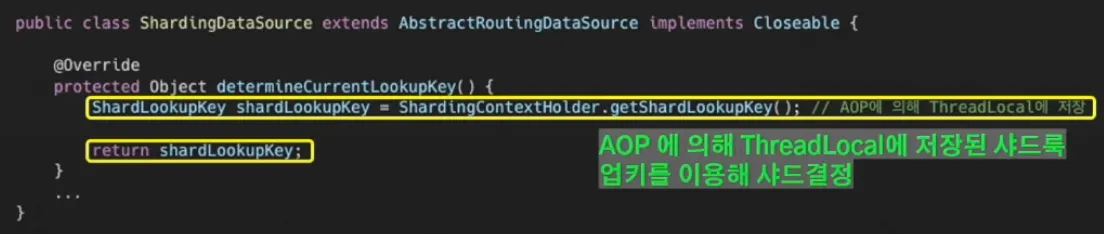
샤딩 구현은 AOP와 AbstractRoutingDataSource로 구현하였다.
다건 조회 애그리거트의 경우에는 시간 순서 조회 필요한데,
CQRS를 통해 조회성 데이터는 mongoDB에 저장해두었기 때문에 유연하게 처리할 수 있었다.
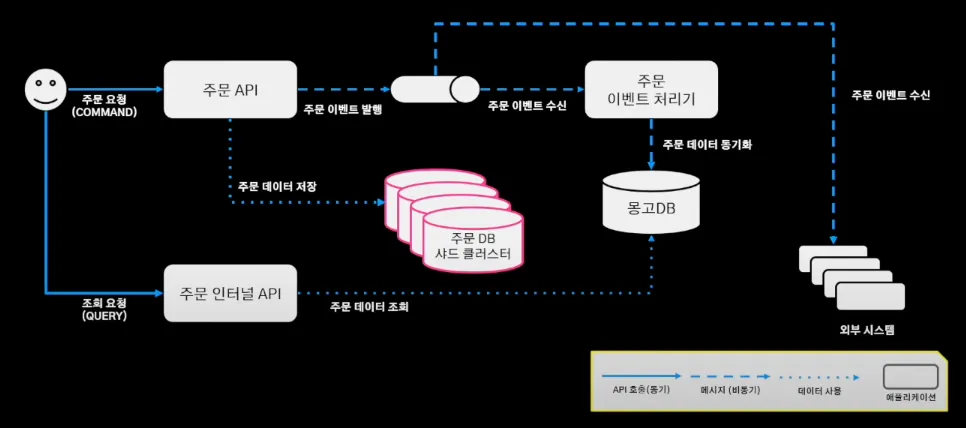
주문 시스템의 전체 흐름은 이와 같고,
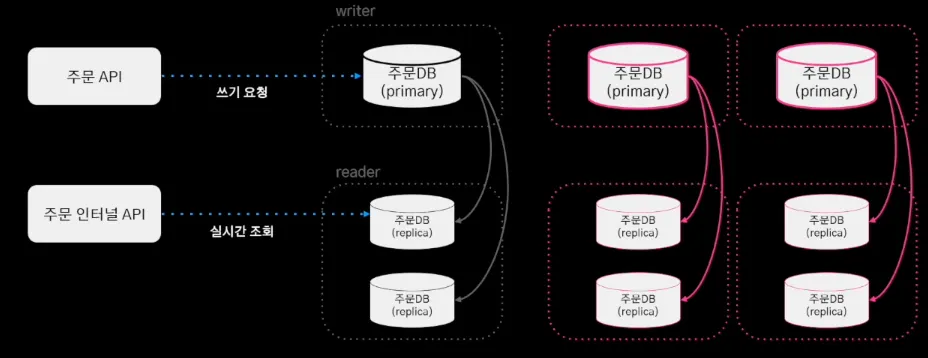
이를 통해 쓰기 요청 증가에 스케일 아웃으로 대응할 수 있게 되었다.
4. 복잡한 이벤트 아키텍처
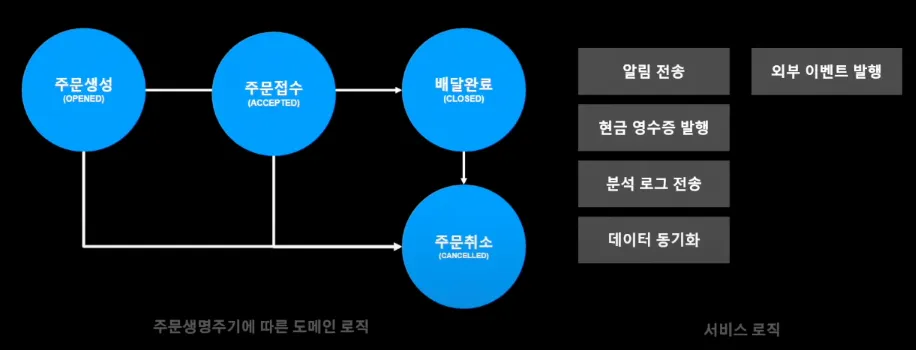
주문 시스템의 경우 이벤트 기반으로 관심사가 분리되어 있었다.
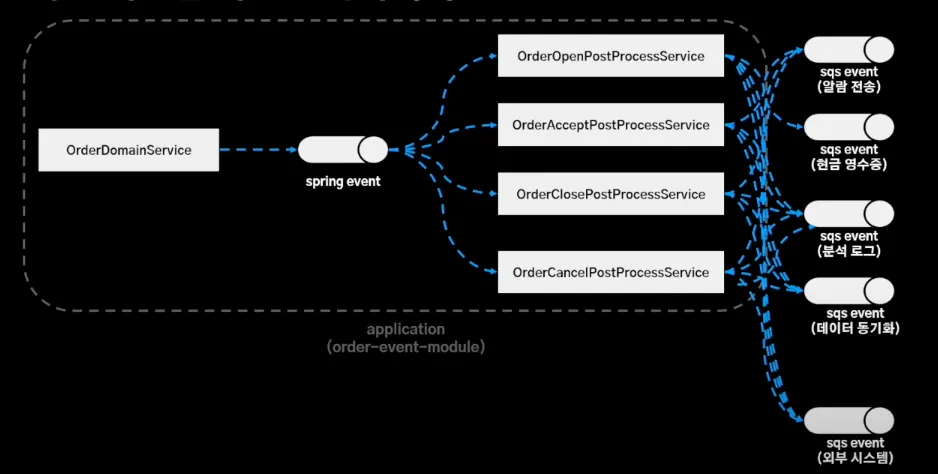
주문을 받게 되면 Spring 이벤트로 발행하여 PostProcessService 레이어가 로직 수행했다.
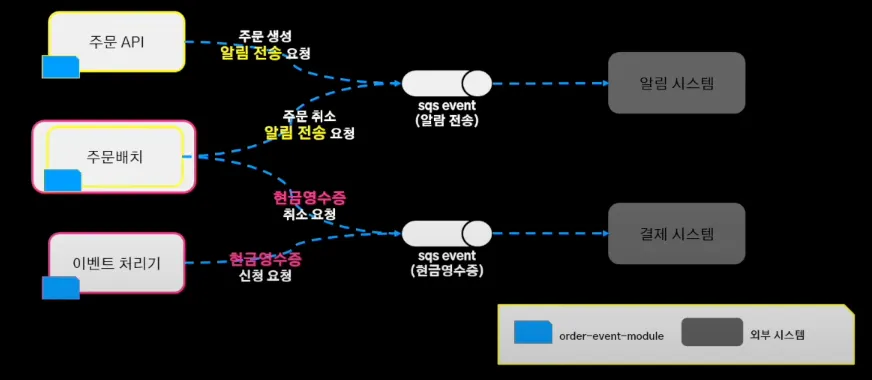
주문 시스템 관점에서 보면 알림 전송의 노란색 라인과 현금 영수증 발행의 분홍색 라인이 각각 로직 수행했다. 이로 인해 스프링 애플리케이션 이벤트는 서비스 주체를 파악하기 어렵기도 하고, 특정 서버에서만 이벤트를 놓쳐 해당 서버에서만 이벤트가 처리되지 않는 이슈 발생하기도 했다.
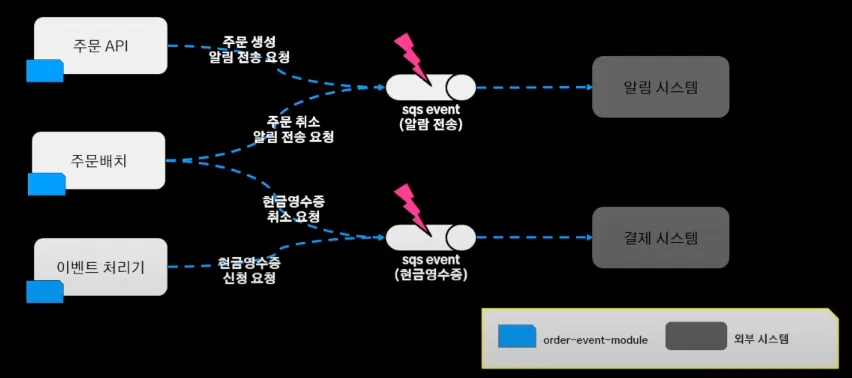
이렇게 이벤트를 유실하더라도, 스프링 이벤트에 의존하다보니 유실된 이벤트를 재처리 하기가 어렵다는 문제가 있었다.
이를 해결하기 위해 내부 이벤트와 외부 이벤트를 정리하여,
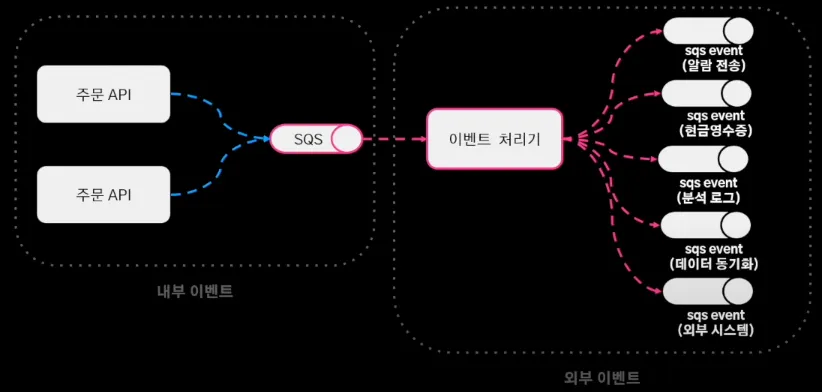
이처럼 주문 도메인 이벤트는 내부 이벤트로 정의하고 서비스 로직은 외부 이벤트로 정의하였다. 여기에 SQS를 구독하는 이벤트 처리기가 이벤트를 받아 외부 이벤트를 발행하는 구조로 변경했다.
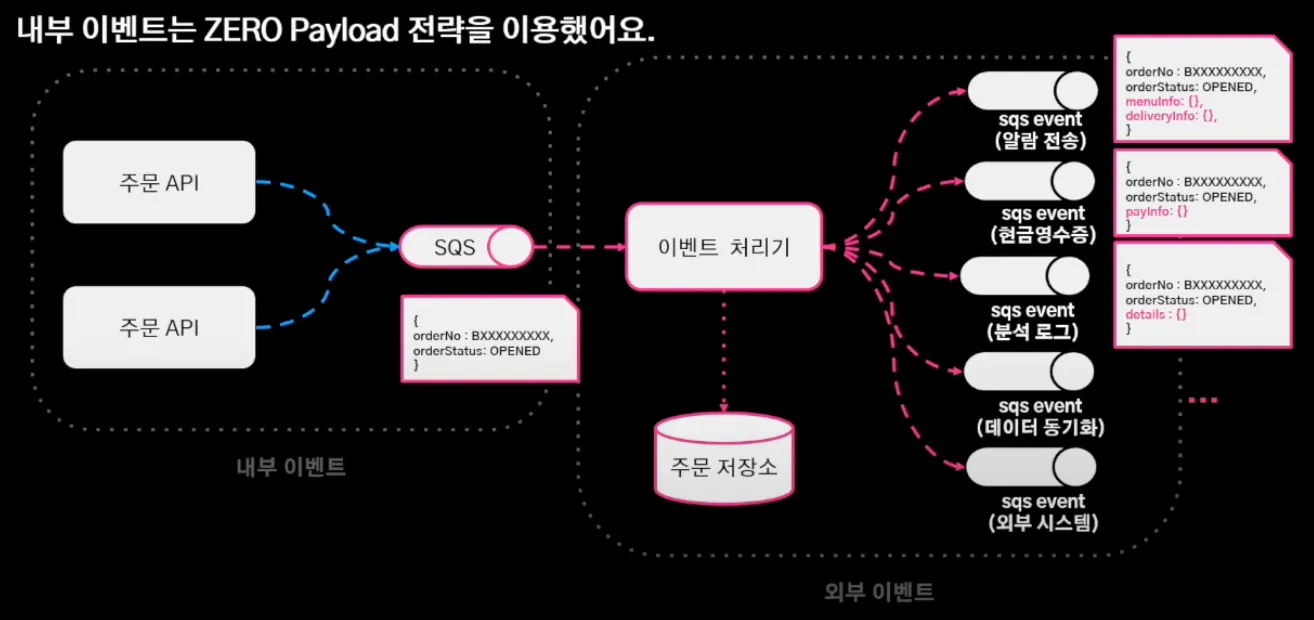
내부 이벤트는 zero payload 전략을 이용하여 서비스 로직을 심기 어렵게 만들어, 내부 이벤트는 어떤 도메인 로직이 수행됐고 그 결과가 어떻게 됐어 정도만 송신하고 이벤트 처리기가 모든 서비스 로직을 처리할 수 있게끔 주문 저장소에서 필요한 조회하여 payload를 채워주고 이벤트 발행했다. (mongoDB를 통해 조회 로직 분리했기 때문에 부담 X)
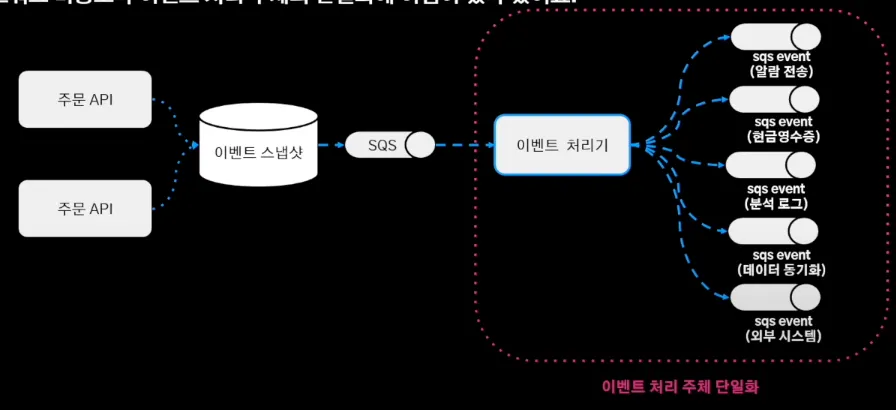
이를 통해 이벤트 처리 주체의 단일화를 구축했다.
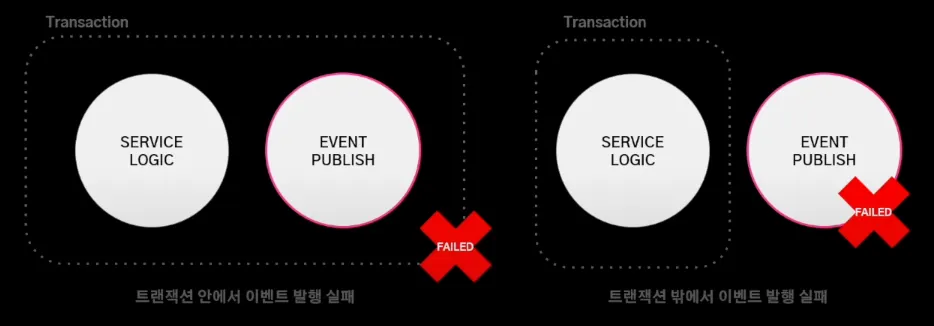
이벤트 발행 실패 유형에는 트랜잭션의 내부에서 실패하는 경우와 외부에서 실패하는 경우가 있다.
트랜잭션 내부에서 이벤트 발행 실패하는 경우에는 도메인 로직 전체가 실패하여 롤백 되기 때문에 서비스의 일관성 유지된다. 하지만 트랜잭션 외부에서 이벤트 발행 실패하는 경우에는 도메인 로직은 성공하지만 서비스 로직은 실패하여 일관성 해치게 된다.
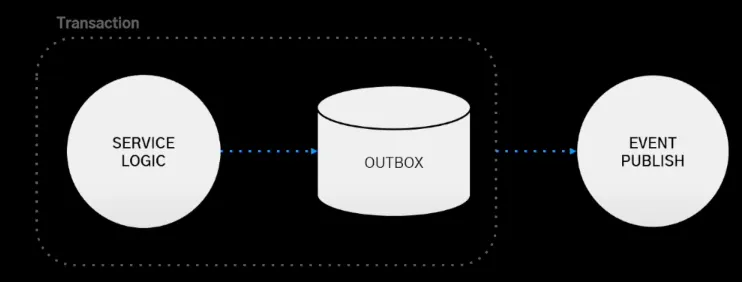
트랜잭션 아웃박스 패턴을 통해 이렇게 트랜잭션 외부에서 이벤트 발행을 실패하는 경우 일관성이 깨지는 문제를 해소하였다. 아웃 박스 엔티티에 데이터 payload를 저장하고 이벤트 발행 및 트랜잭션 커밋한 후, 이벤트 발행에 실패하더라도 아웃박스 엔티티에 저장된 payload로 이벤트 재발행하여 이벤트 유실 문제를 해결했다.
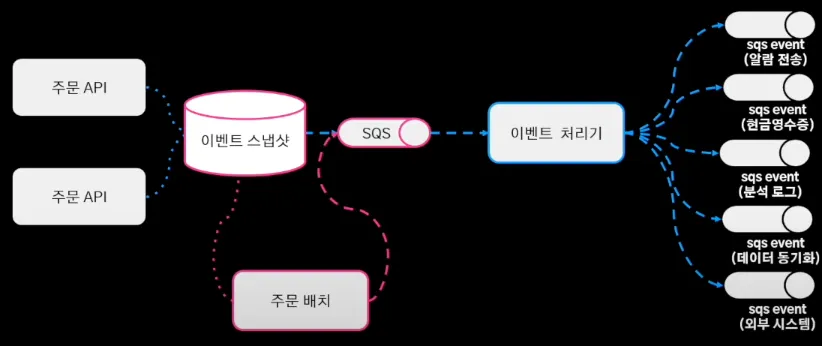
여기에 이벤트 스냅샷과 주문 배치를 추가하여, 특정 시간이 지나도록 이벤트가 처리가 안되면 재발행 하도록 구현하였다. 이를 통해 이벤트가 중복 처리는 되더라도 유실되는 상황은 없도록 구축하였다.
결론
위 내용을 요약하자면 다음과 같다.
1.
단일 장애 포인트
→ MSA를 적용하여 한 시스템의 장애가 다른 시스템에 전파되지 않도록 개선
2.
대규모 데이터로 인한 조회 성능 저하
→ CQRS를 통해 조회용 mongoDB를 추가하여 조회 성능 극대화
3.
대규모 트랜잭션로 인한 쓰기 처리량 한계 도달
→ 애플리케이션 샤딩을 구현하여 쓰기용 DB의 스케일 아웃 대응
4.
복잡한 이벤트 아키텍처와 이벤트 유실 문제
→ 이벤트 내외부 분리 및 외부에서 조회 및 처리 로직을 가지도록 수정, 아웃 박스 엔티티를 통한 이벤트 유실 대응
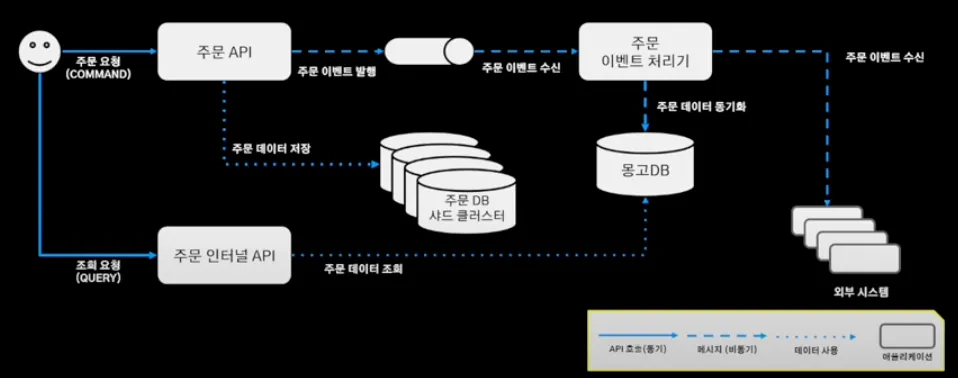
이렇게 개선해온 배달의 민족 주문 시스템의 최종 아키텍처는 이와 같다.